









本博客记录学习数据分析的思考和心得
本博客会分享数据源码,以及在学习数据分析过程中,学习到的内容和本人不熟悉的地方
本节主要研究运动员身高,看参加奥运会的运动员身高有没有独特的优势?
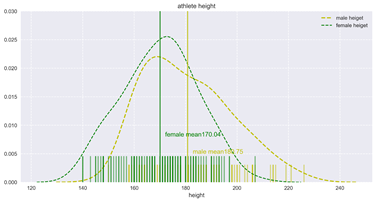
下图是本篇博客最终完成的目标,横抽是运动员的身高,两条曲线分别表示的是男女运动员的差异,中间的两条竖线表示的是男女运动员身高的平均值,下面的小竖线表示的是每一个运动员的身高分布。
本次代码思路主要有以下几步
- 加载数据
- 数据处理与清洗,获取运动员的项目、名字、性别、身高四项信息
- 图表绘制。特别说明,图表绘制时,有大量的参数,什么颜色、宽度、调色盘等等把,这个需要慢慢研究,用的时候查一下,我自己目前也是处于不熟悉的阶段,都是跟着老师敲代码,练习。
# -*- coding: utf-8 -*-
"""
Created on Thu Apr 11 19:10:05 2019
sns.distplot() #直方图绘制,身高越高越容易参加奥运会吗?
@author: zss0330816
"""
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import os
#os.chdir('C:\\')
df = pd.read_excel(r"D:\数据分析\数据分析师\classdata\奥运运动员数据.xlsx", sheetname=1)
print(df)
df_length = len(df)
df_columns = df.columns.tolist()
#print(df_columns)
data = df[['event', 'name', 'height', 'gender']]#筛选出相应列
data_male = data[data['gender'] == '男']#筛选男运动员
data_female = data[data['gender'] == '女']#筛选女运动员
#男女平均身高
male_mean = data_male['height'].mean()
female_mean = data_female['height'].mean()
sns.set_style('darkgrid')#有几个取值,可以不设置
#绘制图表
plt.figure(figsize=(12,6))#图表大小
#大堆参数来袭,多用吧,没有特别的窍门
sns.distplot(data_male['height'], hist=False,
kde=True, rug=True,
rug_kws={'color':'y', 'lw':2,'alpha':0.5, 'height': 0.1},
kde_kws={'color':'y', 'lw': 2, 'linestyle':'--'},
label='male heiget')
sns.distplot(data_female['height'], hist=False,
kde=True, rug=True,
rug_kws={'color':'g','lw':2,'alpha':0.5, 'height':0.15},
kde_kws={'color':'g', 'lw': 1.5, 'linestyle':'--'},
label='female heiget')
plt.axvline(male_mean, color='y', linestyle= '-', alpha=0.9)#中间竖线
plt.text(male_mean+2, 0.005, 'male mean%.2f'%male_mean, color='y')#中间标签
plt.axvline(female_mean, color='g', linestyle= '-', alpha=0.9)#中间竖线
#中间标签
plt.text(female_mean+2, 0.008, 'female mean%.2f'%female_mean, color='g')
plt.ylim([0, 0.03])#纵向高度,值越小,钟越瘦高,值越大,钟越矮胖
plt.grid(linestyle='--')#添加网格线
plt.title('athlete height')#添加标签
plt.savefig('pic1.png', dpi=300)#图片保存,dpi图片像素
print('finished')针对上述数据,有几个常用的点,在此mark一下
df_columns = df.columns.tolist()
data = df[['event', 'name', 'height', 'gender']]#- 将列的索引转成列表
- 从较多数据中,获取部分自己想要处理的数据,可以看作是数据挑选;
- 绘图参数学习,每次认识一些,这样参数也都能明白含义啦
seaborn.distplot(a,bins=None,hist=True,kde=True,
rug=False, fit=None, hist_kws=None, kde_kws=None,
rug_kws=None, fit_kws=None, color=None, vertical=False,
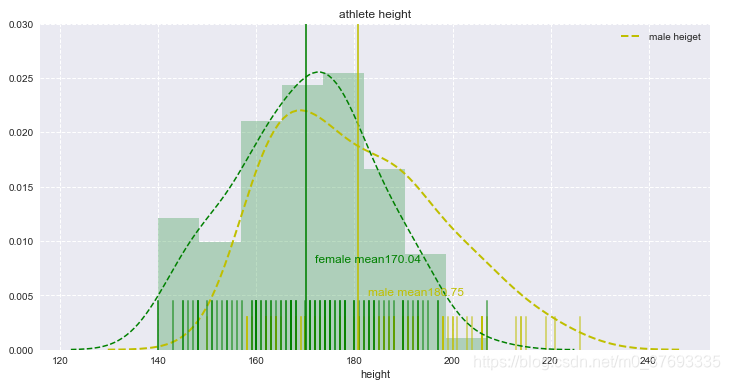
norm_hist=False, axlabel=None, label=None, ax=None)a-data数据,hist=True时,下面会出现直方图的长方形,如下图1,
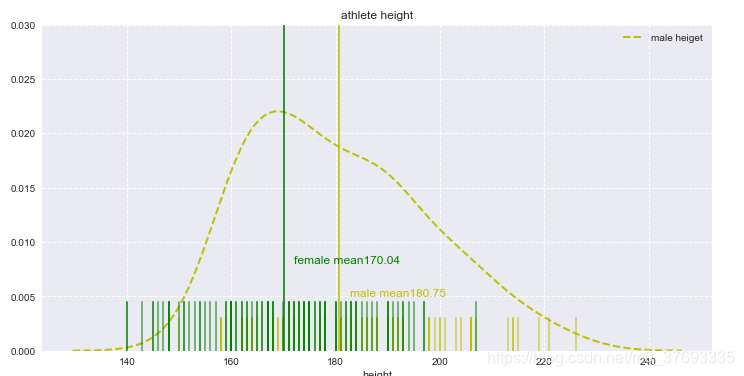
下图在绘制data_female图形时,把kde=False时,绿色线消失,如下图2,
综上,hist和kde参数调节是否显示直方图及核密度估计
rug_kws ,kde_kws则是对样式的调节,颜色,间距,透明度,高度等
在数据分析中,常用的库主要是科学计算库,numpy pandas 绘图工具matplotlib.pyplot seaborn这些,
还是勤加练习把!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









