







1.这里就不介绍二叉树的相关概念,如,树高度,节点层数,节点度数,路径,叶节点,分支节点,根节点,父节点,左节点,右节点,兄弟节点,祖先节点,子孙节点,左子树,右子树等基本概念
2.二叉树的分类
(1).斜树
斜树:所有的结点都只有左子树的二叉树叫左斜树。所有结点都是只有右子树的二叉树叫右斜树。这两者统称为斜树。
左斜树:

右斜树:

(2).满二叉树
国际标准定义是除了叶结点外每一个结点都有左右子结点的二叉树。
国际定义满二叉树:

注意:这里的定义与国内某些教材的定义不同,国内的定义是:除了叶结点外每一个结点都有左右子叶且叶子结点都处在最底层的二叉树。很显然,按照这个定义,上面的图示二叉树就不是满二叉下图是国内定义满二叉树:

满二叉树的特点有:
1)叶子只能出现在最下一层。出现在其它层就不可能达成平衡。
2)非叶子结点的度一定是2。
3)在同样深度的二叉树中,满二叉树的结点个数最多,叶子数最多。
(3).完全二叉树
完全二叉树:对一颗具有n个结点的二叉树按层编号,如果编号为i(1<=i<=n)的结点与同样深度的满二叉树中编号为i的结点在二叉树中位置完全相同,则这棵二叉树称为完全二叉树。

特点:
1)叶子结点只能出现在最下层和次下层。
2)最下层的叶子结点集中在树的左部。
3)倒数第二层若存在叶子结点,一定在右部连续位置。
4)如果结点度为1,则该结点只有左孩子,即没有右子树。
5)同样结点数目的二叉树,完全二叉树深度最小。
注:满二叉树一定是完全二叉树,但反过来不一定成立。
(4).平衡二叉树
是一棵空树或它的任意节点的左右两个子树的高度差的绝对值不超过1,这就是它的定义,并没有说关于排序的问题,所以平衡二叉树不一定是二叉pai xu sh
将二叉树节点的左子树的深度减去它的右子树的深度称为平衡因子BF,则平衡二叉树上所有节点的平衡因子只可能是-1、0和1。如果出现其他的平衡因子说明他不是一颗平衡二叉树


