







CV计算机视觉核心02-中阶计算机视觉(求图像的灰度直方图、反色变换、gamma变换、直方图与直方图均值化、计算机视觉分为以下四大问题、决策函数distance、综合做好计算机视觉问题,两个关键、主要的描述子有三个、Hog直方图方向梯度 、LBP局部二值模式、Haar-like、作业(用一个判别器f(x)来决策输出结果y))
灰度变换
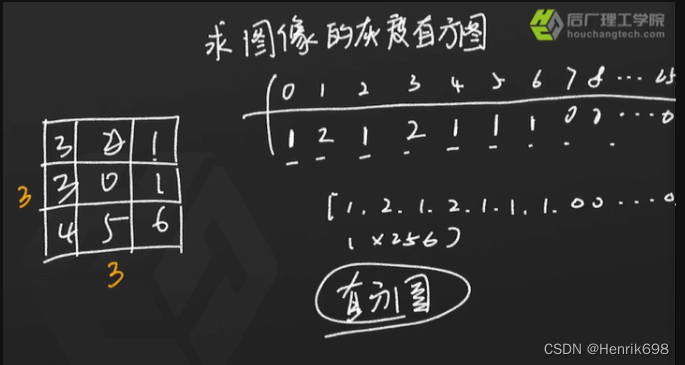
求图像的灰度直方图
就是灰度级上每个像元值的像素数量
反色变换
import cv2
import sys
import os
import matplotlib.pyplot as plt
def trans2show(img):
return cv2.cvtColor(img,cv2.COLOR_BGR2RGB)
img=cv2.imread("tangsan.jpg")
dog=cv2.imread("dog.png")
#img = cv2.cvtColor(img,cv2.COLOR_BGR2RGB)
gray = cv2.cvtColor(img,cv2.COLOR_RGB2GRAY)
dog_gray = cv2.cvtColor(dog,cv2.COLOR_RGB2GRAY)
print(dog.shape)

plt.figure(figsize=(11,11))
plt.imshow(trans2show(img))
plt.show()

# 灰度图像
plt.imshow(gray,cmap='gray')
plt.show()

灰度变换
反色变换
#反色变换
reverse_c=img.copy()
rows=img.shape[0]
cols=img.shape[1]
deeps=img.shape[2]
#反色方法1:效率慢:
# for i in range(rows):
# for j in range(cols):
# for d in range(deeps):
# reverse_c[i][j][d]=255-reverse_c[i][j][d]
#反色方法2:效率快
reverse_c = 255-reverse_c
#cv2.imwrite()将图像存下来了:
cv2.imwrite("tangsan_img_reverse.jpg",cv2.hconcat([img,reverse_c]))
#显示一下:
# hconcat([])水平显示两个图片
# vconcat([])竖直显示两个图片
plt.imshow(trans2show(cv2.hconcat([img,reverse_c])))
plt.show()

