






 该博客探讨了在Kaggle上的Titanic数据集上应用分类算法预测乘客存活情况。作者首先分析了目标变量Survived,接着检查数据关联性,特别是特征Pclass、Sex、SibSp和Parch与存活率的关系。接着进行特征工程,包括删除不必要特征,创建新特征,转换类别型特征以及处理缺失值。最后,文章介绍了模型建立和分析,包括逻辑回归和分类模型的应用。
该博客探讨了在Kaggle上的Titanic数据集上应用分类算法预测乘客存活情况。作者首先分析了目标变量Survived,接着检查数据关联性,特别是特征Pclass、Sex、SibSp和Parch与存活率的关系。接着进行特征工程,包括删除不必要特征,创建新特征,转换类别型特征以及处理缺失值。最后,文章介绍了模型建立和分析,包括逻辑回归和分类模型的应用。
分类算法预测存活-Kaggle
查看目标变量
1)库函数导入

2)导入数据集

3)查看数据集
查看所有表项

查看数据概况
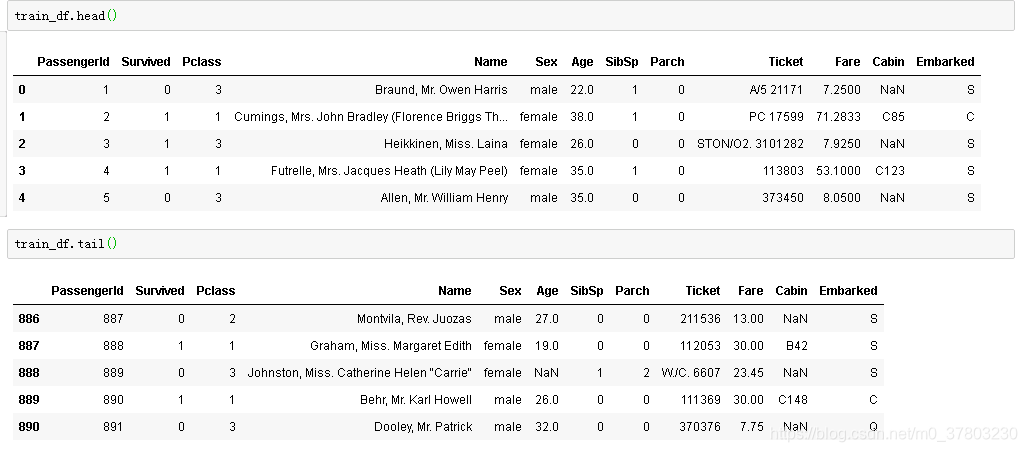
查看训练集和测试集各特征数据类型及数据缺失情况
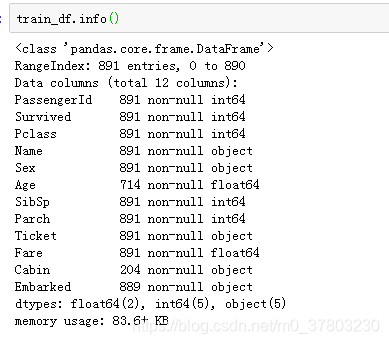
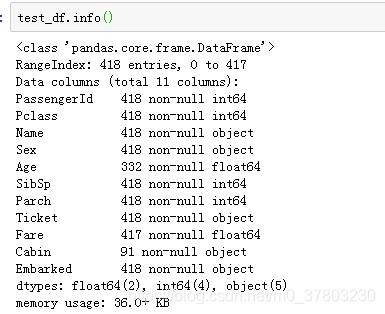
查看数据取值与数据分布(查看字符型数据,为大写字母O)

4)目标变量
预测目标为Survived
为整型数据,取值为0/1,训练集中无缺失值
0:未存活
1:存活
二分类问题。
查看数据关联性
数据量较少,依次查看特征与预测目标变量的关系
首先根据特征的类型(数值型和字符串型)进行特征分类

1)然后根据特征是否为类别型特征进行可视化查看:
可以看出Pclass(客舱类型)、Sex(性别)、SibSp (乘客在船上的兄弟姐妹/配偶数量)、 Parch(乘客在船上的父母/孩子数量)为类别型,根据求取均值来查看其相关性:

