







参考:
https://blog.csdn.net/u012877472/article/details/51039278
https://www.cnblogs.com/rilley/p/5616026.html :Scala操作MongoDB(比较全)
https://blog.csdn.net/kakaluoteyy/article/details/80267941 :使用用户名和密码进行连接。
https://blog.csdn.net/leed_11/article/details/78944652?utm_source=blogxgwz4:Spark写入数据到mongDB
注意:casbah-core_2.10版本需要与scala版本保持一致。
本项目中:scala采用2.11,所以配置如下。
<dependency>
<groupId>org.mongodb.spark</groupId>
<artifactId>mongo-spark-connector_2.11</artifactId>
<version>2.1.3</version>
</dependency>
<dependency>
<groupId>org.mongodb</groupId>
<artifactId>casbah-core_2.11</artifactId>
<version>3.1.1</version>
</dependency>


2.spark shell链接数据库MongDB
一般默认的spark库中没有MongDB所需要的工具包,此时需要将对应的包打入jar包中,并且注意版本。

如果数据库的版本打包错误,同样连接不上。
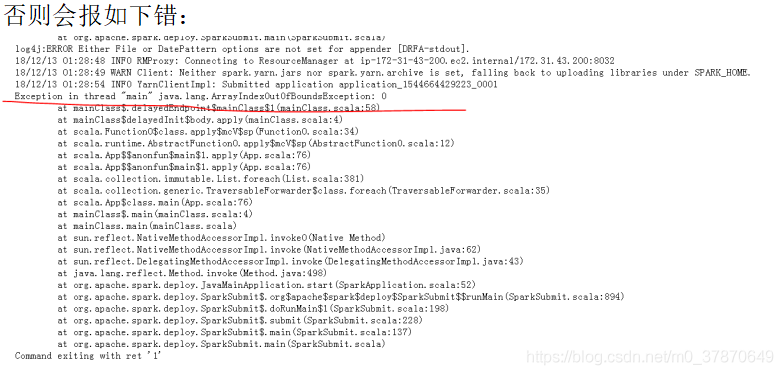
版本对应出错的例子1
Spark 2.1.0 - Caused by: java.lang.ClassNotFoundException: scala.collection.GenTraversableOnce$class
I am trying to use spark-submit with Spark 2.1.0 to read Avro files.
Maven dependencies:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.1.0</version>
</dependency>
<dependency>
<groupId>com.databricks</groupId>
<artifactId>spark-avro_2.10</artifactId>
<version>3.2.0</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.11.8</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.1.0</version>
</dependency>
Getting the following exception:
Caused by: java.lang.NoClassDefFoundError: scala/collection/GenTraversableOnce$class
at com.databricks.spark.avro.DefaultSource$$anonfun$buildReader$1$$anon$1.<init>(DefaultSource.scala:205)
at com.databricks.spark.avro.DefaultSource$$anonfun$buildReader$1.apply(DefaultSource.scala:205)
at com.databricks.spark.avro.DefaultSource$$anonfun$buildReader$1.apply(DefaultSource.scala:160)
at org.apache.spark.sql.execution.datasources.FileFormat$$anon$1.apply(FileFormat.scala:138)
at org.apache.spark.sql.execution.datasources.FileFormat$$anon$1.apply(FileFormat.scala:122)
at org.apache.spark.sql.execution.datasources.FileScanRDD$$anon$1.nextIterator(FileScanRDD.scala:150)
at org.apache.spark.sql.execution.datasources.FileScanRDD$$anon$1.hasNext(FileScanRDD.scala:102)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIterator.processNext(Unknown Source)
at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43)
at org.apache.spark.sql.execution.WholeStageCodegenExec$$anonfun$8$$anon$1.hasNext(WholeStageCodegenExec.scala:377)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$2.apply(SparkPlan.scala:231)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$2.apply(SparkPlan.scala:225)
at org.apache.spark.rdd.RDD$$anonfun$mapPartitionsInternal$1$$anonfun$apply$25.apply(RDD.scala:826)
at org.apache.spark.rdd.RDD$$anonfun$mapPartitionsInternal$1$$anonfun$apply$25.apply(RDD.scala:826)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:323)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:287)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:87)
at org.apache.spark.scheduler.Task.run(Task.scala:99)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:282)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
Caused by: java.lang.ClassNotFoundException: scala.collection.GenTraversableOnce$class
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
The source of the problem is mixing Scala 2.10 (spark-avro_2.10) and Scala 2.11 libraries. If you use Scala 2.11 it should be:
<dependency>
<groupId>com.databricks</groupId>
<artifactId>spark-avro_2.11</artifactId>
<version>3.2.0</version>
</dependency> 版本对应错的例子2
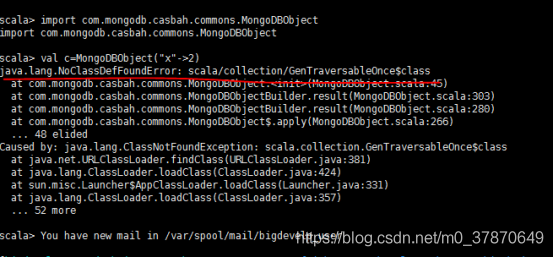

