






pt-diskstats —— 一个用于GNU/Linux的交互式I/O监视工具。
pt-diskstats打印GNU/Linux的磁盘I/O统计数据。它有点类似于iostat,但它是交互式的,而且更加详细。它可以分析从另一台机器上收集的样品。
描述
pt-diskstats工具类似于iostat,但是有一些优点。它单独打印读和写统计信息,并且有更多的列。它是菜单驱动和交互式的,有几种不同的方式来聚合数据。它与pt-stalk工具集成良好。默认情况下,它还执行“正确的操作”,比如隐藏空闲的磁盘。这些特性使得快速钻取I/O性能和检查磁盘行为非常方便。
pt-diskstats可以工作在两种模式下,第一是工作在交互模式下,该模式下我们可以动态控制pt-diskstats的输出,立刻看到结果,第二种是先收集/proc/diskstats的信息,存到一个文件里面,采集一段时候后再通过pt-diskstats来计算。;本文档后面有一个shell脚本,展示了如何收集这样的文件。
这种模式下无人值守,用一个脚本在后台定时采集/proc/diskstats,采集完后我们用工具分析最终结果好了,最后我们可以得出该段时间内的整体IO性能,而不是瞬间的性能指标
在这两种情况下,工具都是由键盘交互控制的,因此您可以灵活、轻松地重新显示和切片数据。它会一直循环,直到你用“q”键退出为止。如果你按下 ?你将打开一个“帮助”互动菜单,显示哪些键控制程序。
交互模式下 按?键出现帮助菜单:

A:每个snapshot每个磁盘设备一行
D:每个磁盘一行
S:一个snapshot只输出一行,所有设备聚合在一起
c:查看某列
/:查看某系列磁盘 (正则)
z:聚合时间步长
i:隐藏没有IO活动的设备
p:暂停
q:退出
space:回车是输出表头
当程序收集/proc/diskstats的样本并刷新其显示时,每次刷新时都会打印关于最新样本的信息。当它对保存的示例文件进行操作时,每当您更改一个选项时,它都会重新绘制整个文件的内容。
该程序不会打印系统上每个块设备的信息。它隐藏了从未观察到有任何活动的设备。您可以通过按下“i”键启用和禁用此功能。
在本文档的其余部分中,我们将尝试澄清块设备(例如/dev/sda1)和块设备下的物理设备(通常是磁盘、RAID控制器等)之间的区别,前者由内核通过文件系统呈现给应用程序。我们有时会引用发生在块设备上的逻辑I/O操作,而不是在底层设备上执行的物理I/Os。当我们提到队列时,我们指的是与块设备相关联的队列,它持有请求,直到它们被发送到物理设备为止。
程序的输出看起来像下面的示例,对于这个手册页来说太宽了,所以我们用换行符将它格式化为几个示例:

列说明如下:
#ts:
如果按照disk聚合,该值代表运行的总时间,如果按照sample聚合,该值也代表当前运行的时间,如果按照all聚合,代表两个快照间时间间隔。
device:
- 设备名称。如果有多个设备,则用{花括号}显示聚合到行的设备数量。
rd_s:
-
每秒读取的平均次数。这是发送到底层设备的I/O请求的数量。这通常比应用程序发出的逻辑IO请求的数量要少。
-
更多的请求可能已经排队到块设备,但其中一些请求通常在发送到磁盘之前被合并。
-
该字段从/proc/diskstats的内容计算,如下所示:
delta[field1] / delta[time]
rd_avkb:
-
读取的平均大小,以千字节为单位。(kb)
2 * delta[field3] / delta[field1]
rd_mb_s:
-
每秒读取的平均兆字节数
2 * delta[field3] / delta[time]
rd_mrg:
-
在发送到物理设备之前,在队列调度程序中合并在一起的读请求的百分比。计算字段如下:
100 * delta[field2] / (delta[field2] + delta[field1])
rd_cnc:
-
根据利特尔定律计算的读操作的平均并发性。这是块设备上的端到端并发性,而不是底层磁盘上的并发性。它包括在队列中花费的时间。计算字段如下:
delta[field4] / delta[time] / 1000 / devices-in-group
rd_rt:
-
读取操作的平均响应时间(以毫秒为单位)。这是端到端响应时间,包括在队列中花费的时间。发出I/O请求的应用程序看到的是响应时间,而不是块设备底层物理磁盘的响应时间。计算方法如下:
delta[field4] / (delta[field1] + delta[field2])
wr_s, wr_avkb, wr_mb_s, wr_mrg, wr_cnc, wr_rt
- 这些列显示写活动,并与读活动的相应列匹配。
busy:
-
该设备至少有一个请求正在进行的时间的百分比;
-
这就是iostat所称的%util,实际上它是利用率,这取决于您如何定义利用率,但在通常的说法中,这有时是含糊不清的。
-
也可以称为停留时间;至少一个请求驻留在系统中的时间。
计算方法如下:
100 * delta[field10] / (1000 * delta[time])
- 除非有舍入误差,否则该字段不能超过100%,但是认为一直处于忙碌状态的设备已经饱和是常见的错误。RAID卷之类的设备应该支持高于1的并发性,而固态驱动器可以支持非常高的并发性。并发性可以在没有绑定的情况下增长,并且是设备实际负载情况的更可靠指示器。
in_prg
-
正在进行的请求数量。与读写组合不同,读写组合是由可靠的数字生成的平均值,这个数字是一个瞬时样本,您可以看到它可能代表一个请求高峰,而不是真正的长期平均值。如果这个数字很大,本质上意味着设备负载很重。计算方法如下:
field9
ios_s
- 物理设备的平均吞吐量,以每秒I/O操作(IOPS)表示。本列显示底层设备正在处理的IOPS总数。它是rd_s和wr_s的和。
qtime
- 平均排队时间;也就是说,一个请求在发送到物理设备之前在设备调度程序队列中花费的时间。这是读写的平均值。
- 计算方法稍微复杂一些:应用程序所看到的平均响应时间减去平均服务时间(参见下一列的描述)。这是从响应时间的排队理论公式得到的,R = W + S:响应时间=队列时间+服务时间。这就解出了W,当然,得到W = R - s,计算如下:
delta[field11] / (delta[field1, 2, 5, 6] + delta[field9])-delta[field10] /delta[field1, 2, 5, 6]
stime
-
平均使用时间;也就是说,物理设备在请求在队列中完成等待后处理请求所花费的时间。这是读写的平均值。由排队理论利用率公式U = SX计算得到s,即利用率除以吞吐量得到服务时间:
delta[field10] / (delta[field1, 2, 5, 6])
-
但是,请注意,可能有一些内核bug导致/proc/diskstats中的字段9变为负值,这可能导致字段10出错,从而使服务时间计算不完全可信。
-
注意,在上面的公式中,我们非常具体地使用了利用率。这是一个持续时间,而不是百分比。
-
您可以比较stime和qtime列,以查看读和写的响应时间是在队列中还是在物理设备上。但是,您无法看到读和写之间的区别。改变块设备调度算法可以大大提高队列时间。默认的算法cfq对服务器非常不利,应该只在执行电子表格处理和上网等任务的笔记本电脑和工作站上使用。
-
如果您习惯使用iostat,您可能想知道在pt-diskstats中何处可以找到相同的信息。下面是在同一台机器上同时使用这两种工具的两个输出示例,分别用于/dev/sda,并对其进行包装以适应:


列之间的对应不是一对一的。特别是:
rrqm/s, wrqm/s
iostat中的这些列被pt-diskstats中的rd_mrg和wr_mrg替换。
avgrq-sz
本列位于iostat中的扇区中,是读和写的组合。pt-diskstats输出将这些数据分开显示,并用kB表示。您可以通过pt-diskstats中的rd_avkb和wr_avkb的加权平均值得到它,然后乘以2得到扇区(每个扇区512字节)。
avgqu-sz
这一列实际上表示块设备调度程序的并发性。pt-diskstats输出分别显示读写的并发性:rd_cnc和wr_cnc。
await
这一列是请求到块设备从开始到结束的平均响应时间,包括队列时间和服务时间,在pt-diskstats中没有显示。相反,pt-diskstats显示读写操作在磁盘级别上的单个响应时间(rd_rt和wr_rt),以及读写操作的队列时间和服务时间的总和。
svctm
这一列是磁盘上的平均服务时间,在pt-diskstats中显示为stime。
%util
这个列在pt-diskstats中称为busy。利用率通常定义为至少有一个活动请求的时间部分,而不是百分比,这就是为什么我们选择避免这个混淆的术语。
收集数据
为该工具收集数据样本非常简单。文件应该是这种格式,在每个统计数据样本之前有一个时间戳行:

您可以简单地使用pt-diskstats和- -save-samples来为您收集这些数据。如果您希望捕获样例作为其他一些工具的一部分,并使用pt-diskstats来分析它们,您可以包含一个shell脚本片段,例如:

内核文件
本文件补充关于/proc/diskstats.内容的正式文件
对于那些不熟悉Linux内核内部的人来说,这些文档有时很难理解。/proc/diskstats的内容由内核源文件块/ genhdc中的diskstats_show()函数生成。
下面是最近内核上的/proc/diskstats示例。