注意此处越接近0/1的,相关性越高,越接近0.5的,更倾向于随机分布。此处可以看到客舱为1的生存率更高,为3的生存率很低,客舱为2的对半。

可以看出女性的存活率明显高于男性

可以看到兄弟姐妹配偶数越多的,存活率越低
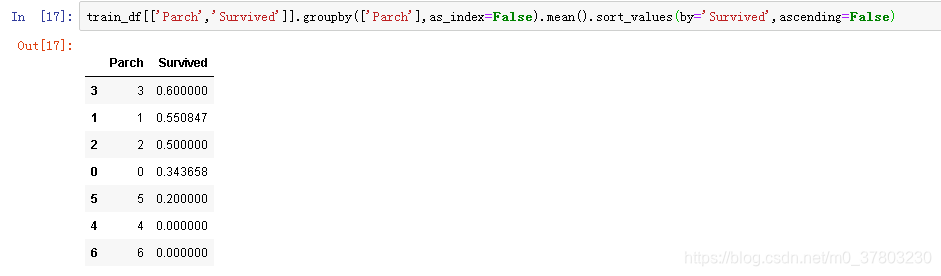
可以看到一定的分割,大于3的存活率极低。
2)查看数值型特征
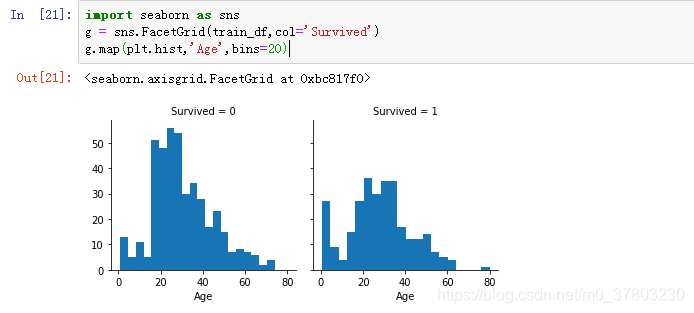
