







文章目录
一、流处理数据Sink到目的地的N种错误操作
pom.xml添加依赖:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.13</version>
</dependency>
在MySQL中创建wc表:
create table wc(
word varchar(20),
`count` int(10)
);
编写StreamingSinkApp.scala代码:
package com.huiq.test
import java.sql.DriverManager
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
object StreamingSinkApp {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf()
.setMaster("local[2]")
.setAppName("StreamingSinkApp")
val ssc = new StreamingContext(sparkConf, Seconds(5))
val lines = ssc.socketTextStream("hadoop001", 8999)
// lines.print()
// TODO... 需要将从socke端接收到的数据进行处理(WordCount)之后写入到MySQL中
val result = lines.flatMap(_.split(",")).map((_,1)).reduceByKey(_+_)
// 这是一种固定的开发模式,只要streaming输出数据到外部系统,都是按照这个套路来即可
result.foreachRDD(rdd => {
rdd.foreach(pair =>{
val connection = createConnection()
val sql = s"insert into wc(word,count) values('${pair._1}', ${pair._2})"
connection.createStatement().execute(sql)
connection.close()
})
})
ssc.start()
ssc.awaitTermination()
}
def createConnection() = {
Class.forName("com.mysql.cj.jdbc.Driver")
DriverManager.getConnection("jdbc:mysql://localhost:3306/database1", "root", "123456")
}
}
在服务器上用nc命令传输数据:
nc -lk 8999
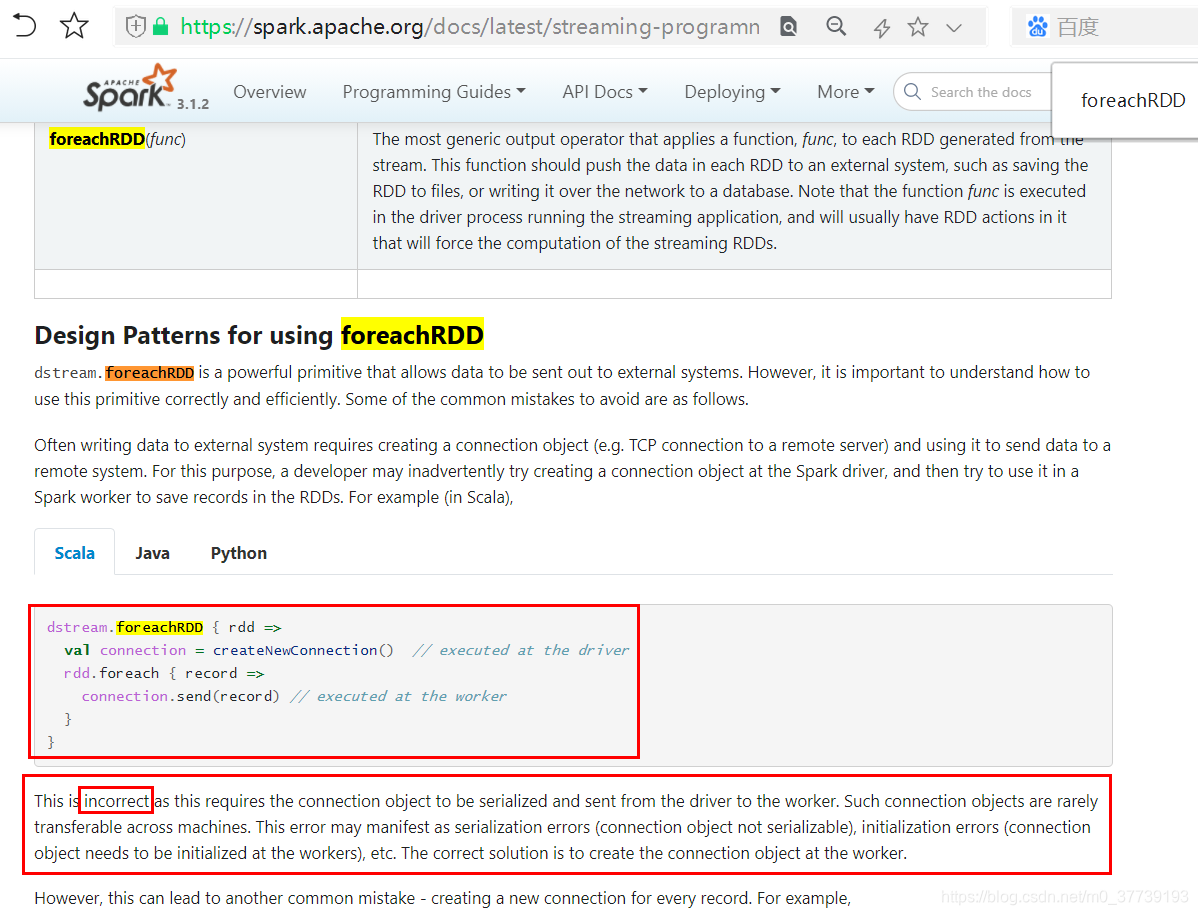
1.序列化异常:
如果上面的代码写成这样会报错:
result.foreachRDD(rdd => {
val connection = createConnection()
rdd.foreach(pair =>{
val sql = s"insert into wc(word,count) values('${pair._1}', ${pair._2})"
