







工具介绍
Airtest是网易出的基于图像识别和Poco控件识别的一款UI自动化测试工具。其功能类似于appium,但是但是Appium的安装配置环境相对复杂,而Airtest则显得十分简单,只需 去官网下载(http://airtest.netease.com/),选适合自己电脑的版本。
项目地址:http://airtest.netease.com/
快速上手教程:http://airtest.netease.com/tutorial/Tutorial.html
IDE快速上手教程:http://airtest.netease.com/docs/docs_AirtestIDE-zh_CN/1_quick_start.html
Airtest连接
打开Airtest IDE 用数据线连接手机(Airtest也支持无线连接,具体方式自行查找),并开启手机的usb调试模式,连接手机点击刷新ADB,正常情况下显示查显出连接设备,点击connect如下图
如能正常连接如下图,显示手机屏幕
工作模式介绍与选择
AirTest 工作模式具体分为两种
- 基于图像识别
Airtest可以通过屏幕截图的方式来获取我们想要操作的区域。例如对一些按钮进行测试时,我们可以不再写复杂的代码去获取按钮的信息,直接对按钮进行截图,把截图放在程序中,程序就会自动识别到截图中的位置以访问该按钮。
- 基于Poco控件
Airtest可以通过pocoUI树 查看控件的name、id等信息的来定位目标控件,再调用函数方法对控件进行不同的操作
由于图像识别的准备确不一定是百分百识别,所以poco控件一般做为基于图像识为的辅助功能,精确定位页面元素,poco控件也可以独自完成所有自动化工作,因为图像识别底层也是基于poco库的
