









技术预研
一.预研目的
模拟人类感知,不仅可以用来为图像评分,还能在很多劳动力密集的主观任务中发挥作用,如智能照片编辑、优化视觉质量提升用户参与度、减少图像pipeline中视觉感知的错误等等。
二.评估指标
1.DxOMark https://www.dxomark.com/cn/
2.MOS、DMOS(观察者主观评价法)
3.RMSE(均方根误差:比较算法评价值与人眼主观打分之间的绝对误差)
4.Pearson(线性相关系数:描述算法评价值与人眼主观打分之间的相关性)
5.OR(离出率:表示存在多个观察者主观评价分数时,超出主观得分ξ2倍标注差的样本数百分比)
三.数据库
1.LIVE 3D Image Quality Database Phase I AND II ( I 针对对称扭曲失真, II针对对称和不对称扭曲刺激)
2.MICT 3D Image Quality Evaluation Database(3D图像,不适合使用)
3.Ningbo University 3D Image Quality Database Phase I AND II
4.LIVE Image Quality Assessment Database(图像数量不多且畸变异常图像多,不太适合使用或可以作为模型训练集的补充或模型测试集使用)
(包含了来自29张参考图像的779张畸变图像,在7-8个退化级别上有5种不同的畸变。
在[0,100]范围内的每张图像都提供了差分平均意见评分(DMOS),其中DMOS越高,质量越差。)
5.TID2008(问题同上4.)
(它包含了1700张扭曲的图像,其中17种不同的扭曲来自于4个退化级别的25张参考图像。每个图像都与在[0,9]范围内的平均意见得分(MOS)相关联。)
6.TID2013(问题同上4.)
(它包含了来自25个参考图像的3000幅失真图像,这些参考图像有24种不同程度的失真。每个图像都与一个MOS相关联。)
7.AVA Dataset: 大型美学质量评估数据库,包括250000张照片。每一张照片,都有一系列的评分,以及语义级别的label,其中语义级别的label共60类,同时还有photographic style,也就是照片的风格,有14类。
(数据量大,摄影图片类别多;可用,但是否采用AVA标签存疑。)
https://www.jianshu.com/p/50da0dd4bf19
四.IQA方法:
1.传统算法
1)全参考图像质量评价算法FR-IQA:
需要同时用到原始图片和失真图片,对二者的特征进行相似性比较。一般来说,FR-IQA包括两类方法,一种是传统的自底向上方法,这类方法基于HVS的某些视觉通路,如掩盖效应,对比灵敏度,最小可视差等,由于HVS的复杂性和认知的有限性,这类自底向上的方法通常很难与主观感知保持一致;比较经典的自底向上方法有MSE/PSNR。另一种是自顶向下的方法。这类方法对HVS的整体函数进行建模,利用了图像的全局信息,与主观感知的一致性要高于前一类方法。这类方法比较经典的算法包括,SSIM,MDSI以及GMSD
2)半参考图像质量评价算法RR-IQA:
不需要原始图像本身,但是需要一些特征,在卫星和遥感图像中被使用的较多。RR-IQA类方法常常在不同的特征空间中使用,主要思路是对FR-IQA类评价指标进行近似
3)无参考图像质量评价算法NR-IQA:
完全基于图像本身,不再需要原始图。不过由于没有原始的图像,需要对原始的图像进行统计建模,同时还要兼顾人眼的视觉特征,本来这就有一定的主观和不确定性。虽然研究人员提出了数十个NR-IQA指标,但是真正广泛使用的没有几个。另外无参考的美学质量评估也是当前比较开放的一个问题,它需要更多考虑摄影学等因素。
总结:
传统算法中,无论参考图像的程度多少,其本质都是以固定指标通过或多或少的与无失真图像对比来进行图像质量评价;
算法偏规则化,无法做到智能模拟主观人类评价图像的目的。
2.deep IQA
1)Deep Convolutional Neural Models for Picture-Quality Prediction

