







PyTorch-06 (过拟合&欠拟合、Train-Val-Test划分、Regularization减轻防止overfitting、动量与学习率衰减、其他技巧Tricks(Early Stop,Dropout))
一、过拟合&欠拟合
讨论过拟合和欠拟合之前,先了解一下数据真实的模态(即数据的真实分布):Pr(x)
讨论一下过拟合和欠拟合:
场景1 Scenario1: house price 房价
是一个线性模型:
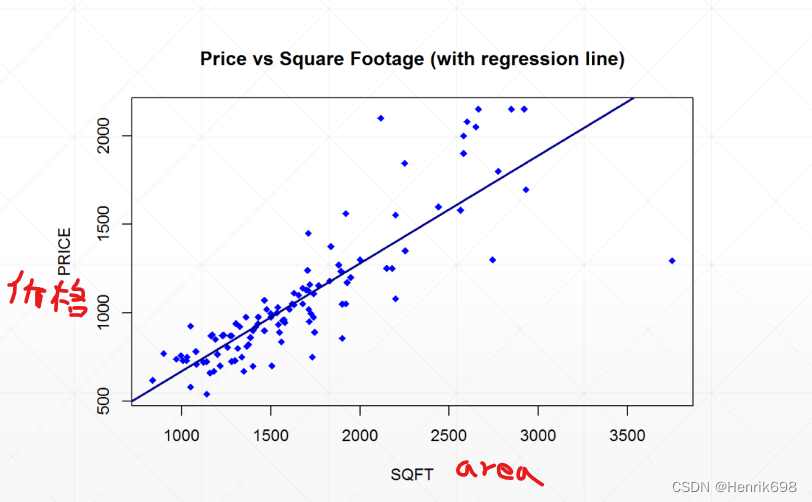
场景2 Scenario2: GPA
非线性模型:
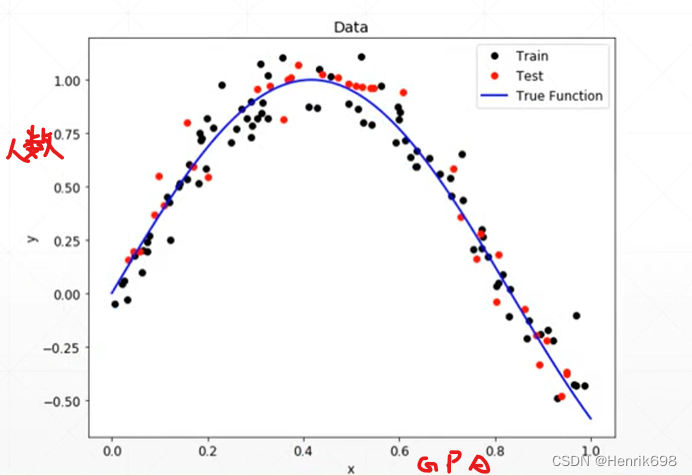
首先,对于上面两个图,我们知道真实的分布吗?The ground-truth distribution?
▪ That’s perfect if known 如果知道那就完美了
▪ However 我们是不知道的。
其次,另一个因素Another factor,噪声noise

对模型本身进行度量Let’s assume
对于高次方越高,则模型抖动越大,波形越复杂。
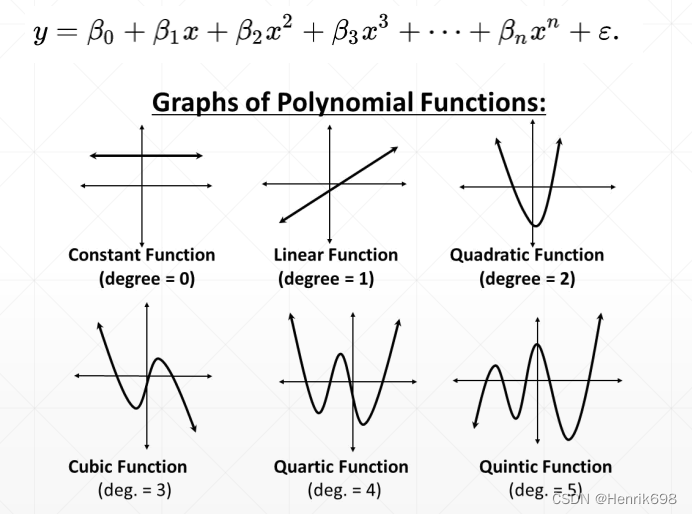
衡量不同模型的学习能力 Mismatch: ground-truth VS estimated
model capacity模型容量:

对于常数模型来说,学习能力非常的弱。
次方越高模型所表达的能力越强。
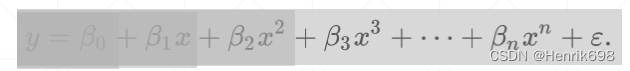
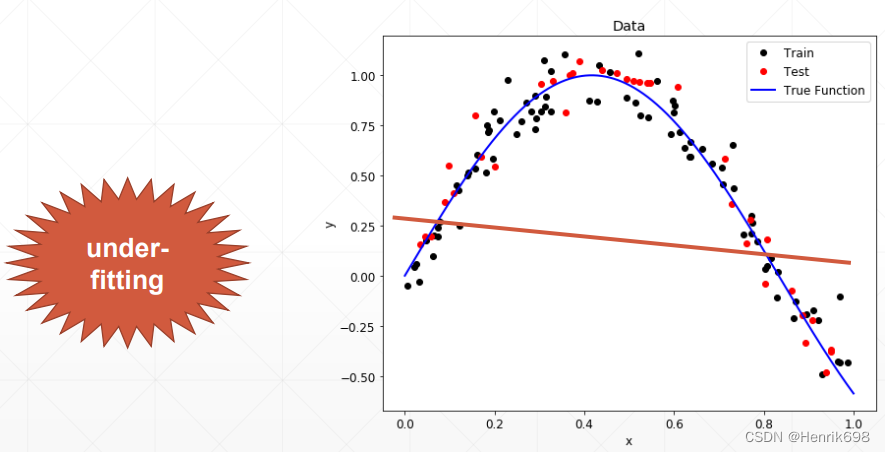
案例Case1: Estimated < Ground-truth(Underfitting)
Estimated 模型本身的capacity,即模型的表达能力。
当模型的表达能力<真实模型的复杂度,出现under-fitting的情况。
这种时候会造成我们模型的表达能力不够。
for example :WGAN
WGAN早期版本也是增加了一个约束,将模型的复杂度降低下来。

Underfitting:
发现不论是训练数据还是测试数据的loss、acc表现都不是很好的时候,尝试将模型复杂度增加一些(比如说堆叠更多的层数、每一层的单元数量会增加)。通过这种方式增加模型的复杂度后,查看Underfitting这种情况是不是有所改变。

