







文章目录
Elastic Stack 是什么
- Elasticsearch : 基于Json的分布式搜索和分析引擎
- 搜索、聚合分析、大数据存储
- 分布式、高性能、高可用、可伸缩、易维护
- 支持文本搜索、结构化数据、非结构化数据、地理位置搜索等
- Logstash : 动态数据收集管道,生态丰富
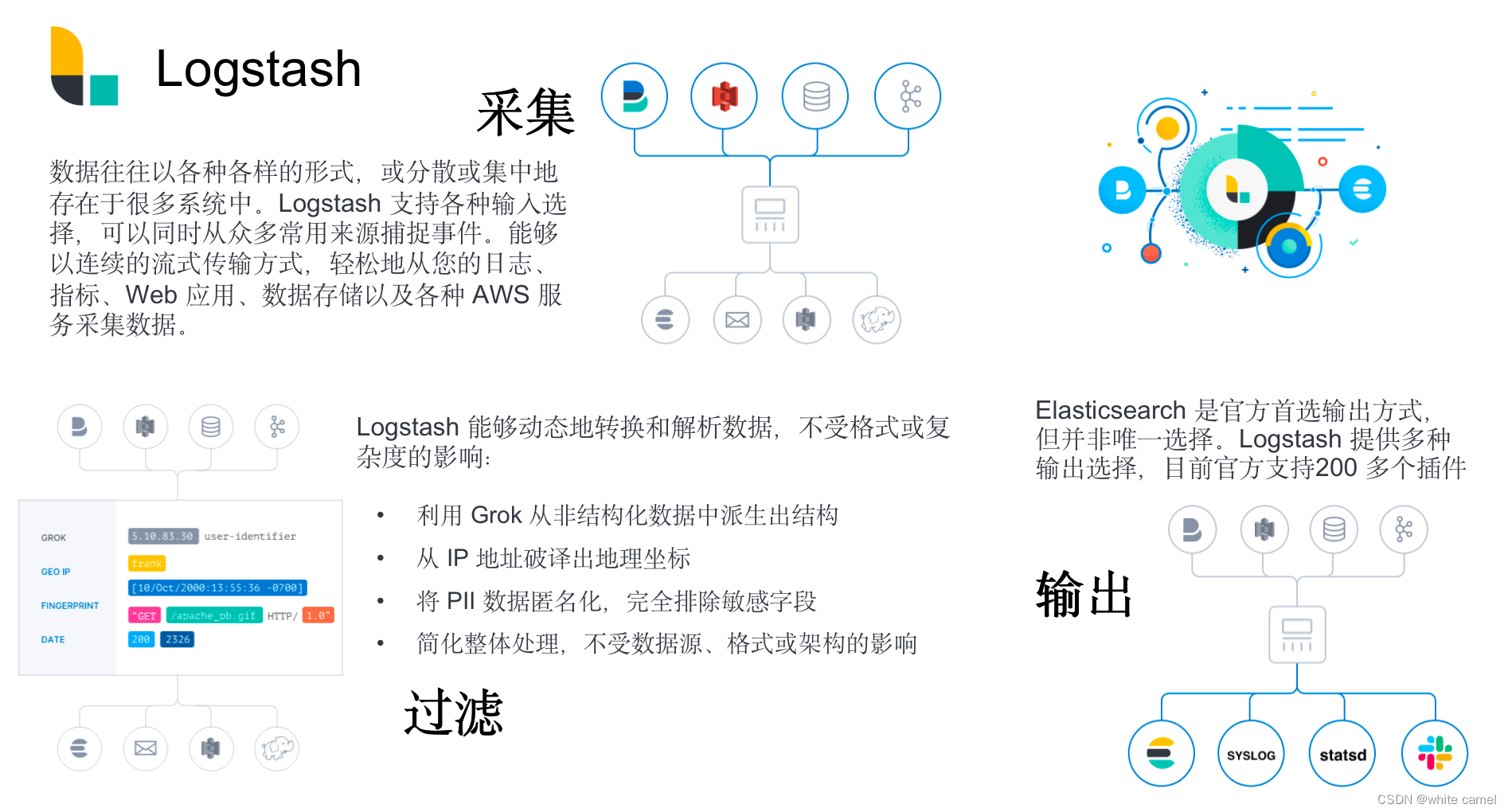
- Kibana : 提供数据的可视化界面
- 查询、查看并与存储在ES索引的数据进行交互操作
- 执行高级的
数据分析,并能以图表、表格和地图的形式查看数据。
- Beats : 轻量级的数据采集器
- 开源:Beats 是一个免费且开放的平台,集合了多种单一用途数据采集器。它们从成百上千或成千上万台机器和系统向 Logstash 或 Elasticsearch 发送数据。
- 轻量级:Beats使用go语言开发,对服务器资源占用极低。Beats 可以采集符合 Elastic Common Schema (ECS) 要求的数据,可以将数据转发至 Logstash 进行转换和解析。
- 即插即用:Filebeat 和 Metricbeat 中包含的一些模块能够简化从关键数据源(例如云平台、容器和系统,以及网络技术)采集、解析和可视化信息的过程。只需运行一行命令,即可开始探索。
- 可扩展:由于Beats开源的特性,如果现有Beats不能满足开发需要,我们可以自行构建,并且完善Beats社区
ElasticSearch 概念
什么是RestFul
REST : 表现层状态转化(Representational State Transfer),如果一个架构符合REST原则,就称它为 RESTful 架构风格。
资源: 所谓"资源",就是网络上的一个实体,或者说是网络上的一个具体信息
表现层 :我们把"资源"具体呈现出来的形式,叫做它的"表现层"(Representation)。
状态转化(State Transfer):如果客户端想要操作服务器,必须通过某种手段,让服务器端发生"状态转 化"(State Transfer)。而这种转化是建立在表现层之上的,所以就是"表现层状态转化"。
REST原则就是指一个URL代表一个唯一资源,并且通过HTTP协议里面四个动词:GET、POST、PUT、DELETE对应四种服务器端的基本操作: GET用来获取资源,POST用来添加资源(也可以用于更新资源),PUT用来更新资源,DELETE用来删除资源。
什么是全文检索
全文检索是计算机程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置。当用户查询时根据建立的索引查找,类似于通过字典的检索字表查字的过程。
