






分别测试了 多线程、线程池、aio 等模式
线程受CPU调度限制,大请求量下 AIO 效率最高,详见代码
注释中有详细说明,main 方法中是程序入口
"""
python 各种方式发起 http 请求对比
参考:
https://plainenglish.io/blog/send-http-requests-as-fast-as-possible-in-python-304134d46604
"""
import time
import requests
from requests.sessions import Session
from threading import Thread,local
from queue import Queue
from concurrent.futures import ThreadPoolExecutor
def sync_get(url_list: list):
"""
同步方式请求
:param url_list:
:return:
"""
def download_link(url: str) -> None:
result = requests.get(url).content
print(f'Read {len(result)} from {url}')
def download_all(urls: list) -> None:
for url in urls:
download_link(url)
start = time.time()
download_all(url_list)
end = time.time()
print(f'sync download {len(url_list)} links in {end - start} seconds')
def sync_get_share_session(url_list: list):
"""
依然是同步请求,但是可以共享 Session
共享 Session 可以记录 cookie,保持登录状态
复用 TCP 减少 TLS 时间等
详情可以搜索【python session 优化 requests 性能】
TODO 根据情况补充:session 和 cookie,后面安全经常会用到
:param url_list:
:return:
"""
def download_link(url: str, session: Session):
with session.get(url) as response:
result = response.content
print(f'Read {len(result)} from {url}')
def download_all(urls: list):
with requests.Session() as session:
for url in urls:
download_link(url, session=session)
start = time.time()
download_all(url_list)
end = time.time()
print(f'download {len(url_list)} links in {end - start} seconds')
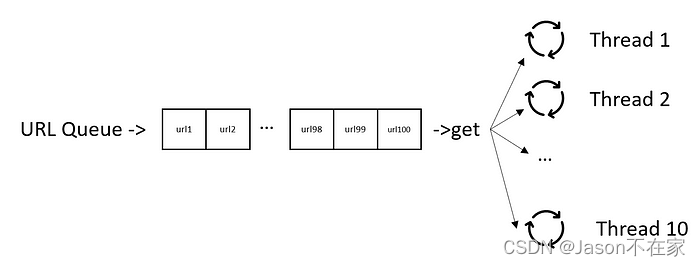
def multi_thread_get(url_list):
"""
多线程请求,启动10个线程
要点:
1. 多线程操作 list 时会存在线程安全问题,这里使用 queue 解决,关键词【python queue 线程安全队列】
2. 多线程共享 Session 对象会有线程安全问题,这里使用 thread_local 解决,保证一个线程只有一个 session
:param url_list:
:return:
"""
# 将压入线程安全队列
q = Queue(maxsize=0) # Use a queue to store all URLs
for url in url_list:
q.put(url)
thread_local = local() # The thread_local will hold a Session object
def get_session() -> Session:
if not hasattr(thread_local, 'session'):
thread_local.session = requests.Session() # Create a new Session if not exists
return thread_local.session
def download_link() -> None:
'''download link worker, get URL from queue until no url left in the queue'''
session = get_session()
while True:
# 全部执行完成后线程会一直卡住,需要手动停止
# 设置超时时间的话,可以在 $timeout 秒后抛异常终止
url = q.get(block=True, timeout=None)
with session.get(url) as response:
print(f'Read {len(response.content)} from {url}')
q.task_done() # tell the queue, this url downloading work is done
def download_all() -> None:
'''Start 10 threads, each thread as a wrapper of downloader'''
thread_num = 10
for i in range(thread_num):
t_worker = Thread(target=download_link)
t_worker.start()
q.join() # main thread wait until all url finished downloading
print("start work")
start = time.time()
download_all()
end = time.time()
print(f'download {len(url_list)} links in {end - start} seconds')
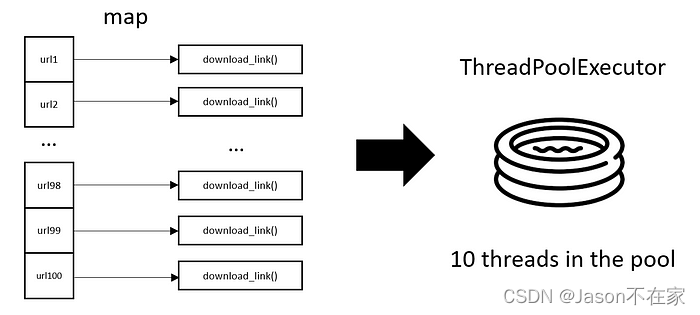
def thread_pool_get(url_list):
thread_local = local()
def get_session() -> Session:
if not hasattr(thread_local, 'session'):
thread_local.session = requests.Session()
return thread_local.session
def download_link(url: str):
session = get_session()
with session.get(url) as response:
print(f'Read {len(response.content)} from {url}')
def download_all() -> None:
with ThreadPoolExecutor(max_workers=10) as executor:
executor.map(download_link, url_list)
start = time.time()
download_all()
end = time.time()
print(f'download {len(url_list)} links in {end - start} seconds')
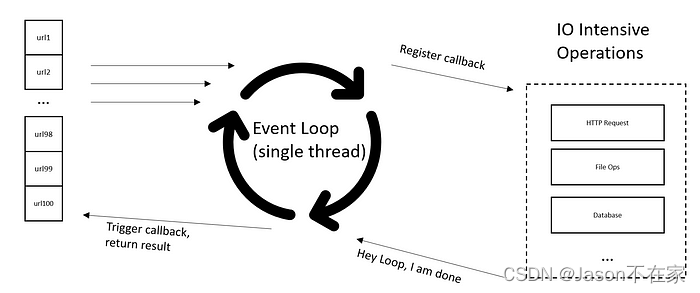
def aio_get(url_list):
"""
异步非阻塞的方式发送请求
这种情况下,并发可以非常搞,性能看带宽、网卡等情况,不过并发太高可能会被服务端限流
:param url_list:
:return:
"""
import asyncio
import aiohttp
from aiohttp.client import ClientSession
async def download_link(url: str, session: ClientSession):
async with session.get(url) as response:
result = await response.text()
print(f'Read {len(result)} from {url}')
async def download_all(urls: list):
my_conn = aiohttp.TCPConnector(limit=40)
async with aiohttp.ClientSession(connector=my_conn) as session:
tasks = []
for url in urls:
task = asyncio.ensure_future(download_link(url=url, session=session))
tasks.append(task)
await asyncio.gather(*tasks, return_exceptions=True) # the await must be nest inside of the session
start = time.time()
asyncio.run(download_all(url_list))
end = time.time()
print(f'download {len(url_list)} links in {end - start} seconds')
if __name__ == '__main__':
_url_list = ["https://cn.bing.com/", "https://www.baidu.com/", "https://www.so.com/"] * 50
# 方法1 同步方式请求
# sync_get(_url_list) # 58.78762245178223
# 方法2 同步请求,但是共享 session
# sync_get_share_session(_url_list) # 32.01118564605713
# 方法3 多线程请求
# multi_thread_get(_url_list) # 3.5877575874328613
# 方法4 线程池
thread_pool_get(_url_list) # 3.5470234870910645
# 方法5 异步非阻塞的方式发送请求
aio_get(_url_list) # 1.354555606842041
多线程示意图
线程池示意图
AIO异步非阻塞IO















 1846
1846











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