本次app数据爬取将采用poco控件的方式进行,第一种基于图像识别教程的可自行百度,此提供一处博客https://www.cnblogs.com/xieqiankun/p/use_airtest.html
poco脚本录制
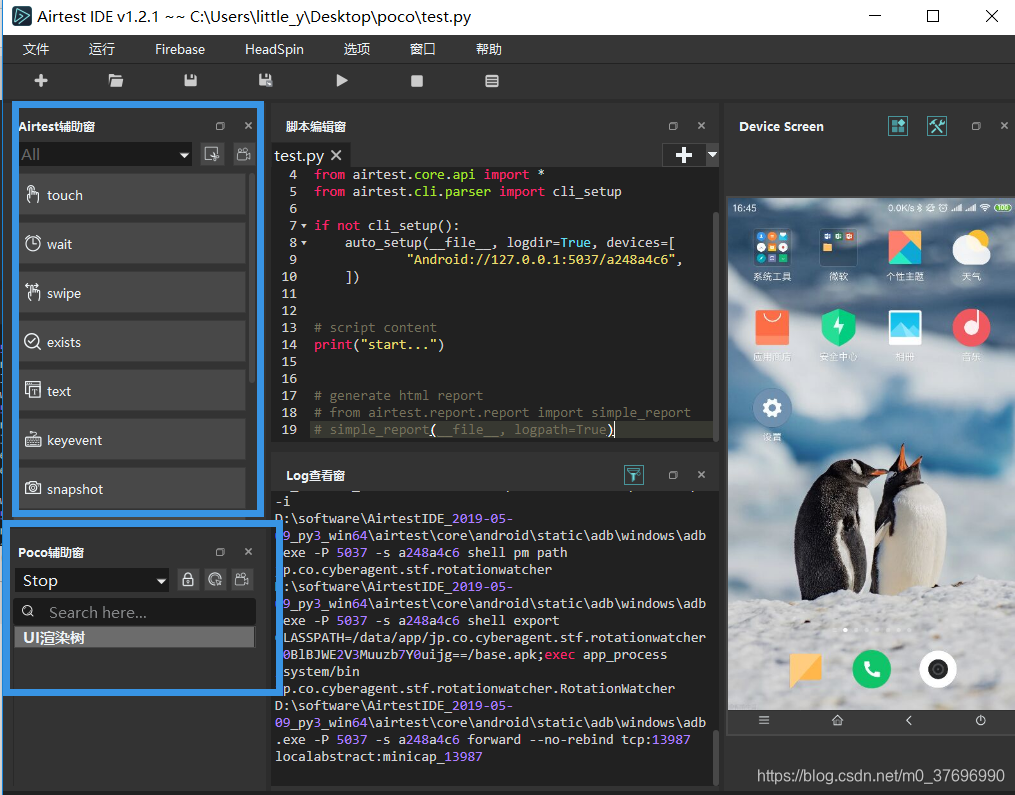
点击文件–》新建脚本—》纯.py脚本(高阶用户)如下图:
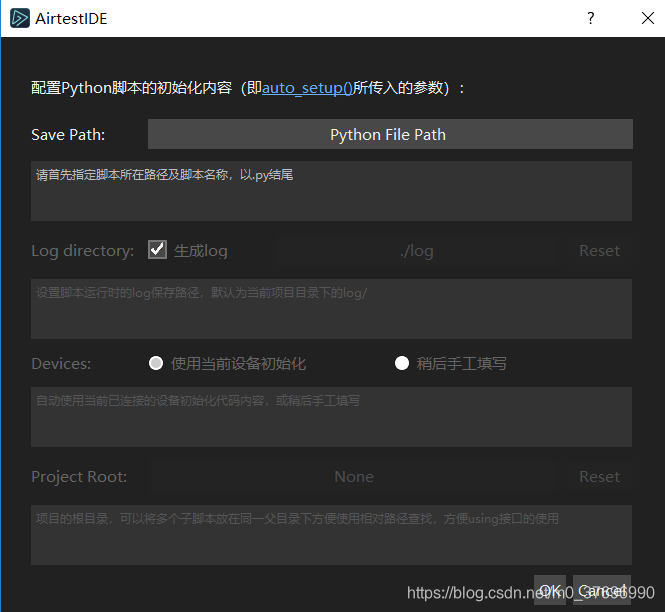
点击python File Path 创建一个py文件,并点Ok定(其他保持默认即可),然后在poco辅助窗选 择Android(根据手机系统自行选择),此时可以看下面的ui树形结构
下面介绍一下脚录制比较常用的三个按扭
第一个是冻结按扭,点击冻结,此时ui树的结构不会随着手机操作及时更新,避免手机误操作,ui结构树及时刷新
第二个是通过屏幕上的扭按来定位ui树的位置,类于似浏览器此按扭的功能
第三个是录制功能,开启后可以通过点手机中的按扭来生成操作代码如点微信图标则会生成
poco("com.miui.home:id/workspace").offspring("com.miui.home:id/cell_layout").child("微信")[0].offspring("com.miui.home:id/icon_icon").click()
此代码一般情况下是用来参照,实际代码可能要调整一下,比如.child(“微信”)[0],实代代码可能不会用[0]来写死而是用用for来处理,而.click()则按实际情况来改成对应的操作如get_text()
南方航空app脚本录制
首先下载南方航空app,此教程不在从登录开始,请先登录app;

打开app
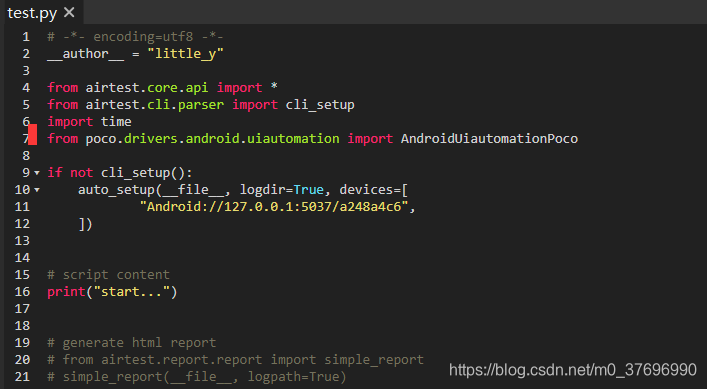
