







文章主要参考:https://www.cnblogs.com/xiao-zhang-blogs/p/7147369.html
经测试后得出此案例,如有错误之处,欢迎批评指正
总结:此语法是查询id为123456,且prior在id一侧,则id为父节点,parent_id为子节点,
翻译过来就是查询根节点id为123456的数据,以及parent_id='123456‘的叶子节点的数据,level表示层级关系,根节点表示1,一级叶子节点表示2,二级叶子节点表示3,一次类推。
案例:
现在有一组这样的数据,以树的结构存在数据库中:

语法结构及具体案例一:
SELECT
id,
LEVEL AS lv
FROM
tableASTART WITH id = '123456'
CONNECT BY parent_id = PRIOR id;
解释:start with:以id为123456的开始,
connect by parent_id = prior id;将id 与parent_id进行了连接,id为父节点,parent_id为子节点
PRIOR运算符在一侧表示父节点,在另一侧表示子节点,从而确定查找树结构是的顺序是自顶向下还是自底向上。
PRIOR被置于CONNECT BY子句中等号的前面时,则强制从根节点到叶节点的顺序检索,即由父节点向子节点方向通过树结构,我们称之为自顶向下的方式。如:
CONNECT BY PRIOR EMPNO=MGR
PIROR运算符被置于CONNECT BY 子句中等号的后面时,则强制从叶节点到根节点的顺序检索,即由子节点向父节点方向通过树结构,我们称之为自底向上的方式。比如:
CONNECT BY EMPNO=PRIOR MGR
总结(自己理解):connect by prior column1 = column2 或者 connect by column2 = prior column1 写法都可以,
主要看prior写在谁的前面,prior写在谁的前面谁就作为父级值(参照值),也就是说[connect by prior column1 = column2]的意思就是是 按start with 条件查询出的记录行,以column1为参考值,查询column2为column1值的记录。
则我上边的那段代码,表示从叶节点到子节点遍历,
执行具体案例一的代码后,效果是这样的:
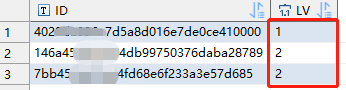
level我在上边代码中重命名成了LV,1 2 表示了树中的层级管理,1表示根节点,2表示叶子,两个2 两个叶子,
然后就可以获取我们想要的数据了,我这需要的是最大层级数,即
SELECT
MAX( lv )
FROM
(
SELECT
id,
LEVEL AS lv
FROM
tableA START WITH id = '' CONNECT BY parent_id = PRIOR id
);
max(lv) 获取了最大的层级数。















 995
995











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









