









1.在所有的老师中求出最受欢迎的老师Top3
2.求每个学科中最受欢迎老师的top3(至少用2到三种方式实现)
文件内容;
http://english.com.lj/laoda
http://english.com.lj/laoda
http://english.com.lj/laoer
http://english.com.lj/laoer
http://english.com.lj/laoer
http://english.com.lj/laoer
http://english.com.lj/laoer
http://english.com.lj/laowu
http://english.com.lj/laowu
http://math.com.lj/laosan
http://math.com.lj/laosan
http://math.com.lj/laosi
http://math.com.lj/laosi
http://math.com.lj/laosi
http://english.com.lj/laoer
http://english.com.lj/laoer
http://english.com.lj/laoer
http://english.com.lj/laoer
http://english.com.lj/laoer
http://english.com.lj/laowu
http://english.com.lj/laowu
http://math.com.lj/laosan
http://math.com.lj/laosan
http://math.com.lj/laosi
http://math.com.lj/laosi
http://math.com.lj/laosi
http://english.com.lj/laoer
http://english.com.lj/laoer
http://english.com.lj/laoer
http://english.com.lj/laoer
http://english.com.lj/laoer
http://english.com.lj/laowu
http://english.com.lj/laowu
http://math.com.lj/laosan
http://math.com.lj/laosan
http://math.com.lj/laosi
http://math.com.lj/laosi
http://math.com.lj/laosi
http://chinese.com.lj/laoliu
http://chinese.com.lj/laoliu
http://chinese.com.lj/laoliu
http://chinese.com.lj/laoliu5种方法:
1.聚合后按学科进行分组,然后在每个分组中进行排序(调用的是Scala集合的排序)
2.先按学科进行过滤,然后调用RDD的方法进行排序(多台机器+内存+磁盘),需要将任务提交多次
3.自定义分区,然后在每个分区中进行排序(patitionBy、mapPartitions)
4.在聚合是就用于自定义的分区,可以减少shuffle
5.自定义分区,mapPartitions,在调用mapPartitions方法里面定义一个可排序的集合(6)
1.如何切分出学科和老师
方式1:
val index = line.lastIndexOf("/") //拿到最后一个斜线
val teacher = line.substring(index + 1)
val httpHost = line.substring(0, index)
val subject = new URL(httpHost).getHost.split("[.]")(0) //[] 即为正则的语义歧义解决
println(teacher + ", " + subject)方式2:
val splits: Array[String] = line.split("/")
val subject = splits(2).split("[.]")(0)
val teacher = splits(3)
println(subject + " " + teacher)计算每个学科前三名老师
方法一:分组排序
object GroupFavTeacher1 {
def main(args: Array[String]): Unit = {
val topN = args(1).toInt
val conf = new SparkConf().setAppName("FavTeacher").setMaster("local[4]")
val sc = new SparkContext(conf)
val lines: RDD[String] = sc.textFile(args(0)) //指定以后从哪里读取数据,运行时传参
//整理数据
val sbjectTeacherAndOne: RDD[((String, String), Int)] = lines.map(line => {
val index = line.lastIndexOf("/")
val teacher = line.substring(index + 1)
val httpHost = line.substring(0, index)
val subject = new URL(httpHost).getHost.split("[.]")(0)
((subject, teacher), 1)
})
//和 1 组合在一起-不好,调用了两次map方法;应该在上面map时就把1 放进去
//val map: RDD[((String, String), Int)] = sbjectAndteacher.map((_, 1))
val reduced: RDD[((String, String), Int)] = sbjectTeacherAndOne.reduceByKey(_+_) //聚合,将学科和老师联合当做key
val grouped: RDD[(String, Iterable[((String, String), Int)])] = reduced.groupBy(_._1._1) //分组排序(按学科进行分组)-[学科,该学科对应的老师的数据]
//经过分组后,一个分区内可能有多个学科的数据,一个学科就是一个迭代器,将每一个组拿出来进行操作
val sorted = grouped.mapValues(_.toList.sortBy(_._2).reverse.take(topN)) //能调用sacla的sortby方法是因为一个学科的数据已经在一台机器上的一个scala集合里面了
val r: Array[(String, List[((String, String), Int)])] = sorted.collect() //收集结果
println(r.toBuffer) //打印
sc.stop()
}
}
方式二:先过滤在排序
object GroupFavTeacher1 {
def main(args: Array[String]): Unit = {
val topN = args(1).toInt
val subjects = Array("english", "math", "chinese")
val conf = new SparkConf().setAppName("FavTeacher2").setMaster("local[4]")
val sc = new SparkContext(conf)
val lines: RDD[String] = sc.textFile(args(0)) //指定以后从哪里读取数据,运行时传参
//整理数据
val sbjectTeacherAndOne: RDD[((String, String), Int)] = lines.map(line => {
val index = line.lastIndexOf("/")
val teacher = line.substring(index + 1)
val httpHost = line.substring(0, index)
val subject = new URL(httpHost).getHost.split("[.]")(0)
((subject, teacher), 1)
})
val reduced: RDD[((String, String), Int)] = sbjectTeacherAndOne.reduceByKey(_+_) //聚合,将学科和老师联合当做key
for (sb <- subjects) {
val filtered: RDD[((String, String), Int)] = reduced.filter(_._1._1 == sb) //该RDD中对应的数据仅有一个学科的数据(因为过滤过了)
