







1.什么是spring cloud stream
这是一个用来为微服务应用构建消息驱动能力的框架,本质上就是整合了spring boot和spring Integration ,而spring integration的功能就是解决不同系统之间交互的问题。通过异步消息消息驱动来达到系统交互时系统之间的松耦合。
2.快速入门
首先配置依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-rabbit</artifactId>
</dependency>接着创建消费者
@EnableBinding :实现了对消息通道(channel)的绑定
@EnableBinding (Sink.class) :绑定了Sink接口,该接口是Spring cloud Stream中默认实现的对输入消息通道绑定的定义
@EnableBinding(Sink.class)
public class SinkReceiver {
private static Logger logger=LoggerFactory.getLogger(StreamHelloApplication.class);
@StreamListener(Sink.INPUT)
public void receive(Object payload){
logger.info("Receive---------------------------------------:"+payload);
}
}
从代码中可以看到通过注解的方式绑定了一个名字为input的通道
public interface Sink {
String INPUT = "input";
@Input("input")
SubscribableChannel input();
}既然有输入就会有输出
public interface Source {
String OUTPUT = "output";
@Output("output")
MessageChannel output();
}
当需要绑定多个接口的时候,只需要用逗号隔开,添加类即可
@EnableBinding({Sink.class,Source.class})
public class SinkReceiver {
private static Logger logger=LoggerFactory.getLogger(StreamHelloApplication.class);
@StreamListener(Sink.INPUT)
public void receive(Object payload){
logger.info("Receive---------------------------------------:"+payload);
}
}@StreamListener
将方法作为消息的监听器
@StreamListener(Sink.INPUT)
public void receive(Object payload){
logger.info("Receive---------------------------------------:"+payload);
}3.核心概念
绑定器
这里的Binder是指Stream的Binde,如果没有Binder,那么spring boot 在使用消息中间件的时候,由于每个消息中间件都不太相同,一旦切换将会使代码重构。而使用了Binder之后,最终暴露给用户的只有Channel
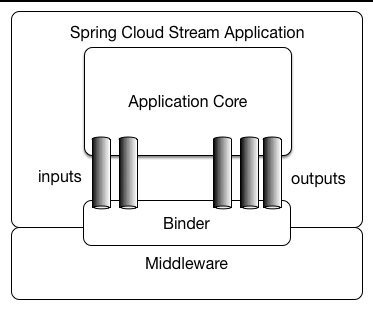 .
.
发布-订阅模式
Stream的消息通讯方式遵循了发布-订阅模式,当一条消息发送到消息中间件后,它会通过共享的Topic主题进行广播,消息消费者在订阅的主题中收到它并触发相关事务。对于Topic只是一个抽象概念,在MQ中是Exchange,在Kafaka中则是Topic
相对于点对点队列实现的消息通信来说,Spring Cloud Stream 采用的发布-订阅模式可以有效降低消息生产者与消费者之间的耦合。当需要对同一类消息增加一种处理方式时,只需要增加一个应用程序并将输入通道绑定到既有的Topic中就可以实现功能的扩展,而不需要改变原来已经实现的任何内容
消费组
由于我们的每一个微服务应用都会有多个实例,但是我们只希望消息只被其中一个实例消费一次,所以有了消费组的概念。当多个实例在同一组的时候,也就是设置spring.cloud.stream.bindings.input.group属性的时候,那么消息只会被其中一个实例消费一次。默认情况下,Stream默认分配了一个独立的匿名消费组。所以,如果不是必须像刷新配置一样,最好是指定消费组。
消息分区
指定某一个实例消费信息。Stream为分区提供了抽象实现,所以它不在乎消息中间件是否有分区功能。
4.使用详解
开启绑定功能@EnableBinding
它只有唯一一个属性:value。上面已经介绍过,由于该注解已经被@Import了BindingBeansRegistrar实现,所以在加载了基本配置内容之后,它会回调来读取value中的类,以创建消息通道的绑定。另外,由于value是一个Class类型的数组,所以我们可以通过value属性一次性指定多个关于消息通道的配置。
@Target({ElementType.TYPE, ElementType.ANNOTATION_TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
@Configuration
@Import({BindingServiceConfiguration.class, BindingBeansRegistrar.class, BinderFactoryConfiguration.class, SpelExpressionConverterConfiguration.class})