案例Case2: Ground-truth < Estimated(Overfitting)
使用模型的复杂度>真实模型的复杂度
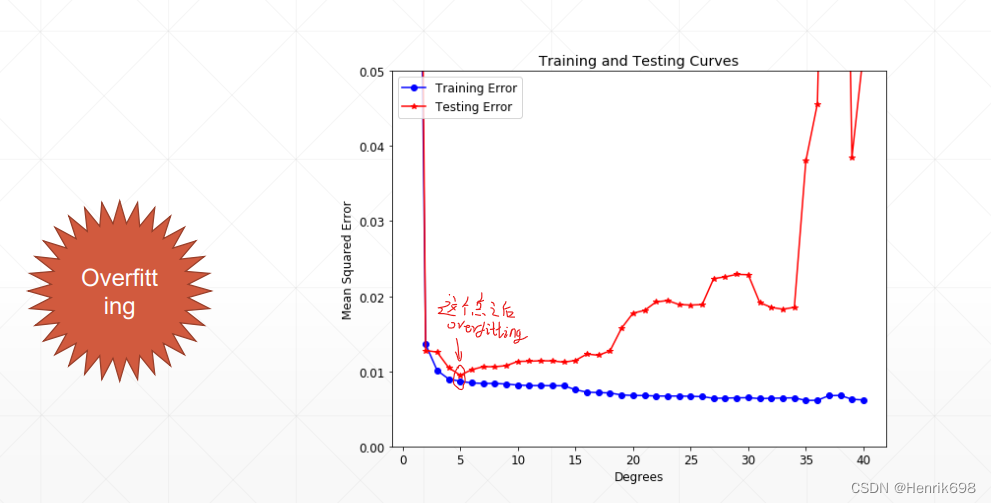
这样的情况在训练的时候,模型会尝试将模型每一个点的loss都降低。这样模型会逼近每一个点。这种情况会使得train的结果非常的好,但是test的结果会比较差。
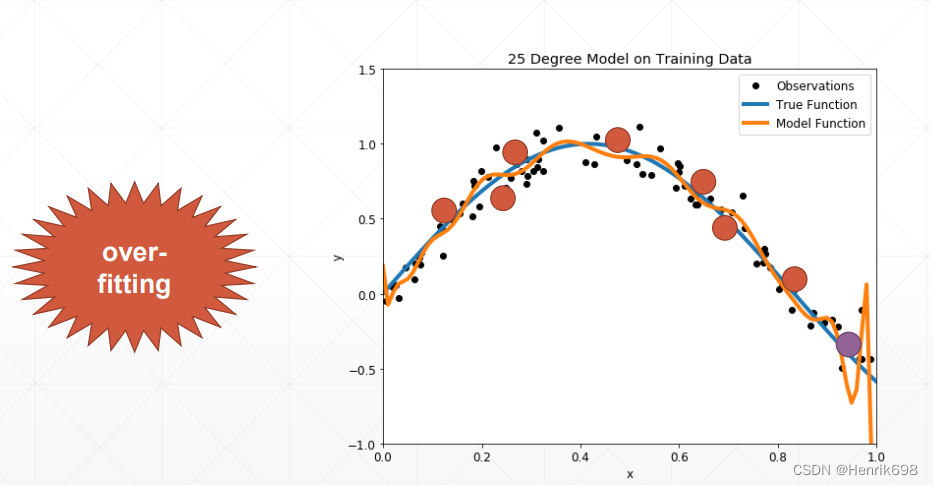
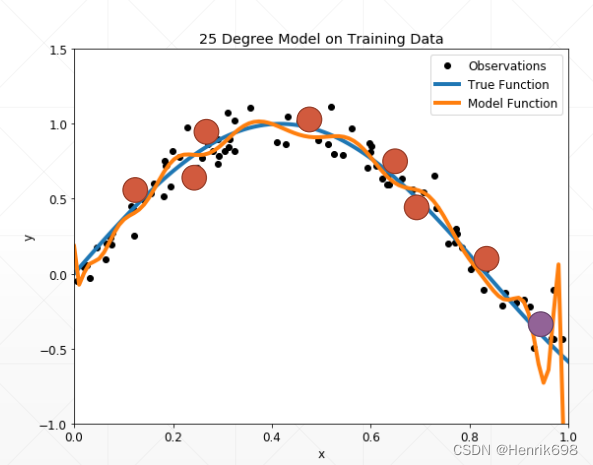
Overfitting:
▪ train loss and acc. is much better 训练模型的loss和acc都非常好。
▪ test acc. is worse 但是训练模型的loss和acc会很差。
▪ => Generalization Performance 泛化能力效果。
当Overfitting很严重的情况,泛化能力会很差。
本节总结
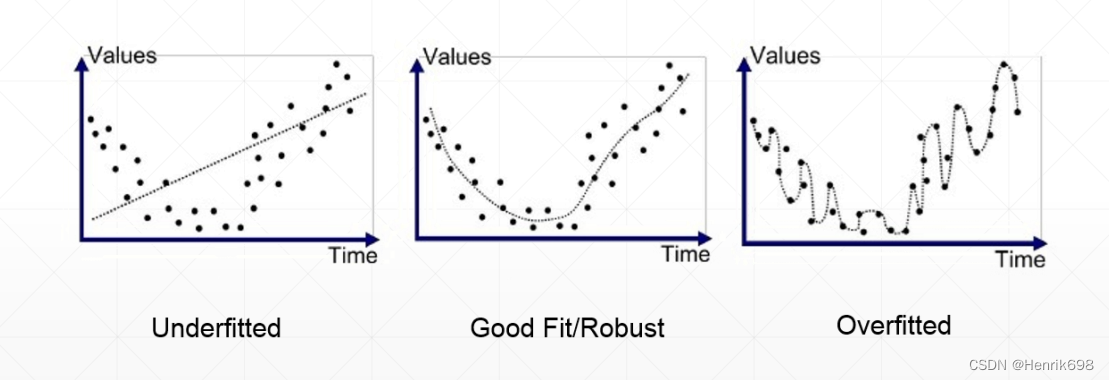
在现实生活中,大多数情况都是overfitting,因为现在计算机的计算能力很强,优化的网络复杂度会变得非常非常深,这样很容易网络的表达能力超过了现实模型的能力(数据集足够多,就不会overfitting,如果数据集有限的话,因为包含了噪声,这样就很容易overfitting),因此我们需要如何检测overfitting,并且降低overfitting的情况,下节会讲。
二、Train-Val-Test划分(交叉验证)
如何检测Overfitting
首先我们将数据划分为Train dataset 和 Test dataset
划分了之后,在train dataset进行training训练,在training的过程中就会去学习pattern,train dataset和test dataset都是来自同一个数据集,所以他们的真实分布肯定是一样的,当我们在train dataset上学习到了一个分布情况以后,我们要检测是不是overfitting,就需要用train dataset训练好的模型对test dataset进行loss和acc的检测,发现在train dataset表现很好,test dataset表现很差就是overfitting了。
源数据集的划分 splitting:

