







背景
由于这样那样的原因,我们从各个端收集回来的数据不一定是完整的,经常会碰到某些关键字段缺失的情况。如果做一般的大数据分析或者数据可视化,小部分的缺失其实影响不大,在预处理把含有空缺值的整条数据删掉就行了。但是也有一些特定的场景下不能这么简单了事,需要对数据进行补全。
假设我们现在有这样一张表test(片段):
| t_date | t_device_id | app_name | package_name | launch_time |
| 日期 | 设备ID | 应用名称 | 应用包名 | 启动时长 |
模拟构建
--建表
CREATE TABLE test
(
`t_date` Date,
`t_device_id` String,
`app_name` String,
`package_name` String,
`launch_time` UInt32
)
ENGINE = Memory ;
--插入数据
insert into test values('2022-01-01','D0001','launcher','com.android.launcher',1658),
('2022-01-01','D0002','setting','com.android.settings',2005),
('2022-01-02','D0003','','com.google.setupwizard',1052),
('2022-01-03','D0003','launcher','com.android.launcher',1360),
('2022-01-03','D0004','setting','com.android.settings',0),
('2022-01-03','D0004','','com.google.setupwizard',1357),
('2022-01-04','D0005','qq','com.tencent.qq',1698);
--查询
select * from test;
1.删除法
alter table test delete where app_name is null or app_name=''
2.填充固定值
select t_date,t_device_id,if(app_name='','other',app_name),package_name,launch_time from test
3.填充相邻值
即 将上一行或者下一行的值填充到空缺的位置中,主要用到arrayFill()或者arrayReverseFill()函数。
arrayFill():使用上一行的值替换当前值
select tuple.1 as t_date, tuple.2 as t_device_id,tuple.5 as app_name, tuple.3 as package_name, tuple.4 as launch_time from
(select arrayJoin(
arrayZip(
groupArray(t_date),
groupArray(t_device_id),
groupArray(package_name),
groupArray(launch_time) ,
arrayFill(x ->x !='',groupArray(app_name))
)
) as tuple
from test)
arrayReverseFill():使用下一行的值替换当前值
select tuple.1 as t_date, tuple.2 as t_device_id,tuple.5 as app_name, tuple.3 as package_name, tuple.4 as launch_time from
(select arrayJoin(
arrayZip(
groupArray(t_date),
groupArray(t_device_id),
groupArray(package_name),
groupArray(launch_time) ,
arrayReverseFill(x ->x !='',groupArray(app_name))
)
) as tuple
from test)
4.填充平均值
此方法仅用于数值型的缺失值。以案例中的launch_time为例,使用arrayAvg()和groupArray()结合,计算出相同包名的平均launch_time填充空缺值。
select t.t_date,t.t_device_id,t.app_name,t.package_name,if(t.launch_time=0, a.avg ,t.launch_time) as launch_time
from test t any left join (
select package_name,arrayAvg(arrayFilter(x->x!=0,groupArray(launch_time))) as avg
from test
group by package_name
) a on t.package_name = a.package_name 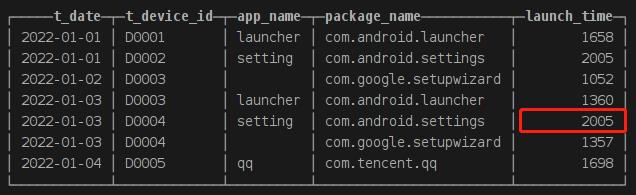
5.填充枚举值
试想这样的场景,我们可以根据相关列推断出这个空缺值,并事先定义好了一些枚举,例如本案例中,预先设定了“com.google.setupwizard”这个包名对应的app_name为wizard,那么可以预定义package_name和app_name的对应枚举,并使用transform进行取值。PS: 当然有if()语句也能实现相同的效果,但是如果枚举很多的话,看起来会很复杂。
SELECT
t_date,
t_device_id,
if(app_name = '', transform(package_name, ['com.google.setupwizard', 'com.hello.clickhouse'], ['wizard', 'ch'], 'OTHER'), app_name) AS app_name,
package_name,
launch_time
FROM test

6.他山之石法
意思就是这张表缺失的数据,用另一张表的数据来填充。其实原理跟“填充枚举值”是一样的,当枚举值太多的时候,可以考虑新建另一张表来维护这些空缺值的映射。
构建另一张表:
CREATE TABLE test_map
(
`app_name` String,
`package_name` String
)
ENGINE = Memory
insert into test_map values('aa','com.test.aa'),('bb','com.test.bb'),('cc','com.test.cc'),('wizard','com.google.setupwizard')结合groupArray()和transform()进行填充
WITH (
SELECT (groupArray(package_name), groupArray(app_name)) FROM test_map
) AS k_v
select t_date,t_device_id,if(app_name='',transform(package_name, k_v.1, k_v.2, 'OTHER'),app_name) AS app_name,package_name,launch_time from test
7.其他高级算法
比如利用k最近邻或者贝叶斯估算法填充数据,这个就不属于Clickhouse的范畴了。















 3918
3918











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