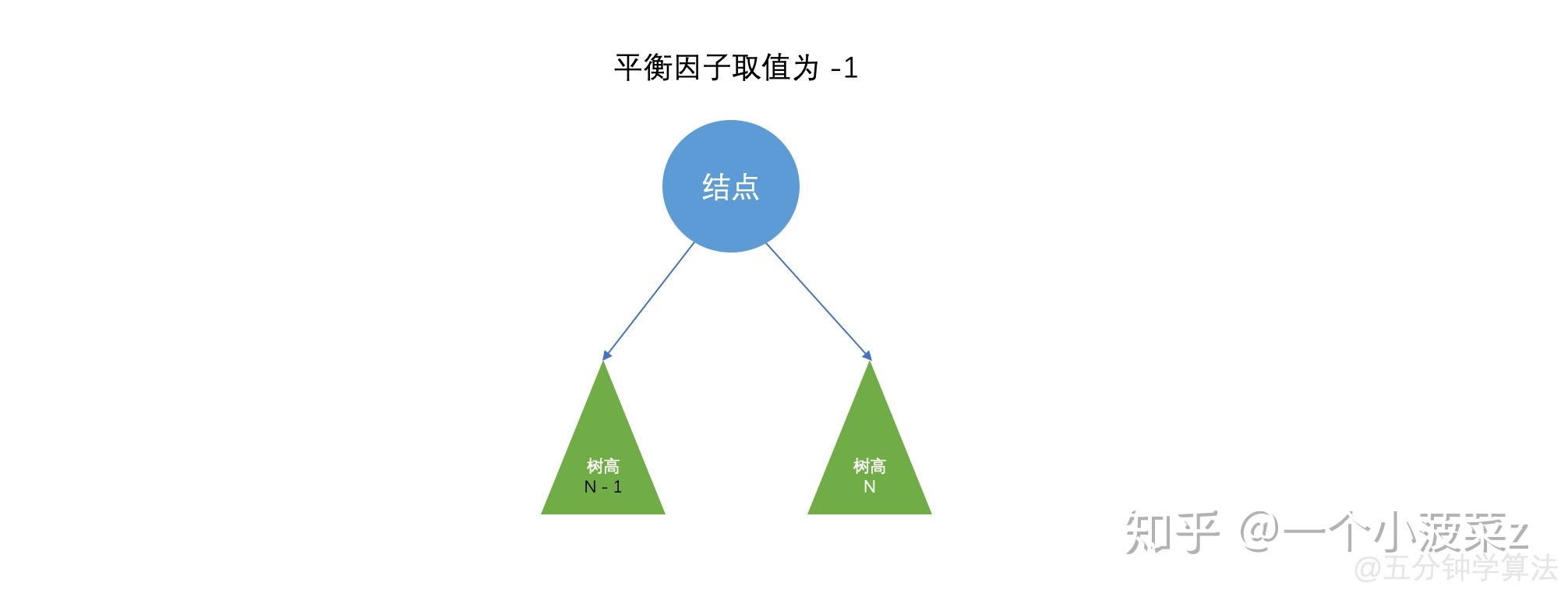
(5).二叉查找树又称二叉搜索树也叫二叉排序树

在二叉查找树中:
(01) 若任意节点的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
(02) 任意节点的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
(03) 任意节点的左、右子树也分别为二叉查找树。
(04) 没有键值相等的节点(no duplicate nodes)。
平衡二叉树和二叉排序树没有直接关系,平衡二叉树做到了每一个节点的左、右子树深度尽量相等,二叉排序树是一颗有排序关系的树,当二叉排序树出现极端情况比如斜树,它的查找速度会比较慢趋向于O(n),如果二叉排序树和平衡二叉树结合起来保证有排序关系的情况下做到左右子树平衡,这样查找的速度会较快趋向于O(log2N log以2为底n的对数,因为以几为底不影响数量级所以大家都写成logN log以10为底N的对数简写),二者结合起来就是平衡二叉排序树AVL树。
(6).AVL树
AVL树是根据它的发明者G.M. Adelson-Velsky和E.M. Landis命名的。它是最先发明的自平衡二叉查找树,也被称为高度平衡树。
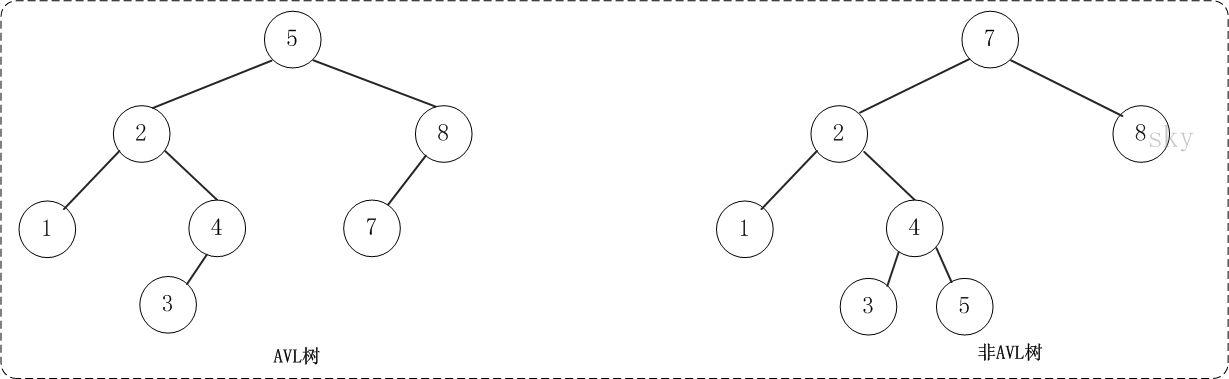
上面的两张图片,左边的是AVL树,它的任何节点的两个子树的高度差别都<=1;而右边的不是AVL树,因为7的两颗子树的高度相差为2(以2为根节点的树的高度是3,而以8为根节点的树的高度是1)。
AVL树的查找、插入和删除在平均和最坏情况下都是O(logn)。
如果在AVL树中插入或删除节点后,使得高度之差大于1。此时,AVL树的平衡状态就被破坏,它就不再是一棵二叉树;为了让它重新维持在一个平衡状态,就需要对其进行旋转处理。学AVL树,重点的地方也就是它的旋转算法;
在所有的不平衡情况中,都是按照先 寻找最小不平衡树,然后 寻找所属的不平衡类别,再 根据 4 种类别进行固定化程序的操作。
AVL树应用:
由于维护这种高度平衡所付出的代价比从中获得的效率收益还大,故而实际的应用不多,更多的地方是用追求局部而不是非常严格整体平衡的红黑树.当然,如果应用场景中对插入删除不频繁,只是对查找要求较高,那么AVL还是较优于红黑树.
Windows NT内核中广泛存在.
AVL树详解:
(7).红黑树
R-B Tree,全称是Red-Black Tree,又称为“红黑树”,它一种特殊的二叉查找树。红黑树的每个节点上都有存储位表示节点的颜色,可以是红(Red)或黑(Black)。
红黑树的特性:
(1)每个节点或者是黑色,或者是红色。
(2)根节点是黑色。
(3)每个叶子节点(NIL)是黑色。 [注意:这里叶子节点,是指为空(NIL或NULL)的叶子节点!]
(4)如果一个节点是红色的,则它的子节点必须是黑色的。 [注意:可以出现父节点和子节点都是黑色]
(5)从一个节点到该节点的子孙节点的所有路径上包含相同数目的黑节点。
注意:
(01) 特性(3)中的叶子节点,是只为空(NIL或null)的节点。
(02) 特性(5),确保没有一条路径会比其他路径长出俩倍。因而,红黑树是相对是接近平衡的二叉树。
红黑树的应用:
红黑树的应用比较广泛,主要是用它来存储有序的数据,它的时间复杂度是O(lgn),效率非常之高。
- 广泛用于C++的STL中,map和set都是用红黑树实现的.
- 著名的linux进程调度Completely Fair Scheduler,用红黑树管理进程控制块,进程的虚拟内存区域都存储在一颗红黑树上,每个虚拟地址区域都对应红黑树的一个节点,左指针指向相邻的地址虚拟存储区域,右指针指向相邻的高地址虚拟地址空间.
- IO多路复用epoll的实现采用红黑树组织管理sockfd,以支持快速的增删改查.
- ngnix中,用红黑树管理timer,因为红黑树是有序的,可以很快的得到距离当前最小的定时器.
- Java集合中的TreeSet和TreeMap和hashMap树化为红黑树,C++ STL中的set、map,以及Linux虚拟内存的管理,都是通过红黑树去实现的。
红黑树详解:
3.二叉树的遍历
分为:深度优先遍历和广度优先遍历
深度优先遍历分为:
1).先序遍历
递归实现:
public void preOrder(TreeNode<T> k1){
if (k1 != null){
System.out.printf(k1.key + " ");
preOrder(k1.left);
preOrder(k1.right);
}
}循环实现:
public void PreOrder(TreeNode<T> Node) {
if (Node == null) {
System.out.println("null");