可以看到年纪小的存活率较高,年纪最大的也存活下来。15-20岁的人数较多,且大部分未存活下来
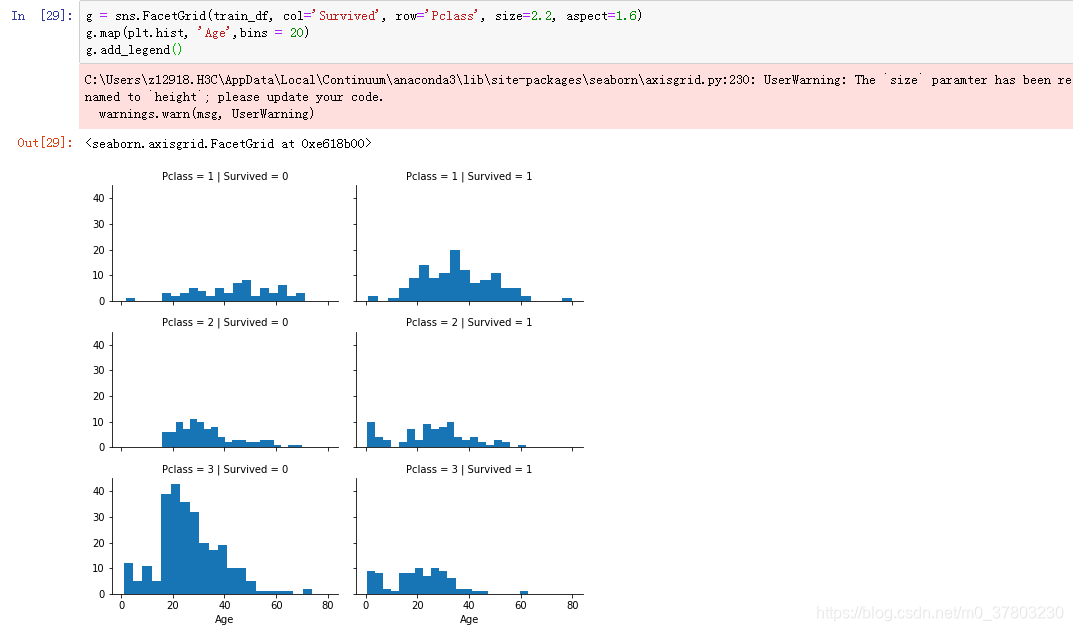
3号舱的乘客人数较多,且大多数都没有存活下来
2/1号舱的人大多数活下来了
1号舱的存活比例较高
各等级舱的岁数比较存在一定差异
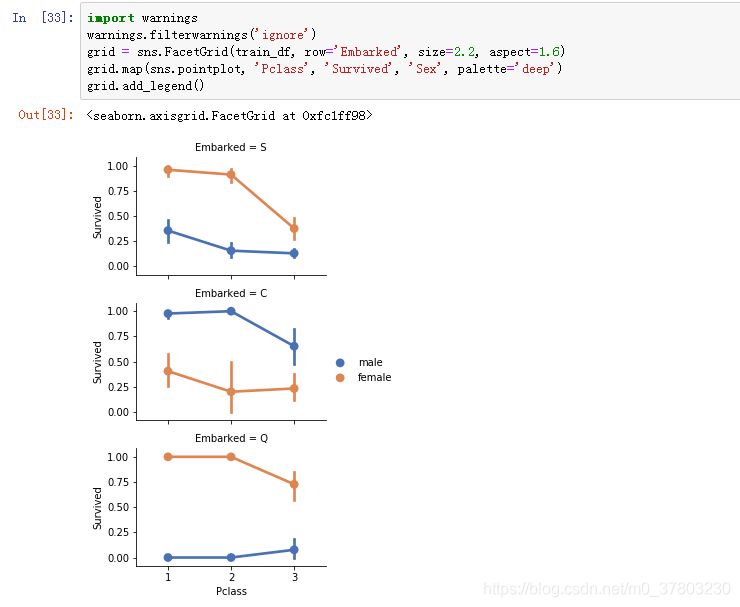
之前计算得到女性的存活率比较高,此处同样
Embarked=c的男性的存活率高过女性,存在一定的差异
特征工程
删除不必要特征