#反色变换
#对灰度图片进行反色变换:
reverse_c=gray.copy()
rows=gray.shape[0]
cols=gray.shape[1]
for i in range(rows):
for j in range(cols):
reverse_c[i][j]=255-reverse_c[i][j]
cv2.imwrite("tangsan_img_reverse.jpg",cv2.hconcat([gray,reverse_c]))
plt.figure(figsize=(13,13))
plt.imshow(trans2show(cv2.vconcat([gray,reverse_c])))
plt.show()
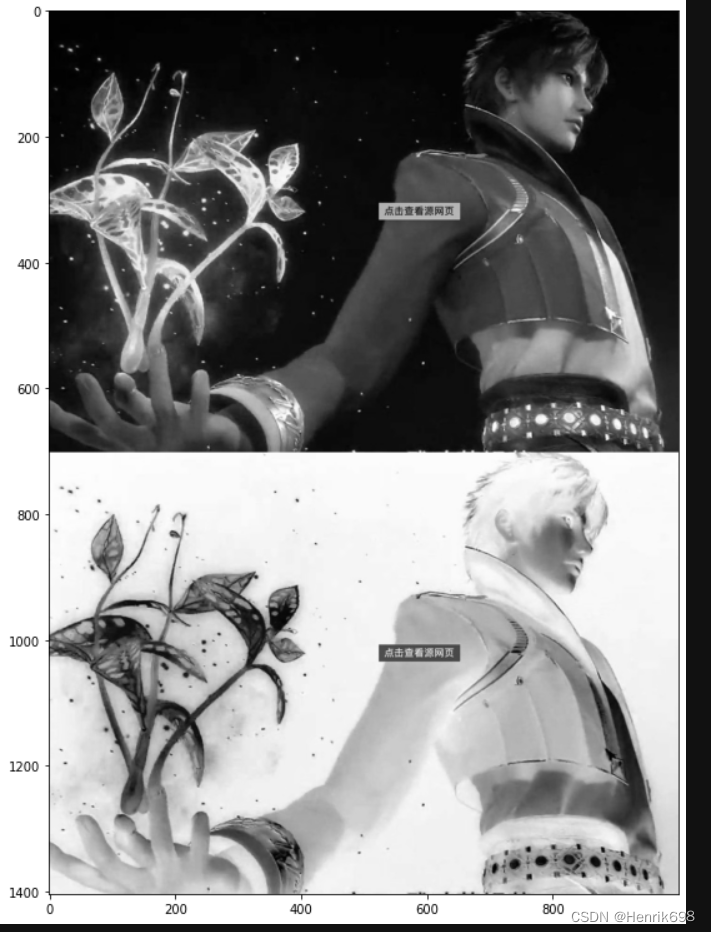
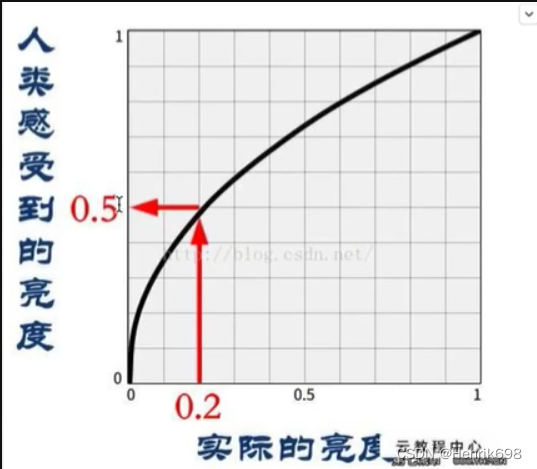
gamma变换,伽马变换
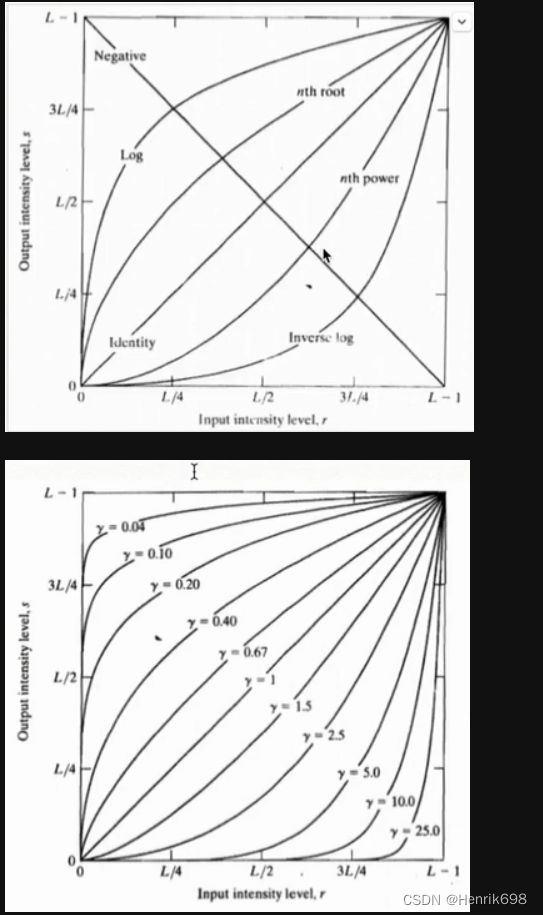
原图I的次方变换
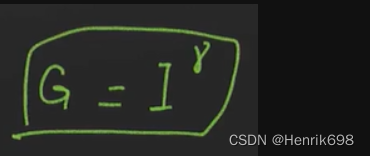
这里需要注意的是伽马变化需要将像元值从0-255压缩到0-1之后才能进行变换。
#伽马变换
#在彩色图片上
#这里是对狗的图片进行操作
import numpy as np
#img = cv2.cvtColor(img,cv2.COLOR_RGB2BRG)
gamma_c=dog.copy()
rows=dog.shape[0]
cols=dog.shape[1]
deeps=dog.shape[2]
#for循环方式太耗资源
# for i in range(rows):
# for j in range(cols):
# for d in range(deeps):
# gamma_c[i][j][d]=255*pow(gamma_c[i][j][d]/255,0.9)
#使用矩阵的方式
#gamma_c/255目的是将像元压缩到0-1范围
#之后每个像元再开0.8次方
#最后再乘以255,恢复0-255范围
#次方数越小,图片越亮,符合上面的曲线图片
gamma_c = 255*np.power(gamma_c/255,0.2)
gamma_c = gamma_c.astype('uint8')
print(gamma_c[100,100,:])
#显示图片的方法1:
#先将图片写入磁盘上
cv2.imwrite("tangsan_img_gamma_c.jpg",cv2.hconcat([dog,gamma_c]))
#再通过os.system()操作打开
os.system("open tangsan_img_gamma_c.jpg")

