










有一天傍晚,在陪孩子看完一集又一集的动画片《超级飞侠》的时候,我发现每集的主人公性别不是有规律的,然后就无聊的想统计一下男性和女性的性别,就是想知道《超级飞侠》有没有间接暗示小孩子时候那个性别更爱订包裹(我是有多无聊)。那说干就干吧。
五季的《超级飞侠》一共有104集,我不可能单纯的每集去看一遍统计一下,就算在播放每集的时候滑动进度条就浪费时间,而且没会员的话还有广告时间。
不过还好,我知道有些网站有文字剧情介绍,那不如收集文字信息呢。然后从文字信息中得知每集订购包裹主角的性别啦。信息怎么获取,爬虫???如果你用爬虫那我想说没什么必要了,因为这种文字剧情一般都是几集几集连在一起的,只需要“ctrl+C”和“ctrl+V”的骚操作就能在几十秒的时间收集完成。虽然在百度百科上收集到了我想要的文字剧情,可惜只有前三季的(其他网站也未提供)。估计几年后可能会有人百度百科网页上添加文字剧情信息吧,以后再说吧。
得到前三季文字信息之后,我不想让自己去一个一个的看然后有笔去统计,我用来“百度云”提供的中文分词功能来提取人物名称,然后自己再去训练一个由名称识别性别的分类器来帮我识别性别(有这时间不如自己拿笔去统计呢)。
我的菜鸟思路
先收集文字剧情信息,然后用百度云api提取文字中人物姓名,然后用姓名性别识别器来得到每集人物性别,最后统计男女比列。
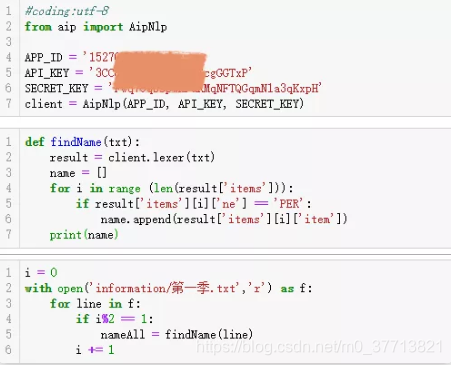
即使是百度云也不能想我们人脑一样可以从文字信息中获得人物名称,第一季的文字信息就有两集没有识别到,而且还统计到了《超级飞侠》中飞机们的姓名,因此我们需要除去飞机的姓名。
![]()
加一行代码,凡是得到的人名中有上面那些名字都不要(估计漏了个别飞机名字)。再优化一下代码去除相同名称的。
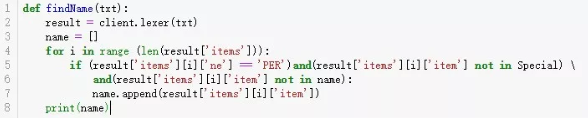
优化结果如下:

发现结果每集中存在多个名字,再看一下数据集分析发现。文字剧情中出现的第一个姓名是我们所要的姓名,所以我们只存取第一个姓名。然后再做一下姓名性别分类器,拿一下第一季第一集的“阿佳斯”做测试,得到结果是男性。然后查看一下文字剧情确认一下,看样子是个男生呀!


最后初略得到了三季78集中的59个人物姓名,然后分类得到34个男性和25个女性。分类器正确率是80%左右,我大概得到:在小时候,男孩子比女孩子更爱购物(剁--手)。
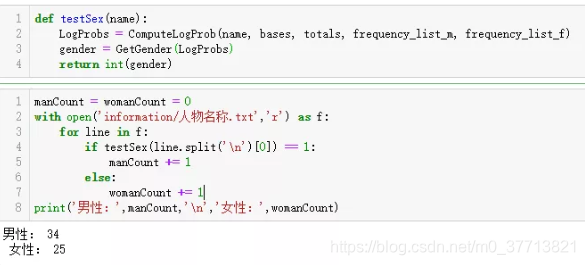
小结一下
真实的结果真的是这样吗??我想说不一定,因为这里面存在不少对数据集错误的清洗操作。例如:
如果你曾经认真陪过孩子看《超级飞侠》,你应该知道有的时候订购的包裹不一定是孩子订购的,而是孩子的父母。所以对于这些噪点数据,我们不能一个一个处理,不然那样就失去了数据挖掘的意义了。
尽管很少但还是有个别剧情是连集的,这种情况我们有可能多统计重复一个人名。
所以我们在做数据挖掘过程中,绝大部分时间都不是花在挑选合适算法和训练分类器(调参大法),而是用在了数据清洗上,数据清洗的效果也是能够一定程度上影响分类器的正确率的。
最后再说一个问题,在调用百度的NLP的接口时,我发现返回的结果中有将地方名称当作人名反馈给我。因为在西方历史文化中有些人物姓名是部分地区的地方名,例如美国第一任总统乔治·华盛顿 是美国首部的名称。所以现在的NLP技术真的很难达到我们人脑识别的正确率,但它高效率及低错误率我们还是愿意接受的。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