connection.createStatement().execute(sql)
connection.close()
})
})

参考官网:https://spark.apache.org/docs/latest/streaming-programming-guide.html
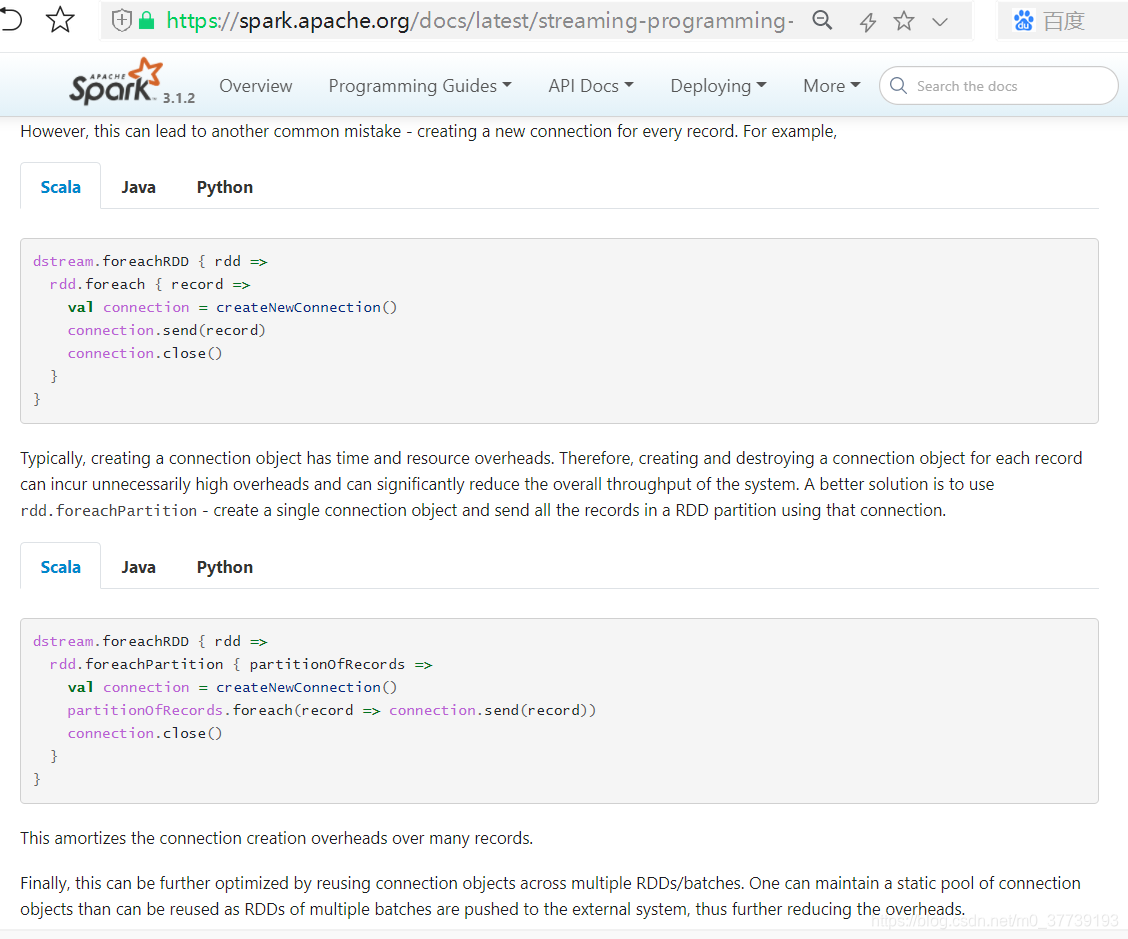
2.高性能写结果数据:
但是上面的代码性能好吗,看官网说明其实并不是很好:
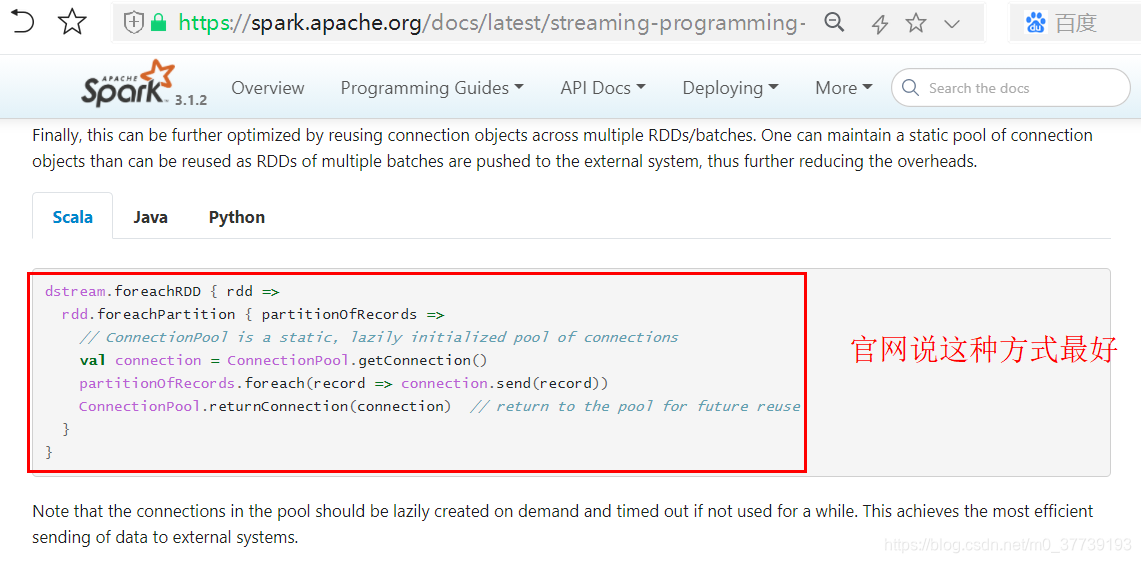
二、对接Kafka的方式
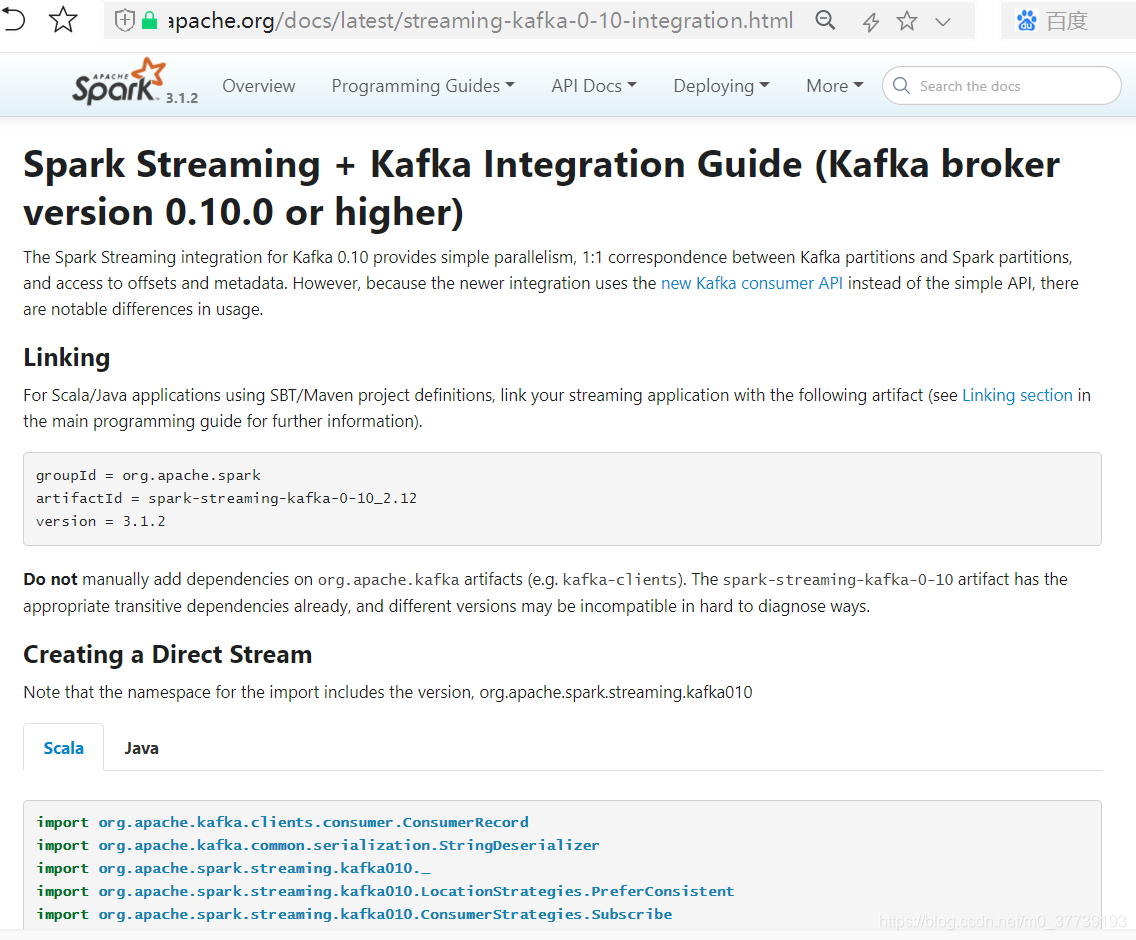
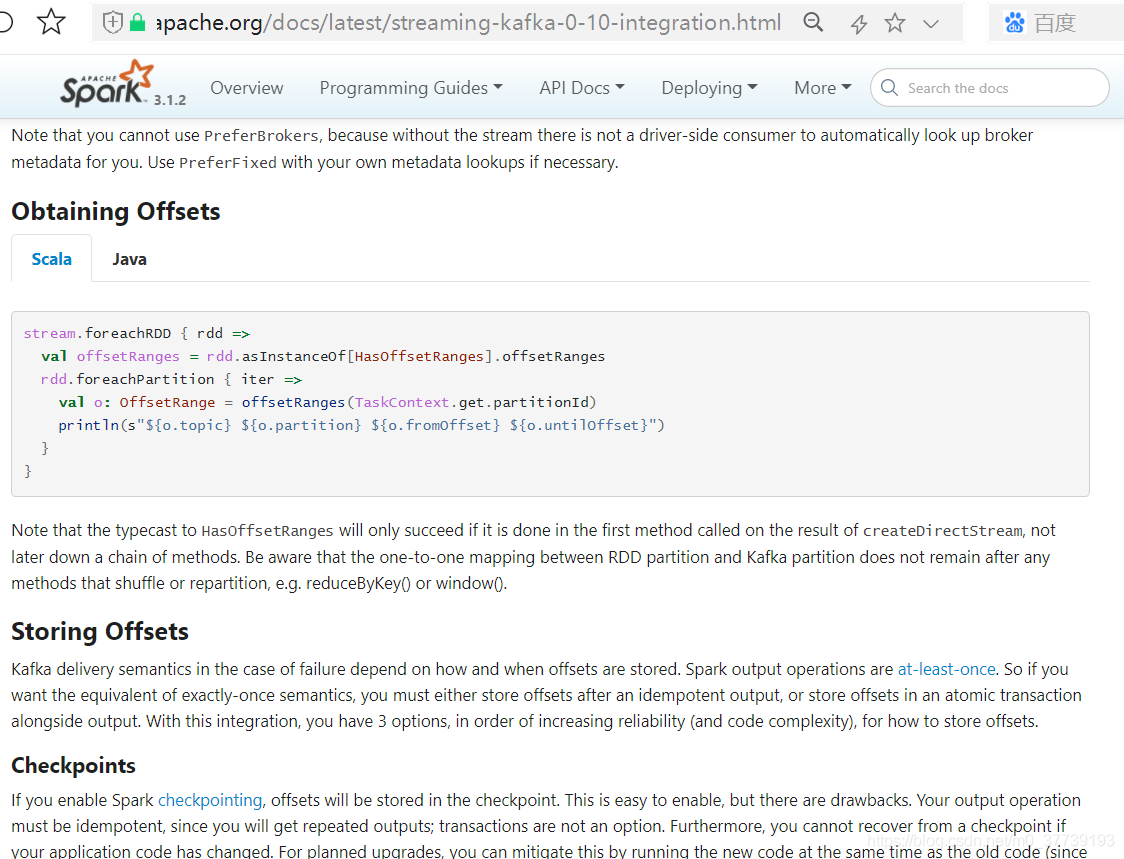
注:以前官网还有对Kafka 0.8版本(可能有的公司还在使用0.8版本)的对接方式,现在已经更新没有了。
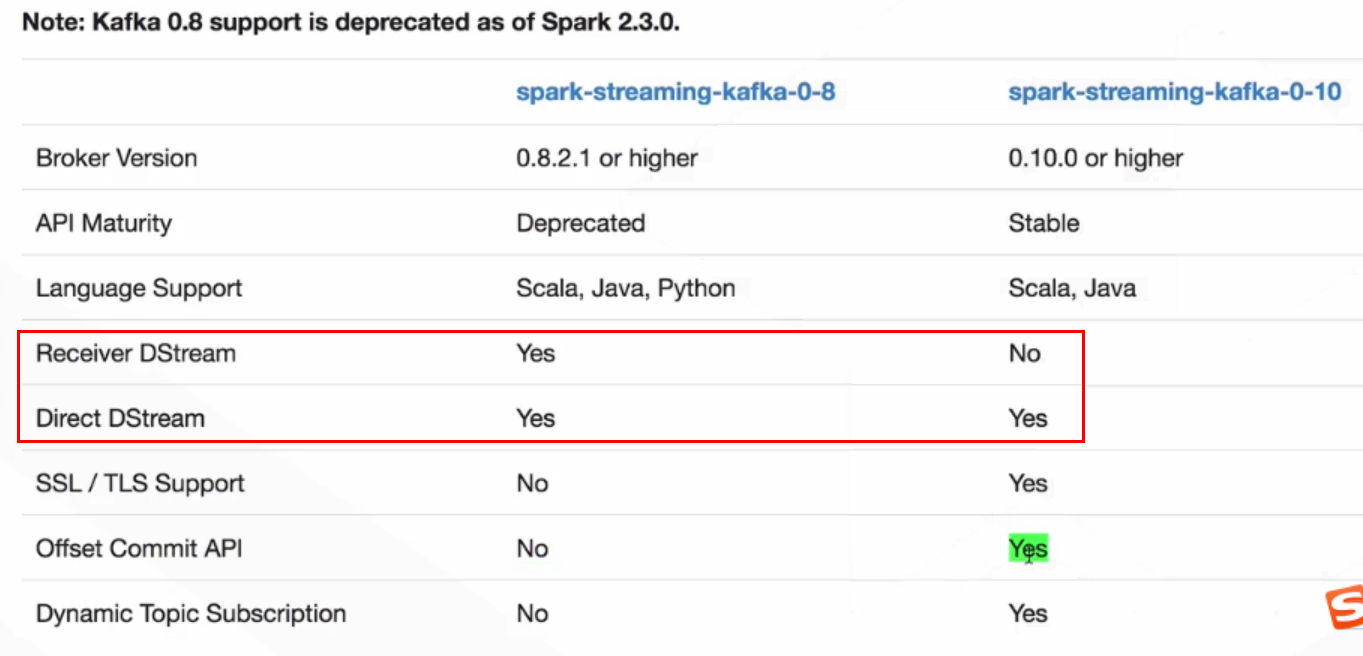
spark-streaming作为一个24*7不间断运行的程序来设计,但是程序都会crash,如果crash了,如何保证数据不丢失,不重复。spark streaming提供了两种streaming input source:
- basic source: Source directly avaliable in the StreamingContext API. Examples: file,socket connnection.