For example
另一种常用的对源数据的划分情况 splitting:数据集划分为三部
常用的划分splitting情况是划分三部分:新增了validation dataset,这时test dataset就不在是对模型进行挑选了。将原来test dataset换成了validation dataset。将挑选模型的功能给了validation dataset,而test dataset是交给客户,客户在验收的时候查看模型性能的表现。所以在Kaggle这样的比赛,主办方是不会将test set提供给我们的。


数据集划分为三部分如何划分:train-val-test
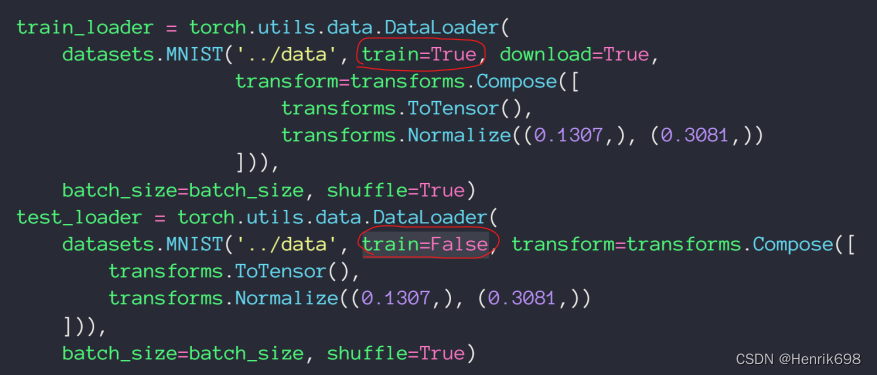
一般来说,现有的数据集只提供两个划分,一个是train一个是test。
通过参数train=True划分为train dataset,train=False划分为test dataset。
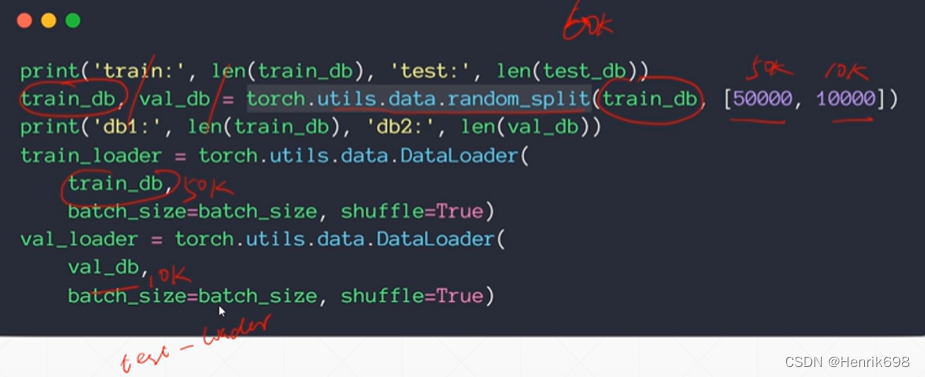
之后我们在train dataset 的基础上进行人为的划分:
假设train_db有60k个sample样本,将60k的样本数据划分为50k和10k。其中50k依然是train_db,10k就是val_db,再加上之前数据默认划分的test_db,这样就划分好了三部分。
for example:使用了三个的划分
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
batch_size=200
learning_rate=0.01
epochs=10
#将参数train=True
#获得train_db
train_db = datasets.MNIST('../data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
]))
train_loader = torch.utils.data.DataLoader(
train_db,
batch_size=batch_size, shuffle=True)
#将参数train=False
#获得test_db
test_db = datasets.MNIST('../data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
]))
test_loader = torch.utils.data.DataLoader(test_db,
batch_size=batch_size, shuffle=True)
print('train:', len(train_db), 'test:', len(test_db))
#再将train_db划分为train_db和val_db
train_db, val_db = torch.utils.data.random_split(train_db, [50000, 10000])
print('db1:', len(train_db), 'db2:', len(val_db))
train_loader = torch.utils.data.DataLoader(
train_db,
batch_size=batch_size, shuffle=True)
val_loader = torch.utils.data.DataLoader(
val_db,
batch_size=batch_size, shuffle=True)
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.model = nn.Sequential(
nn.Linear(784, 200),
nn.LeakyReLU(inplace=True),
nn.Linear(200, 200),
nn.LeakyReLU(inplace=True),
nn.Linear(200, 10),
nn.LeakyReLU(inplace=True),
)
def forward(self, x):
x = self.model(x)
return x
device = torch.device('cuda:0')
net = MLP().to(device)
optimizer = optim.SGD(net.parameters(), lr=learning_rate)
criteon = nn.CrossEntropyLoss().to(device)
for epoch in range(epochs):
#使用train_loader来做训练
for batch_idx, (data, target) in enumerate(train_loader):
data = data.view(-1, 28*28)
data, target = data.to(device), target.cuda()
logits = net(data)
loss = criteon(logits, target)
optimizer.zero_grad()
loss.backward()
# print(w1.grad.norm(), w2.grad.norm())
optimizer.step()