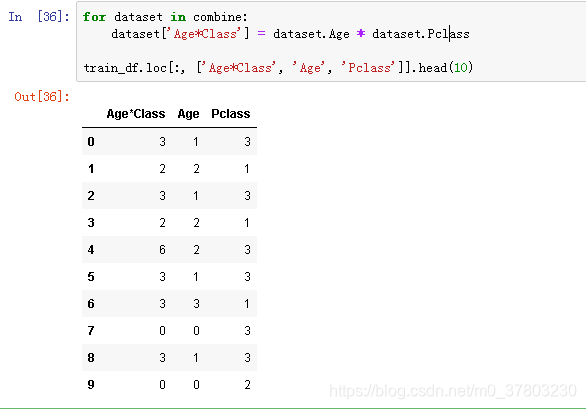
根据现有特征构建新特征

crosstab交叉表是用于统计分组频率的特殊透视表
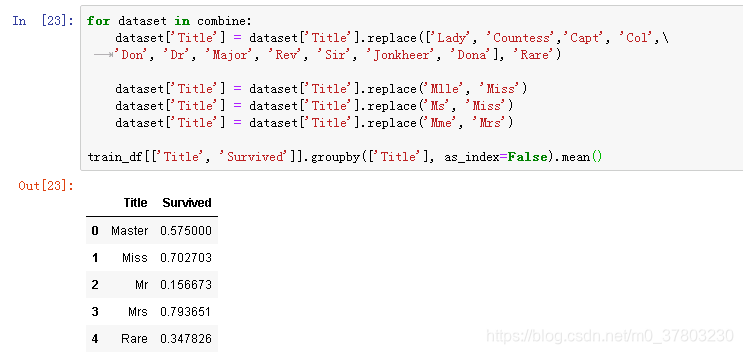
将称谓进行分类替换
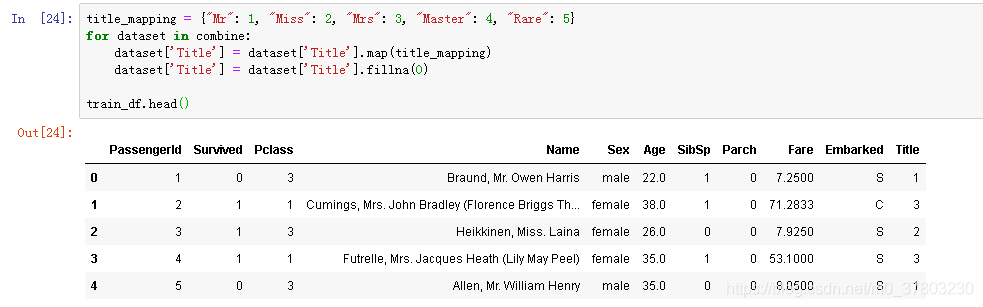
将字符串型转换为数字。此处也可以使用labelencoder
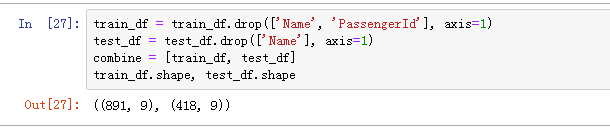
将姓名特征删除。注意测试集为何不删除id,因为id是后续需要提交的标志字段
