









本文专注在简化应用的部署过程,并不包含需要对应用重新设计的内容,比如高可用和横向扩展。
概念
什么是“传统”应用?
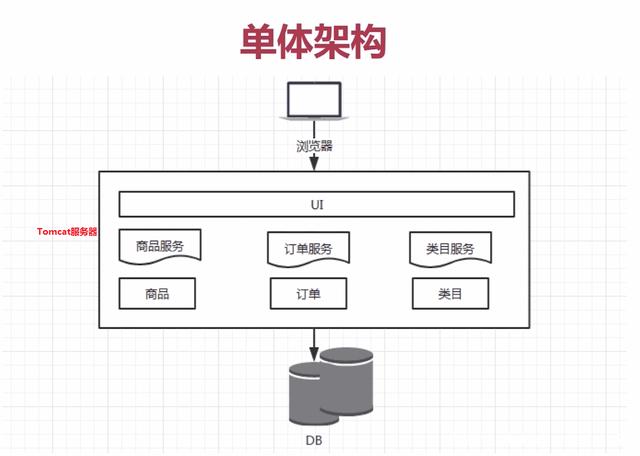
并没有一个特定的定义能够描述所有的传统应用,但它们有一些共同的特性:
使用本地文件系统来持久化存储,数据文件和应用的文件混合在一起。
在同一个服务器上运行很多服务,比如 MySQL 数据库,Redis 服务器,nginx web 服务器,一个 Ruby on Rails 应用,以及一大堆定时任务
使用大杂烩式的脚本和手工流程进行安装和升级(文档也很简陋)。
配置是存储在文件里的,通常散落在多个位置,并与应用的文件混在一起。
进程间的通信是借助本地文件系统进行的(比如在磁盘上放一个文件,另一个进程来读取),而不是TCP/IP。
按照单个服务器上只运行一个应用的示例的方式来设计的。
传统应用的缺点
自动化部署很困难。
如果需要运行应用的多个不同的实例,很难让多个实例在同一个服务器上“共存”。
如果服务器停机,由于需要手工操作所以需要较长的时间来恢复。
部署新版本的过程基本是手动的,或者大部分是手动的,难以回滚。
很有可能测试环境与生产环境有较大差异,导致一些生产环境问题不能在测试期间发现。
很难通过增加新的实例来进行横向扩展。
什么是容器化?
将应用“容器化”的过程,就是让应用能够运行在 Docker 容器或类似技术中,它们能将操作系统环境和应用封装在一起(完整的应用+系统镜像)。由于容器能给应用提供近似于完整系统的环境,这就为在不修改,或者少量修改应用的情况下,对应用的部署进行现代化改造提供了一种思路。这也是应用的架构持续能保持“云有好”的基础。
容器化的好处
部署容易多了:使用新的容器镜像直接替换整个老版本。
自动化部署也相对容易,甚至可以完全由 CI(Continuous Integration, 持续集成)来驱动。
部署失败时的回滚只要切换到之前的镜像。
应用升级非常容易,因为现在没有可能出错的“中间步骤”了(不管它是否影响整个部署过程的成功)。
相同的容器镜像可以在不同的环境中充分测试,再直接部署到生产环境。这可以确保测试态与生产态的产品是完全一致的。
系统更容易从宕机中恢复,因为可以迅速在新硬件资源上启动装有这个应用的新容器,并附加到同一数据源上。
开发人员能在本地以容器的形式,在更逼真的环境里测试新功能。
硬件资源的利用更高效,在单一主机上现在可以运行多个容器应用,而以前不能。
容器化是支持零停机升级、金丝雀部署、高可用和横向扩展的坚实基础。
容器化之外的选择
用 Puppet 和 Chef 之类的配置管理工具,能解决一部分的“传统”问题,比如环境一致性等。但它们不能支持“原子”部署,以及对应用+环境的完整回滚。而一种无法方便回滚的部署方案,仍然会在部署中途充满风险。
虚拟机镜像是能实现部分上述能力的另一种方法,而且在有些情形中,相对于容器,使用完整的虚机进行“原子地”部署会更合适。但使用虚机的主要问题是,它对硬件的利用率更低效。因为虚机需要一些独占的资源(CPU、内存和磁盘等),而容器之间可以共享主机的资源。
如何容器化
一、准备工作
列出存储数据的文件系统位置
由于部署新版本应用是通过替换 Docker 镜像实现的,所以任何持久化的数据都应该存储在容器之外。如果运气不错的话,可能遇到应用已经将所有数据都写入了特定位置,不过多数传统应用常将它们的数据往磁盘上到处乱写,还有可能与应用本身的文件混在一起。Docker 的持久化存储卷(volume)让主机的文件系统能暴露给容器用作特定路径,这样数据可以在容器之间共享。
现在你可以考虑让应用里所有输出的数据写入到文件系统的同一目录去了,这样能明显简化容器化版本的部署工作。不过,如果确实不好实现,这一步也并不是必须的。
找出会随部署环境变化的配置数据
为了确保一致性,同一个镜像要在多套环境中使用(比如,测试和生产),因此必须要列出所有在不同环境中会变化的配置值,在启动容器时再设置值。容器中应用启动时可以从环境变量,或者从配置文件中获取这些配置的值。
你可以现在就考虑修改应用并支持从环境变量中读取配置,以便简化容器化的过程。同样的,如果不好修改应用,这也不是必须的
找出容易移出去的服务
