






什么是JMM?
JMM即为JAVA 内存模型(java memory model)。因为在不同的硬件生产商和不同的操作系统下,内存的访问逻辑有一定的差异,结果就是当你的代码在某个系统环境下运行良好,并且线程安全,但是换了个系统就出现各种问题。Java内存模型,就是为了屏蔽系统和硬件的差异,让一套代码在不同平台下能到达相同的访问结果。JMM从java 5开始的JSR-133发布后,已经成熟和完善起来。
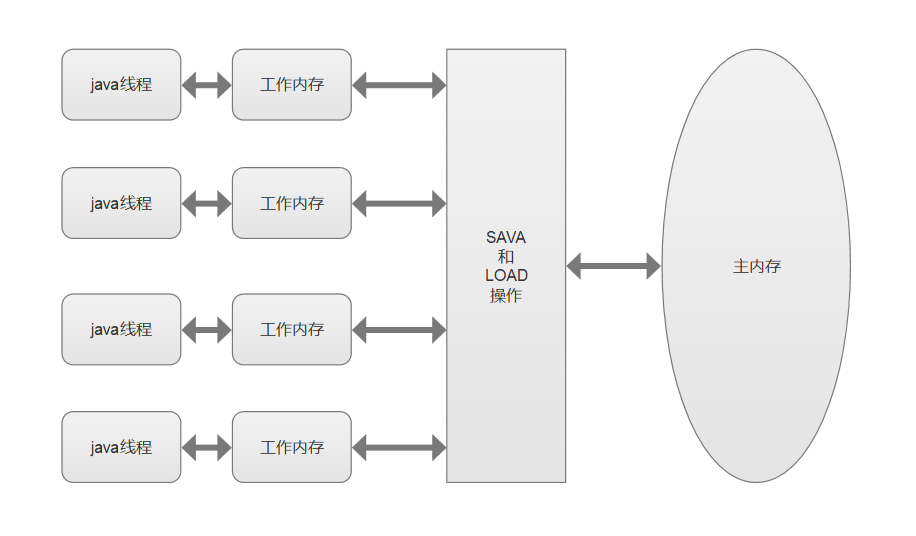
JMM内存划分
JMM规定了内存主要划分为主内存和工作内存两种。此处的主内存和工作内存跟JVM内存划分(堆、栈、方法区)是在不同的层次上进行的,如果非要对应起来,主内存对应的是Java堆中的对象实例部分,工作内存对应的是栈中的部分区域,从更底层的来说,主内存对应的是硬件的物理内存,工作内存对应的是寄存器和高速缓存。
CPU高速缓存

二者是不是有点类似,都是从主内存获取数据,然后保存本地进行运算。其实我在学习后,感觉两个可以直接进行等效看待,因为说到底,线程执行最终还是在cpu,因此JMM中工作内存,简单的可以认为表示的就是cpu的3级高速缓存。
那么cpu运算单元是如何获取数据的呢?
- 首先运算单元会访问一级缓存L1,数据在L1存在,直接返回。
- 如果数据在L1中不存在,则访问二级缓存L2,数据在L2存在,直接返回。
- 如果数据在L2也不存在,则访问三级缓存L3,数据在L3存在,直接返回。
- 如果数据在L3也不存在,则访问主内存,主内存返回数据data。
- L3缓存主内存返回的数据data,并返回L2。
- L2缓存data,并返回L1。
- L1缓存data,并返回给计算单元进行计算。
- 将计算结果写回主内存中,如果是共享数据,需要将其他核内数据状态置为invalid,这里可以去了解MESI等相关协议,这里不展开介绍了。
那么每次从cpu取多少数据呢?
当然不是只取一个数据,这里按照局部性原则,会返回若干个缓存行,每个缓存行默认为64byte(这个其实和mysql数据库类似,取一个数据页的数据)。为啥是64byte,那肯定是通过工业实践检验得到的,缓存行设置64byte,可以最大提升计算机效率。
缓存行设置过小问题:缓存行设置过小,就需要频繁从主内存获取数据,而从主内存获取数据是比较慢的(与从3级高速缓存相比),这样就会让cpu计算单元浪费大量时间于等待从主内存获取数据。
缓存行过大问题:高速缓存区相较于主内存小很多,所以不能将缓存行设置过大,如果设置过大,对于内存连续的计算数据其实会提升效率,但是如果对于数据较为散列的情况,就会频繁重新获取数据,因为缓存行设置过大,那么高速缓存中,缓存行个数就会减少,因此过大也不合适。
伪共享问题
如上面CPU缓存图,当两个数据x,y位于同一个缓存行中,恰好这个时候,cpu核1需要修改x的值,cpu核2需要修改y的值,又因为需要将计算结果写回主内存中,并将其他核内数据状态置为invalid,所以两个核修改同一个缓存行内数据时,当将计算后的数据写回主内存后,会将对方高速缓存内的缓存行状态置为invalid,导致每次操作x,y都需要重新从主内存进行获取,降低了效率。
那么如何解决呢?可以在x,y前后都进行填充,保证x,y一定不在一个缓存行。
public class MyTestObject {
long p0, p1, p2, p3, p4, p5, p6;
long x;
long p7, p8, p9, p10, p11, p12, p13;
}
这里有段代码可以进行验证缓存行的存在:
private static class Padding {
public volatile long p1, p2, p3, p4, p5, p6, p7; //
}
private static class T extends Padding {
public volatile long x = 0L;
}
public static T[] arr = new T[2];
static {
arr[0] = new T();
arr[1] = new T();
}
public static void main(String[] args) throws Exception {
Thread t1 = new Thread(()->{
for (long i = 0; i < 1000_0000L; i++) {
arr[0].x = i;
}
});
Thread t2 = new Thread(()->{
for (long i = 0; i < 1000_0000L; i++) {
arr[1].x = i;
}
});
final long start = System.nanoTime();
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println((System.nanoTime() - start)/100_0000);
}
个人测试,不进行填充计算时间为280ms左右,填充数据计算时间为88ms左右。
总结
本文后续还会连续进行补充,这里内容较多,后续再进行更新。可以推荐几个博客大家可以去学习:voliate关键字、java内存模型JMM理解整理















 2721
2721











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