return;
}
Stack<AVLTreeNode<T>> stack = new Stack<>();
while (Node != null || !stack.isEmpty()) {
if (Node != null) {
System.out.print(Node.key+" ");
stack.push(Node);
Node = Node.left;
} else {
Node = stack.pop();
Node = Node.right;
}
}
}2).中序遍历 二叉排序树的中序遍历就是排序
递归实现:
public void midOrder(TreeNode<T> k1){
if (k1 != null){
mOrder(k1.left);
System.out.printf(k1.key + " ");
mOrder(k1.right);
}
}循环实现:
和先序遍历本质是一样的,都是先从根结点把左边遍历到头并且保存下来为了回溯用,注意下面的处理:拿到栈顶的元素,并且栈顶元素出栈,打印栈顶元素的数值,然后看栈顶元素有没有右孩子,如果有的话就重复上面的步骤(这个右孩子相当于一个新的根节点),如果没有就继续出栈
我们一步一步分析:
1.先把左边遍历到头并且保存下来回溯用,无论先、中、后序,一定是先左,所以先把左边遍历到头,要保存下来是因为左边的元素既是父亲节点的左,又是右孩子的中,我们遍历右孩子的时候需要用到这些左边节点
2.遍历到头之后,就直接打印这个最左边的元素,因为中序遍历是左、中、右,这个最左边的元素
最多有一个右孩子,它既是父亲节点的左,又是右孩子节点的中,所以直接打印
3.栈顶元素出栈,并把当前节点赋值为栈顶元素的右孩子:因为栈顶元素已经打印完毕,它的作用除了打印,就是找到它的右孩子,我们是靠栈来回溯节点的,如果打印完了不出栈,回溯的时候就会重复。
4.现在当前节点是右孩子,如果右孩子是null说明这个分支已经遍历完成了,我们就回溯到上层继续出栈,如果右孩子不为null,这时候我们需要重复步骤1(就像把这个右孩子当作一个根结点一样)
public void midOrder(AVLTreeNode<T> Node) {
if (Node == null) {
System.out.println("null");
return;
}
Stack<AVLTreeNode<T>> stack = new Stack<>();
while (Node != null || !stack.isEmpty()) {
if (Node != null) {
stack.push(Node);
Node = Node.left;
} else {
Node = stack.pop();
System.out.print(Node.key+" ");
Node = Node.right;
}
}
}3).后续遍历
递归实现:
public void lastOrder(TreeNode<T> k1){
if (k1 != null){
lastOrder(k1.left);
lastOrder(k1.right);
System.out.printf(k1.key + " ");
}
}循环实现:
后序遍历是左右中,先从根结点遍历左边的元素,一直遍历到最左边的元素同时用栈保存用于后面的回溯,然后判断这个最左边的元素有没有右孩子,有右孩子就重复上面的步骤遍历右孩子左边的元素一直遍历到最左边同时保存,如果没有右孩子,才打印并且出栈。
上面的方法有一个漏洞,当没有右孩子时打印并且出栈之后,回溯到上一个元素,上一元素从头执行这段逻辑的时候会重复,为什么中序遍历不会重复,本质在于中序遍历是左、中、右,每个节点就只有打印和寻找下层节点的责任,所以可以在打印完后先pop然后再去管右孩子,这样下次回溯的时候会直接回到上上层,而且只用以上上层的右孩子去重复开始的步骤(代码逻辑保证了左孩子不会重复,即左孩子只会入栈一次),这样就不存在重复打印的问题,然而后序遍历不行,后序遍历的顺序是左、右、中,后序遍历需要先管右再管中,就造成了打印完右孩子之后只能回溯到上一层,而上一层的右孩子还是刚才打印的那个节点,这样就造成了重复。
如何解决这个重复问题呢?
我们先明确一点,所有的节点都是先入栈,然后再从栈中出栈,所以我们只要保证每个元素只入栈一次,这样就能解决重复的问题。
还有一点就是,在回溯的过程中发现重复的节点了,说明已经打印过那个重复节点,这种情况就继续pop回溯。
public void LastOrder(AVLTreeNode<T> Node) {
if (Node == null) {
System.out.println("null");
return;
}
Stack<AVLTreeNode<T>> stack = new Stack<>();
while (Node != null || !stack.isEmpty()) {