@EnableIntegration
public @interface EnableBinding {
Class<?>[] value() default {};
}绑定消息通道
value里面填的接口对象,里面有消息通道的定义,通过接口对象进行通道绑定
@EnableBinding({Sink.class,Source.class})定义了输入通道
public interface Sink {
String INPUT = "input";
@Input("input")
SubscribableChannel input();
}定义了输出通道
public interface Source {
String OUTPUT = "output";
@Output("output")
MessageChannel output();
}通过继承直接定义输入和输出通道
public interface Processor extends Source, Sink {
}注入绑定接口
在完成了消息通道绑定的定义之后,Stream会为其创建具体的实例,而开发者只需要通过注入的方式来获取这些实例并直接使用即可。
public interface SinkSender {
@Output(Sink.INPUT)
MessageChannel output();
}
增加接口,使Stream 能创建出对应的实例
@EnableBinding({Sink.class,Source.class,Processor.class,SinkSender.class})配置文件
需要配置一个相同的主题Topic
spring.cloud.stream.bindings.input.destination=raw-sensor-data
spring.cloud.stream.bindings.output.destination=raw-sensor-data
spring.cloud.stream.bindings.input-1.destination=raw-sensor-data
spring.cloud.stream.bindings.output-1.destination=raw-sensor-data测试
分别为系统的默认消息通道,自定义消息通道,直接注入的消息通道
@RunWith(SpringRunner.class)
@SpringBootTest
public class StreamHelloApplicationTests {
@Autowired
private Processor processor;
@Autowired
private SinkSender sinkSender;
@Autowired
private MessageChannel output;
@Test
public void contextLoads() {
processor.output().send(MessageBuilder.withPayload("From SinkSender").build());
output.send(MessageBuilder.withPayload("From SinkSender-LLG").build());
sinkSender.output().send(MessageBuilder.withPayload("From SinkSender-LLG").build());
}
}
5.消息生产与消费
由于Stream 是由 Spring Integration 构建起来的,所以可以使用Integration提供相同服务
@ServiceActivator类比于@StreanListener,实现了对Sink.INPUT通道的监听处理,而该通道绑定了名为input的主题,这个主题就是我们在配置文件上配置的,必须确保input和output为同一个主题Topic.
@StreamListener(SinkSender.INPUT)
public void receives(Object payload){
logger.info("Receive---------------------------------------:"+payload.toString());
}
@ServiceActivator(inputChannel = SinkSender.INPUT)
public void receivess(Object payload){
logger.info("Receive---------------------------------------:"+payload.toString());
}共用一个主题Topic,构成了一组生产者与消费者 。 @InboundChannelAdapter是对通道的输出绑定,同时使用Poller轮询的方式执行
@Bean
@InboundChannelAdapter(value=SinkSender.OUTPUT,poller = @Poller(fixedDelay = "2000"))
public MessageSource<Date> timerMessageSource(){
return ()->new GenericMessage<>(new Date());
}消息转换
@Transformer(inputChannel = SinkSender.INPUT,outputChannel = SinkSender.OUTPUT)
public Object transform(Date message){
return new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(message);
}@StreamListener详解
@StreamListener虽然同@ServiceActivator功能相似,但是功能更加强大
