








世上有两种人
勇于负责的人和去找靠山的人
靠山比较好
----《Scent of a Woman》
一.pivot函数
行转列。
工作中遇到一个业务,需要某列数据(这个列一般是有不同类型的,比如县,科目等)转成多列来显示,也可以说是行转列。
引用:博客
学生成绩表,原数据:
select class_name, student_name, course_type, result, created_date
from class_tmp_2;
每个同学的两门成绩,是两条数据,因为业务需要,展示给用户看的时候,用户想要每个同学只要一条数据,并且把所有成绩都展示出来,比如

这个时候就需要用到行专列函数PIVOT.
SELECT class_name, student_name, 语文, 数学, created_date
FROM (SELECT CLASS_NAME, STUDENT_NAME, COURSE_TYPE, RESULT, CREATED_DATE
FROM CLASS_TMP_2) T
PIVOT(SUM(RESULT)
FOR COURSE_TYPE IN('语文' AS 语文, '数学' AS 数学));浅灰色的sql和上面的原数据sql一样,主要看一下后面的PIVOT部分。
sum(result):成绩之和(PIVOT内需有聚集函数)
for course_type in ('语文' as语文, '数学' as数学):将course_type列的字段值转换成列名,其中,字段值是'语文',转换成语文列,字段值是'数学',转换成数学列,这两列的字段值,即前面的sum(result)。
这个例子由于同属一个班级,所以也可以使用如下子查询来实现
select t1.class_name,
t1.student_name,
t1.result 语文,
t2.result 数学,
t1.created_date
from (select a.class_name,
a.student_name,
a.course_type,
a.result,
a.created_date
from class_tmp_2 a
where a.course_type = '语文') t1,
(select a.class_name,
a.student_name,
a.course_type,
a.result,
a.created_date
from class_tmp_2 a
where a.course_type = '数学') t2
where t1.class_name = t2.class_name
and t1.student_name = t2.student_name;二.unpivot函数
列转行。
原数据如下:

想要得到的结果如下

也就是说,如果工作中遇到要将数据库查出的的多列根据全放到同一列来多行显示,他们对应的数据放到另一类,也就是下方的result,使用此函数。
select class_name, student_name, course_type, result, created_date
from class_tmp
unpivot(result for course_type in(chinese_result,math_result));说明:
原数据的chinese_result列和math_result列的列名(浅灰色),将转换为新建列course_type的字段值,表示课种。
原数据的chinese_result列和math_result列的字段值,将转换为新建列result的字段值,表示分数。
三.with as
with as短语,也叫做子查询部分,就是定义了一个sql片断,这个片断在整个大sql语句里会被经常用到,然后它的使用限制为---多次使用,数据量不大的业务场景,增加sql的可读性,降低扫表次数(这个用F5可以直接看出来走的是基表还是内存里的临时表),减少代码重写;with as 是相当于放在内存中的一个临时表,所以他快,他性能好,所以数据量不能很大;
语法:
主要的写法:
with query1 AS
(select ...from ....where ..),
query2 AS
(select...from ...where..),
query3 AS
(select...from ...where..)
SELECT ...FROM query1,quer2,query3
where ....;比如:
with
e as
(select * from scott.emp),
d as
(select * from scott.dept)
select * from e, d where e.deptno = d.deptno;再比如多个union all:
with
sql1 as
(select to_char(a) s_name from test_tempa),
sql2 as
(select to_char(b) s_name
from test_tempb
where not exists (select s_name from sql1 where rownum = 1))
select * from sql1
union all
select * from sql2
union all .. .. ..四.leading函数
/*+LEADING(TABLE)*/ /*+LEADING(table1,table2....)*/
将指定的表做为链接次序中的首表,leading提示后面可以跟多个表名,它用来表示在相关的表关联中,以哪个表作为驱动表。使用leading提示后,优化器将不会再考虑from后表的顺序。
简单的说就是规定哪个是驱动表,一般是小表;有的时候oracle优化器会指定大表为驱动表,这就增加了扫描次数;
比如最近遇到的一个业务,由于保密要求,类似的语句如下
select a...