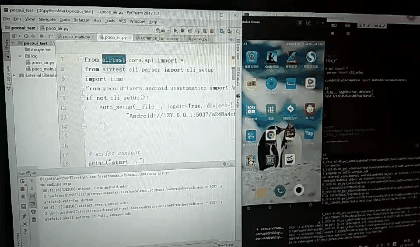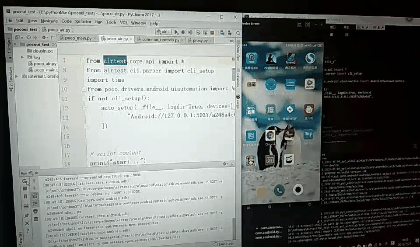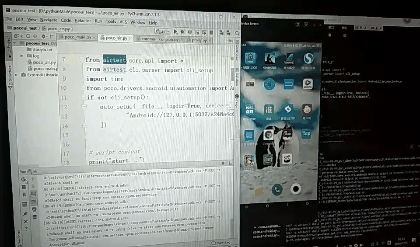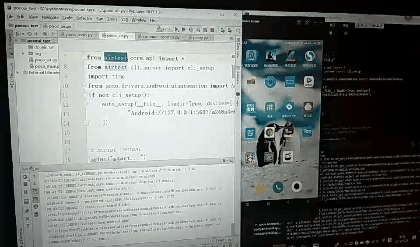
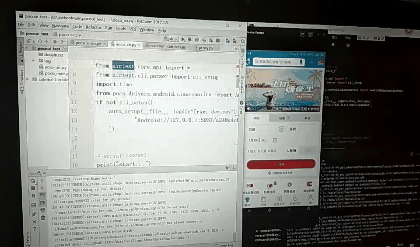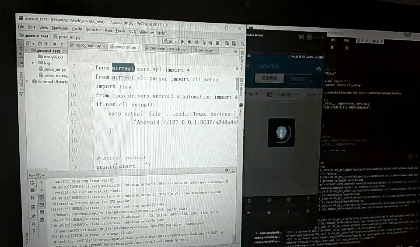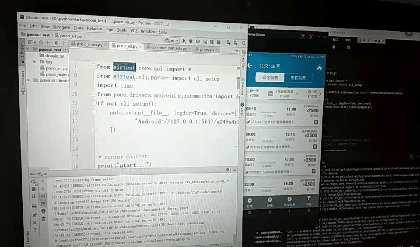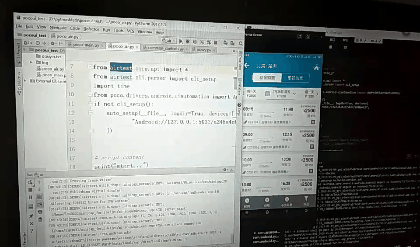
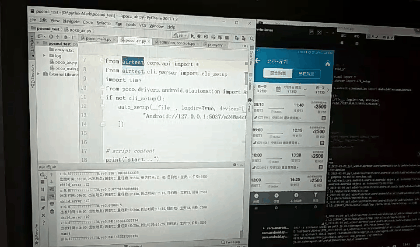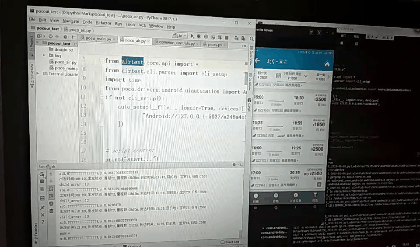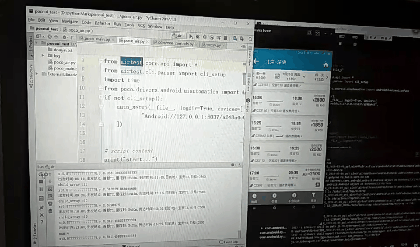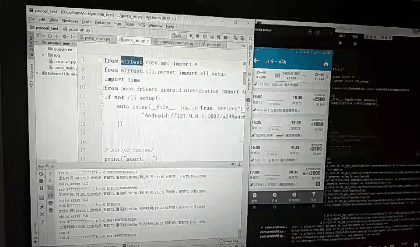
先创建的test.py,默认内容如下
# -*- encoding=utf8 -*-
__author__ = "little_y"
from airtest.core.api import *
from airtest.cli.parser import cli_setup
if not cli_setup():
auto_setup(__file__, logdir=True, devices=[
"Android://127.0.0.1:5037/a248a4c6",
])
# script content
print("start...")