if batch_idx % 100 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
#在总的epoch中添加监视是否overfitting,就使用val_loader数据集
test_loss = 0
correct = 0
for data, target in val_loader:
data = data.view(-1, 28 * 28)
data, target = data.to(device), target.cuda()
logits = net(data)
test_loss += criteon(logits, target).item()
pred = logits.data.max(1)[1]
correct += pred.eq(target.data).sum()
test_loss /= len(val_loader.dataset)
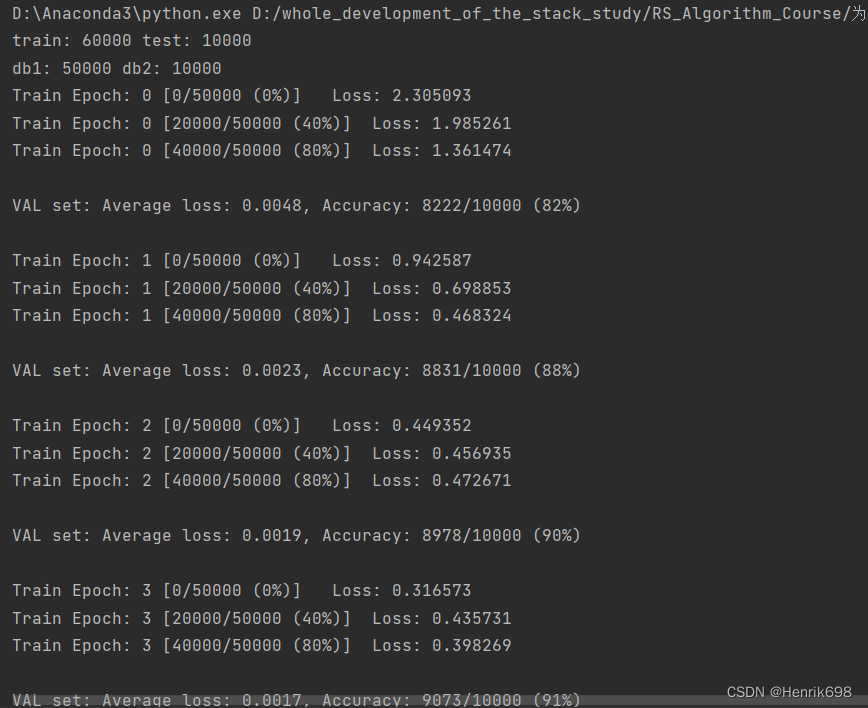
print('\nVAL set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(val_loader.dataset),
100. * correct / len(val_loader.dataset)))
#test_loader这部分代码和val_loader的代码是一样的,只不过使用模型最好时所对应的参数
test_loss = 0
correct = 0
for data, target in test_loader:
data = data.view(-1, 28 * 28)
data, target = data.to(device), target.cuda()
logits = net(data)
test_loss += criteon(logits, target).item()
pred = logits.data.max(1)[1]
correct += pred.eq(target.data).sum()
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
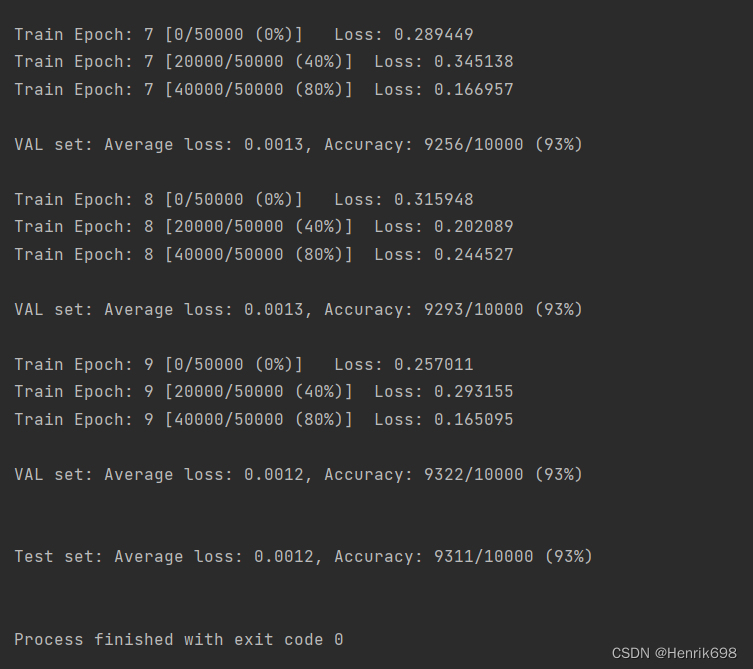
另一种数据划分的方式:交叉验证 K-fold cross-validation
首先test dataset是不能动的,之后第一次划分train dataset:
在train dataset基础上划分出了val set蓝色部分,和剩余train set部分。
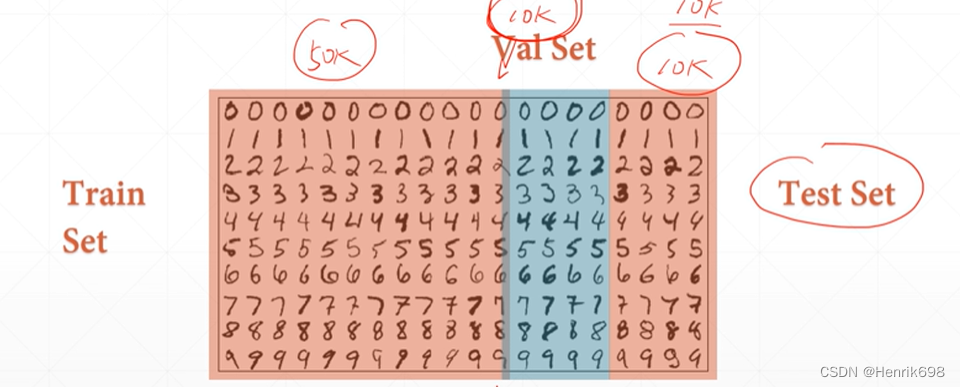
第二次再切割划分:
黄色部分为切割划分后的train set,白色部分是val set。
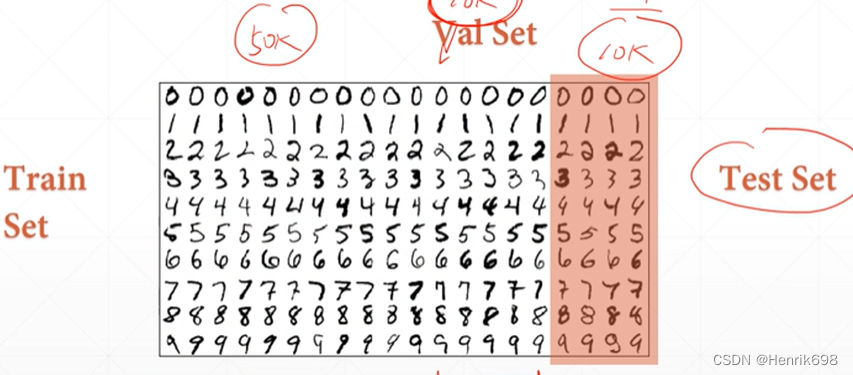
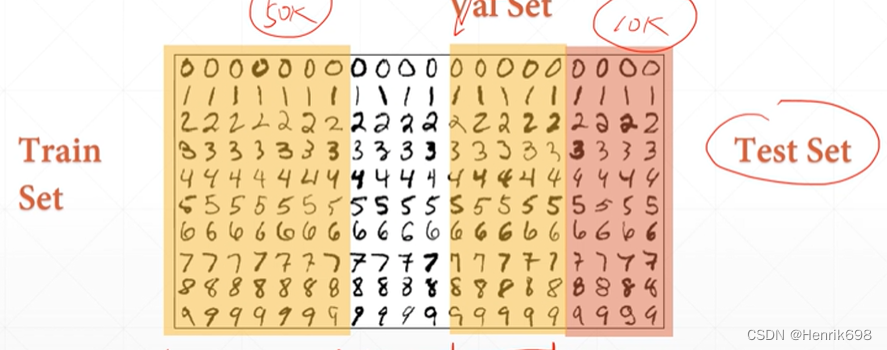
这样做的好处是每个数据集都有可能成为validation dataset。
K-fold cross-validation就是将train dataset的数据集划分成k份,每次取k-1/k 做train,另外剩下的1份做val。这样做是提升了train dataset数据的利用度。
三、Regularization 减轻防止overfitting
Reduce Overfitting
▪ More data 获得更多的数据,但是代价最大。
▪ Constraint model complexity 约束模型的复杂性
▪ shallow 降低模型的表达能力
▪ regularization 本节课所讲解的内容
▪ Dropout 对于神经网络单元,按照一定的概率将其暂时从网络中丢弃。
▪ Data argumentation 做数据增强
▪ Early Stopping 提前停止
Regularization
累加不同cross entropy的成为最终的loss,如果给原来的loss添加一项。
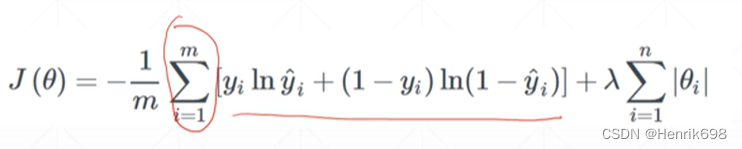
让|θi|接近于0,即模型参数的范数接近于0,这里的范数可以是1范数,也可以是2范数或者无穷范数。 这样可以使得参数的范数接近于0,使得β0、β1、β2、β3…这些参数接近于0,因为其参数范数接近于零,可以使得高维项的参数接近于0,达到降维效果。为了保证模型的解释能力,因此前几个参数保持较大的数值,而后面的参数接近于0,即β0,β1,β2保持不变这样可以保证模型的解释能力,β3,β4…很小,使得高维特征网络几乎没有了。可以将下图的网络,退化成更小次方的网络。即退化成 y = β0+β1x+β2x^2 失去了高维,也保证了模型的性能,也降低了overfitting。
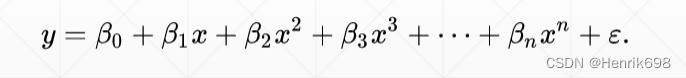
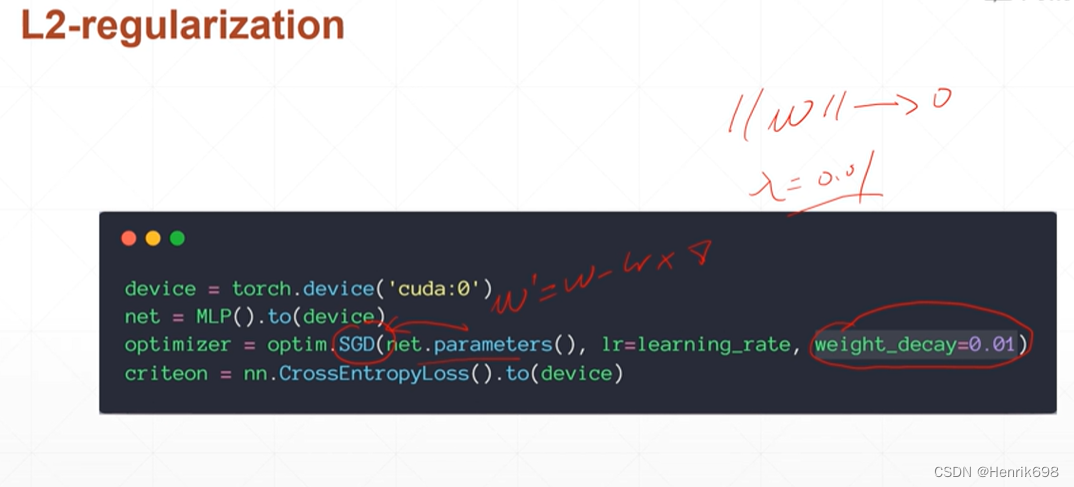
该过程叫Regularization,在pytorch或则其他文本中也被称作Weight Decay,Weight权值参数w,使得w接近于0,迫使w越来越接近于0,有衰减的意思Decay。