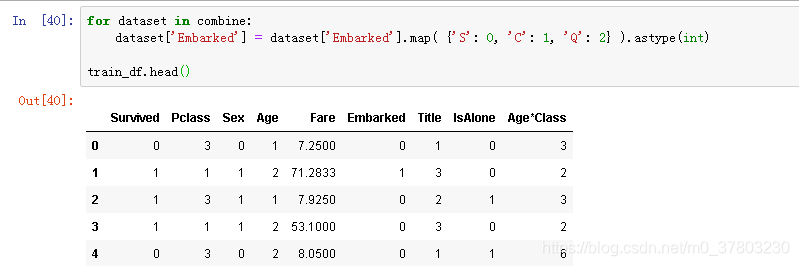
转换类别型特征
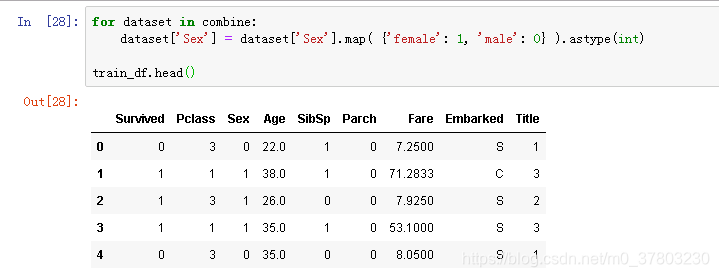
此处也可使用独热算法或者labelencoder
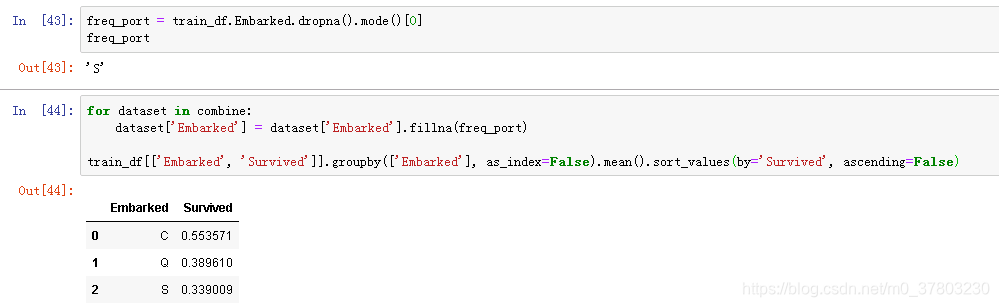
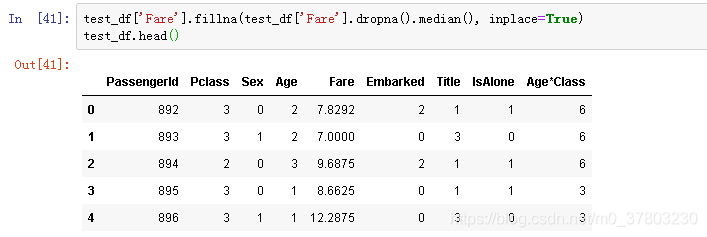
缺失值填补
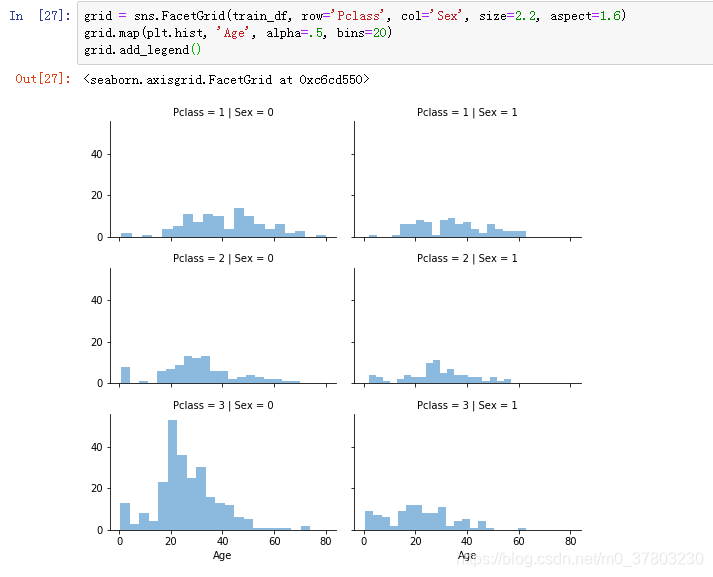