#显示图片的方法2:
#使用Matplotlib显示:
plt.imshow(trans2show(cv2.hconcat([dog,gamma_c])))
plt.show()

#伽马变换
#在灰度图片上:
#img = cv2.cvtColor(img,cv2.COLOR_RGB2BRG)
gamma_c=dog_gray.copy()
rows=dog_gray.shape[0]
cols=dog_gray.shape[1]
for i in range(rows):
for j in range(cols):
gamma_c[i][j]=255*pow(gamma_c[i][j]/255,0.2)
cv2.imwrite("tangsan_img_gamma_c.jpg",cv2.hconcat([dog_gray,gamma_c]))
os.system("open tangsan_img_gamma_c.jpg")
plt.imshow(trans2show(cv2.hconcat([dog_gray,gamma_c])))
plt.show()

直方图与直方图均衡化【面试常考】
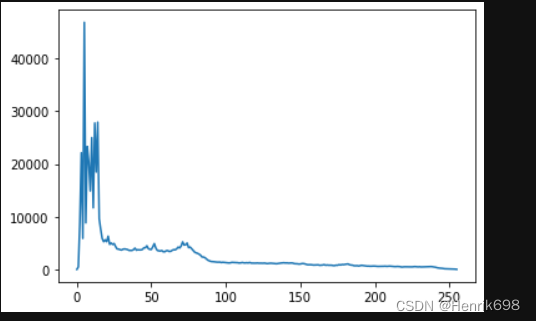
不同图片的直方图
# 直方图
import numpy as np
hist = np.zeros(256)
rows = img.shape[0]
cols = img.shape[1]
for i in range(rows):
for j in range(cols):
#当前的灰度值
tmp = gray[i][j]
#hist[灰度值] 最初都是0,循环的像元获得灰度值,并给原来的hist[灰度值]+1
hist[tmp]=hist[tmp]+1
print(hist.shape)

import matplotlib.pyplot as plt
#print(hist)
#plt.show(hist)
plt.plot(hist)
plt.show()
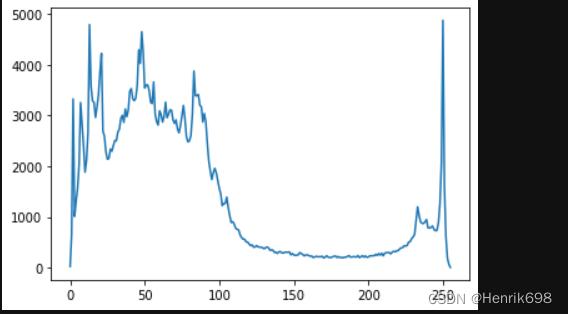
# 直方图
import numpy as np
hist = np.zeros(256)
#import pdb
#pdb.set_traoce()
img = cv2.imread("hist.png")
rows = img.shape[0]
cols = img.shape[1]
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
for i in range(rows):
for j in range(cols):
tmp = gray[i][j]
hist[tmp]=hist[tmp]+1
import matplotlib.pyplot as plt
#print(hist)
#plt.show(hist)
plt.plot(hist)
plt.show()
#print(hist)
#plt.show(hist)
plt.imshow(img)
plt.show()

直方图均衡化
目的是想在灰度级上的像素个数是一样的。这样均值化后,整个图片亮度相对均衡,不会出现都集中在灰度级一侧的情况。
#这个hist就是需要均值化图像的灰度直方图
trans = hist/(rows*cols) #获得比例,不同灰度值数量的比例
trans = trans*255 #按照比例分配255,这样下面循环累加最后那个值就是255
# print(trans)
print(trans.shape)
#从1开始
for i in range(1,len(trans)):
trans[i]=trans[i-1]+trans[i]
#累加过程,就是均值化过程
#trans[1] = trans[0] + trans[1]
#trans[2] = trans[0] + trans[1] + trans[2]
print(trans[-1])
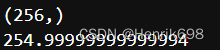
print(int(trans[155]))
print(trans.shape)

gray_h = gray.copy()
print(gray[0][0])
for i in range(rows):
for j in range(cols):
#直方图均值化核心:
gray_h[i][j] = int(trans[gray[i][j]])

plt.imshow(gray_h,cmap='gray')
plt.title("Histogram Equalization")
plt.show()

plt.figure(figsize=(10,10))
plt.imshow(cv2.hconcat([gray,gray_h]),cmap='gray')
plt.title("scr and Histogram Equalization")
plt.show()

