







第一篇成功使用深度学习作图像语义分割的论文,使得网络可以接受任意大小的图片并输出和原图一样大小的分割图。
实现的过程
从分类的CNN到用于dense prediction
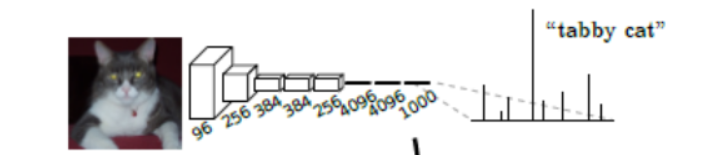
典型的分类网络,采用固定尺寸的输入产生了非空间的输出。这些网络的全连接层有确定的位数并丢弃空间坐标,也被看作是覆盖全部输入域的核卷积。如上图正确识别图片中的猫为tabby cat ,不需要将猫轮廓识别出来,只需要一个概率值。

FCN将最后的FC层变为卷积层
关于FC层和卷积层相互转化的可能性
卷积层是对一个局部区域进行操作,全连接是对所有像素点操作。用全连接进行卷积操作可以看作一个巨大的权重矩阵除了特定区域其余均为0,和原图进行卷积操作。全连接层可以看作是卷积操作,在VGG16网络中,第一个K=4096FC层的输入是7×7×512的特征图,可以看作是滤波器为7×7×4096与特征图进行卷积操作,结果是1×1×4096,第二个FC层可看作1x1x4096 输出为1x1x4096同理最后FC输出1x1x4096

如图经过5次pooling 特征图变为为原来的1/32,最后的输出是1000张heatmap经过上采样(转置卷积)变为原图大小的图片,为了对每个像素进行分类预测,成最后已经进行语义分割的图像,就是最后通过逐个像素地求其在1000张图像该像素位置的最大数值描述(概率)作为该像素的分类。此时保留pool3、pool4、pool5的featureMap;pool5后图像不再叫featureMap而是叫heatMap。现在我们有1/32尺寸的heatMap,1/16尺寸的featureMap和1/8尺寸的featureMap,1/32尺寸的heatMap进行上采样操作之后,因为这样的操作还原的图片仅仅是conv5中的卷积核中的特征,限于精度问题不能够很好地还原图像当中的特征,因此在这里向前迭代。把conv4中的卷积核转置对上一次upsampling之后的图进行转置卷积补充细节,最后把conv3中的卷积核对刚才upsampling之后的图像进行再次反卷积补充细节,最后就完成了整个图像的还原。
跳连
采用了跳连,跳连采用的是sum。
提供了思路解决分辨率的问题。
FCN不足:
(1)网络的感受野尺寸是预先固定。因此,对于输入图片中比感受野大或者小的物体可能会被忽略。换言之,对于较大的物体,只有局部的细节信息能够被正确标记,或者标记的结果是不连续的,而对于小物体会被忽略。由于分割的边界细节和语义信息之间的权衡,通过跳跃结构来改善效果这一做法也无法从根本上解决问题。
(2)由于,卷积后送入反卷积层的feature map十分稀疏,而且,反卷积的过程又十分的粗糙,输入图片中的结构细节信息会有所损失。















 7万+
7万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