消息转换
例如将json字符串转换成java对象
使用@Transformer注解实现,通过上面的例子,我们可以通过代码的方式去实现消息的转化。
使用@StreamListener注解实现,只需要指定传输过来的数据格式即可,因为Stream已经有了内置的消息转换机制,我们无需重复编写。所以说对于此注解来说,只是多写了一个配置信息而已。
spring.cloud.stream.bindings.input-1.content-type=application/json消息反馈
处理完消息之后,需要反馈一个消息给对方,这时候可以通过@SendTo注解来指定返回内容的输出通道
使用sendto注解即可搞定.对于配置信息,要确保绑定的topic也就是destination是同一个在可以实现订阅,因为通道名字会默认为交换机exchange也就是topic的名字,所以在测试的时候例如在一个应用里面要记得配置相同的交换机。
@StreamListener(SinkSender.INPUT)
@SendTo(SinkSender.OUTPUT)
public Object receives(Object payload){
logger.info("Receive---------------------------------------:"+payload.toString());
return "From llg Channe Return";
}
App1
spring.cloud.stream.bindings.input-1.destination=input-1
spring.cloud.stream.bindings.output-1.destination=output-1
App2
spring.cloud.stream.bindings.input-1.destination=output-1
spring.cloud.stream.bindings.output-1.destination=input-1相比较于Sendto,我们同样可以使用原生注解@ServiceActivator来实现
@ServiceActivator(inputChannel = SinkSender.INPUT,outputChannel = SinkSender.OUTPUT)
public Object receivess(Object payload){
logger.info("Receive---------------------------------------:"+payload.toString());
return "测距送!!!!!!!!!!!!!!";
}响应式编程实现消息的处理和输出
首先引入rxjava-stream的相关依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-rxjava</artifactId>
</dependency>开始对监听通道进行改造
@EnableRxJavaProcessor
public class SinkReceiver {
private static Logger logger=LoggerFactory.getLogger(StreamHelloApplication.class);
@Bean
public RxJavaProcessor<String,String> processor(){
return inputStream->inputStream.map(data-> {
logger.info("Receive---------------------------------------:" + data);
return data;
}).map(data->String.valueOf("From Input Channel Return -" + data));
}
}首先对比@EnableRxJavaProcessor,作用相当于@EnableBing.可以看到里面其实就是包含了@EnableBinding
/** @deprecated */
@Target({ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
@EnableBinding({Processor.class})
@Import({RxJavaProcessorConfiguration.class})
@Deprecated
public @interface EnableRxJavaProcessor {
}
继续看返回对象,定义了一个用来处理输入通道和返回内容给输出通道的process方法,由于设置输入输出都采用了Observable,所以该方法只会在应用启动的时候被调用一次,用来设置输入输出都采用了Observable.
@Deprecated
public interface RxJavaProcessor<I, O> {
Observable<O> process(Observable<I> var1);
}由于我们使用了Rxjava,我们可以轻松实现消息缓存,比如接收到5条消息才将信息返回。
@EnableRxJavaProcessor
public class SinkReceiver {
private static Logger logger=LoggerFactory.getLogger(StreamHelloApplication.class);
@Bean
public RxJavaProcessor<String,String> processor(){
return inputStream->inputStream.map(data-> {
logger.info("Receive---------------------------------------:" + data);