- advanced source: Source like kafka/kinesis, etc. are avaliable through extra utility classes.
这里只讨论高级数据源,因为针对流计算场景,基本数据源不适用。高级数据源,以kafka为例,kafka作为输入源,有两种方式:receive模式(开启WAL即预写日志,将从kafka中接受到的数据写入到日志文件中,所有数据从失败中可恢复)和direct 模式(依靠checkpoint机制来保证)。
1.Spark streaming消费kafka数据通过手动管理kafkaoffset保证实时流消费数据的一致性
第一点:需要明白 kafka 的底层机制及工作原理,这里只简要说明,详细的参考 kafka 官网。kafka 是将每一条写入 kafka 的数据按分区分布存储,将每条写入的数据作一个 offset 标记,这个标记的顺序是按插入数据自增的。当消费程序的时候,会按照分区区分,逐个根据 offset 顺序消费。当在消费数据时,如果将自动提交 offset 参数设置为 true(enable.auto.commit=true),那么不管消费数据的结果是否正确,只要消费数据程序没有因为异常而中断,kafka 都会讲数据的 offset 信息按照分区组合的方式存在依赖的 zookeeper上。反之当 enable.auto.commit=false 时,消费程序及时消费结果正确,程序没有中断都不会提交 offset,需要程序手动提交 offset。举一个场景,如果消费程序没有出现异常,但消费数据的结果不对,应该是不提交 offset 的,当优化了流式消费程序,在启动消费程序,应该必须能消费到之前消费结果不对的数据。但是前者已经提交了 offset,没法拿到了。而后者能够很好的解决这个问题,提交与不提交 offset,由消费程序自己决定。
第二点:需要清楚spark的底层机制,这里做简要说明,详细的参考spark官网。spark在对数据进行分布式计算时(不管是流式还是离线批),都是将数据读成RDD,然后在对RDD进行spark自带算子计算和spark的方法API进行业务处理,而这两种本质上是一样的。这里以计算数据写入下游某个组件举例重点说方法API。一般情况下,spark都是将获取的数据RDD做如下操作:
- 先对rdd进行foreach得到每个Partition
- 在对每个Partition进行遍历得到Partition里面的数据,这里是一个迭代器(iterator),iterator里面就是实际每一条数据
rdd.foreachRDD(new VoidFunction<JavaRDD<String>>() {
@Override
public void call(JavaRDD<String> partition) throws Exception {
partition.foreachPartition(new VoidFunction<Iterator<String>>() {
@Override
public void call(Iterator<String> iterator) throws Exception {
while (iterator.hasNext()) {
String message = iterator.next();
}
});
}
});
明白一二两点后就需要思考 spark streaming 消费 kafka 数据时如何保存数据一致性,怎样去保证。这里其实不难,有两种方式:
第一种:将 spark 获取到的 kafka 数据转化成的 rdd 对应的 kafka 的 offset 全部拿出来,以 rdd 为实体,当 rdd.foreachRDD 整个无误后手动提交 offset。