from A a
left join B b
on a.id = b.id
inner join C c
on a.id = c.id
inner join D d
on a.id = d.idid是ABCD四个表的主键,所以这意味着都有索引,那么看一下扫描计划后发现A与B表都是全表扫描,B表cost耗时较长,一共用时为45秒左右查出,A表数据有100条,B表有30万条;
针对上面这种现象,首先优化的方向为让B表走强制索引,所以优化如下:
select /*+index(B)*/ a...
from A a
left join B
on a.id = b.id
inner join C c
on a.id = c.id
inner join D d
on a.id = d.id再看执行计划发现B表走索引了,所以速度一下子到了0.2秒。
继续以上面这个例子为例,实际上后来最后的优化是这样的:
select /*+leading(A B) index(B)*/ a...
from A a
left join B
on a.id = b.id
inner join C c
on a.id = c.id
inner join D d
on a.id = d.id注意:如果⼀个表有索引,⼀个表没有索引,ORACLE会将没有索引的表作驱动表。如果两个表都有索引,则外表作驱动表。如果两个都没索引的话,则也是外表作驱动表。这个时候考虑用leading函数根据扫描计划来指定。
五.connect by递归
基本语法
select t.*,level from table t [start with condition1]
connect by [prior] id=parentid这个函数一般用来查找存在父子关系的数据,具有层级关系的表;
-
start with condition1 是用来限制第一层的数据,或者叫根节点数据;以这部分数据为基础来查找第二层数据,然后以第二层数据查找第三层数据以此类推。
而connect by prior id=parentid或者connect by id=prior parentid有什么区别吗?
先举个例子:
造个数据,以半泽直树为例子:
-- Create table
create table BANK
(
id NUMBER(8) not null,
funcid NUMBER(8),
parentid NUMBER(8),
funcname VARCHAR2(20),
parentname VARCHAR2(20)
);
insert into BANK (FUNCID, PARENTID, FUNCNAME, PARENTNAME)
values (1001, 0, '中野渡行长', null);
insert into BANK (FUNCID, PARENTID, FUNCNAME, PARENTNAME)
values (1002, 1001, '三笠副行长', '中野渡行长');
insert into BANK (FUNCID, PARENTID, FUNCNAME, PARENTNAME)
values (1003, 1002, '大和田常务', '三笠副行长');
insert into BANK (FUNCID, PARENTID, FUNCNAME, PARENTNAME)
values (1005, 1003, '伊佐山部长', '大和田常务');
insert into BANK (FUNCID, PARENTID, FUNCNAME, PARENTNAME)
values (1006, 1005, '半泽直树', '伊佐山部长');
insert into BANK (FUNCID, PARENTID, FUNCNAME, PARENTNAME)
values (1007, 1003, '渡真利忍', '大和田常务');
insert into BANK (FUNCID, PARENTID, FUNCNAME, PARENTNAME)
values (1004, 1002, '纪本常务', '三笠副行长');
commit;查询如图,层级关系为:行长-副行长-常务-部长-工人
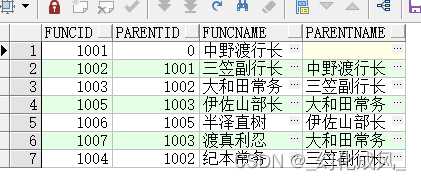
工作中经常会使用这个,比如有的表存放的是组织关系的数据,有的是左侧菜单的这种,在复杂业务中如果要用到关于组织表的通常会用到这个。
对于上面的语法,里面有个关键字prior,这个可以在等号左边与右边,level有无都行,只是用来说明该行数据属于哪个层级。
select t.*,level from tablename t
start with 条件1
connect by prior 子字段id=父字段id
where 条件3;如果在左边,查的则是以条件一为基础的叶子节点;
如果在右边,查的则是以条件一为基础的上层节点。
左边
从1001开始,查询其子节点;
select t.*,level from bank t
start with t.funcid=1001
connect by prior t.funcid=t.parentid
order by funcid;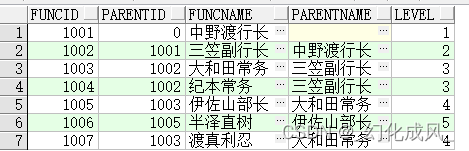
右边
查1001开始的父节点,所以只有一条数据;
select t.*, level
from bank t
start with t.funcid = 1001