a.图像裁剪分块分别输入共享CNN,将输出的预测分数分别加权重再pool成全局分数
b.图像裁剪分块分别输入共享CNN,提取每个图像块对应的特征向量,将它们聚合成一个表示整图的特征向量后再回归得到图片分数
c.图像整图输入CNN,将训练后的最深层级特征图进行加权,最后得到表示整图的特征向量后再回归得到图片分数
d.图像裁剪分块分别输入共享CNN,提取每个图像块对应的特征向量,再接入一个神经网络用来训练得到不同块的特征向量聚合所使用的权重,再回归得到图片分数
总结:
综述中深度学习方法基本涵盖在以上四类方法中,个人观点是c.方案更符合实际应用。
1.a.b.d.(patchwise):图像如何切分成块的问题,若平均切分,可能会破坏全局信息,把本来连通的区域切分开了;在图像中随机取固定个固定大小的图像块由于针对图像部分失真或部分细节质量的衡量问题带来了不确定性,同样不可。综上,如用a.b.d.分块方法,可(例:将图像平均分9块,在加上图像本身缩放到与九个块同样大小,共十个图像块作为输入)
2.a.的问题是:CNN提取不同块的特征后,人在无法确定每个CNN提取的特征和它们对全局的重要性时,不能随意赋予权重。
3.b.和d.旨在解决a.的权重不可解释问题,而b.简单整合的方法其实相当于权重都为1,d.的方法相当于训练权重。
4.patchwise带来的另一个较大的问题为,图像质量分数标签为整图的,训练时分块对应的分数标签理论上应不同,这个问题还没有思考到合适的解决方案。
5.c.(imagewise)规避了如何分块的问题,将权重加到卷积之后的特征图上; 图像的QA问题没法做augmentation,数据可能较少。
2)Blind Predicting Similar Quality Map for Image Quality Assessment

a.第一步:得到quality map。使用Unet框架,生成两个分别使用SSIM和FSIM做label的quality map。
b.第二步:回归quality score。生成两个quality map后,分别pool之后连接,然后输入FC做regression得到回归分数。
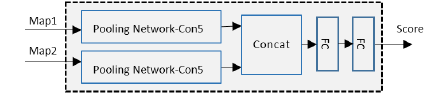
总结:
1.文章的思想很清楚,但不清楚使用unet生成的两个map图效果如何。如果效果还可以理论上直接还原未失真图像也是可行的,但是想要到达一定的效果,恐怕要做不少的工作。
2.结合实际业务,恐怕不能单纯以SSIM和FSIM为标签生成map,这个问题待深入了解业务后讨论。
3)Neural Image Assessment
https://arxiv.org/abs/1709.05424

通过裁剪块扩增数据且规避图像缩放中对质量的不可避免的变化,通过各种pipeline CNN预测给定图像的评级分布,修改损失函数使分类网络正常使用交叉熵预测类(0-10),对交叉熵损失缺乏判断的得分区间之间的内部关系,不使用回归,基于EMD损失(将一个分布的质量移动到另一个分布的最小成本)来得到具体分数。
总结:
1.优点:网络结构明确易实现;不是将图像分类为低/高分或回归到平均分,评级的分布被预测为EMD损失
2.缺点:AVA数据库标签我们是否认可,仍然是数据及标签问题。
4)GAN实现IQA:略
总结:
1.优点:算法创新。
2.缺点:GAN网络本身训练很难收敛,使用GAN做IQA的很多想法在学术界仍在research阶段,故不适合我们作为工程使用。
五.设想方案
1.复现四-2-3)方法(可在网络结构,主动学习调整模型等方向上考虑调参和改进)
2.使用四-2-2)方法,但用来label生成quality map的参考标准待定义
3.利用全卷积神经网络(FCN或Unet等等)直接自动生成显著图,进而得到表示图像中不同区域在质量评分中重要程度的权重参数,将像素点对应的权重加权到四-2-1-c)方法 中得到的feature map上,然后回归得到IQA score
六.存疑&需要深入了解实际评测业务
- 数据库构建:图像是模型训练的基础,标签相当于给出我们想得到的IQA的分布
• 数据来源:官方or自建图片库
• 标签标注:打分标准 and 是否认可
• 数据库是否需分类:不同场景或不同测试偏重图像是否需要分开
• 数据量:需沟通(了解可以拿到的数据量)
2.模型训练:是否需要人为评测中途介入(主动学习策略)
3.需要了解评测组实际项目中的主客观打分项和标准等等:明确项目中实际需要的参考标准
4.AI在实际评测项目中,介入哪个环节?? & 如何对人力和效率进行节省和提升??**















 3135
3135











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