第二种:在 rdd.foreachRDD 里面的 partition.foreachPartition 里面将每个 partition 对应的数据的 kafka 数据的 offset 查询出来,然后单个 partition 处理无误后提交单个 partition 对应的kafka数据的 offset。
第一种和第二种比较,他们的原理基本相同,第一种获取的 offset 其实也是第二种的数组,而第一种更加广义,第二种更加详细。
可能有读者会问,为什么不更加详细点,在 partition.foreachPartition 里面迭代每一条数据时,将每一条数据的 offset 获取出来,成功一条,提交该条对应的 offset。为什么不这样做,有一下三点原因:
- 分而治之,在保证数据质量的同时,要确保性能和其他指标,如果消费一条数据保存该数据的 offset,势必会带来性能的影响。而按照分区的方式,一个分区里面的每一条记录都消费成功,证明这个分区处理是无误的,则提交 offset。如果分区里的每一条和几条数据消费不成功,则认为该分区处理是不成功的,不提交 offset,待修复后再一次消费这个 partition 对应的 kafka 的 offset 数据,这样肯定会造成数据重复,但一定不会造成数据遗漏。而大数据处理中,数据重复从来不是问题。但数据遗漏是不被允许的。
spark streaming消费 kafka 数据的官方 api 中并没有这样的 api,而是将 partition 作为一个整体的到 offset 的信息。
参考:Spark streaming消费kafka数据通过手动管理kafkaoffset保证实时流消费数据的一致性
实操:
// 控制日志级别
Logger.getLogger("org.apache.spark").setLevel(Level.WARN);
SparkConf sparkConf = new SparkConf()
// .setMaster("local[*]")
.setAppName("SparkStreamingTest")
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.set("spark.driver.allowMultipleContexts", "true")
.set("spark.streaming.backpressure.enabled", "true"); // 是否开启反压
// 窗口间隔
JavaSparkContext sc = new JavaSparkContext(sparkConf);
// 设置调用时间5秒获取一批数据
JavaStreamingContext streamingContext = new JavaStreamingContext(sc, Durations.seconds(30));
// 从MySQL中读取该主题对应的消费者组的分区偏移量
Map<TopicPartition, Long> offsetMap = JDBCConnPool.getOffsetMap(groupId, topic);
JavaInputDStream<ConsumerRecord<String, String>> javaInputDStream;
//如果MySQL中已经存在了偏移量,则应该从该偏移量处开始消费
if (offsetMap.size() > 0) {
System.out.println("存在偏移量,从该偏移量处进行消费!!" + offsetMap);