红色代码一直报错。
经过排查,scala使用的是2.11版本,但是如下3个相关的jar包却使用了2.10版本,修改版本号后,重新运行上述代码,调试OK。
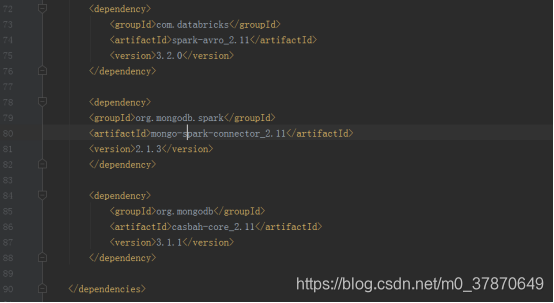
连接OK的例子
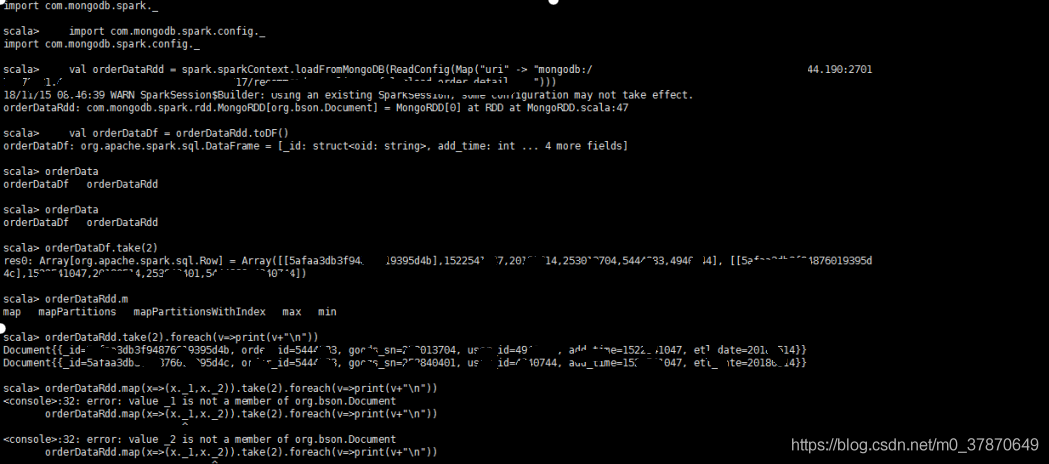
注意RDD数据的读取要使用get