在同一机器上,我们的应用可能要依赖一些其他服务,它们如果独立性比较高、使用 TCP/IP 通信,就很容易能移出去。举例来说,如果在同一机器上运行 MySQL 或 PostgreSQL 数据库,或者类似 Redis 的缓存,那就容易移出去了。有时还需要调整配置,才能支持指定机器名(hostname)和端口(port)而不是直接认为应用运行在 localhost。
二、创建容器镜像
创建用于安装应用的 Dockerfile
如果已经有基于脚本或者 Chef、Puppet 之类的配置管理工具的自动化安装能力,那这个过程就很简单了。挑选一个喜欢的系统镜像、安装所有依赖,然后运行自动化脚本就行了。
如果目前的安装过程是手动的,就需要写一些自动化脚本了。不过,由于镜像是静态文件,因此在编写脚本要比基于可能存在不一致性的原生系统来的容易。
如果提前找出了要移出去的服务,那么在脚本里就不应该安装它们了。
下面是一个简单的示例 Dockerfile:
# 基于官方 Ubuntu 16.04 Docker 镜像
FROM ubuntu:16.04
# 安装所依赖的 Ubuntu 软件包
RUN apt-get install -y <REQUIRED UBUNTU PACKAGES> \
&& apt-get clean \
&& rm -rf /var/lib/apt/lists/*
# 将应用的文件复制到镜像里
ADD . /app
# 运行安装脚本
RUN /app/setup.sh
# 切换到应用的目录
WORKDIR /app
# 指定应用的启动脚本
COMMAND /app/start.sh
制作用于配置的启动脚本
如果应用已经在使用环境变量中读取配置值了,那这一步可以跳过了。如果要从文件里读取特定环境相关的配置值,那启动脚本就要能从环境变量里读取配置值,并将这些值更新到配置文件中去。
这里有一个启动脚本的例子:
#!/usr/bin/env bash
set -e
# 把环境变量 $MYAPPCONFIG 的值添加到配置文件中
cat >>/app/config.txt <<END
my_app_config = "${MYAPPCONFIG}"
END
# 用环境变量 $MYAPPARG 作为应用的启动参数
/app/bin/my-app --my-arg="${MYAPPARG}"
推送镜像至镜像仓库
镜像生成之后(使用 docker build),需要推送到 Docker 仓储(Registry)中才能从部署机器上拉取到(如果要在生成镜像的同一台机器上运行,就不需要)。
可以使用 Docker Hub 来存储镜像(用付费账号可以创建私有仓库),大多数云服务商也提供容器仓储(比如 Amazon ECR)。
给镜像设置标签(比如 docker tag myimage mycompany/myimage:mytag)之后,就可以推送到仓库了(比如 docker push mycompany/myimage:mytag)。每次在应用新版本生成镜像时打上新的标签,这样既能明确当前所运行的版本,还能保留旧版本的镜像以便回滚。
三、如何部署
部署容器是个很大的话题,接下来只关注直接使用 docker 命令运行容器的部分。实际生产环境中,应该考虑使用 docker-compose(对于所有容器都运行在同一机器上的简单情形)和 Kubernetes (在集群中编排容器)之类的工具。
被移出来的服务
提前移出来的服务可以运行在单独的 Docker 容器中,然后链接(link)到我们的应用所在容器。另外,还可以用云上托管的服务。
举个例子,在 AWS 上,可以使用 RDS 作为数据库、用 Elasticache 作为缓存,这样可以极大地简化你的工作,因为他们能为你解决后期维护,高可用和备份等需求。
运行 Postgres 数据库容器的例子:
docker run -d \
--name db \
-v /usr/local/postgresql/data:/var/lib/postgresql/data \
postgres
容器化之后的应用
要在 Docker 容器中运行一个应用,只要用一个命令行:
docker run -d \
-p 8080:80 \
--name myapp \
-v /usr/local/myappdata:/var/lib/myappdata \
-e MYAPPCONFIG=myvalue \