connect by t.funcid = prior t.parentid
order by funcid;
六.keep函数
keep是oracle下的一种分析函数,Oracle中为了解决子集合中查询最值的问题,提出了KEEP()语法,也就是取同一个分组下以某个字段排序后,对指定字段取最小或最大的那个值。
语法如下:
min | max(column1) keep (dense_rank first | last order by column2) over (partion by column3);
示例如下:建一个表,用上方的with as建一个临时的表内容如下:
WITH workers AS(
SELECT 'DOM1' dept, 'zhangsan' names , 23 age, 4000 salaries FROM dual UNION ALL
SELECT 'DOM1' dept, 'lisi' names , 35 age, 9000 salaries FROM dual UNION ALL
SELECT 'DOM2' dept, 'wangwu' names , 26 age, 6500 salaries FROM dual UNION ALL
SELECT 'DOM2' dept, 'maliu' names , 28 age, 6000 salaries FROM dual UNION ALL
SELECT 'DOM2' dept, 'zhaoqi' names , 26 age, 5000 salaries FROM dual UNION ALL
SELECT 'DOM1' dept, 'liba' names , 23 age, 3000 salaries FROM dual
)
select * from workers;查询如下
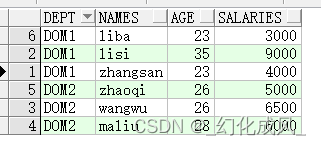
业务目标:获取部门内年龄最小的人中,工资最高的记录;
那么可以使用keep(dense_rank first/last)来处理,替换掉上面的sf..works,比如
SELECT w.dept,
max(w.salaries) KEEP(dense_rank first order by w.age) max_salary
FROM workers w
GROUP BY dept;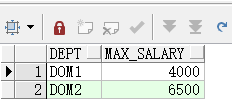
意思是按照年龄排序查最大的工资,由于这里是查年龄最小的,所以用了first,如果查年龄最大的,用last;
解释
1.keep的意思就是“保持”,会保持满足括号内条件的记录,用order by 后自然会有first和last了,这也是固定的写法;
2.dense_rank是排序策略,一般默认这个;
3.first/last就是对数据进行筛选了,这里我们筛选age最小的记录;
4.由于用到了聚合函数,所以最后需要有group by;
七.over函数
语法:rank()/dense_rank over(partition by A order by B)
over是一种分析函数,根据字段A对结果进行分区,在各分区内按照字段进行排序;
over不能单独使用,需要与row_number(),rank()和dense_rank,lag()和lead(),sum()等配合使用
说明:
- over()在什么条件之上;
- partition by 按哪个字段划分组;
- order by 按哪个字段排序;
注意:
- 使用rank()/dense_rank() 时,必须要带order by否则非法;
- rank(): 跳跃排序,如果有两个第一级时,接下来就是第三级。
- dense_rank(): 连续排序,如果有两个第一级时,接下来仍然是第二级。
举个例子:
创造一个表并插入数据:
create table EMP
(
empno NUMBER(4) not null,
ename VARCHAR2(10),
job VARCHAR2(9),
mgr NUMBER(4),
hiredate DATE,
sal NUMBER(7,2),
comm NUMBER(7,2),
deptno NUMBER(2)
)
alter table EMP
add constraint PK_EMP primary key (EMPNO);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7369, 'SMITH', 'CLERK', 7902, to_date('17-12-1980', 'dd-mm-yyyy'), 800, null, 20);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7499, 'ALLEN', 'SALESMAN', 7698, to_date('20-02-1981', 'dd-mm-yyyy'), 1600, 300, 30);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7521, 'WARD', 'SALESMAN', 7698, to_date('22-02-1981', 'dd-mm-yyyy'), 1250, 500, 30);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7566, 