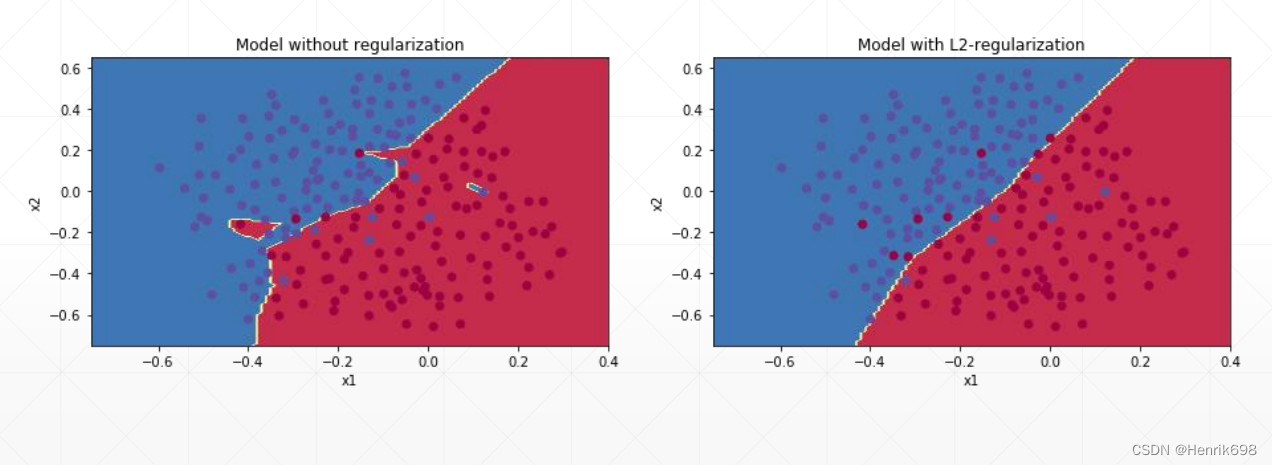
通过直观Intuition的角度来解释:右图加了一个L2-regularization
How 如何Regularization:
常用的是L2-regularization
此外lambda也是一个超参数,需要人为的进行调整。

在pytorch中如何做L2-regularization:
注意:没有overfitting,设置了L2-regularization,就会使得原有网络的复杂度降低,使得模型的性能急剧下降。
如果有overfitting,设置了weight decay ,该参数设置的好的话,该网络模型表现不会有大的影响,但是这个网络的test performance会有一定的提升。