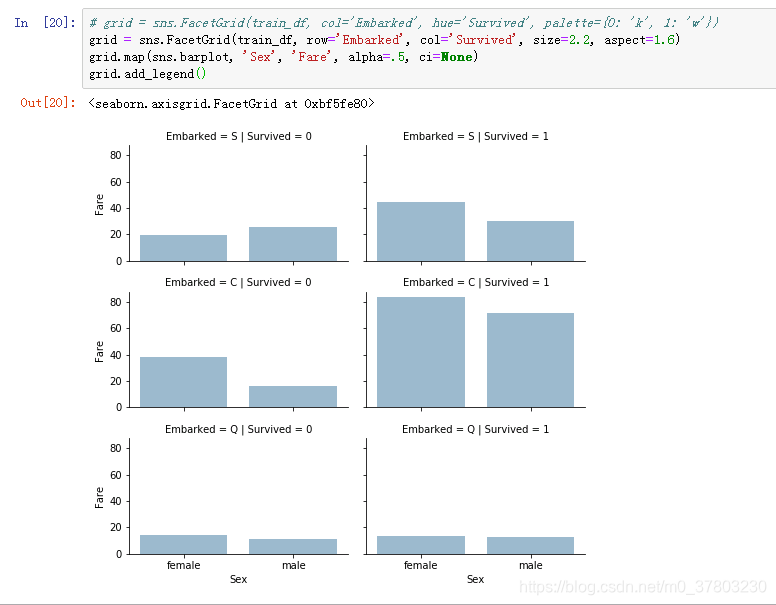
观察到船舱等级、性别与岁数分布的关系。见图。
决定采用中位数的方式来进行填补。
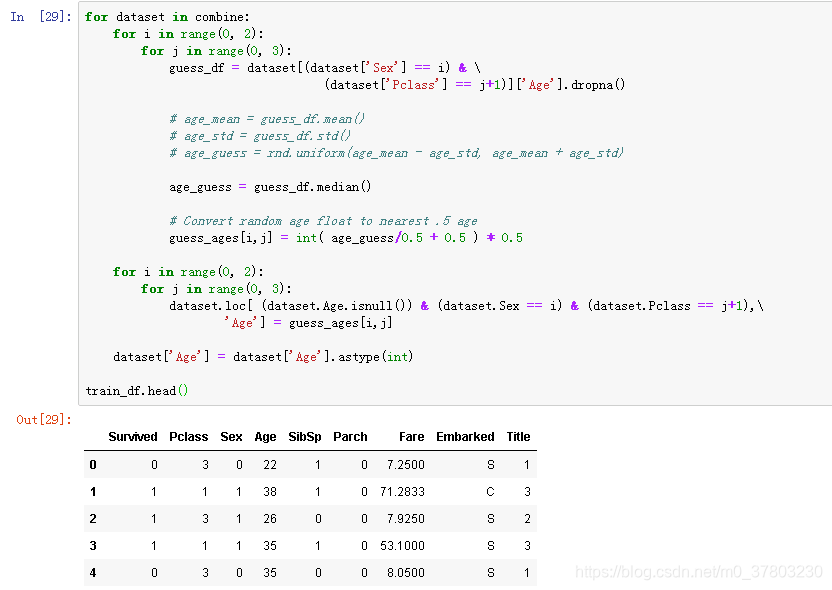
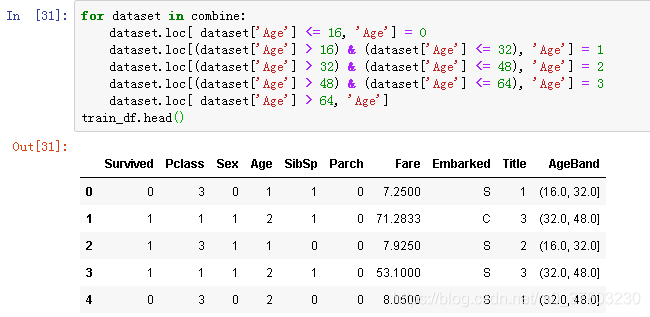
数据按范围划分
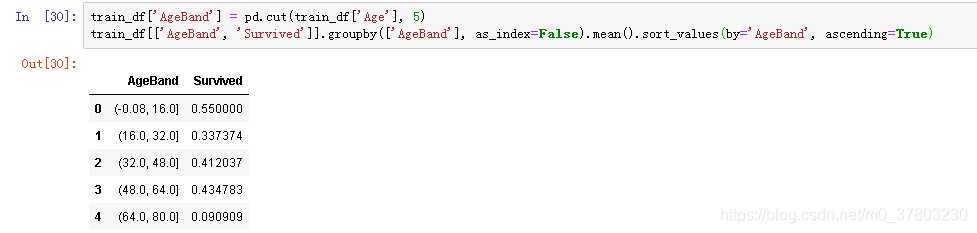
合并多变量
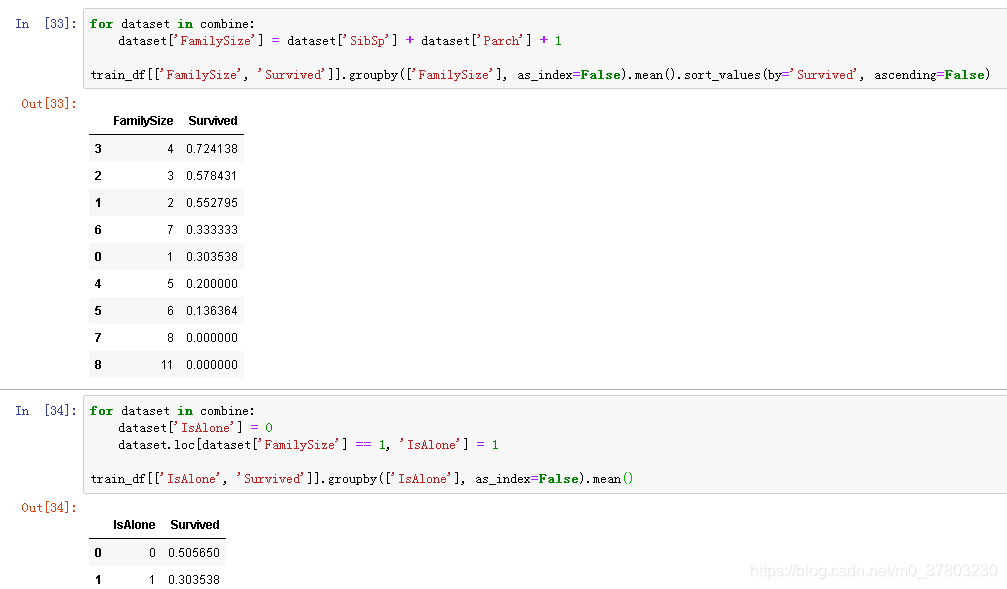
构建全新特征