'JONES', 'MANAGER', 7839, to_date('02-04-1981', 'dd-mm-yyyy'), 2975, null, 20);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7654, 'MARTIN', 'SALESMAN', 7698, to_date('28-09-1981', 'dd-mm-yyyy'), 1250, 1400, 30);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7698, 'BLAKE', 'MANAGER', 7839, to_date('01-05-1981', 'dd-mm-yyyy'), 2850, null, 30);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7782, 'CLARK', 'MANAGER', 7839, to_date('09-06-1981', 'dd-mm-yyyy'), 2450, null, 10);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7788, 'SCOTT', 'ANALYST', 7566, to_date('19-04-1987', 'dd-mm-yyyy'), 3000, null, 20);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7839, 'KING', 'PRESIDENT', null, to_date('17-11-1981', 'dd-mm-yyyy'), 5000, null, 10);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7844, 'TURNER', 'SALESMAN', 7698, to_date('08-09-1981', 'dd-mm-yyyy'), 1500, 0, 30);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7876, 'ADAMS', 'CLERK', 7788, to_date('23-05-1987', 'dd-mm-yyyy'), 1100, null, 20);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7900, 'JAMES', 'CLERK', 7698, to_date('03-12-1981', 'dd-mm-yyyy'), 950, null, 30);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7902, 'FORD', 'ANALYST', 7566, to_date('03-12-1981', 'dd-mm-yyyy'), 3000, null, 20);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7934, 'MILLER', 'CLERK', 7782, to_date('23-01-1982', 'dd-mm-yyyy'), 1300, null, 10); 查询如图:
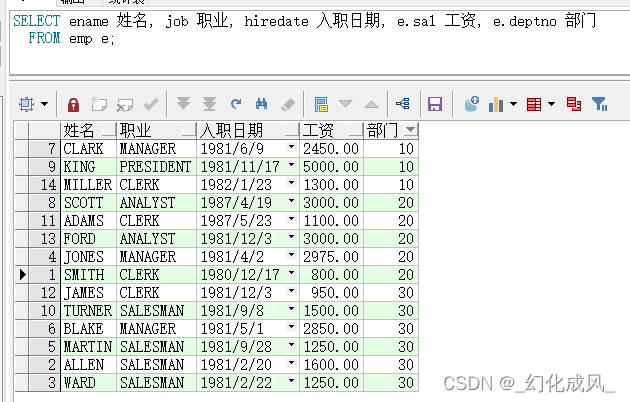
1、rank()/dense_rank() over(partition by ...order by ...)
业务一:要求查询每个部门工资最高的雇员的信息
常见的普通写法为:
select *
from (select ename 姓名,
job 职业,
hiredate 入职日期,
e.sal 工资,
e.deptno 部门
from emp e,
(select deptno, max(sal) sal from emp group by deptno) t
where e.deptno = t.deptno
and e.sal = t.sal)
order by 部门; 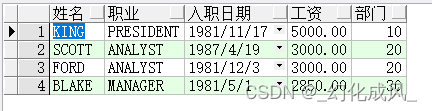
使用over函数为:
select empno, ename, job, hiredate, sal, deptno
from (select empno,
ename,
job,
hiredate,
sal,
deptno,
rank() over(partition by deptno order by sal desc) r
from emp)
where r = 1;
select empno, ename, job, hiredate, sal, deptno
from (select empno,
ename,
job,
hiredate,
sal,
deptno,
dense_rank() over(partition by deptno order by sal desc) r
from emp)
where r = 1 这两种运行的结果与上方是一致的,
按照部门(deptno)分区后根据工资(sal)从高到底排序,然后每个区只取一个结果即是最高工资;
另:如果要查询最低工资,desc改为asc即可;
2、min()/max() over(partition by ...)