return data;
}).buffer(5).map(data->String.valueOf("From Input Channel Return -" + data));
}
}6.消费组与消息分区
消费组
消费组的概念上文说过,其实就是如果出现需要让服务中多个实例的其中一个消费消息的话,就需要设置消费组进行隔离标记。
不难理解,最主要还是因为是订阅模式,所以会统一发送消息,并且默认组名是匿名组,所以也就自然而然的对服务的所有实例发送了,下面我们来设置消费组。
可以看到配置一个组名Service ,那么开启多个实例的时候自然而然的所有实例的组名都是Service.所以消费组的意思就是把一个服务按一个组划分,每次只传递一个消息到这个组来,再随机给其中的一个实例消费。
spring.cloud.stream.bindings.input.group=Service
spring.cloud.stream.bindings.input.destination=input
spring.cloud.stream.bindings.output.destination=input消息分区
为了将某些特定的消息给特定的实例消费,所以需要设置消息分区
首先需要在消费者应用配置信息
- spring.cloud.stream.bindings.input.consumer.partitioned=true :开启消费者分区功能
- spring.cloud.stream.instance-count=2 :指定了消费者的实例总数
- spring.cloud.stream.instance-index=0 :索引号,从0开始。必须每个实例按索引为0开始递增
spring.cloud.stream.bindings.input.group=Service
spring.cloud.stream.bindings.input.destination=input
spring.cloud.stream.bindings.output.destination=input
spring.cloud.stream.bindings.input.consumer.partitioned=true
spring.cloud.stream.instance-count=2
spring.cloud.stream.instance-index=0接着配置生产者
- spring.cloud.stream.bindings.output.producer.partition-key-expression=payload 指定了分区键的表达式规则
- spring.cloud.stream.bindings.output.producer.partition-count=2 指定了消息分区的数量
spring.cloud.stream.bindings.output.producer.partition-key-expression=payload
spring.cloud.stream.bindings.output.producer.partition-count=27.消息类型
类似于springmvc的消息转换器等等,Stream允许使用sprinc.cloud.stream.bindings.<channelName>.content-type 属性以声明式的配置方式为绑定的输入和输出通道设置消息内容的类型。
json------pojo
json------org.springframework.tuple.Tuple
object-------byte[] 传输序列化数据
string--------byte[]
object-----纯文本
spring cloud stream 会将所有org.springframework.messaging.converter.MessageConverter接口实现的自定义转换器以及默认实现的那些转换器都加载到消息转换工厂中,以提供给消息处理时使用。
8.绑定器详解
绑定器SPI
最为关键的接口是Binder接口,它是用来将输入和输出连接到外部中间件的抽象。
public interface Binder<T, C extends ConsumerProperties, P extends ProducerProperties> {
Binding<T> bindConsumer(String var1, String var2, T var3, C var4);
Binding<T> bindProducer(String var1, T var2, P var3);
}
应用程序对输入和输出通道进行绑定的时候,实际上就是通过该接口的实现来完成的。
- 向消息通道发送数据的生产者调用bindProducer方法来绑定输出通道时,第一个参数代表了发往消息中间件的目标名称,第二个参数代表了发送消息的本地通道实例,第三个参数是用来创建通道时使用的属性配置(比如分区键的表达式等)。
- 从消息通道接受数据的消费者调用bindConsumer方法来绑定输入通道时,第一个参数代表了接受消息中间件的目标名称,第二个参数代表了消费组的名称(如果多个消费者实例使用相同的组名,则消息将对这些消费者实例实现负载均衡,每个生产者发出的消息只会被组内一个消费者实例接受接受和处理),第三个参数代表了接受消息的本地通道实例,第四个参数是用来创建通道时使用的属性配置。
一个典型的Binder绑定器实现一般包含以下内容。
- 一个实现Binder接口的类
- 一个Spring配置加载类,用来创建连接消息中间件的基础结构使用的实例。
- 一个或多个能够在classpath下的META-INF/spring.binders路径找到的绑定器定义文件。比如我们可以再spring-cloud-starter-stream-rabbit中找到该文件,该文件中存储了当前绑定器要使用的自动化配置类的路径:
自动化配置
Spring Cloud Stream 通过绑定器SPI的实现应用程序逻辑上的输入输出通道连接到物理上的消息中间件。为了适应多个消息中间件的差异,所以需要实现各自的绑定器
下面的依赖包括了rabbitmq的binder依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-rabbit</artifactId>
</dependency> <dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-rabbit</artifactId>
</dependency>还有kafaka的绑定器
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud--stream-binder-kafka</artifactId>
</dependency>
多绑定器配置
就是说可以同时用多种消息中间件
首先如果我们需要默认为某种绑定器的时候,比如默认为rabbit的绑定器
spring.cloud.stream.default-binder=rabbit对于一些少数的消息通道需要单独设置绑定器,通过上面的配置我们可以发现我们是直接写rabbit和kafka,但是这不是代表名字,而是某个配置文件的别名。
spring.cloud.stream.bindings.input.binder=kafka对需要使用多个消息中间件,例如消息输入通道和消息输出通道使用不同的消息中间件.显示指定配置别名后会自动禁用默认的绑定器配置,所以我们需要使用spring.cloud.stream.binders.<configurationName>属性来进行设置
spring.cloud.stream.bindings.input.binder=rabbit1
spring.cloud.stream.bindings.output.binder=rabbit2
spring.cloud.stream.binders.rabbit1.type=rabbit
spring.cloud.stream.binders.rabbit1.environment.spring.rabbitmq.host=localhost
spring.cloud.stream.binders.rabbit1.environment.spring.rabbitmq.port=5672
spring.cloud.stream.binders.rabbit1.environment.spring.rabbitmq.username=guest
spring.cloud.stream.binders.rabbit1.environment.spring.rabbitmq.password=guest
spring.cloud.stream.binders.rabbit2.type=rabbit
spring.cloud.stream.binders.rabbit2.environment.spring.rabbitmq.host=192.168.88.8
spring.cloud.stream.binders.rabbit2.environment.spring.rabbitmq.port=5672
spring.cloud.stream.binders.rabbit2.environment.spring.rabbitmq.username=guest
spring.cloud.stream.binders.rabbit2.environment.spring.rabbitmq.password=guest以下是对绑定器的一些属性配置
- spring.cloud.stream.binders.<configurationName>.type 指定了绑定器类型
- spring.cloud.stream.binders.<configurationName>.environment 用来设置各种绑定器属性
- spring.cloud.stream.binders.<configurationName>.inheritEnvironment=true 当前绑定器是否继承应用程序自身额环境配置
- spring.cloud.stream.binders.<configurationName>.defaultCandidate=true 设置当前绑定器配置是否被视为默认绑定器的候选项
RabbitMQ与Kafka绑定器
由于这两者稍有不同,所以绑定器是由Stream实现的。
- RabbitMQ绑定器:在RabbitMQ中,通过Exchange交换器实现主题Topic的概念,消息通道的输入输出目标映射了一个具体的Exchange交换器。而对于每个消费组,则会为对应的Exchange交换器绑定一个Queue队列进行消息收发。
- Kafka绑定器:继续沿用Kafka的Topica主题概念
9.配置详解
基础配置
下面是spring cloud stream 应用级别的通用基础属性,这些属性都以spring.cloud.stream 为前缀
- instanceCount=1 应用程序部署的实例数量。当使用Kafka的时候需要设置分区
- instanceIndex 应用程序实例的索引,该值从0开始,最大值设置为-1.当使用分区和kafka的时候使用
- dynamicDestinations 动态绑定的目标列表,该列表默认为空,当设置了具体列表之后,只有列表中的目标才能发现
- defaultBinder 默认绑定器配置,在应用程序中有多个绑定器时使用
绑定通道配置
绑定通道分别为输入通道和输出通道,所以在绑定通道的配置中包含了三类面向不同通道类型的配置:通用配置、消费者配置、生产者配置
通用配置
下面省略spring.cloud.stream.bindings.<channelName>.前缀