四、动量与学习率衰减
动量 momentum
梯度更新的公式:
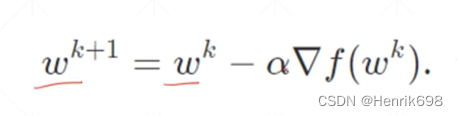
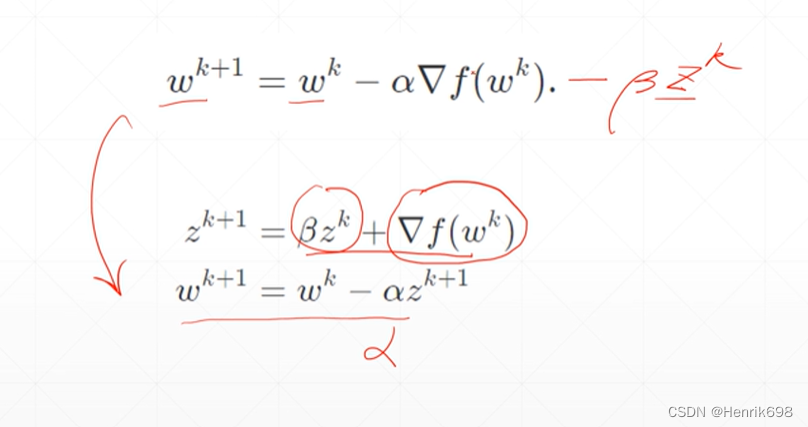
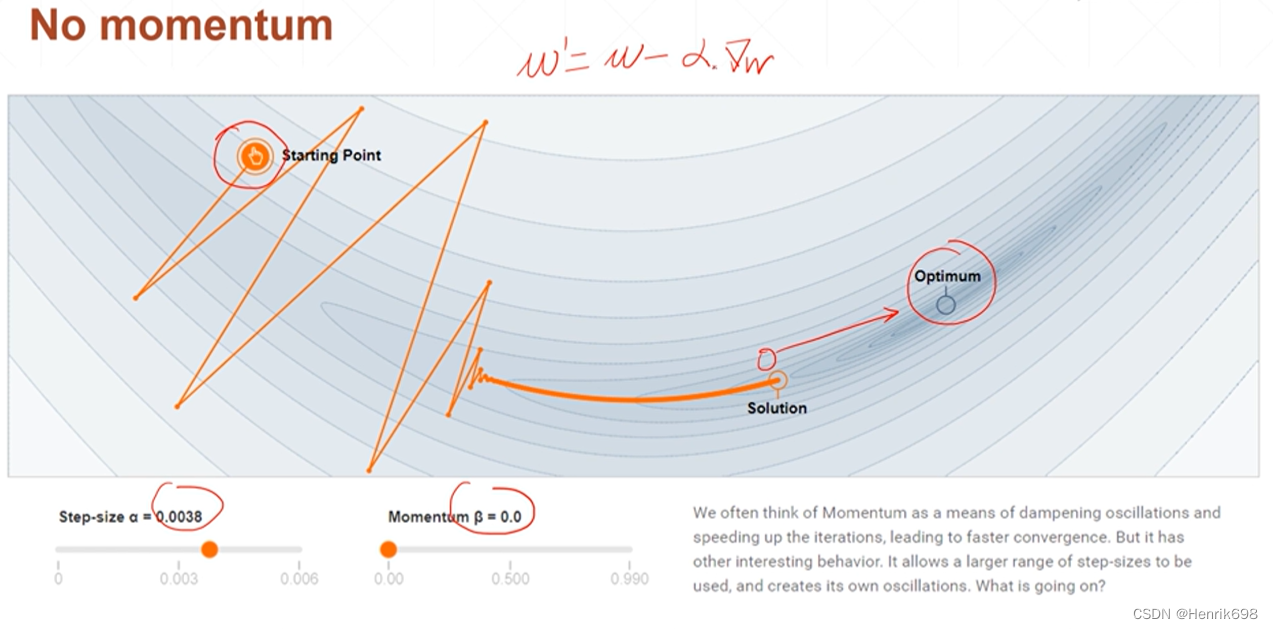
情况1,no momentum
情况2,with appr.momentum
添加了动量后,会更加偏向原来运动的方向,动量越大,偏向越多。
此外如果有动量,会有可能使原本停止的最小点被增加的原本的动量所冲出去,会有一定的惯性,使其达到新的最小值点,这个最小值点更加接近全局最小值点。