业务二:查询雇员信息的同时算出雇员工资与部门最高/最低工资的差额
注意:min/max不用order by
常见普通的写法为:
select ename 姓名,
job 职业,
hiredate 入职日期,
e.deptno 部门,
e.sal 工资,
e.sal - me.min_sal 最低差额,
me.max_sal - e.sal 最高差额
from emp e,
(select deptno, min(sal) min_sal, max(sal) max_sal
from emp
group by deptno) me
where e.deptno = me.deptno
order by e.deptno, e.sal;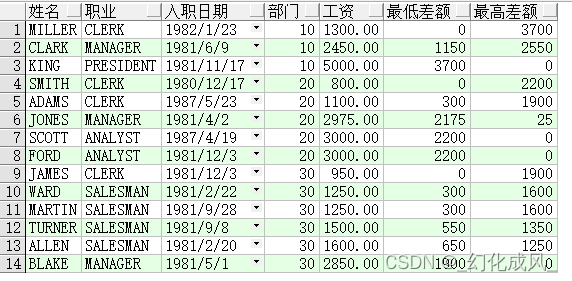
使用over为:
select ename 姓名,
job 职业,
hiredate 入职日期,
deptno 部门,
sal 工资,
min(sal) over(partition by deptno) 部门最低工资,
max(sal) over(partition by deptno) 部门最高工资,
nvl(sal - min(sal) over(partition by deptno), 0) 部门最低工资差额,
nvl(max(sal) over(partition by deptno) - sal, 0) 部门最高工资差额
from emp
order by deptno, sal; 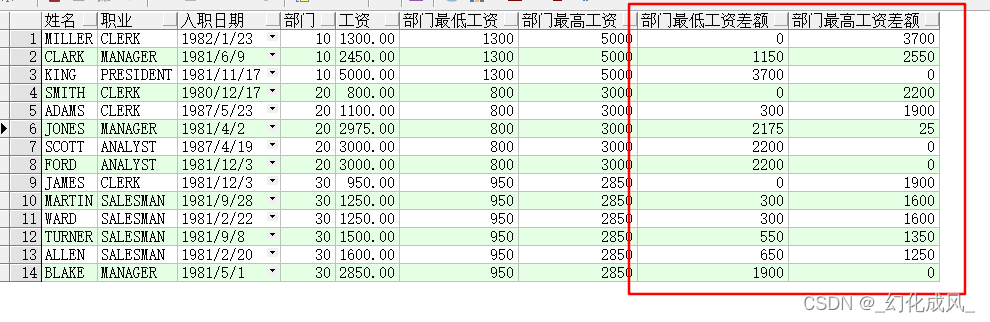
查询差额结果与常见的一致,且比上方的代码量更少;
如果看看两边的代码扫描结果呢?如下图对比:
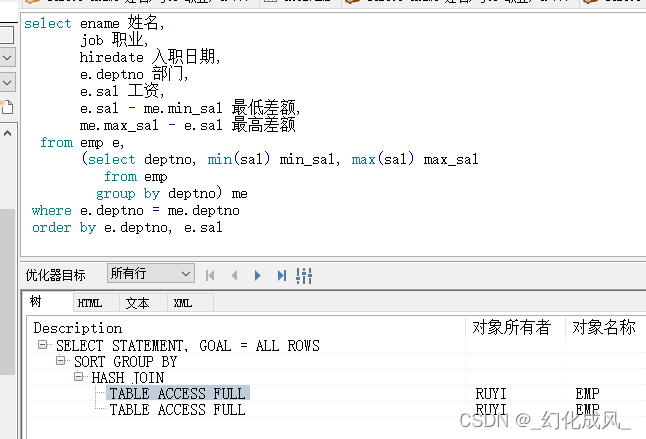
而下方只走了一次全表扫描
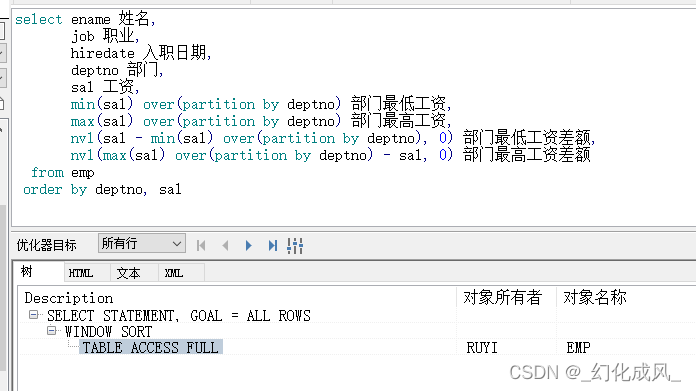
所以综上对比,针对业务需求可进行相应的优化。
另外说一些问题:
为什么不用order by sal了?
order by 默认是asc从小到大排序,写成如下写法查询
select ename 姓名,
job 职业,
hiredate 入职日期,
deptno 部门,
sal 工资,
min(sal) over(partition by deptno order by sal) 部门最低工资,