- destination 配置Topic名称,也就是exchange名称 ,如果是消费者可以配置多个并且用逗号隔开
- group 消费组
- contentType 消息类型
- binder 指定那个具体的绑定器
消费者配置
仅对消费者有效,下面省略spring.cloud.stream.bindings.<channelName>.consumer 前缀
- concurrency 输入通道消费者的并发数,默认为1
- partitioned 是否采用分区,默认false
- headerMode 当设置为raw的时候将禁用对消息头的解析。该属性只有在使用不支持消息头功能的中间件时有效,因为Spring Cloud Stream 默认会解析嵌入的头部信息 ,默认值embeddedHeaders
- maxAttempts 对输入通道消息处理的最大重试次数,默认值3
- backOffInitialInterval 重试消息处理的初始间隔时间 ,默认1000
- backOffMaxInterval 重试消息处理的最大间隔时间,默认为10000
- backOffMultiplier 重试消息处理时间间隔的递增乘数 2.0
生产者配置
仅对生产者者有效,下面省略spring.cloud.stream.bindings.<channelName>.producer 前缀
- partitionKeyExpression 配置输出通道数据分区键的SpEL表达式。当设置该属性后,将对绑定通道的输出数据进行分区处理。同时,partitionCount参数必须大于1才能生效。
- partitionKeyExtractorClass 配置分区键提取策略接口PartitionKeyExtractionStrategy 的实现。当设置该属性之后,将对当前绑定通道的输出数据进行分区处理。同时,partitionCount参数必须大于1才能生效,该参数与partitionKeyExpression互斥,不能同时使用
- partitionSelectorClass 该参数用来指定分区选择器的接口PartitionSelectorStrategy的实现,如果两者都没设置,那么默认计算规则为hashCode(key)%partitionCount,这里的key根据上面的配置得到
- partitionSelectorExpression 该参数用来设置自定义分区的选择器的SpEL表达式
- headerMode 当设置为raw的时候将禁用对消息头的解析。该属性只有在使用不支持消息头功能的中间件时有效,因为Spring Cloud Stream 默认会解析嵌入的头部信息 ,默认值embeddedHeaders
绑定器配置
由于Stream只实现了kafka和rabbitmq的实现,所以下面只讲这两种实现
RabbitMQ配置
通用配置
由于rabbitmq默认使用了spring boot 的ConnectFactory,所以Rabbitmq绑定器支持在Spring boot 中的配置选项,他们以spring.rabbitmq为前缀
在Spring Cloud Stream 对RabbitMQ时下的绑定器中,以spring.cloud.stream.rabbit.binder 为前缀
- adminAddresses 该参数用来配置RabbitMQ管理插件的URL,当需要配置多个时用逗号分隔。该参数只有在nodes参数包含多个时使用,并且这里配置的内容必须在spring.rabbitmq.address 中存在
- nodes 该参数用来配置RabbitMQ的节点名称,用逗号隔开,并且这里配置的内容必须在spring.rabbitmq.address 中存在。
- compressinLevel 绑定通道的压缩级别,它的具体可选值及含义可见java.util.zip.Deflater的定义
消费者配置
仅对消费者有效,下面省略spring.cloud.stream.rabbit.bindings.<channelName>.consumer 前缀
- acknowledgeMode 用来设置消息的确认模式,可写:NONE、MANUAL、AUTO,默认值为AUTO
- autoBindDlq 用来设置是否自动声明DLQ(queue),并绑定到DLX(exchange)上
- durableSubScription 用来设置订阅是否被持久化,该参数被设置时有效。默认为true
- maxConcurrency 用来设置消费者的最大并发数 ,默认为1
- prefetch 用来设置预取数量,它表示在一次会话中从消息中间件中获取的消息数量,该值越大消息处理越快,但是会导致非顺序处理的风险。默认为1
- prefix 用来设置统一的目标和队列名称前缀
- recoveryInterval 用来设置恢复连接的尝试时间间隔,默认为5000
- requeueRejected 用来设置消息传递失败时重传,默认为true
- requestHeaderPatterns 用来设置需要被传递的请求头信息
- replyHeaderPatterns 用来设置需要被传递的响应头信息
- republishToDlq 默认情况下,消息在重试也失败之后会被拒绝。如果DLQ被配置的时候,RabbitMQ会将失败的消息路由到DLQ中。如果该参数被设置为true ,总线会将失败的消息附加一些头信息(包括异常信息,引入失败的跟踪堆栈)之后重新发布到DLQ中
- transacted 用来设置是否启用channeltransacted 是否在消息中使用事务 ,默认false
- txSize 用来设置transaction-size 的数量,当acknowledgeMode被设置为AUTO时候,容器会在处理txSize 数目消息之后才开始应答,默认为1
生产者配置
仅对生产者者有效,下面省略spring.cloud.stream.rabbit.bindings.<channelName>.producer 前缀