类别性特征缺失值处理

建模分析
库函数导入

数据划分

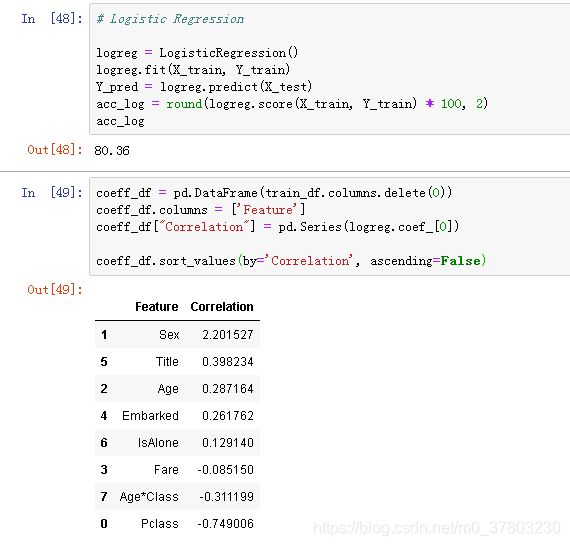
逻辑回归
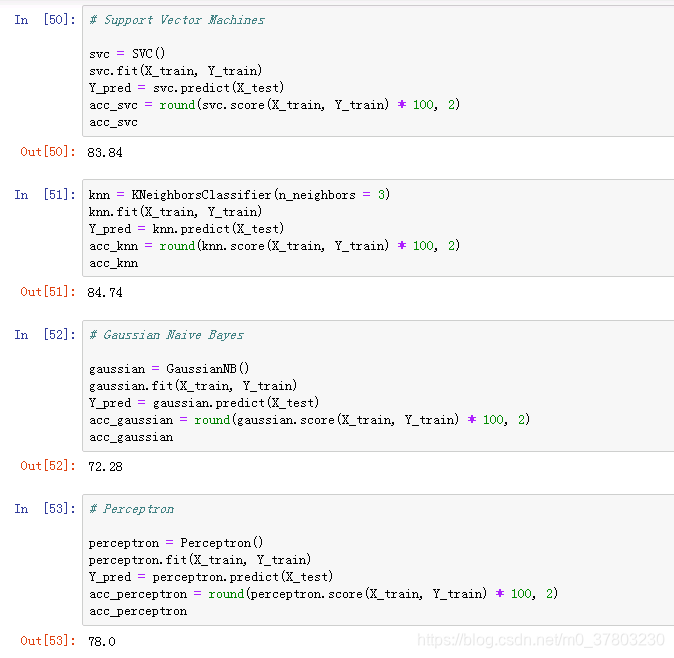
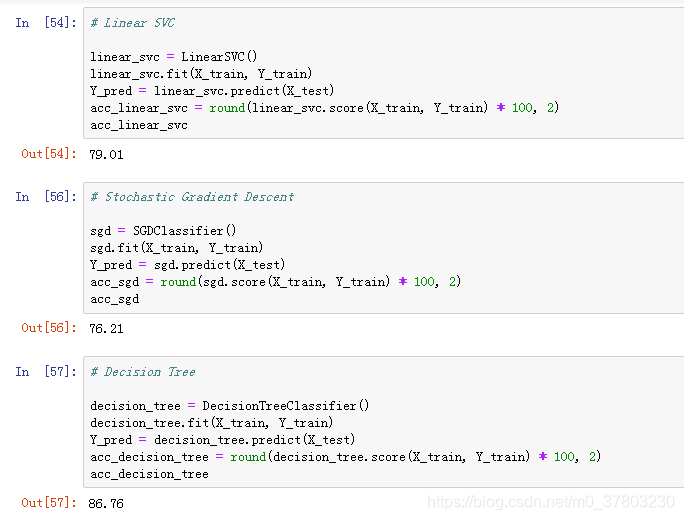
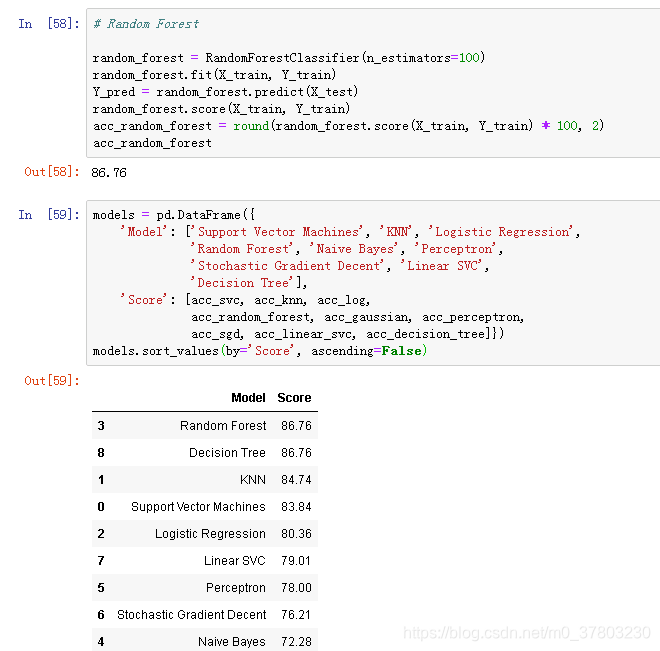
分类模型



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