# generate html report
# from airtest.report.report import simple_report
# simple_report(__file__, logpath=True)
导入

在最下载创建poco对象
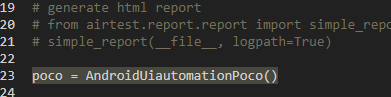
点击录制,然后点击app图标生成代码:
poco("com.miui.home:id/workspace").offspring("南方航空").offspring("com.miui.home:id/icon_icon").click()
app进入下面页面
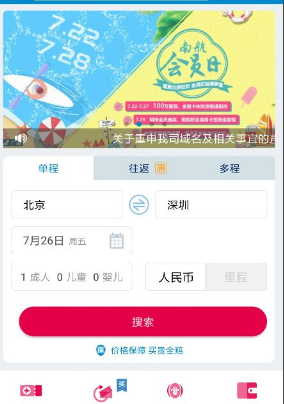
然后进app页面后点击"北京"即第一个输入框生成代码:
poco("com.csair.mbp:id/include_main_home_view_booking_tv_start").click()
进入页面:
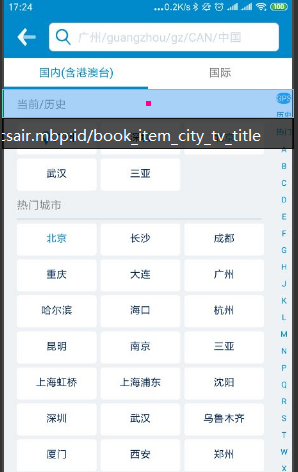
在热门城市里随便 点一个如北京生成代码
poco("android.widget.LinearLayout").offspring("android.view.ViewGroup").offspring("com.csair.mbp:id/layout_content").offspring("com.csair.mbp:id/rcyView_cities").child("android.widget.LinearLayout")[1].child("com.csair.mbp:id/book_item_city_rcyView_cities").child("com.csair.mbp:id/book_item_city_name_layout_parent")[0].offspring("com.csair.mbp:id/book_item_city_name_tv_cityName").click()
此代码显然是硬编码换种写法通过文字定位元素即:
poco(text='北京').click()
同样操作录制出目地的城市 选择的代码,也可以录制出日期的选择(此时教程选择默认)
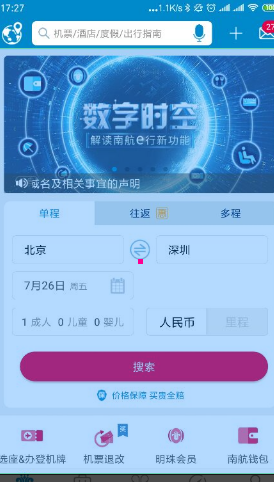
此时进行录制搜索按扭
poco("com.csair.mbp:id/include_main_home_view_booking_llyt_querybtn").click()
进行页面
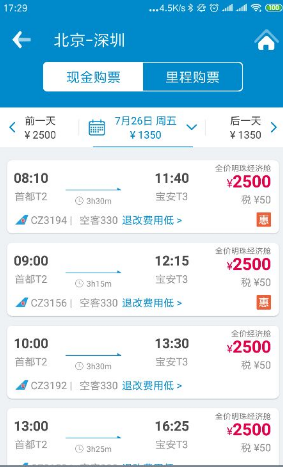
现在要提取详情内容:
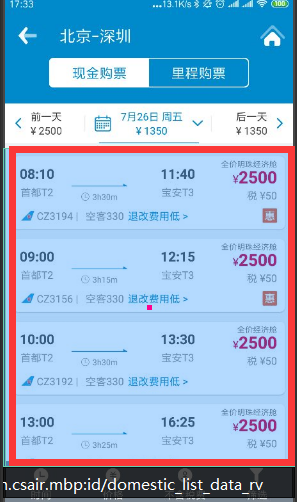
通过定位标签及查看ui树可以查找出机票详情的父类并获取所有子标签
array = poco("android.widget.LinearLayout").offspring("android.view.ViewGroup").\