// 存在偏移量,从该偏移量处进行消费
javaInputDStream = KafkaUtils.createDirectStream(
streamingContext,
LocationStrategies.PreferConsistent(),
ConsumerStrategies.<String, String>Subscribe(topics, kafkaParams, offsetMap));
} else {
System.out.println("不存在偏移量,从最早开始消费!!");
//如果MySQL中没有存在了偏移量,从最早开始消费
javaInputDStream = KafkaUtils.createDirectStream(
streamingContext,
LocationStrategies.PreferConsistent(),
ConsumerStrategies.Subscribe(topics, kafkaParams));
}
// kafka实时数据计算和保存HBASE
javaInputDStream.foreachRDD(rdd -> {
// 获取rdd中offset相关的信息:offsetRanges里面就包含了该批次各个分区的offset信息
OffsetRange[] offsetRanges = ((HasOffsetRanges) rdd.rdd()).offsetRanges();
// 循环分区, 处理 Kafka 消息
rdd.map(ConsumerRecord::value).foreachPartition(partitionRecords -> {
OffsetRange offset = offsetRanges[TaskContext.get().partitionId()];
long dataCount = offset.count();//数据总量
long successCount = 0;//写入成功总量
while (partitionRecords.hasNext()) {
String originalData = partitionRecords.next();
System.out.println("originalData-->"+originalData);
// ...
successCount++;
}
// 根据offset将数据的处理结果写到mysql表中,如果dataCount=0,证明这一批流没有数据,不需要写
if (dataCount > 0) {
long failedCount = dataCount - successCount;//写入失败总量
if (failedCount == 0) {
JDBCConnPool.saveOffsetPartition(groupId, offset);
}
}
});
});
streamingContext.start();
streamingContext.awaitTermination();
三、流处理过程的零数据丢失
当我们正确地部署好Spark Streaming,我们就可以使用Spark Streaming提供的零数据丢失机制。为了体验这个关键的特性,你需要满足以下几个先决条件:
- 输入的数据来自可靠的sources(数据源)和可靠的receivers(接收器);
- 应用程序的metadata被application的driver持久化了(checkpointed );
- 启用了WAL特性(Write ahead log)。
1.可靠的数据源和可靠的接收器:
对于一些输入数据源(比如Kafka),Spark Streaming可以对已经接收的数据进行确认。输入的数据首先被接收器(receivers )所接收,然后存储到Spark中(默认情况下,数据保存到2个执行器中以便进行容错)。数据一旦存储到Spark中,接收器可以对它进行确认(比如,如果消费Kafka里面的数据时可以更新Zookeeper里面的偏移量)。这种机制保证了在接收器突然挂掉的情况下也不会丢失数据:因为数据虽然被接收,但是没有被持久化的情况下是不会发送确认消息的。所以在接收器恢复的时候,数据可以被原端重新发送。
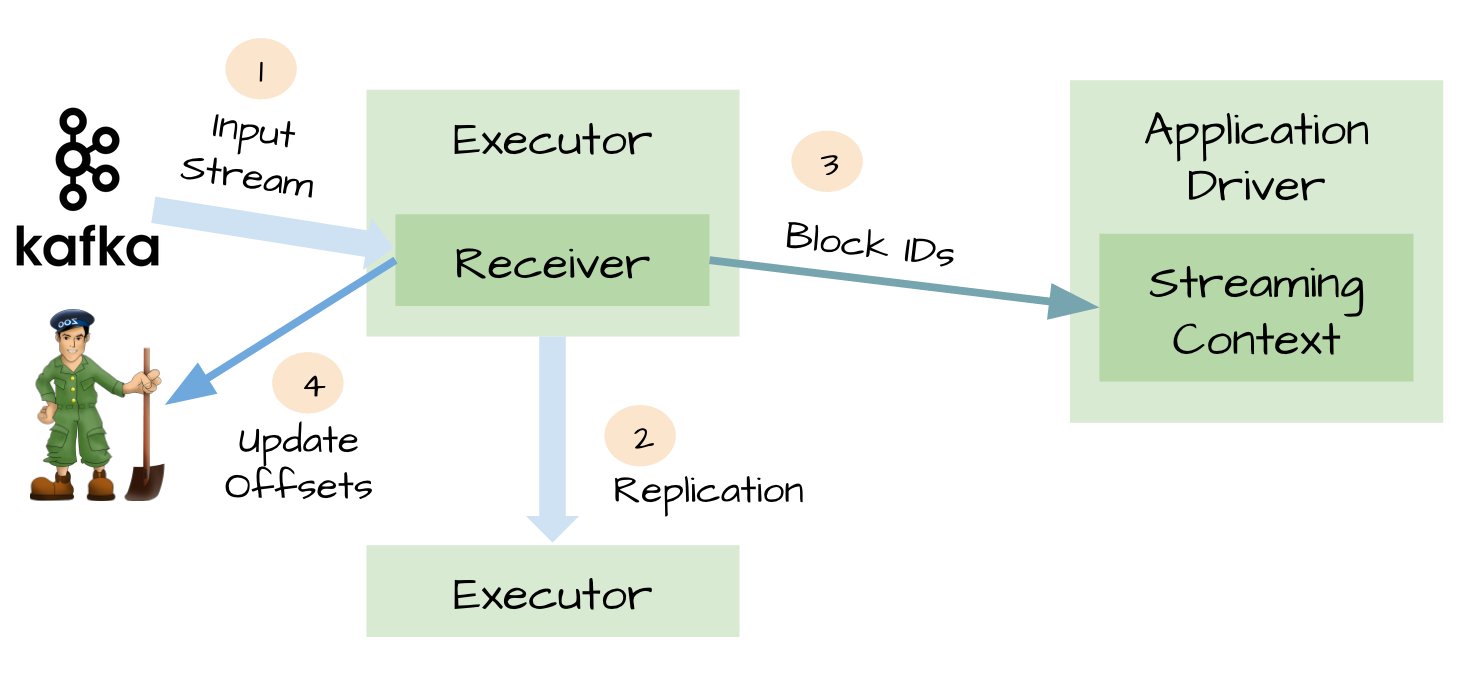
2.元数据持久化(Metadata checkpointing):
可靠的数据源和接收器可以让我们从接收器挂掉的情况下恢复(或者是接收器运行的Exectuor和服务器挂掉都可以)。但是更棘手的问题是,如果Driver挂掉如何恢复?对此开发者们引入了很多技术来让Driver从失败中恢复。其中一个就是对应用程序的元数据进行Checkpint。利用这个特性,Driver可以将应用程序的重要元数据持久化到可靠的存储中,比如HDFS、S3;然后Driver可以利用这些持久化的数据进行恢复。元数据包括:
- 配置;
- 代码;
- 那些在队列中还没有处理的batch(仅仅保存元数据,而不是这些batch中的数据)
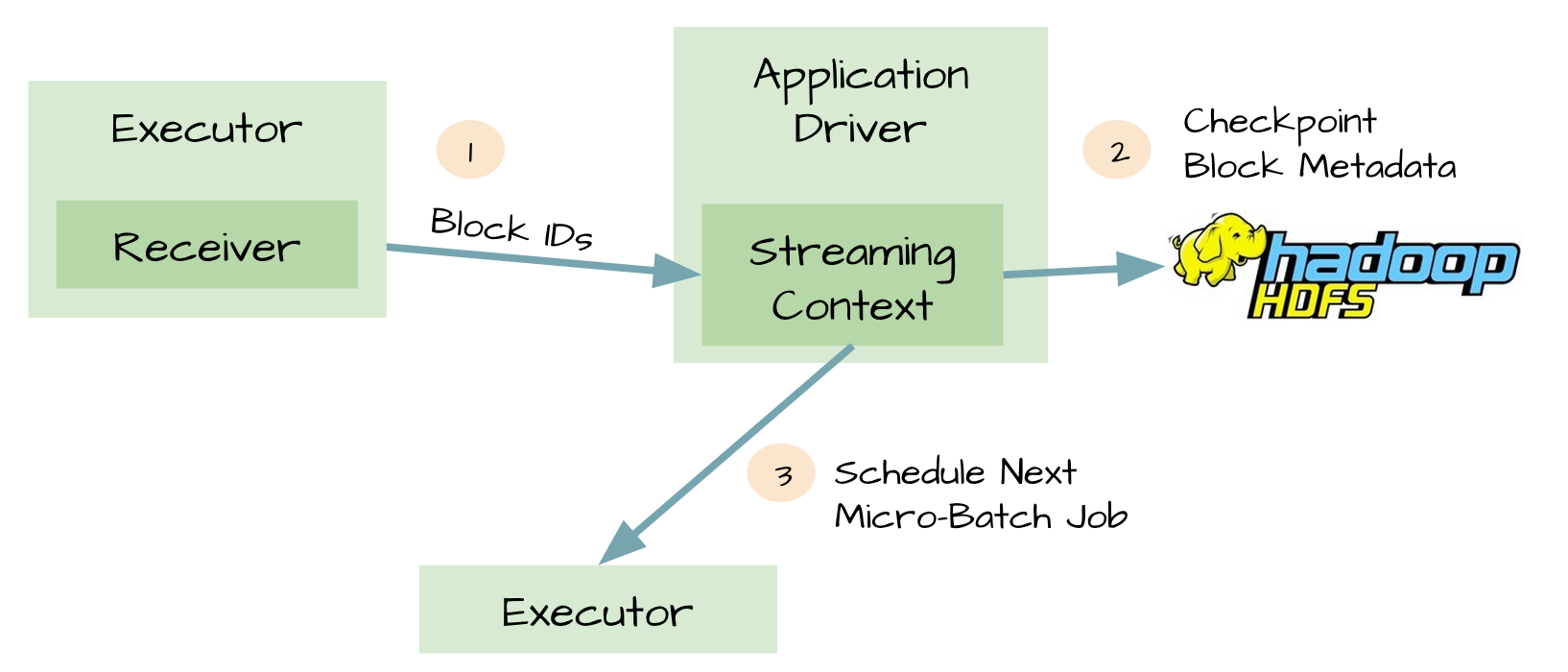
由于有了元数据的Checkpint,所以Driver可以利用他们重构应用程序,而且可以计算出Driver挂掉的时候应用程序执行到什么位置。
令人惊讶的是,即使是可靠的数据源、可靠的接收器和对元数据进行Checkpint,仍然不足以阻止潜在的数据丢失。我们可以想象出以下的糟糕场景:两个Exectuor已经从接收器中接收到输入数据,并将它缓存到Exectuor的内存中;接收器通知输入源数据已经接收;Exectuor根据应用程序的代码开始处理已经缓存的数据;这时候Driver突然挂掉了;从设计的角度看,一旦Driver挂掉之后,它维护的Exectuor也将全部被kill;既然所有的Exectuor被kill了,所以缓存到它们内存中的数据也将被丢失。结果,这些已经通知数据源但是还没有处理的缓存数据就丢失了;缓存的时候不可能恢复,因为它们是缓存在Exectuor的内存中,所以数据被丢失了。
这对于很多关键型的应用程序来说非常的糟糕。
3.WAL(Write ahead log):
为了解决上面提到的糟糕场景,Spark Streaming 1.2开始引入了WAL机制。
启用了WAL机制,所以已经接收的数据被接收器写入到容错存储中,比如HDFS或者S3。由于采用了WAl机制,Driver可以从失败的点重新读取数据,即使Exectuor中内存的数据已经丢失了。在这个简单的方法下,Spark Streaming提供了一种即使是Driver挂掉也可以避免数据丢失的机制。
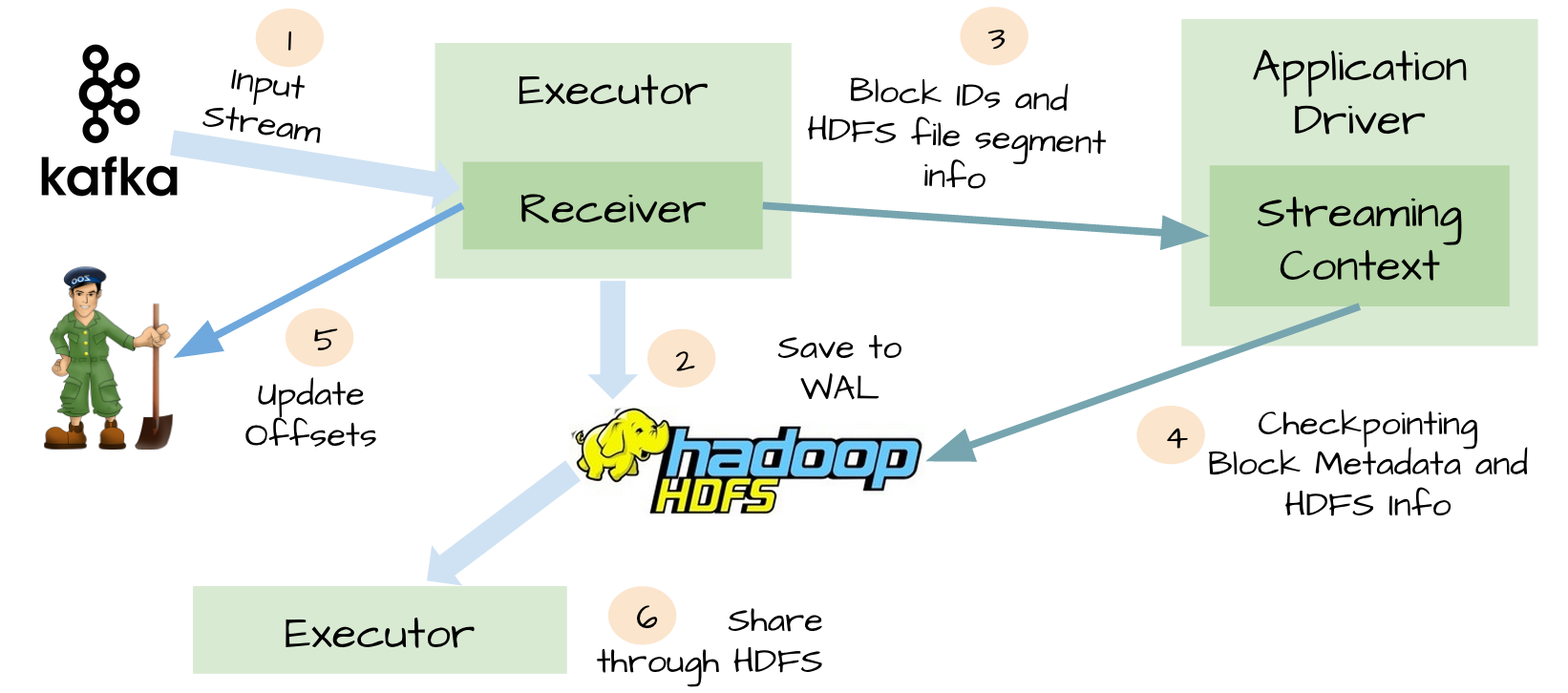
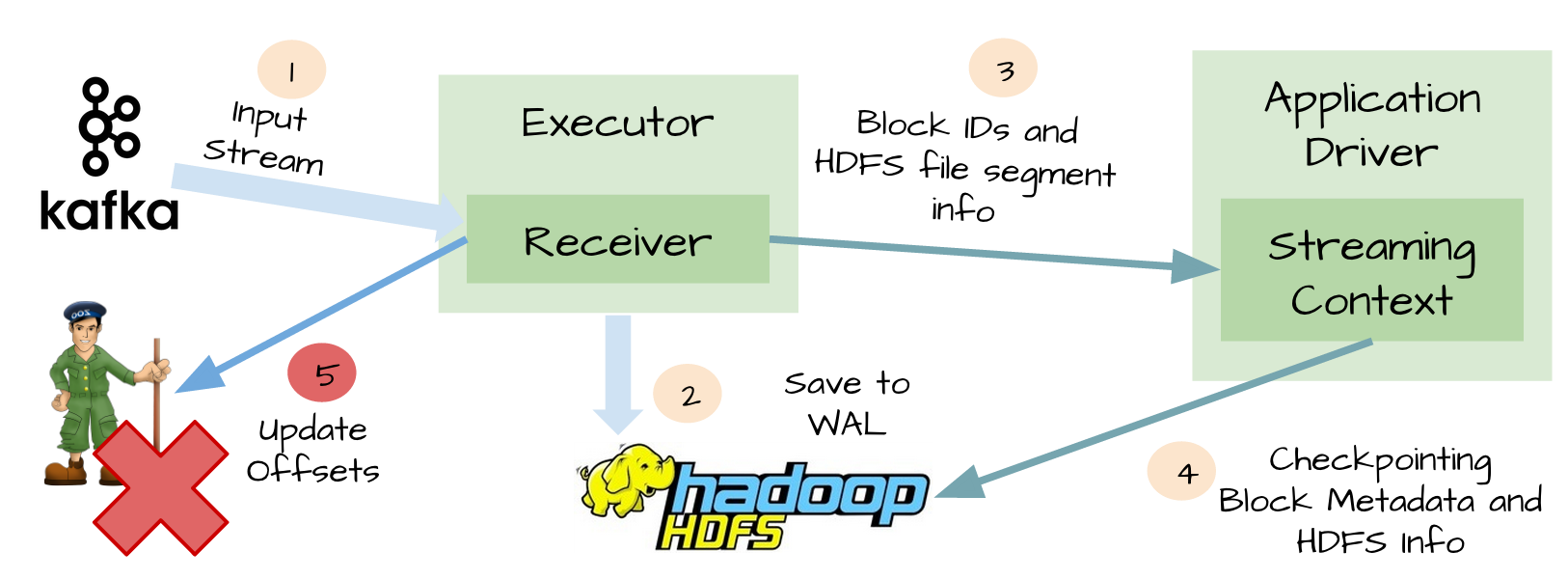
At-least-once语义:
虽然WAL可以确保数据不丢失,它并不能对所有的数据源保证exactly-once语义。想象一下可能发生在Spark Streaming整合Kafka的糟糕场景:接收器接收到输入数据,并把它存储到WAL中;接收器在更新Zookeeper中Kafka的偏移量之前突然挂掉了;Spark Streaming假设输入数据已成功收到(因为它已经写入到WAL中),然而Kafka认为数据没有被消费,因为相应的偏移量并没有在Zookeeper中更新;过了一会,接收器从失败中恢复;那些被保存到WAL中但未被处理的数据被重新读取;一旦从WAL中读取所有的数据之后,接收器开始从Kafka中消费数据。因为接收器是采用Kafka的High-Level Consumer API实现的,它开始从Zookeeper当前记录的偏移量开始读取数据,但是因为接收器挂掉的时候偏移量并没有更新到Zookeeper中,所有有一些数据被处理了2次。