- 这个示例中的字段如下。前三个字段是主设备号(不同类别设备编号不一样,磁盘统一为8)和副设备号(比如sda的sda为0,sda1位1,sda2为2.也就是一个物理磁盘后面的分区,编号依次递增)(8,1)以及设备名(一般ide接口的以hd[a-d]口命名,scsi和sata接口的以sd[a-z]命名。)(sda1)。其后是11个统计范畴:
-
- 1.已完成的读取次数。这是底层磁盘执行的物理读操作的数量,而不是应用程序从块设备执行的读操作的数量。这意味着426个对/dev/sda1所在磁盘的实际读取已经成功完成。读完才算读。
-
- 2.读取的数量合并,因为它们是相邻的。在示例中,合并了243个读取。这意味着/dev/sda1实际上接收了869个逻辑读,但是只向底层物理设备发送了426个物理读。
-
- 3.读取成功的扇区数。对磁盘的426个物理读操作读取3386扇区。扇区是512字节,因此从/dev/sda1.总共读取了大约1.65MB
-
- 4.用于读取的毫秒数。这只计算已完成的读操作,而不是正在进行的读操作。它计算从请求放置到队列完成所花费的时间,而不是底层磁盘为请求服务所花费的时间。也就是说,它度量应用程序所看到的总响应时间,而不是磁盘响应时间。
-
- 5.同字段1 ,但是用于写。
-
- 6.同字段2 ,但是用于写。
-
- 7.同字段3 ,但是用于写。
-
- 8.同字段4 ,但是用于写。
-
- 9.当前正在进行的I/Os数量,也就是说,它们已经由队列调度程序调度并分发到磁盘(提交到底层磁盘的队列),但尚未完成。有些内核中有bug导致这个数字,因此字段10和11有时是错误的。
-
- 10.执行I/Os所花费的总毫秒数。这不是应用程序所看到的总响应时间,而是至少一个I/O正在进行的总时间。如果一个I/O在100时发出,另一个I/O在101时发出,两个I/O都在102时完成,那么这个字段将增加2,而不是3。
-
- 11.该字段计算所有I/Os的总响应时间。与字段10相反,当两个I/Os重叠时,它的计数加倍。在前面的例子中,这个字段将增加3,而不是2。
参数
这个工具接受额外的命令行参数
- -columns-regex
类型:字符串;默认值: .
打印与此Perl正则表达式匹配的列。
- -config
类型:数组
读取这个逗号分隔的配置文件列表;如果指定,这必须是命令行上的第一个选项。
- -devices-regex
类型:字符串
打印与此Perl正则表达式匹配的设备。
- -group-by
类型:字符串;默认值:all
Group-by 模式: disk, sample,或all.
在disk模式下,每一行输出显示一个磁盘设备,以及自工具启动以来计算的统计数据。在sample模式中,每一行输出显示一个统计数据示例,所有磁盘平均在一起。在所有模式下,每一行输出都显示一个示例和一个磁盘设备。
- -headers
类型:hash;默认值:group,scroll
如果存在group,则每个示例之间将用空行分隔,除非该示例只有一行。如果
出现滚动,该工具将根据需要随时打印标题,以防止它们滚动到视图之外。
请注意,您可以按空格键或回车键随意重新打印标题。
- -help
帮助并退出
- -interval
type: int; default: 1
在交互模式下,在打印到屏幕前等待N秒(默认为1)。此外,该工具应该对/proc/diskstats进行采样的频率
该工具试图精确地收集时钟时间间隔为偶数的统计数据。也就是说,如果指定一个5秒间隔,它将尝试在12:00:00、12:00:05等时间捕捉样本;它不会在12:00:01 12:00:06收集。
在某些情况下,这可能导致稍微奇怪的延迟,因为工具在打印出第一组行之前要等待一个完整的周期。(与iostat和vmstat不同,pt-diskstats不以表示计算机启动以来的平均值的行开始。)因此,规则有一个例外,以避免非常长的延迟。
假设您指定了一个10秒间隔,但是您在12:00:00.01启动该工具。该工具可能要等到12:00:20才打印它的第一行输出,在中间的19.99秒内,它似乎什么也不做。
为了缓解这种情况,工具会等到下一个偶数间隔的时间才收集数据,除非该间隔的20%以上仍然存在。这意味着该工具不会等待超过120%的采样间隔来产生输出,如果您在12:00:53以10秒的采样间隔启动该工具,那么第一个采样将只有7秒长,而不是10秒。
- -iterations
类型:int
运行命令N秒后停止。默认情况下永远运行。
- -sample-time
type: int; default: 1
在-group-by sample模式中,每组包含N秒的样本。
- -save-samples
type: string
用于保存diskstats样本的文件; 这些可以用于以后的分析。
- -show-inactive
显示非活动设备
- -show-timestamps
在#ts列中显示’ HH:MM:SS '时间戳。如果将多个时间戳聚合到一行中,将显示第一个时间戳。
- -version
显示版本并退出
- -[no]version-check
default: yes
查看Percona Toolkit、MySQL和其他程序的最新版本。
演示:
1.不加任何参数:

2.使用正则匹配:
pt-diskstats --devices-regex sd[a-z]

pt-diskstats --columns-regex rd
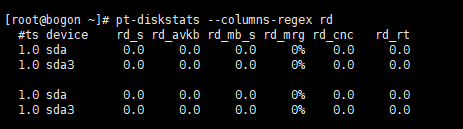
3.规定打印到屏幕前等待的时间
pt-diskstats --interval 2

4. 在分组样本模式下,每组包含5秒样本
pt-diskstats --group-by sample --sample-time 5

5. 显示时间戳
pt-diskstats --show-timestamps

6. 文件形式进行统计输出
通过前文脚本抓取部分数据
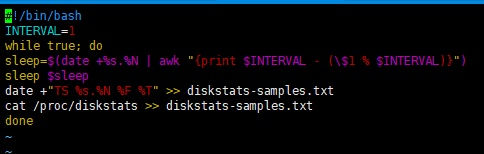
抓取到的数据:

pt-diskstats --group-by sample diskstats-samples.txt

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