if (Node != null && Node.canPush) { //保证只入栈一次
stack.push(Node);
Node.canPush = false; //保证只入栈一次
Node = Node.left;
} else if (!stack.isEmpty()){
//重复只会在这个else分支重复,因为上面我们直接左边循环到头,
//else分支里Node = Node.right都是处理的右孩子,所以重复是只有在回溯的时候重
//复,而且只是重复右孩子
Node = stack.peek(); //不能用pop因为需要先输出右再输出中
Node = Node.right;
if (Node == null || !Node.canPush){
//Node == null 右孩子为null,栈顶元素就是当前分支最右的那个节点,或者是光杆司
//令没有左孩子(或者是左孩子已经打印过)也没有右孩子的中间节点,可以直接打印
//!Node.canPush 这就是有右孩子时,打印了右孩子后,回溯到上一层,右孩子
//就是这个Node重复了,这时候就需要继续回溯取栈顶元素并且打印出来,当前节点赋值为
//回溯的这个栈顶元素继续重复循环步骤
Node = stack.pop();
System.out.print(Node.key + " ");
}
}
if (stack.isEmpty()){
break;
}
}
}既然我们分析了,只有在回溯的时候重复,而且只重复右孩子,那我们换一种写法:
public void lastOrder() {
AVLTreeNode<T> Node = mRoot;
AVLTreeNode<T> pre = null;
if (Node == null) {
System.out.println("null");
return;
}
Stack<AVLTreeNode<T>> stack = new Stack<>();
while (Node != null || !stack.isEmpty()) {
if (Node != null && Node != pre) { //如果已经回溯过,就不让进栈
stack.push(Node);
Node = Node.left;
} else if (!stack.isEmpty()){
Node = stack.peek();
Node = Node.right;
if (Node == null || Node == pre){
Node = stack.pop();
System.out.print(Node.key + " ");
pre = Node; //记录上一个回溯的节点
}
}
if (stack.isEmpty()){
break;
}
}
}广度优先遍:
层序遍历:
1).第一种:
public void lastOrder() {
AVLTreeNode<T> Node = mRoot;
AVLTreeNode<T> pre = null;
if (Node == null) {
System.out.println("null");
return;
}
Stack<AVLTreeNode<T>> stack = new Stack<>();
while (Node != null || !stack.isEmpty()) {
if (Node != null && Node != pre) {
stack.push(Node);
Node = Node.left;
} else if (!stack.isEmpty()){
Node = stack.peek();
Node = Node.right;
if (Node == null || Node == pre){
Node = stack.pop();
System.out.print(Node.key + " ");
pre = Node;
}
}
if (stack.isEmpty()){
break;
}
}
}2).第二种:
public void levelOrderTraverse() {
AVLTreeNode<T> Node = mRoot;
if (Node == null) {
System.out.println("null");
return;
}
Queue<AVLTreeNode<T>> queue = new LinkedList<AVLTreeNode<T>>();
queue.add(Node);
while (!queue.isEmpty()) {
AVLTreeNode<T> node = queue.poll();
System.out.print(node.key + " ");
if (node.left != null) {