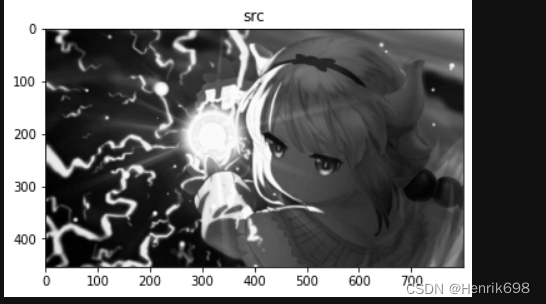
plt.imshow(gray,cmap='gray')
plt.title("src")
plt.show()
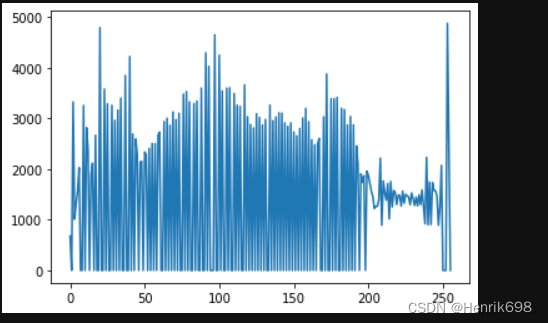
hist_h=np.zeros(256)
for i in range(rows):
for j in range(cols):
tmp = gray_h[i][j]
hist_h[tmp]=hist_h[tmp]+1
plt.plot(hist_h)
plt.show()
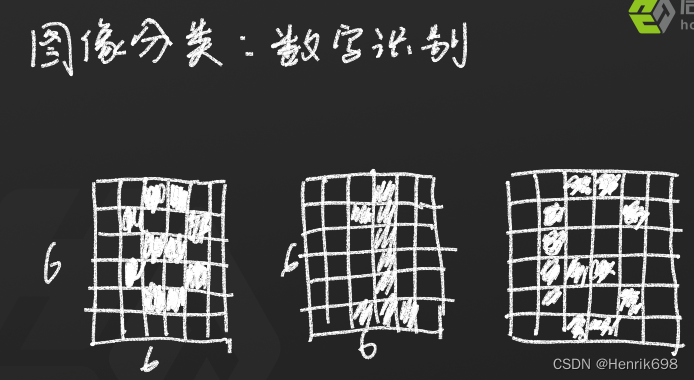
如何完成图片分类:
数字识别,如何来决策
完成一种映射:
Matrix => id{1,2,3}
要求计算来判别,好像计算机有了视觉一样:
id= Function(Matrix)
计算机视觉分为以下四大问题:

输入:
图片、视屏、表现数据上是Matrix
输出:
类别(id)、位置(x,y,z)、精细轮廓(Matrix)、一句话(Matrix)。
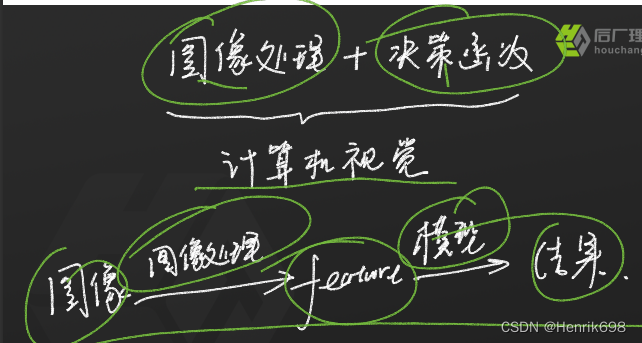
图像处理 VS 计算机视觉
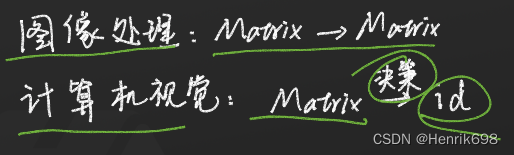

那么针对分类问题,我们会以何种方式给与计算机视觉功能呢?

直接判断:


本例feature可以这样设计:

投影法:就是横向或则纵向,每行或每列的所有像元相加。
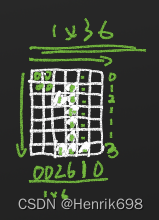

特征设计,提取是否能解决问题?
feature + 直接判断
feature会在一定程度将问题简单化,解决问题需要后续步骤的改进。

决策函数distance
L1 distance : | x1 - v1 | + | x2 - v2 |
L2 distance : 欧式距离
下图为L2距离:
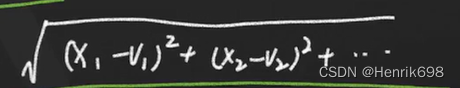
决策函数还可以自己来设计:
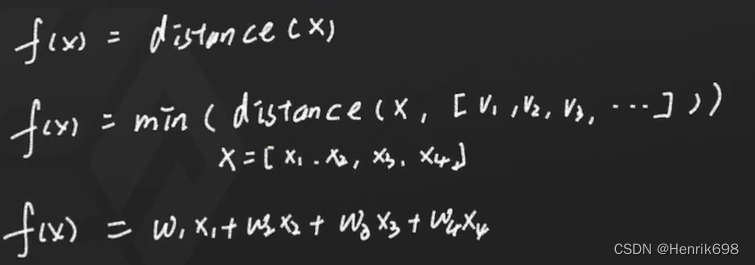