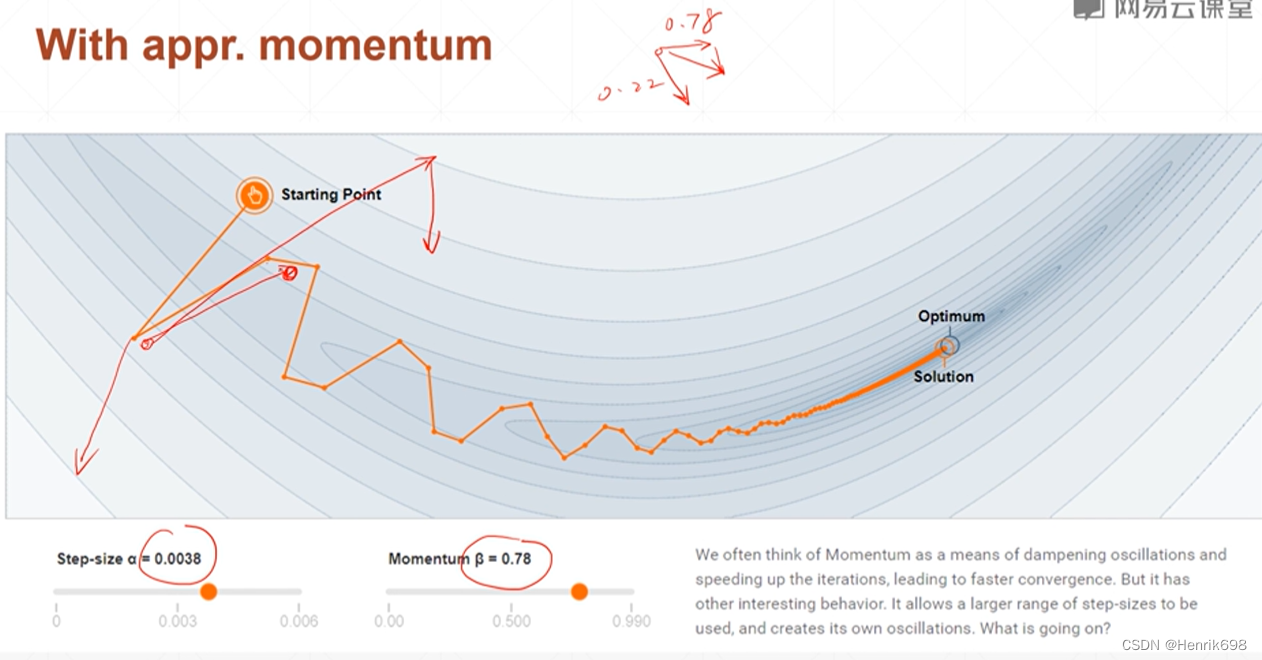
有一些优化器,如Adam是没有momentum这个参数的,这个Adam本身就是用momentum做了一些事情,所以不需要额外管理这个变量,内部已经设置好如何处理这个momentum了。只有最原始的SGD才没有负责处理momentum这个属性,需要我们人为来设置。
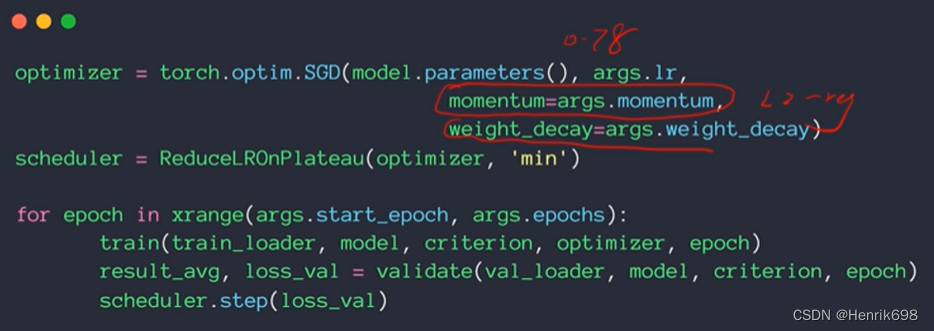
学习率衰减 learning rate decay
学习速率调整Learning rate tunning:
learning rate学习率越大,更新的幅度也就越大。
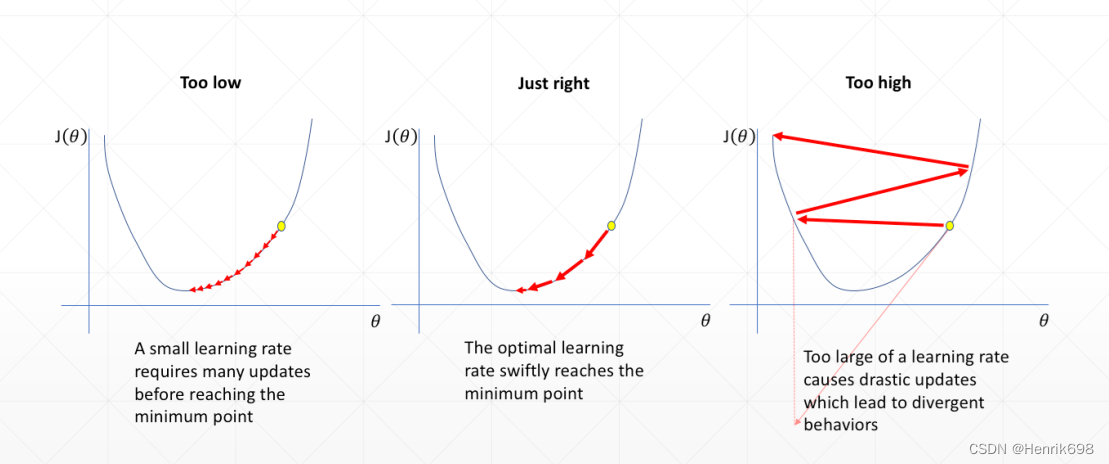
学习率衰减 Learning rate decay
学习率衰减目的是一开始学习率很大,后期学习率逐步减小。
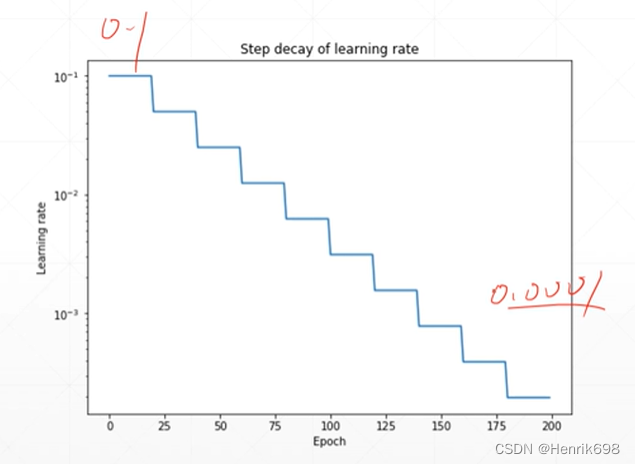
学习率的衰减可以让模型找到更小的最小值点,可以将模型寻找最小值点的性能提升上来。
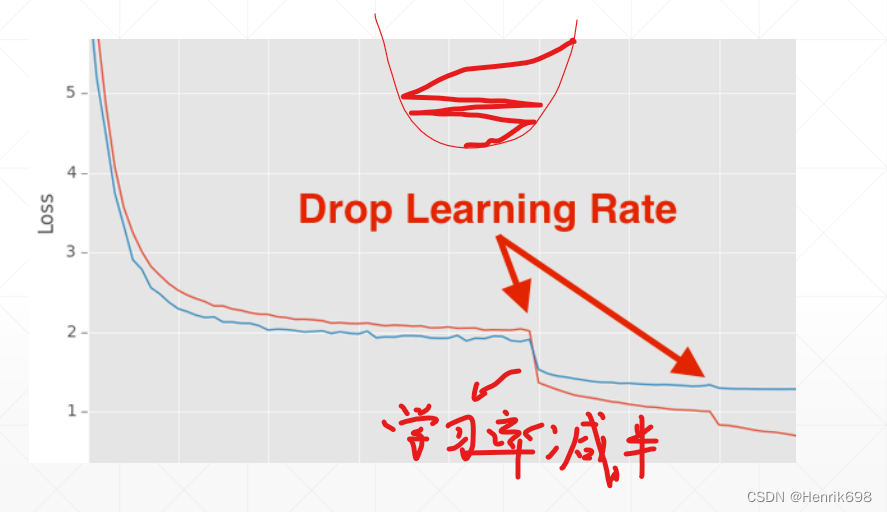
监听learning rate的方案:
1、方案1