max(sal) over(partition by deptno order by sal) 部门最高工资,
nvl(sal - min(sal) over(partition by deptno order by sal), 0) 部门最低工资差额,
nvl(max(sal) over(partition by deptno order by sal) - sal, 0) 部门最高工资差额
from emp
order by deptno, sal; 
个人工资与部门最高工资居然是一致的,则差额是0,原因不清楚,需要记住使用min/max等聚合函数时over内不可以用该聚合的字段进行order by,也就是说不用写order by了。
3、lead()/lag() over(partition by ... order by ...)
首先说明lead函数,不是leading;
这两个函数,是偏移量函数;
其用途是:可以查出同一字段里每行记录对应的下一个值或上一个值。
lead()是取后N行的数据
select ename 姓名,
job 职业,
hiredate 入职日期,
deptno 部门,
sal 工资,
lead(sal) over(order by deptno) 偏移量1,
lead(sal,2) over(order by deptno) 偏移量2
from emp
order by deptno, sal;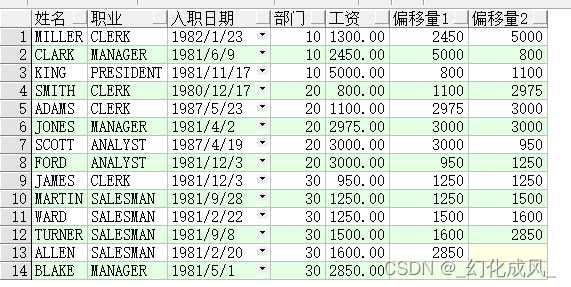
如图,比如偏移量为1是从第2行开始到第14行这N行数据的,所以叫作取后N行;
- lead(column,num,flag)
- col_name是列名;num是取向下第几个值;flag是一个标志,也就是如果向下第几个值是空值的话就取flag;
- 例如lead(column,1,null)这个是向下取一个值,如果这个值为空则按空算,当然也可以用其他值替换。
lag()是取前N行的数据
select ename 姓名,
job 职业,
hiredate 入职日期,
deptno 部门,
sal 工资,
lag(sal) over(order by deptno) 偏移量1,
lag(sal,2,0) over(order by deptno) 偏移量2
from emp
order by deptno, sal;
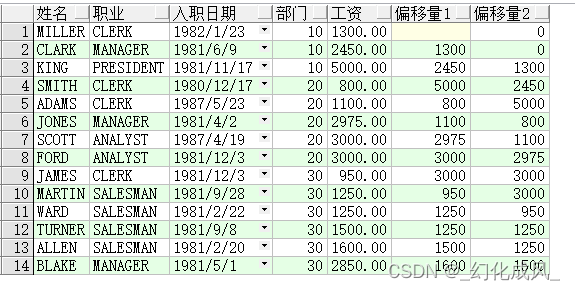