综合做好计算机视觉问题,两个关键:
1、提取好特征(用好图像处理)
2、设计好决策函数(模型)
假设规定:我们决策函数只使用欧式距离。
那么我们怎么办?
我们只能优化图像的描述子,也叫体特征(feature / descriptor)。
主要的描述子有三个:
Hog的直方图是方向梯度的直方图。直方图是一个统计量。
LBP表示局部二值模式,常用于人脸识别(识别的是谁的问题)。
Haar-like 常用于人脸检测(检测位置)。

Hog直方图方向梯度 的提取办法:
第一步:先将彩色图像灰度化(没必要用彩色图像,灰度图像就足够了)。一般灰度化后会加一个Gamma变换或者直方图均衡化,不同的图像对应不同gamma的参数值,因此我们估计一个值来统一所有图片的gamma变换的参数。
第二步:计算每个像素的梯度。(大小和方向)(关键)。
第三步:将图像分成小cell。(比如66的cell,这个计算就好了)。分成小cell的目的就是统计每个小cell的梯度直方图。
第四步:统计每个小cell中的梯度直方图。每个cell一个结果(即每个cell对应一个描述子)。
第五步:将每33个cell组成一个block,每个cell的描述子descriptor窜起来,得到Block的描述子。
第六步:将每个Block的描述子串起来,然后再归一化一下,就得到我们要的整张图片的feature描述子了。


Hog算法中求每个像素梯度的过程:(重要)
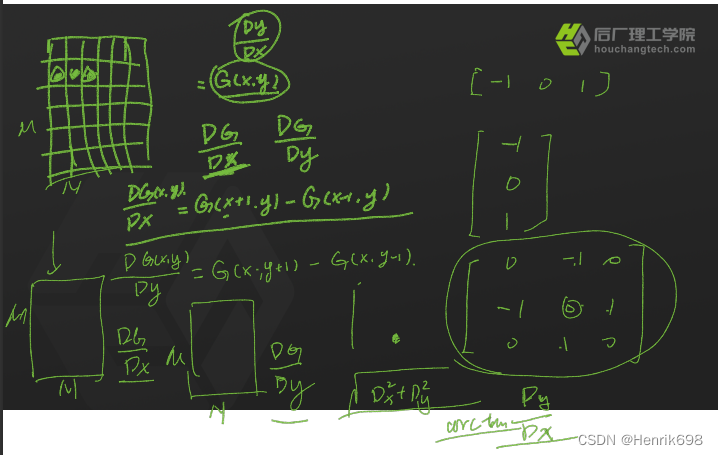
在(x,y)位置的灰度值是G(x,y),如果是一个维度就是Dy/Dx。
那么两个维度就是DG/Dx 和 DG/Dy,一个是x方向的梯度,另一个是y方向的梯度。
DG(x,y)/Dx = G(x+1,y) - G(x-1,y)
DG(x,y)/Dy = G(x,y+1) - G(x,y-1)
相当于做了下图这个卷积核的卷积计算:

那么x轴方向的卷积计算就是: [-1,0,1]
那么y轴方向的卷积计算就是:
[-1,
0,
1 ]
分别对x轴方向和y轴方向做梯度计算,可以分别获得一张x轴梯度的图片,和一张y轴梯度的图片,图片大小和原来的是一样的。
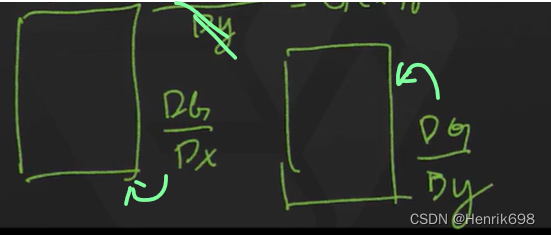
这样获得了x方向的梯度和y方向的梯度了。
这个梯度是像素值(灰度值)对位置的梯度。像素值在x方向位置上的变化,在y方向位置上的变化。
如果要获取梯度的大小,就是下图:

如果要获取梯度的方向,就是下图:
arctan(Dy/Dx)反正切函数,获得角度,用角度表示方向。
通过对梯度大小和梯度方向的计算,又可以获得两张图片,大小与原图保持一致,每个像素都能得到梯度的大小和方向:

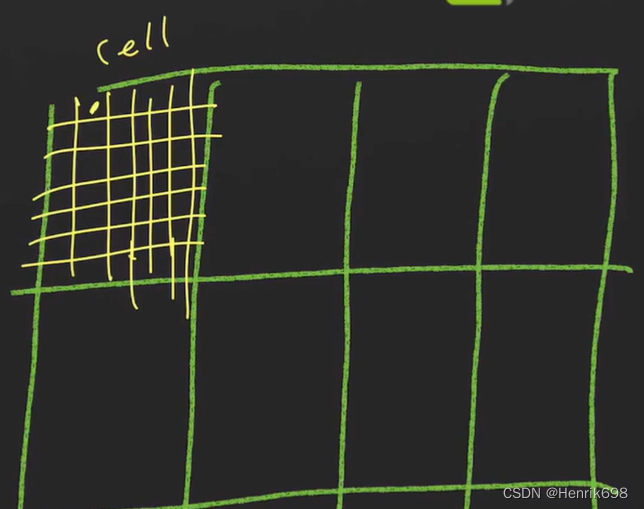
将图片分成66的小cell:

统计每个cell内的直方图,小cell内的黄色格网表示像素。
每个像素都有对应的梯度大小和方向。
对这个像素求梯度直方图,这里我们是按照方向来求直方图的。
方向是一个圆内,四面八方的方向。

一般是将360度按照每20度分,分18个,是118维度的向量,如果当前这个像素的梯度方向落到了18格中的任意一个,就将梯度值(这里以g1表示梯度的大小)写到这个格子中。
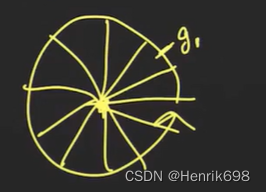
如果下一个像素的梯度方向还落在这个格子中(这里以g2表示该梯度的大小,即模),就将这个梯度累加到原来的g1上。
这里不是个数数量的统计了,是累加和的计算。
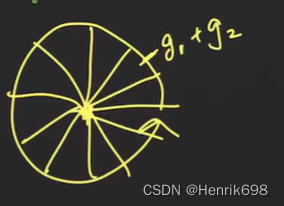
如果再下一个像素梯度方向落到了其他格子中,就将这个像素的梯度模长即大小写到这个格子中。
通过这样不同的累加统计,就获得了这个cell的梯度直方图。这个cell会得到一个18维的向量。
梯度直方图是统计的梯度方向在某一区间内的梯度的值的和。

我们分了多少个cell,就有多少个这样的18维向量。这个向量就是这个cell的描述子。
之后我们将33个cell,组成一个Block。
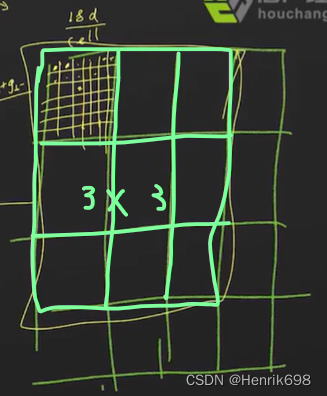
之后将这个block中的9个cell的所有描述子串起来,也就是18维9 = 162维。
这个162维就是这个Block的描述子。
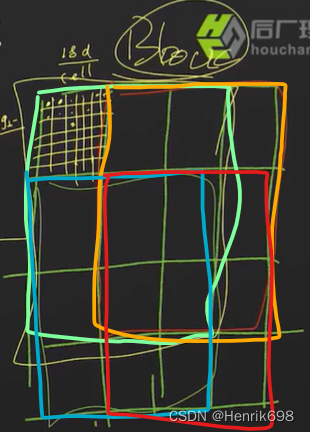
我们将这个block33滑动一下,获得这幅图像的所有block,并将所有block的描述子串起来。
这里有4个block,那么这个图像的描述子就是4162维 = 648维。之后对这个648维的向量做一个归一化处理,归一化处理是为了获得相对的值。
LBP局部二值模式 方法:

下面有一个3*3的图片:
一最中间的像素6为对象,分别与周围一圈的像元比较大小,如果小于中间像元值,那么这个小的像元就被赋值为0,如果大于就被赋值为1。

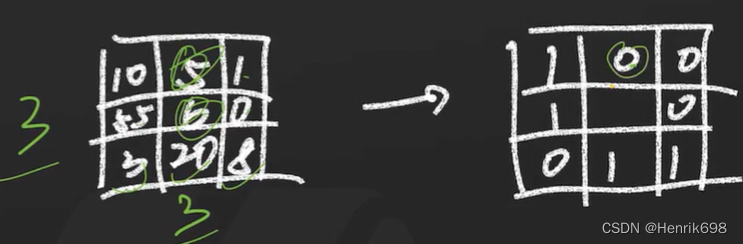
这样我们可以获得一个LBP码:1000110。
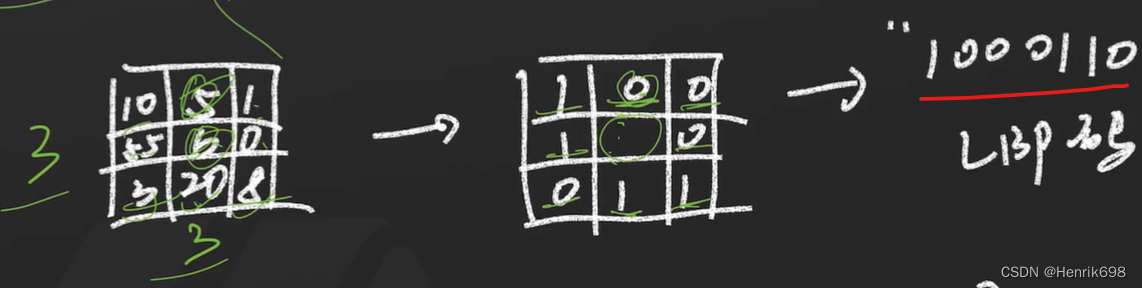
这个LBP码可以按照二进制数来看。可以转成十进制,1000110转十进制141。
这样我们就获得了这个图片的LBP特征。
LBP的旋转是不变的,因为我们可以取LBP的最小值,这样LBP码是不变的了,不受旋转的影响。
LBP步骤:
1、将图像分为16*16的小区域cell。
2、对cell中心的每个像素计算其对应的LBP值。
3、计算每个cell的直方图,然后归一化。(与Hog相同,但是这个直方图就是求个数了,因为是LBP值的数量统计)
4、将每个cell的直方图连起来,就得到这张图片的描述子了。(与Hog相同,最终也是这张完整图片的一个特征向量)

Haar-like
Haar-like是有模板的,就是红色方块,将模板放到图片相应的位置,将模板白色区域对应的图片像元赋值为1,黑色区域对应图片的像元赋值为-1。这样就相当于模板上半部分像素之和(sum白色)减去下半部分的像素之和(sum黑色)。
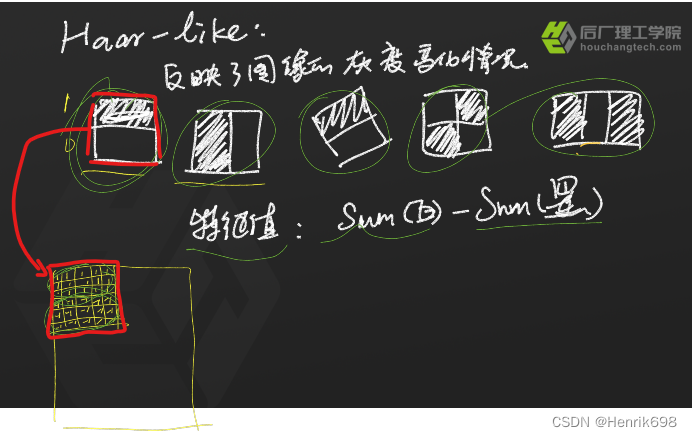