offspring("com.csair.mbp:id/frl_place_holder").offspring("com.csair.mbp:id/domestic_list_data_rv")\
.children()
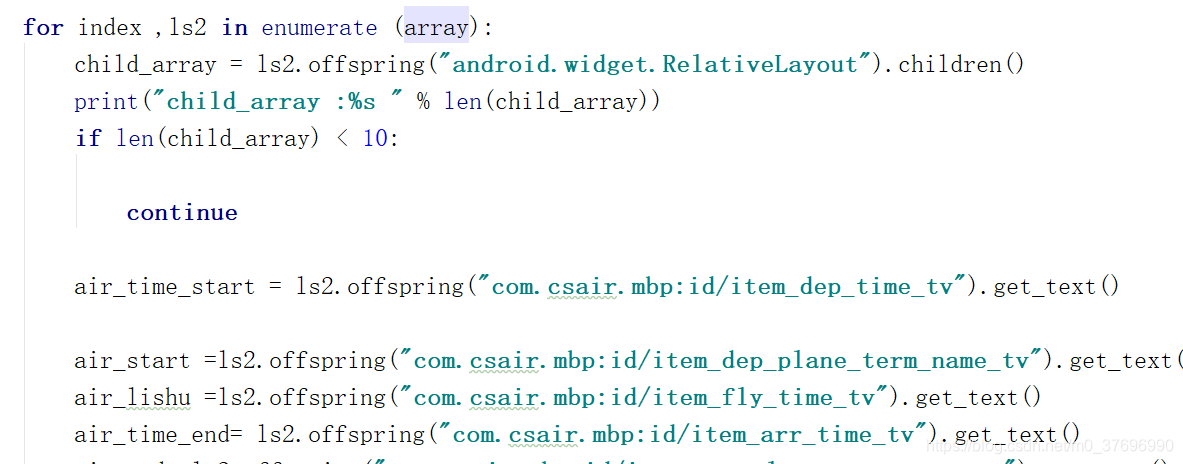
通过遍利子类来获取对应的内容如下图
遍历提取完当前屏幕的航班信息将需要进行模拟手机滑动,首先找到
isSwip = poco("android.widget.LinearLayout").offspring("android.view.ViewGroup").offspring("com.csair.mbp:id/frl_place_holder").child("android.widget.RelativeLayout").swipe([0,-y_postion +0.2])
其中y_postion为最后一个标签的位置,+0.2是为了控制滑动量,只要不使标签遗漏就行,自行控制
注意事项
一.由于滑动不可能精控制,在逻辑中要加入去重逻辑
value = "{air_time_start}#{air_start}#{air_lishu}#{air_time_end}#{air_end}#{price}".format(air_time_start=air_time_start,air_start=air_start,air_lishu=air_lishu,air_time_end=air_time_end,air_end=air_end,price=price)
if value in array_value:
continue
二.滑动是否滑动到底部需要判断此次爬取的最后一项数据与否已经存在,此处加一个列表专存放已爬过的数据用于对比
if value in array_value:
continue
完整代码请点击 app爬虫之航班数据获取----代码
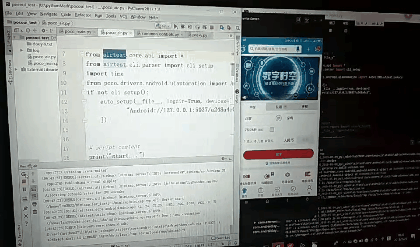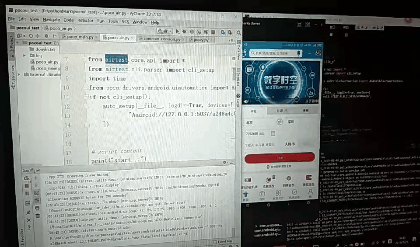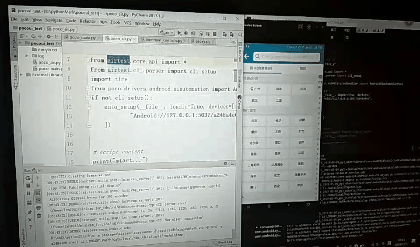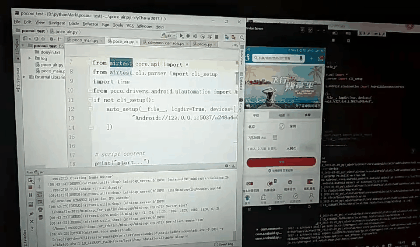
如何在pycharm中写代码并运行
如何将此代码脱离AirTest IDE运行,
1.首先要安装 pip install Airtest pip install pocoui 库;
2.安装adb驱动具体方法见https://blog.csdn.net/m0_37696990/article/details/96982615
3.将在AirTest创建py文件默认生成的那一部分代码拷贝到pycharm中,然后开始写代码代运行即可;


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