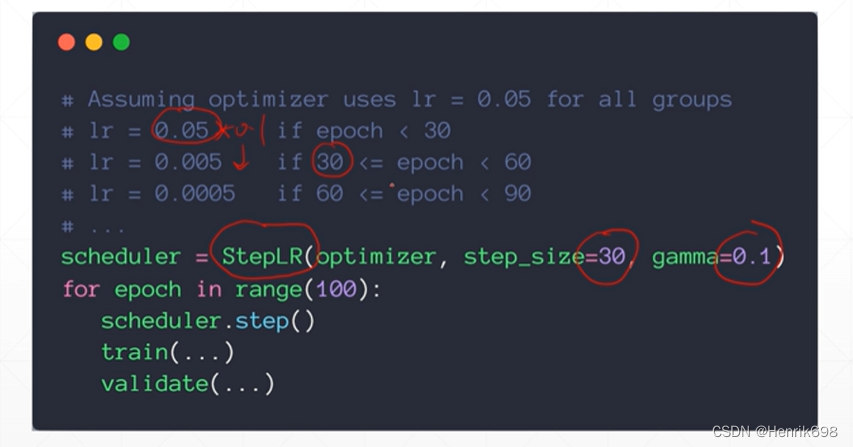
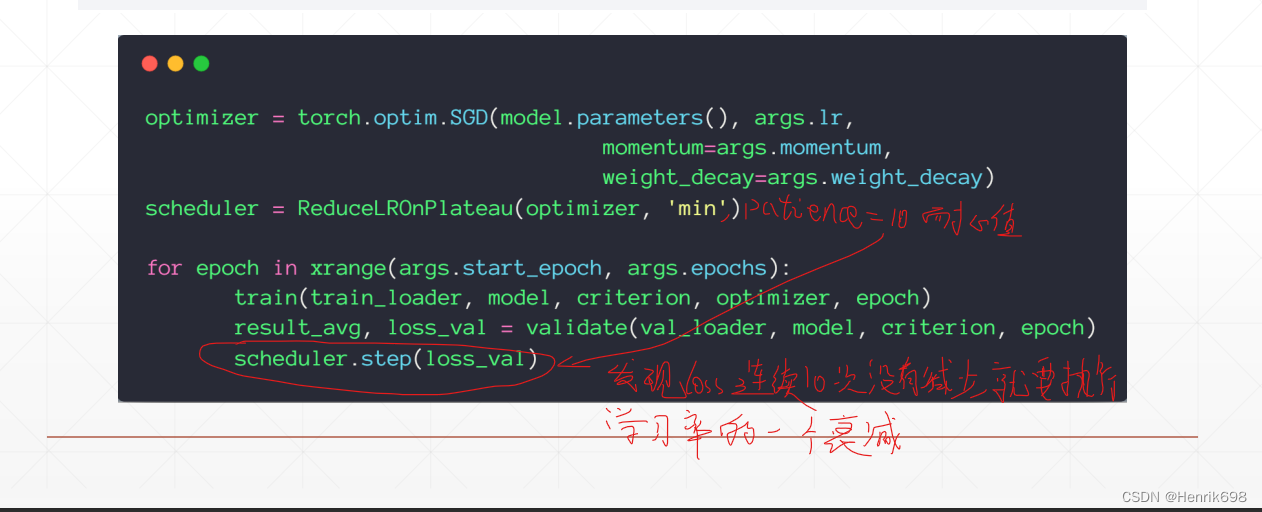 2、方案2:简单粗暴的
2、方案2:简单粗暴的
这里step_size=30设置的有点小,一般我们会设置为1k或10k。
五、其他技巧Tricks(Early Stop,Dropout)
Early Stopping
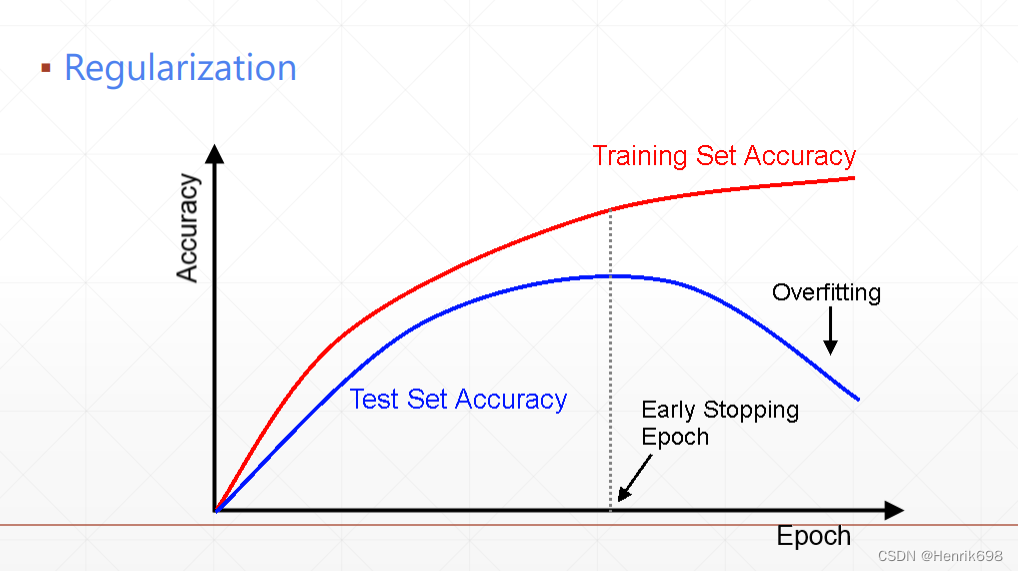
How-To
▪ Validation set to select parameters
▪ Monitor validation performance
▪ Stop at the highest val performance.
Dropout
不使用全部w,使用最少且表现最好的w数量,其他的w被抛弃。
▪ Learning less to learn better
▪ Each connection has 𝑝 = 0, 1 to lose
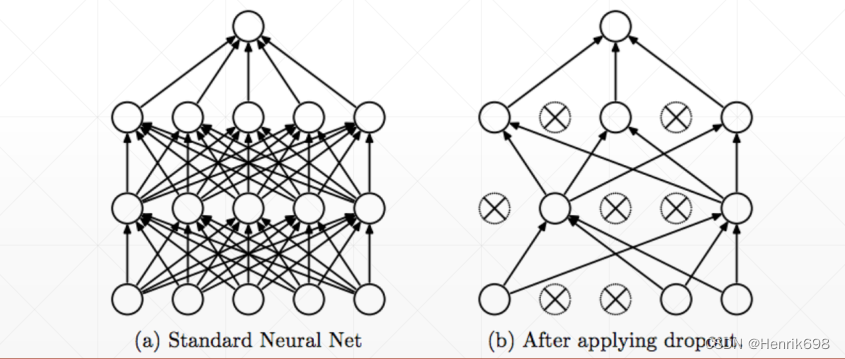
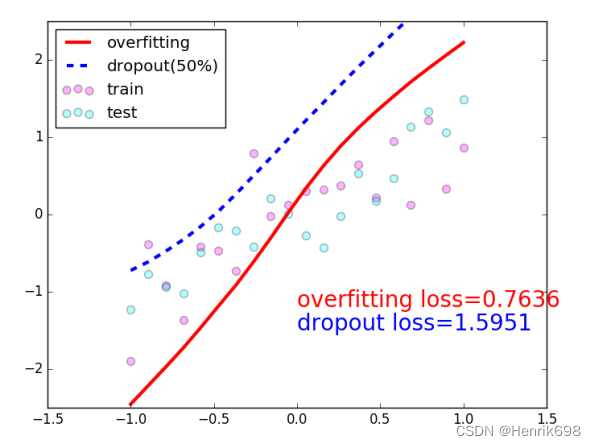

这里需要特别注意:
Clarification澄清:
▪ 在Pytorch中:torch.nn.Dropout(p=dropout_prob)
参数p=1表示网络连接的线都有可能全部断掉;
参数p=0.01表示线断掉的概率比较小。
但是:
▪ 在TensorFlow中:tf.nn.dropout(keep_prob)
参数keep_prob中p=1意味着所有的连接都保持住;
参数p=0.01保持住的概率是0.01,断掉的概率为0.99,断掉的概率更大。
这里Pytorch与TensorFlow定义的区别,需要注意,这个差别非常大。
Behavior between train and test
Dropout的行为在train和test是不一样的。
在train的时候,有的连接可能是断掉的;但是在test的时候,所有都是连接的,所有连接都会使用。
为了防止在validation的时候,还使用train的行为,必须人为的将原来的train的行为切换到net_dropped.eval(),如果不切换,test测试的时候还是会想原来train那样有50%的连接会断掉。这样会使test的performance下降一点点。

Stochastic Gradient Descent 随机梯度下降(SGD)
▪ Not single usually
▪ batch = 16, 32, 64, 128…
















 587
587











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