我们在做人脸识别的时候,会用到很多harr-like不同的特征,提取出来的不同特征组合在一起。
作业
步骤
1 生成10张图片,对应0,1,2,3,4,5,6,7,8,9.
2 对这10张图片提取特征x。
3 用一个判别器f(x)来决策输出结果y。
这个判别器达到作用:
当x是 “0”图片对应的特征时,y=f(x)=0
当x是 “1”图片对应的特征时,y=f(x)=1
当x是 “2”图片对应的特征时,y=f(x)=2
当x是 “3”图片对应的特征时,y=f(x)=3
当x是 “4”图片对应的特征时,y=f(x)=4
当x是 “5”图片对应的特征时,y=f(x)=5
当x是 “6”图片对应的特征时,y=f(x)=6
当x是 “7”图片对应的特征时,y=f(x)=7
当x是 “8”图片对应的特征时,y=f(x)=8
当x是 “9”图片对应的特征时,y=f(x)=9
#coding:utf-8
# code for week2,recognize_computer_vision.py
# houchangligong,zhaomingming,20200520,
import torch
def generate_data():
# 本函数生成0-9,10个数字的图片矩阵
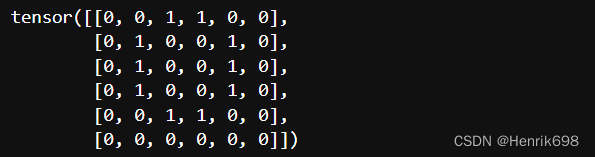
image_data=[]
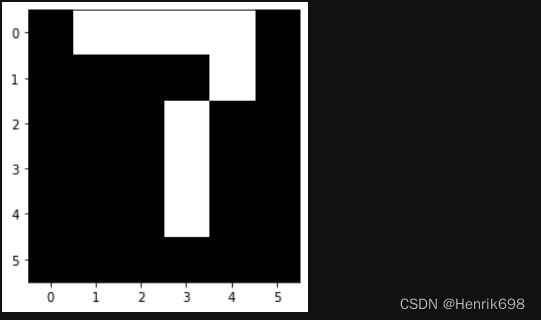
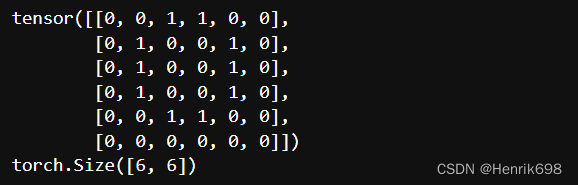
num_0 = torch.tensor(
[[0,0,1,1,0,0],
[0,1,0,0,1,0],
[0,1,0,0,1,0],
[0,1,0,0,1,0],
[0,0,1,1,0,0],
[0,0,0,0,0,0]])
image_data.append(num_0)
num_1 = torch.tensor(
[[0,0,0,1,0,0],
[0,0,1,1,0,0],
[0,0,0,1,0,0],
[0,0,0,1,0,0],
[0,0,1,1,1,0],
[0,0,0,0,0,0]])
image_data.append(num_1)
num_2 = torch.tensor(
[[0,0,1,1,0,0],
[0,1,0,0,1,0],
[0,0,0,1,0,0],
[0,0,1,0,0,0],
[0,1,1,1,1,0],
[0,0,0,0,0,0]])
image_data.append(num_2)
num_3 = torch.tensor(
[[0,0,1,1,0,0],
[0,0,0,0,1,0],
[0,0,1,1,0,0],
[0,0,0,0,1,0],
[0,0,1,1,0,0],
[0,0,0,0,0,0]])
image_data.append(num_3)
num_4 = torch.tensor(
[
[0,0,0,0,1,0],
[0,0,0,1,1,0],
[0,0,1,0,1,0],
[0,1,1,1,1,1],
[0,0,0,0,1,0],
[0,0,0,0,0,0]])
image_data.append(num_4)
num_5 = torch.tensor(
[
[0,1,1,1,0,0],
[0,1,0,0,0,0],
[0,1,1,1,0,0],
[0,0,0,0,1,0],
[0,1,1,1,0,0],
[0,0,0,0,0,0]])
image_data.append(num_5)
num_6 = torch.tensor(
[[0,0,1,1,0,0],
[0,1,0,0,0,0],
[0,1,1,1,0,0],
[0,1,0,0,1,0],
[0,0,1,1,0,0],
[0,0,0,0,0,0]])
image_data.append(num_6)
num_7 = torch.tensor(
[
[0,1,1,1,1,0],
[0,0,0,0,1,0],
[0,0,0,1,0,0],
[0,0,0,1,0,0],
[0,0,0,1,0,0],
[0,0,0,0,0,0]])
image_data.append(num_7)
num_8 = torch.tensor(
[[0,0,1,1,0,0],
[0,1,0,0,1,0],
[0,0,1,1,0,0],
[0,1,0,0,1,0],
[0,0,1,1,0,0],
[0,0,0,0,0,0]])
image_data.append(num_8)
num_9 = torch.tensor(
[[0,0,1,1,1,0],
[0,1,0,0,1,0],
[0,0,1,1,1,0],
[0,1,0,0,1,0],
[0,0,0,0,1,0],
[0,0,0,0,0,0]])
image_data.append(num_9)
return image_data
import matplotlib.pyplot as plt
image_data = generate_data()
print(image_data[0])
i=0
#设置一下cmap
plt.imshow(image_data[i%10],cmap = "gray") #color_map:cmap
plt.show()
i=i+1
# 获取列的和
def get_feature_col(x):
return torch.sum(x,0)
# 获取行的和
def get_feature_row(x):
return torch.sum(x,1)
x = image_data[0]
print(x)
print(x.shape)
print(get_feature_col(x))

print(get_feature_row(x))

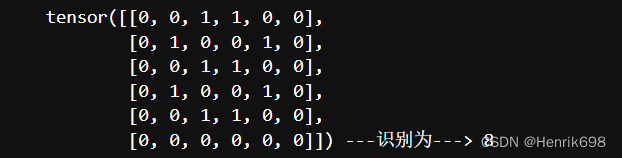
def model(x,image_data):
y = -1
for i in range(0,10):
#输入x,与image_data[i]做差
diff_tmp = x -image_data[i]
#差值的绝对值,并做sum,看看是不是等于0
if torch.sum(torch.abs(diff_tmp)) ==0:
#等于0,则y就是第i个图片
y=i
break
print("%s ---识别为---> %s" %(x,y))
return y
model(image_data[8],image_data)
















 2885
2885











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