-e MYAPPARG=myarg \
--link db:db \
myappimage:mytag
-p 参数将容器里的 80 端口公开并映射到主机上的 8080 端口,
-v 参数设置要在容器里加载的、用于持久化数据的存储卷(格式是 主机上的路径:容器中的路径)
-e 参数设置一个用于配置的环境变量值(这些参数可以指定多次,从而设置多个卷和环境变量),
--link参数将数据库所在容器以链接的方式传入,这样应用就可以与数据库通信了。
容器会根据 Dockerfile 中的 COMMAND 指令指定的脚本来启动。
对应用进行升级
如果要升级到应用的新版本,只要停掉旧版的容器(比如 docker rm -f myapp),并用新的镜像标签启动新的容器就可以了(可能有短暂的停机时间)。回滚操作也类似,只要换用旧版的镜像标签。
更多相关知识点
“init” 进程(PID 1)
传统应用通常有多个进程,如果没有 “init” 守护进程(PID 1)的清理,就容易出现孤儿进程(orphan processes)发生累积的情况了。Docker 默认并不提供这样的守护进程,所以推荐自己用 ENTRYPOINT 在 Dockerfile 里添加一个。dumb-init 是众多初始守护进程中的比较轻量级的一个。phusion/baseimage 是一个包含 init 初始守护进程和其他一些服务的全功能基准镜像。
守护进程和定时任务
在使用 Docker 容器时,一般只会在每个容器中运行一个进程。理想情况下,所有守护进程和定时任务都应该移到其他容器中去,不过对于传统应用来,这也不一定都行得通,主要是经常要求对应用进行重新设计。要运行多个进程也不是一定不行,但确实会需要一些额外的一些配置,因为标准的基准镜像里并不包含进程管理和调度能力。小型进程管理程序,比如 runit,比 systemd 之类的完整功能的子系统更适合在容器中用。
存储卷的权限
在容器里,所有进程通常都以 root 身份运行(不过也不是必须的)。传统的应用对用户的需求通常复杂一些,可能要用其他用户来运行(或者用不同的用户运行多个进程)。这可能给存储卷的使用带来一些麻烦,因为 Docker 默认让加载的卷的所有权指向 root,也就是说非 root 进程就不能写入到这些卷了。有两个方法可以解决这个问题:
第一种方式是在在创建容器之前,先在主机上创建好目录,由有正确的 UID/GID 的用户持有所有权。注意,由于容器里和主机上的用户不能匹配,所以需要用容器里用户的 UID/GID,而不仅仅是用户名要一致。
另一种方式是在容器里,在启动过程中调整挂载点的所有权。这就需要在切换到非 root 用户之前,还在以 root权限调整挂载点目录的权限。
数据库迁移
数据库迁移在部署工作中经常是一大挑战,因为数据库结构通常与应用是紧密耦合的,这对迁移的时机提出了要求,而且这也让回滚到旧版本变得更难,因为数据库迁移并不一定容易回滚。
完成这种迁移的方法是引入一个过渡步骤。如果需要对数据库结构做出与旧版本不兼容的变更,那就将这个变更分为两次部署。比如,如果想将数据移到另一处,步骤是:
1.将数据同时写入旧的位置和的位置,并只从新的位置读取。这意味着,如果把应用回滚到前一个版本,在回滚之前新产生的新数据是不会丢的。
2.不再向旧的位置写入数据。 要注意的是,如果希望部署期间没有停机时间,就意味着在同一时间会有应用的多个版本在运行,相应的也会带来更多挑战。
数据备份
对容器化的应用进行备份通常比较简单。数据文件可以从主机上备份,而不需要担心数据会与应用程序的文件混在一起,因为它们已经进行过地分离。如果将数据库迁移到了像 RDS 这样的托管服务,他们就会处理好备份。
迁移已有数据
在生产环境中,要把现有状态应用进行迁移,就需要对旧的已有数据进行迁移,这个过程需要把数据备份直接恢复给新版本用。这个过程应该提前做好,也不可避免地会需要一定的停机时间。
结论
虽然提前需要做一些工作,但对传统的应用进行容器化后会帮助我们更好地对它进行自动化管理运维。它给对传统应用进行现代化改造提供了一个明确的方向,容器化后能支持零停机部署、高可用和横向扩展。
















 569
569











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