- 索: 建立索引 文本---->切分 —> 词 文章出现过 出现多少次
- 检索: 查询 关键词—> 索引中–> 符合条件文章 相关度排序
全文检索(Full-Text Retrieval(检索))以文本作为检索对象,找出含有指定词汇的文本。全面、准确和快速是衡量全文检索系统的关键指标。
关于全文检索,我们要知道:
只处理文本、不处理语义搜索时英文不区分大小写结果列表有相关度排序
什么是Elasticsearch
ElasticSearch 简称 ES ,是基于Apache Lucene构建的开源搜索引擎,是当前流行的企业级搜索引擎。Lucene本身就可以被认为迄今为止性能最好的一款开源搜索引擎工具包,但是lucene的API相对复杂,需要深厚的搜索理论。很难集成到实际的应用中去。但是ES是采用java语言编写,提供了简单易用的RestFul API,开发者可以使用其简单的RestFul API,开发相关的搜索功能,从而避免lucene的复杂性。
目前 Elasticsearch 有很多地方超越了 Lucene,它不仅可以实现全文搜索功能,还可以完成以下工作:
- 分布式实时文档存储,并将每一个字段都编入索引,使其可以被搜索。
- 分布式实时分析与搜索引擎。
- 可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据。
- 可以轻松地通过客户端或者任何你喜欢的程序语言与 Elasticsearch 的 RESTful API 进行通信
ES的应用场景
ES主要以轻量级JSON作为数据存储格式,这点与MongoDB有点类似,但它在读写性能上优于 MongoDB 。同时也支持地理位置查询 ,还方便地理位置和文本混合查询 。 以及在统计、日志类数据存储和分析、可视化这方面是引领者。
- 国外:
Wikipedia(维基百科)使用ES提供全文搜索并高亮关键字、StackOverflow(IT问答网站)结合全文搜索与地理位置查询、Github使用Elasticsearch检索1300亿行的代码。
- 国内:
百度(在云分析、网盟、预测、文库、钱包、风控等业务上都应用了ES,单集群每天导入30TB+数据, 总共每天60TB+)、新浪 、阿里巴巴、腾讯等公司均有对ES的使用。
使用比较广泛的平台ELK(ElasticSearch, Logstash, Kibana)
安装Elasticsearch
Elasticsearch服务的访问端口为9200
传统安装
鉴于篇幅, 自行百度安装, 有具体详细针对Linux, windows的安装过程
docker安装
# 1.获取镜像
- docker pull elasticsearch:7.14.0
# 2.运行es
- docker run -d -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" elasticsearch:7.14.0
