










map vs mapPartitions
1.源码
1.1.map算子源码
def map[U: ClassTag](f: T => U): RDD[U] = withScope {
val cleanF = sc.clean(f)
new MapPartitionsRDD[U, T](this, (context, pid, iter) => iter.map(cleanF))
}
1.2.mapPartitions算子源码
def mapPartitions[U: ClassTag](
f: Iterator[T] => Iterator[U],
preservesPartitioning: Boolean = false): RDD[U] = withScope {
val cleanedF = sc.clean(f)
new MapPartitionsRDD(
this,
(context: TaskContext, index: Int, iter: Iterator[T]) => cleanedF(iter),
preservesPartitioning)
}
1.3.对比
相似
map算子和mapPartitions算子底层都是构件MapPartitionsRDD
区别
函数功能方面
map算子传入的函数的功能,是将一个元素处理后返回另一个元素;
mapPartitions算子传入的函数的功能,是将一个迭代器(一批元素)处理后返回另一个迭代器(一批元素);
函数执行方面
map算子中,一个迭代器中包含算子需要处理的所有元素,有多少个元素,传入的函数就执行多少次;
mapPartitions算子中,一个迭代器包含一个分区中的所有元素,函数一次处理一个迭代器的数据,即一个分区调用一次函数;
1.4.执行次数验证
代码
val lineSeq = Seq(
"hello me you her",
"hello you her",
"hello her",
"hello"
)
val rdd = sc.parallelize(lineSeq, 2)
.flatMap(_.split(" "))
println("===========mapPartitions.start==============")
rdd.mapPartitions(iter => {
println("mp+1")
iter.map(x =>
(x, 1)
)
}).collect()
println("===========map.start==============")
rdd.map(x => {
println("mp+2")
(x, 1)
}).collect()
执行结果
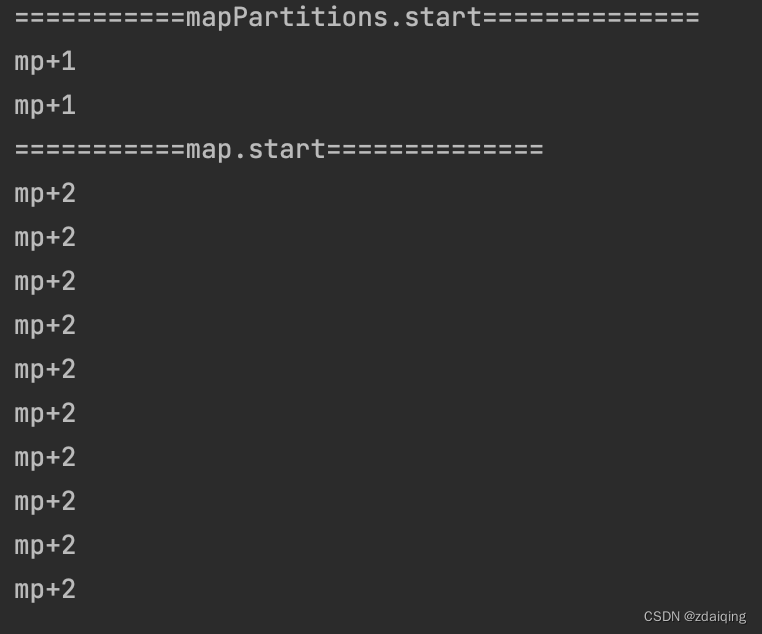
2.特点
map算子
有多少元素,函数执行多少次
mapPartitions算子
有多少分区,函数执行多少次
函数参数是一个迭代器,返回的也是一个迭代器
3.使用场景分析
在进行简单元素表现形式转换操作时,建议使用map算子,避免使用mapPartitions算子:
mapPartitions的函数需要返回一个迭代器,在处理简单元素表现形式的转换操作时,需要用一个中间缓存将处理结果存储起来,然后再转换为迭代器缓存;这个情况下,中间缓存是存放在内存中的,如果迭代器中需要处理的元素比较多,容易引起OOM;
在在大数据集情况下的资源初始化开销和批处理处理的场景中,建议使用mapPartitions算子:
基于spark分布式执行算子的特性,每个分区都需要单独做一次资源初始化;mapPartitions一个分区只执行一次函数的优势可以实现一个分区只需进行一次资源初始化(eg:需要进行数据库链接的场景);
4.参考资料
Spark系列——关于 mapPartitions的误区
Spark—算子调优之MapPartitions提升Map类操作性能
Learning Spark——Spark连接Mysql、mapPartitions高效连接HBase
mapPartition















 154
154











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