WAL的缺点:
除了上面描述的场景,WAL还有其他两个不可忽略的缺点:WAL减少了接收器的吞吐量,因为接受到的数据必须保存到可靠的分布式文件系统中;对于一些输入源来说,它会重复相同的数据。比如当从Kafka中读取数据,你需要在Kafka的brokers中保存一份数据,而且你还得在Spark Streaming中保存一份。
4.Direct API:
为了解决由WAL引入的性能损失,并且保证 exactly-once 语义,Spark Streaming 1.3中引入了名为Direct API。
这个想法对于这个特性是非常明智的。Spark driver只需要简单地计算下一个batch需要处理Kafka中偏移量的范围,然后命令Spark Exectuor直接从Kafka相应Topic的分区中消费数据。换句话说,这种方法把Kafka当作成一个文件系统,然后像读文件一样来消费Topic中的数据。
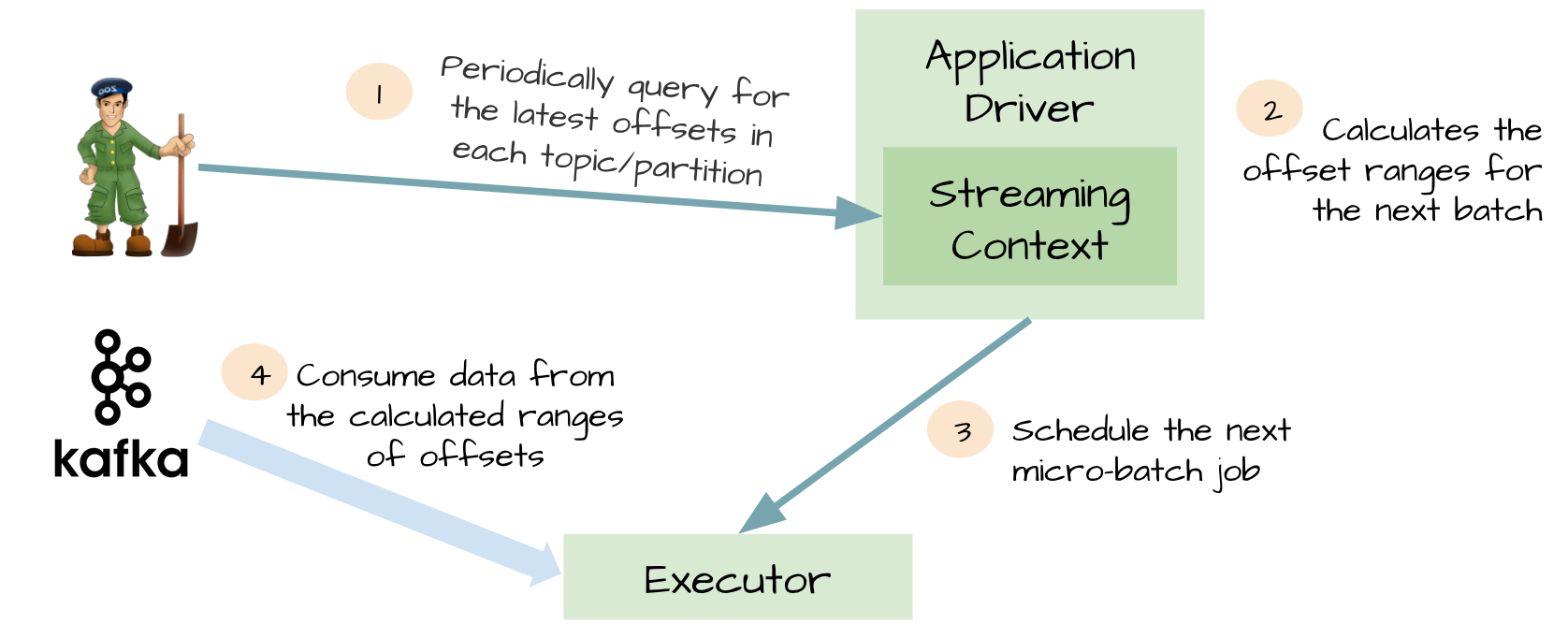
在这个简单但强大的设计中:不再需要Kafka接收器,Exectuor直接采用Simple Consumer API从Kafka中消费数据;不再需要WAL机制,我们仍然可以从失败恢复之后从Kafka中重新消费数据;exactly-once语义得以保存,我们不再从WAL中读取重复的数据。
综合以上,direct 模式比receive模式的优点:
- 简化并行读取:如果要读取多个partition,不需要创建多个输入DStream,然后对它们进行union操作。Spark会创建跟Kafka partition一样多的RDD partition,并且会并行从Kafka中读取数据。所以在Kafka partition和RDD partition之间,有一个一对一的映射关系。
- 高性能:如果要保证零数据丢失,在基于receiver的方式中,需要开启WAL机制。这种方式其实效率低下,因为数据实际上被复制了两份,Kafka自己本身就有高可靠的机制会对数据复制一份,而这里又会复制一份到WAL中。而基于direct的方式,不依赖Receiver,不需要开启WAL机制,只要Kafka中作了数据的复制,那么就可以通过Kafka的副本进行恢复。
- 一次且仅一次的事务机制:基于receiver的方式,是使用Kafka的高阶API来在ZooKeeper中保存消费过的offset的。这是消费Kafka数据的传统方式。这种方式配合着WAL机制可以保证数据零丢失的高可靠性,但是却无法保证数据被处理一次且仅一次,可能会处理两次。因为Spark和ZooKeeper之间可能是不同步的。基于direct的方式,使用kafka的简单api,Spark Streaming自己就负责追踪消费的offset,并保存在checkpoint中。Spark自己一定是同步的,因此可以保证数据是消费一次且仅消费一次。由于数据消费偏移量是保存在checkpoint中,因此,如果后续想使用kafka高级API消费数据,需要手动的更新zookeeper中的偏移量。
















 614
614











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