# 3.访问ES
- http://10.15.0.5:9200/
ES目录结构
| 目录名称 | 说明 |
|---|---|
| bin | 脚本目录,启动ES节点和安装插件 |
| config | 配置文件目录,如elasticsearch配置、角色配置、jvm配置等 |
| lib | elasticsearch所依赖的java库 |
| data | 默认的数据存放目录,包含节点、分片、索引、文档的所有数据,生产环境要求必须修改 |
| logs | 默认的日志文件存储路径,生产环境务必修改 |
| modules | 包含所有的Elasticsearch模块,如Cluster、Discovery、Indices等 |
| plugins | 已经安装的插件的目录 |
| jdk | 7.0以后才有,自带的java环境 |
Kibana 概念
Kibana Navicat是一个针对Elasticsearch mysql的开源分析及可视化平台,使用Kibana可以查询、查看并与存储在ES索引的数据进行交互操作,使用Kibana能执行高级的数据分析,并能以图表、表格和地图的形式查看数据。
安装Kibana
传统安装
# 1. 下载Kibana
- https://www.elastic.co/downloads/kibana
# 2. 安装下载的kibana
- $ tar -zxvf kibana-7.14.0-linux-x86_64.tar.gz
# 3. 编辑kibana配置文件
- $ vim /Kibana 安装目录中 config 目录/kibana/kibana.yml
# 4. 修改如下配置
- server.host: "0.0.0.0" # 开启kibana远程访问
- elasticsearch.hosts: ["http://localhost:9200"] #ES服务器地址
# 5. 启动kibana
- ./bin/kibana
# 6. 访问kibana的web界面
- http://10.15.0.5:5601/ #kibana默认端口为5601
docker安装
# 1.获取镜像
- docker pull kibana:7.14.0
# 2.运行kibana
- docker run -d --name kibana -p 5601:5601 kibana:7.14.0
# 3.进入容器连接到ES,重启kibana容器,访问
- http://10.15.0.3:5601
# 4.基于数据卷加载配置文件方式运行
- a.从容器复制kibana配置文件出来
- b.修改配置文件为对应ES服务器地址
- c.通过数据卷加载配置文件方式启动