如图,比如偏移量为1是从第13行开始到第1行这N行数据的,所以叫作取前N行;
好了,现在说明业务问题:
业务三:计算同一个部门下个人工资与比自己高一位/低一位工资的差额
select ename 姓名,
job 职业,
sal 工资,
deptno 部门,
lead(sal, 1, 0) over(partition by deptno order by sal) 比自己工资高的前一个人工资,
lag(sal, 1, 0) over(partition by deptno order by sal) 比自己工资低的后一个人工资,
nvl(lead(sal) over(partition by deptno order by sal) - sal, 0) 比自己工资高的差额,
nvl(sal - lag(sal) over(partition by deptno order by sal), 0) 比自己工资低的差额
from emp;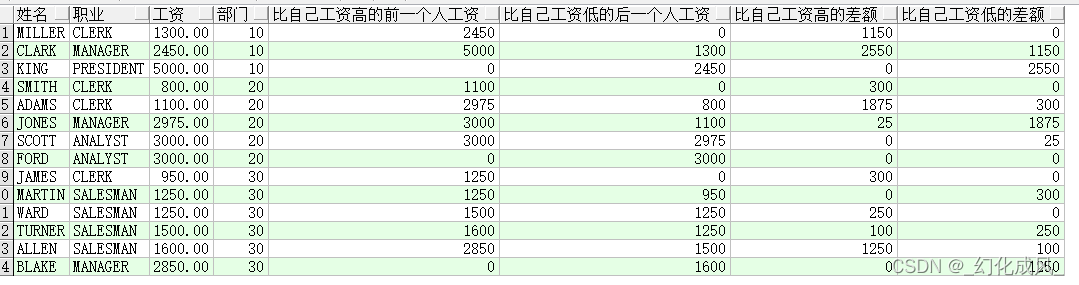
功能已说明,不做解释;
再列举一些常见的搭配聚合函数写法
select ename 姓名, job 职业, sal 工资, deptno 部门,
first_value(sal) over(partition by deptno) first_sal,
last_value(sal) over(partition by deptno) last_sal,
min(sal) over(partition by deptno) min_sal,
max(sal) over(partition by deptno) max_sal,
sum(sal) over(partition by deptno) 部门总工资,
avg(sal) over(partition by deptno) 部门平均工资,
count(1) over(partition by deptno) 部门总数,
row_number() over(partition by deptno order by sal) 序号
from emp; 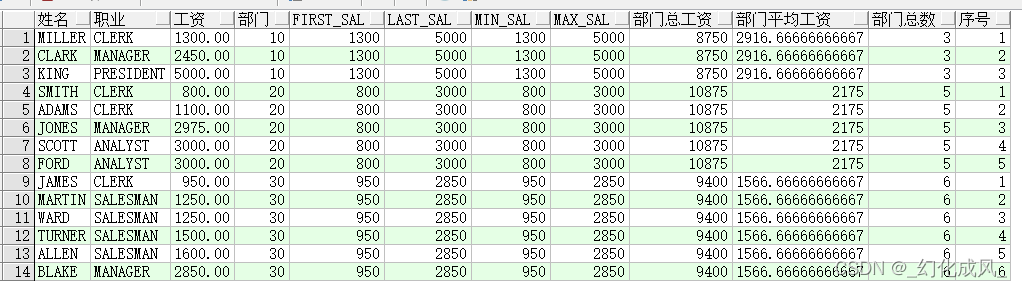
摘自博客并做了更详细说明















 1781
1781











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