val favTeacher = filtered.sortBy(_._2, false).take(topN) //scala的集合排序是在内存中进行的,但是内存有可能不够用,可以调用RDD的sortby方法,内存+磁盘进行排序,现在调用的是RDD的sortBy方法,(take是一个action,会触发任务提交)
println(r.toBuffer) //打印
sc.stop()
}
}
方式三:一次拿一个分区,自定义分区规则
object GroupFavTeacher3 {
def main(args: Array[String]): Unit = {
val topN = args(1).toInt
val conf = new SparkConf().setAppName("FavTeacher3").setMaster("local[4]")
val sc = new SparkContext(conf)
val lines: RDD[String] = sc.textFile(args(0)) //指定以后从哪里读取数据,运行时传参
//整理数据
val sbjectTeacherAndOne: RDD[((String, String), Int)] = lines.map(line => {
val index = line.lastIndexOf("/")
val teacher = line.substring(index + 1)
val httpHost = line.substring(0, index)
val subject = new URL(httpHost).getHost.split("[.]")(0)
((subject, teacher), 1)
})
val reduced: RDD[((String, String), Int)] = sbjectTeacherAndOne.reduceByKey(_+_) //聚合,将学科和老师联合当做key
val subjects: Array[String] = reduced.map(_._1._1).distinct().collect() //计算有多少学科
val sbPatitioner = new SubjectParitioner(subjects); //自定义一个分区器,并且按照指定的分区器进行分区
val partitioned: RDD[((String, String), Int)] = reduced.partitionBy(sbPatitioner) // partitionBy按照指定的分区规则进行分区,调用partitionBy时RDD的Key是(String, String)
val sorted: RDD[((String, String), Int)] = partitioned.mapPartitions(it => { //如果一次拿出一个分区(可以操作一个分区中的数据了)
it.toList.sortBy(_._2).reverse.take(topN).iterator //将迭代器转换成list,然后排序,在转换成迭代器返回
})
val r: Array[((String, String), Int)] = sorted.collect()
println(r.toBuffer) //打印
sc.stop()
}
}
class SubjectParitioner(sbs: Array[String]) extends Partitioner { //自定义分区器,相当于主构造器(new的时候回执行一次)
val rules = new mutable.HashMap[String, Int]() // 用于存放规则的一个map
var i = 0
for(sb <- sbs) {
rules.put(sb, i)
i += 1
}
override def numPartitions: Int = sbs.length //返回分区的数量(下一个RDD有多少分区)
override def getPartition(key: Any): Int = { //根据传入的key计算分区标号,key是一个元组(String, String)
val subject = key.asInstanceOf[(String, String)]._1 //获取学科名称
rules(subject) //根据规则计算分区编号
}
}
三种排序规则:加了一个行号,按照某个规则进行排序 row_number() over(partition by subject order by counts desc) sub_rk, rank() over(order by counts desc) g_rk dense_rank() over(order by counts desc) g_rk
object SQLFavTeacher {
def main(args: Array[String]): Unit = {
val topN = args(1).toInt
val spark = SparkSession.builder().appName("RowNumberDemo").master("local[4]").getOrCreate()
val lines: Dataset[String] = spark.read.textFile(args(0))
import spark.implicits._
val df: DataFrame = lines.map(line => {
val tIndex = line.lastIndexOf("/") + 1
val teacher = line.substring(tIndex)
val host = new URL(line).getHost
//学科的index
val sIndex = host.indexOf(".")
val subject = host.substring(0, sIndex)
(subject, teacher)
}).toDF("subject", "teacher")
df.createTempView("v_sub_teacher")
//该学科下的老师的访问次数
val temp1: DataFrame = spark.sql("SELECT subject, teacher, count(*) counts FROM v_sub_teacher GROUP BY subject, teacher")
//求每个学科下最受欢迎的老师的topn
temp1.createTempView("v_temp_sub_teacher_counts")
//三种写法都对,将相同 学科搞到一个分区,排序
//语句1:g_rk全局排名,sub_rk分区排名
//val temp2 = spark.sql(s"SELECT * FROM (SELECT subject, teacher, counts, row_number() over(partition by subject order by counts desc) sub_rk, rank() over(order by counts desc) g_rk FROM v_temp_sub_teacher_counts) temp2 WHERE sub_rk <= $topN")
//语句2,3:下面两种是把上面入选的老师在进行全局排序
//val temp2 = spark.sql(s"SELECT *, row_number() over(order by counts desc) g_rk FROM (SELECT subject, teacher, counts, row_number() over(partition by subject order by counts desc) sub_rk FROM v_temp_sub_teacher_counts) temp2 WHERE sub_rk <= $topN")
val temp2 = spark.sql(s"SELECT *, dense_rank() over(order by counts desc) g_rk FROM (SELECT subject, teacher, counts, row_number() over(partition by subject order by counts desc) sub_rk FROM v_temp_sub_teacher_counts) temp2 WHERE sub_rk <= $topN")
temp2.show()
spark.stop()
}
}结果:
语句一:
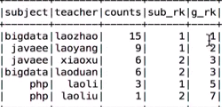
语句二,三:
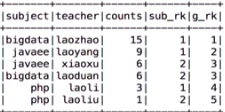















 842
842











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