- autoBindDlq 用来设置是否自动声明DLQ(queue),并绑定到DLX(exchange)上
- batchindEnabled 是否启用消息批处理 ,默认false
- batchSize 当批处理开启时,用在设置缓存的批处理消息数量,默认为100
- batchBufferLimit 批处理缓存限制 ,默认为10000
- batchTimeout 批处理超时时间,默认5000
- compress 消息发送时是否启用压缩 ,默认false
- deliveryMode 消息发送模式 ,默认PERSISTENT
- prefix 用来设置统一的目标前缀
- requestHeaderPatterns 用来设置需要被传递的请求头信息
- replyHeaderPatterns 用来设置需要被传递的响应头信息
KafKa配置
通用配置
在Spring Cloud Stream 对kafka时下的绑定器中,以spring.cloud.stream.kafka.binder 为前缀
- brokers =localhost:Kafka绑定器连接的消息中间件列表。需要配置多个时用逗号分隔,每个地址可以是单独的host,也可以是host:port 的形式
- defaultBrokerPort=9092 :用来设置默认的消息中间件端口号。当brokers中的配置地址没有包含端口信息时,将使用该参数配置的默认端口进行连接
- zkNodes=localhost :kakfa绑定器使用的Zookeeper端口号,当brokers中的配置地址没有包含端口信息时,将使用该参数配置的默认端口进行配置
- defaultZKport=2181 : 用来设置默认的Zookeeper端口号。当zKNodes 中的配置地址没有包含端口信息时,将使用该参数配置的默认端口进行连接
- headers : 用来设置会被传输的自定义头信息
- offsetUpdateCountTImeout =10000: 用来设置offset的更新频率,以毫秒为单位,如果设置为0则忽略
- offsetUpdateCount=0 : 用来设置offset以次数表示的更新频率,如果为0则忽略,该参数与offsetUpdateCountTImeout互斥
- requireAcks =1:用来设置确认消息的数量
- minParttitionCount 该参数仅在设置了autoCreateTopics和autoAddParttions时生效,用来设置该绑定器所使用主题的全局分区最小数量。如果当生产者的parttionCount的参数或instanceCount*concurrency 设置大于该参数配置时,该参数值将被覆盖
- replicationFactor=1 当autoCreateTopics 参数为true时候,用来配置自动创建主题的副本数量
- autoCreateTopics=true 该参数默认为true,绑定器会自动地创建新主题。如果设置为false,那么绑定器将使用已经配置的主题,但是在这种情况下,如果需要使用的主题不存在,绑定器会启动失败
- huautoAddPartition=false 该参数默认为false,绑定器会根据已经配置的主题分区来实现,如果目标主题的分区数小于预期值,那么绑定器会启动失败。如果该参数设置为true,绑定器将在需要的时候自动创建新的分区
- socketBufferSize =2097152 该参数用来设置KafKa 的Socket的缓存大小
消费者配置
仅对消费者有效,下面省略spring.cloud.stream.kafka.bindings.<channelName>.consumer 前缀
- autoCommitOffset=true :用来设置是否在处理消息时自动提交offset。如果设置为false,在消息头 中会加入ACK头消息以实现延迟确认。
- autoCommitOnError :该参数只有在autoCommitOffset设置为true时才有效。当设置为false的时候,引起错误消息不会自动提交offset,仅提交成功消息的offset。如果设置为true,不论消息是否成功,都会自动提交。当不设置该值时,它实际上具有与enabledDlq相同配置
- reconveryInterval =5000 :尝试恢复连接的时间间隔,以毫秒为单位
- resetOffsets =false :是否使用提供的startOffset 值来重置消费者的offset值
- startOffset =null : 用来设置新建组的起始offset,该值也会在resetOffsets开始时被使用
- enableDlq =false : 该参数设置为true时,将为消费者启用DLQ行为,引起错误的消息将被发送到名为error.<destination>.<group>的主题去
生产者配置
仅对生产者者有效,下面省略spring.cloud.stream.kafka.bindings.<channelName>.producer 前缀
- bufferSize = 16384 Kafka批量发送前的缓存数据上限,以字节为单位
- sync=false 该参数用来设置Kafka消息生产者的发送模式,默认为false,即采用async配置,允许批量发送数据。当设置为true时,将采用sync配置,消息将不会被批量发送,而是一条一条发送
- batchTimeout=0 消息生产者批量发送时,为了积累更多发送数据而设置的等待时间。通常情况下,生产者基本不会等待,而是直接发送所有在前一批此发送时基类的消息数据。当我们设置一个非0值时,可以以延迟为代价来增加系统的吞吐量















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