1.Scala远程连接MongoDB读取数据
https://blog.csdn.net/kakaluoteyy/article/details/80267941
使用用户名和密码远程连接MongoDB数据库,用Java和Scala连接其实原理相同,都是JDBC,用MongoDB的连接驱动,只是语法上稍有区别而已,而在类、方法的调用上一模一样。
在此,分享一下Scala连接MongoDB查看数据的Code,语法结构上稍作修改就可以用Java实现。
首先,下载连接驱动,添加到工程里,下载地址:mongo-java-driver-3.7.0.jar
使用用户名和密码远程连接MongoDB数据库,用Java和Scala连接其实原理相同,都是JDBC,用MongoDB的连接驱动,只是语法上稍有区别而已,而在类、方法的调用上一模一样。
在此,分享一下Scala连接MongoDB查看数据的Code,语法结构上稍作修改就可以用Java实现。
首先,下载连接驱动,添加到工程里,下载地址:mongo-java-driver-3.7.0.jar
import java.io.{File, PrintWriter}
import com.mongodb.{MongoClient, ServerAddress}
import com.mongodb.client.{FindIterable, MongoCollection, MongoCursor, MongoDatabase}
import org.bson.Document
import com.mongodb.MongoCredential
import java.util.ArrayList
object MondoDBtoES {
def main(args: Array[String]): Unit = {
//初始化和连接
try {
//两个变量分别为服务器地址和端口
val serverAddress:ServerAddress = new ServerAddress("XX.XXX.XX.XX",27017)
val adds = new ArrayList[ServerAddress]()
adds.add(serverAddress)
//用户名,连接的数据库名,用户密码
val credential = MongoCredential.createCredential("user", "test","passwd".toCharArray)
val credentials = new ArrayList[MongoCredential]()
credentials.add(credential)
//通过验证连接到MongoDB客户端
val mongoClient:MongoClient = new MongoClient(adds,credentials)
//连接数据库
val mongoDatabase:MongoDatabase = mongoClient.getDatabase("test")
println("Connect MongoDB Successfully!!!")
val collection:MongoCollection[Document] = mongoDatabase.getCollection("price_discount")
println("已经选中集合price_discount")
printf(collection.count().toString)
//检索所有文档
//获取迭代器
val findInterable:FindIterable[Document] = collection.find()
//获取游标
val mongoCursor:MongoCursor[Document] = findInterable.iterator()
//开始遍历
while (mongoCursor.hasNext){
println(mongoCursor.next())
}
} catch {
case e:Exception=>
println(e.getClass.getName + ": " + e.getMessage)
}
}
}
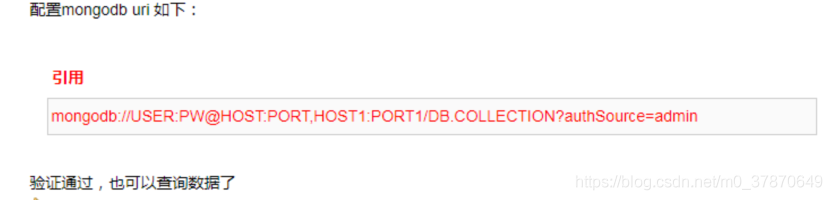
2.方法2 直接在config接口配置,如下对应没有密码的情况。

有密码的情况下,直接要按照如下格式更改URI即可。
mongo-spark-读取不同的库数据和写入不同的库中
参考:https://www.cnblogs.com/wenbronk/p/9887466.html
package com.example.app
import com.mongodb.spark.config.{ReadConfig, WriteConfig}
import com.mongodb.spark.sql._
object App {
def main(args: Array[String]): Unit = {
val MongoUri1 = args(0).toString
val MongoUri2 = args(1).toString
val SparkMasterUri= args(2).toString
def makeMongoURI(uri:String,database:String,collection:String) = (s"${uri}/${database}.${collection}")
val mongoURI1 = s"mongodb://${MongoUri1}:27017"
val mongoURI2 = s"mongodb://${MongoUri2}:27017"
val CONFdb1 = makeMongoURI(s"${mongoURI1}","MyColletion1,"df")
val CONFdb2 = makeMongoURI(s"${mongoURI2}","MyColletion2,"df")
val WRITEdb1: WriteConfig = WriteConfig(scala.collection.immutable.Map("uri"->CONFdb1))
val READdb1: ReadConfig = ReadConfig(Map("uri" -> CONFdb1))
val WRITEdb2: WriteConfig = WriteConfig(scala.collection.immutable.Map("uri"->CONFdb2))
val READdb2: ReadConfig = ReadConfig(Map("uri" -> CONFdb2))
val spark = SparkSession
.builder
.appName("AppMongo")
.config("spark.worker.cleanup.enabled", "true")
.config("spark.scheduler.mode", "FAIR")
.getOrCreate()
val df1 = spark.read.mongo(READdb1)
val df2 = spark.read.mongo(READdb2)
df1.write.mode("overwrite").mongo(WRITEdb1)
df2.write.mode("overwrite").mongo(WRITEdb2)
}
}














 2494
2494











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









