







本文所有的代码都运行在 64位 Linux 系统之上。
背景知识
1. 存储单位
计算机的存储单位从小到大为:B, KB, MB, GB, TB, PB, EB, YB.
2. 栈的大小
32位系统中,地址总线的位数为32位,故栈的大小为 232 = 22 * 210 * 210 * 210 = 4G, 内存地址的分布为从 0xffff ffff 到 0x0000 0000 .
64位系统中,理论上来讲地址总线的位数可达到64位,那么最大寻址空间可达到 264 = 234 GB = 16EB. 一般程序的运行,是不可能使用到那么大的内存空间的;如果为每一个进程都分配这样庞大的一个栈,会造成资源的浪费。
64位系统中应该有48根地址总线,低位:0~47位才是有效的可变地址,高位:48~63位全补0或全补1。一般高位全补0对应的地址空间是用户态,如上面的第1~18行。高位全补1对应的是内核态,如上面的第19行。这64位的地址空间并不能全部被使用(太多了),所以用户态和内核态之间会有未使用的空间(据说叫AMD64空洞)
这一点可以通过gdb调试来验证。这里写了一个非常简单的两个整数相加的函数来验证。
#include<ostream>
using namespace std;
int add(int a, int b){
return a + b;
}
int main(int argc, char const *argv[])
{
int a, b;
a = 3;
b = 4;
add(3, 4);
return 0;
}
编译后用gdb打开,查看 rsp 寄存器内的信息, 可以看到寄存器中保存的地址只有12位。

汇编格式
- at&t指令
格式:指令 源地址/源操作数 目标地址/目标操作数
movl $1, %eax
movl $0xff,%ebx
int $0x80
- intel指令
格式:指令 目标地址/目标操作数 源地址/源操作数
mov eax,1
mov ebx,0ffh
int 80h
gdb调试理解代码的执行过程
函数的调用过程
add(3, 4)这一行的c代码对应的汇编如下(AT&T格式):

抽象成伪代码(intel 格式):
mov 寄存器1 参数1
mov 寄存器2 参数2
call function // call 完成两件事:1. 将当前指令的下一条指令地址压栈;2. 跳转到函数的入口
push rbp // 跳转后的第一件事是保存旧 stack frame 的栈底
mov rbp, rsp // 设置新栈帧的栈底
sub rsp, xxx // 抬高栈顶
Tips:
- 函数调用约定与相关指令
默认情况下,g++ 编译采用stdcall函数调用约定,参数从右至左入栈。 - x86(32位)函数参数是通过栈传递的,而x64(64位)函数参数是通过寄存器传递的。
- 64位系统中参数的传递:当函数参数个数小于7时,参数从左至右放入:rdi, rsi, rdx, rcx, r8, r9.
call add()之后,函数跳转到add()的入口处。在add()函数中,如上伪代码中所述,首先要将旧栈帧的栈底压栈,这样才可以实现add() 函数执行完后的返回。如下所示是add()和main()的汇编代码。
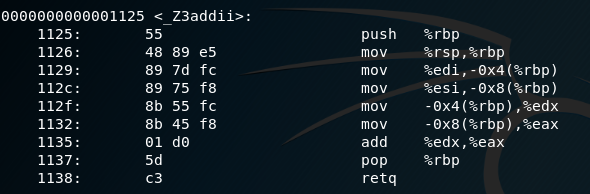

- 众所周知,c或者c++代码需要有main函数才可以运行。再具体一点,一个程序运行的起始入口是
<_start>. 在<_start>完成初始化后会调用main()函数,故此可以将main()函数理解为一个普通的函数。那么在调用main()函数后,不外乎也是执行如上伪代码所示的过程。

函数调用过程中的栈
- 首先在
main()开始的地方设置断点,然后运行程序到断点处。 - 此时,a = 3 这条命令还未执行。
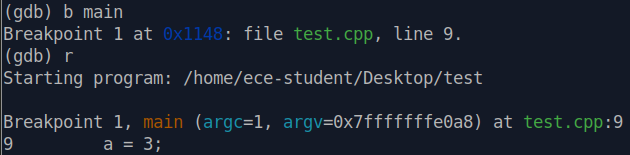
- 单步执行,这里执行的语句是
a = 3.

- 可以看到此时的栈帧底
rbp为0x7ffff fffff fdc0, 栈帧顶rsp为0x7fff ffff dfa0.
通过查看main对应的汇编,可以看到其实在一开始,整个栈帧的空间就已经分配好了。
从c/c++语言层面,可以理解为在执行int a, b时为两个变量在内存中开辟了空间(只是方便理解,不完全正确)。
0000000000001139 <main>:
// 偏移 机器指令 汇编
1139: 55 push %rbp
113a: 48 89 e5 mov %rsp,%rbp
113d: 48 83 ec 20 sub $0x20,%rsp
1141: 89 7d ec mov %edi,-0x14(%rbp) // 因为接下来要用rdi传参,故将寄存器rdi压栈
1144: 48 89 75 e0 mov %rsi,-0x20(%rbp) // rsi同上
1148: c7 45 f8 03 00 00 00 movl $0x3,-0x8(%rbp) // 局部变量a入栈
114f: c7 45 fc 04 00 00 00 movl $0x4,-0x4(%rbp) // 局部变量b入栈
1156: be 04 00 00 00 mov $0x4,%esi // 将add函数的参数放入寄存器中,为参数的传递做准备
115b: bf 03 00 00 00 mov $0x3,%edi // 同上
1160: e8 c0 ff ff ff callq 1125 <_Z3addii>
1165: b8 00 00 00 00 mov $0x0,%eax
116a: c9 leaveq
116b: c3 retq
116c: 0f 1f 40 00 nopl 0x0(%rax)
为了更好地理解代码的执行,用gdb单步汇编代码。
- 使用gdb时增加-tui选项,打开gdb后运行
layout regs命令。 - 在gdb中运行
set disassemble-next-line on,表示自动反汇编后面要执行的代码。 - 使用si和ni。与s与n的区别在于:s与n是C语言级别的单步调试,si与ni是汇编级别的单步调试。

layout:用于分割窗口,可以一边查看代码,一边测试:
layout src:显示源代码窗口
layout asm:显示反汇编窗口
layout regs:显示源代码/反汇编和CPU寄存器窗口
layout split:显示源代码和反汇编窗口
过程中可以使用:
info registers rsp, rbp查看寄存器值或者在layout regs框里查看。x /16xw $rsp查看栈。
当程序跳转到add函数:
0000000000001125 <_Z3addii>:
1125: 55 push %rbp // 前栈帧底指针压栈
1126: 48 89 e5 mov %rsp,%rbp // 太高栈顶
1129: 89 7d fc mov %edi,-0x4(%rbp)
112c: 89 75 f8 mov %esi,-0x8(%rbp)
112f: 8b 55 fc mov -0x4(%rbp),%edx
1132: 8b 45 f8 mov -0x8(%rbp),%eax
1135: 01 d0 add %edx,%eax
1137: 5d pop %rbp // 弹出返回地址
1138: c3 retq // 返回到调用函数的下一条指令
References:
- 64位系统下进程的内存布局
https://blog.csdn.net/chenyijun/article/details/79441166 - gdb单步调试汇编
https://www.cnblogs.com/zhangyachen/p/9227037.html - gdb查看堆栈局部变量
https://www.cnblogs.com/welhzh/p/10335722.html















 647
647











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