queue.add(node.left);
}
if (node.right != null) {
queue.add(node.right);
}
}
}已知两种遍历顺序,还原二叉树:
技巧就是通过前序遍历或者后序遍历确认根节点(包括子树的根节点),通过中序遍历来分左右子树,所以必须已知中序遍历顺序和前序或者后序其中一种遍历顺序,如果只有前序和后序不能还原一颗二叉树。
例如:若一棵二叉树的前序遍历为ABCDEF,中序遍历为CBAEDF,请画出这棵二叉树。
我们用技巧试试,通过前序遍历来确认根节点,根结点是A。通过中序遍历分树CB是根节点A的左子树,EDF是右子树。然后再通过前序遍历找出CB这颗左子树的根是B,然后再用中序遍历以B为根分树,C是B的左子树。同理EDF的根为D,以D分树E为左子树,F为右子树。
后序遍历类似
4.二叉树查找:
1).递归查找
public AVLTreeNode<T> inquiry(AVLTreeNode<T> Node,T key){
if (Node == null){
return null;
}
int compare = key.compareTo(Node.key);
if (compare > 0){
return inquiry(Node.right,key);
}else if (compare < 0){
return inquiry(Node.left,key);
}else {
return Node;
}
}2).非递归查找
public AVLTreeNode<T> inquiry1(AVLTreeNode<T> Node,T key){
while (Node != null){
int compare = key.compareTo(Node.key);
if (compare > 0){
Node = Node.right;
}else if (compare < 0){
Node = Node.left;
}else {
return Node;
}
}
return null;
}5.树的最大值、最小值、前驱和后继
1).最大值
该节点右子树的最右边那个节点
private AVLTreeNode<T> maximum(AVLTreeNode<T> tree) {
if (tree == null)
return null;
while (tree.right != null)
tree = tree.right;
return tree;
}2).最小值
该节点左子树的最左边的那个节点
private AVLTreeNode<T> minimum(AVLTreeNode<T> tree) {
if (tree == null)
return null;
while (tree.left != null)
tree = tree.left;
return tree;
}3).前驱
前驱:中序遍历该节点的前面那个节点
public BSTNode<T> predecessor(BSTNode<T> x) {
// 如果x存在左孩子,则"x的前驱结点"为 "以其左孩子为根的子树的最大结点"。
if (x.left != null)
return maximum(x.left);
// 如果x没有左孩子。则x有以下两种可能:
// (01) x是"一个右孩子",则"x的前驱结点"为 "它的父结点"。
// (01) x是"一个左孩子",则查找"x的最低的父结点,并且该父结点要具有右孩子",找到的这个"最低的父结点"就是"x的前驱结点"。
BSTNode<T> y = x.parent;
while ((y!=null) && (x==y.left)) {
x = y;
y = y.parent;
}
return y;
}4).后继
后继:中序遍历该节点的后面那个节点
public BSTNode<T> successor(BSTNode<T> x) {
// 如果x存在右孩子,则"x的后继结点"为 "以其右孩子为根的子树的最小结点"。
if (x.right != null)
return minimum(x.right);
// 如果x没有右孩子。则x有以下两种可能:
// (01) x是"一个左孩子",则"x的后继结点"为 "它的父结点"。
// (02) x是"一个右孩子",则查找"x的最低的父结点,并且该父结点要具有左孩子",找到的这个"最低的父结点"就是"x的后继结点"。
BSTNode<T> y = x.parent;
while ((y!=null) && (x==y.right)) {
x = y;
y = y.parent;
}
return y;
}














 704
704











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