`docker run -d -v /root/kibana.yml:/usr/share/kibana/config/kibana.yml --name kibana -p 5601:5601 kibana:7.14.0
# kibana配置文件 连接到ES
server.host: "0"
server.shutdownTimeout: "5s"
elasticsearch.hosts: [ "http://elasticsearch:9200" ]
monitoring.ui.container.elasticsearch.enabled: true
ElasticSearch相关术语
接近实时(NRT — Near Real Time )
Elasticsearch是一个接近实时的搜索平台。这意味着,从索引一个文档直到这个文档能够被搜索到有一个轻微的延迟(通常是1秒内)
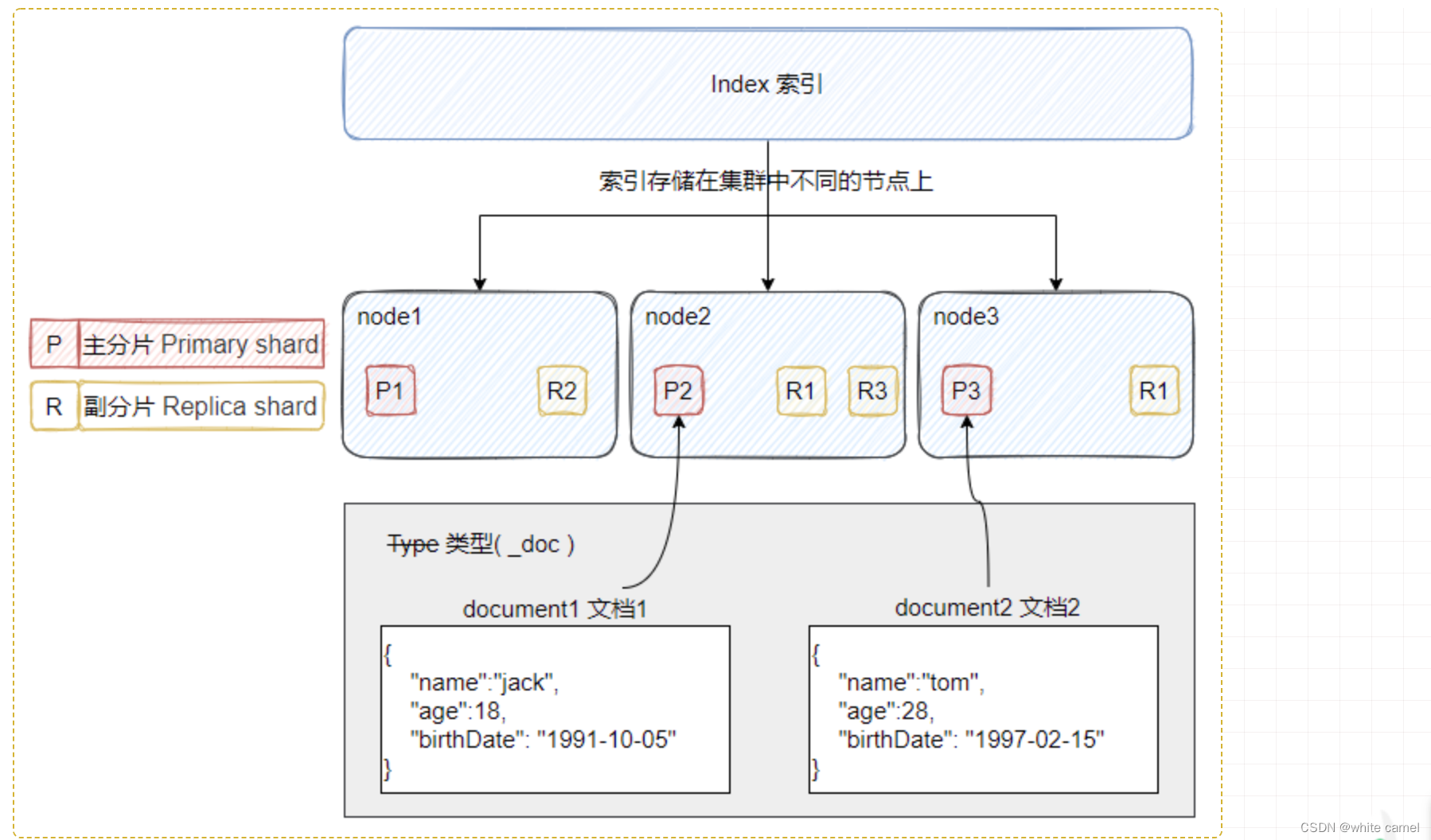
索引(index)
索引是文档的容器,一类文档的集合,存储在分片Shard上
一个索引就是一个拥有几分相似特征的文档的集合。一个索引由一个名字来标识(必须全部是小写字母的),并且当我们要对这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字。在一个集群中,如果你想,可以定义任意多的索引。
- 索引类比关系数据库的db
- 索引的Mapping定义文档字段类型,类比关系数据库的schema
- 索引的Setting定义数据在分片上的分布
映射(Mapping)
相当于数据库中的schema,用来约束字段的数据类型,每一种数据类型都有对应的使用场景。mapping 中定义了一个文档所包含的所有 field 信息,每个文档都有映射,但是在大多数使用场景中,我们并不需要显示的创建映射,因为ES中实现了动态映射。我们在索引中写入一个下面的JSON文档
{
"name":"jack",
"age":18,
"birthDate": "1991-10-05"
}
在动态映射的作用下,name会映射成text类型,age会映射成long类型,birthDate会被映射为date类型,映射的索引信息如下。
{
"mappings": {
"_doc": {
"properties": {
"age": {
"type": "long"
},
"birthDate": {
"type": "date"
},
"name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}
}
自动判断的规则如下:
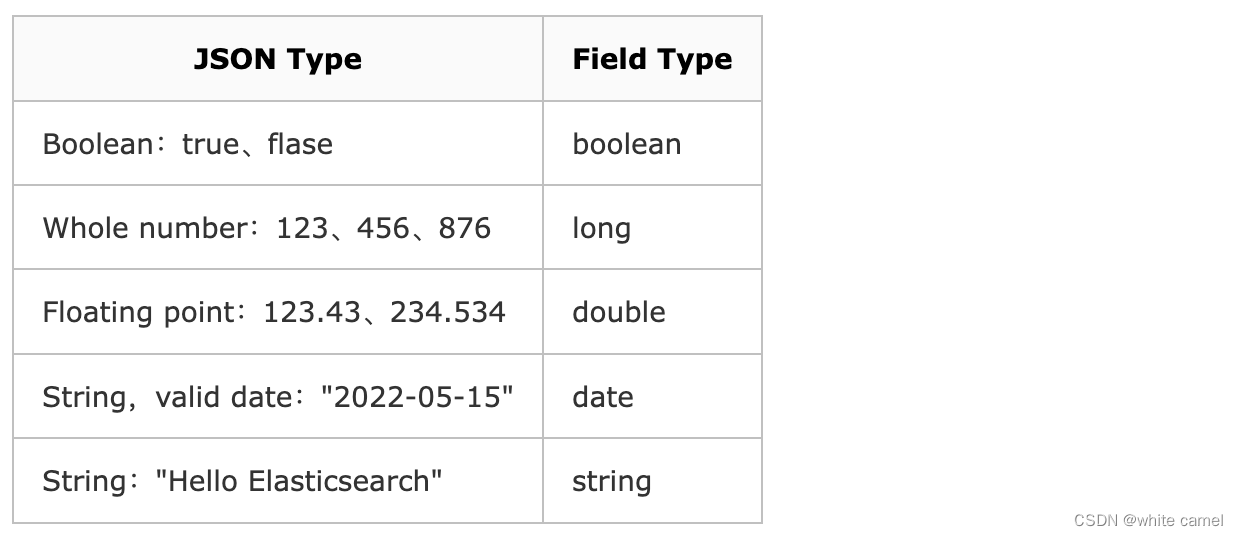
常见的ELasticSearch数据类型如下:
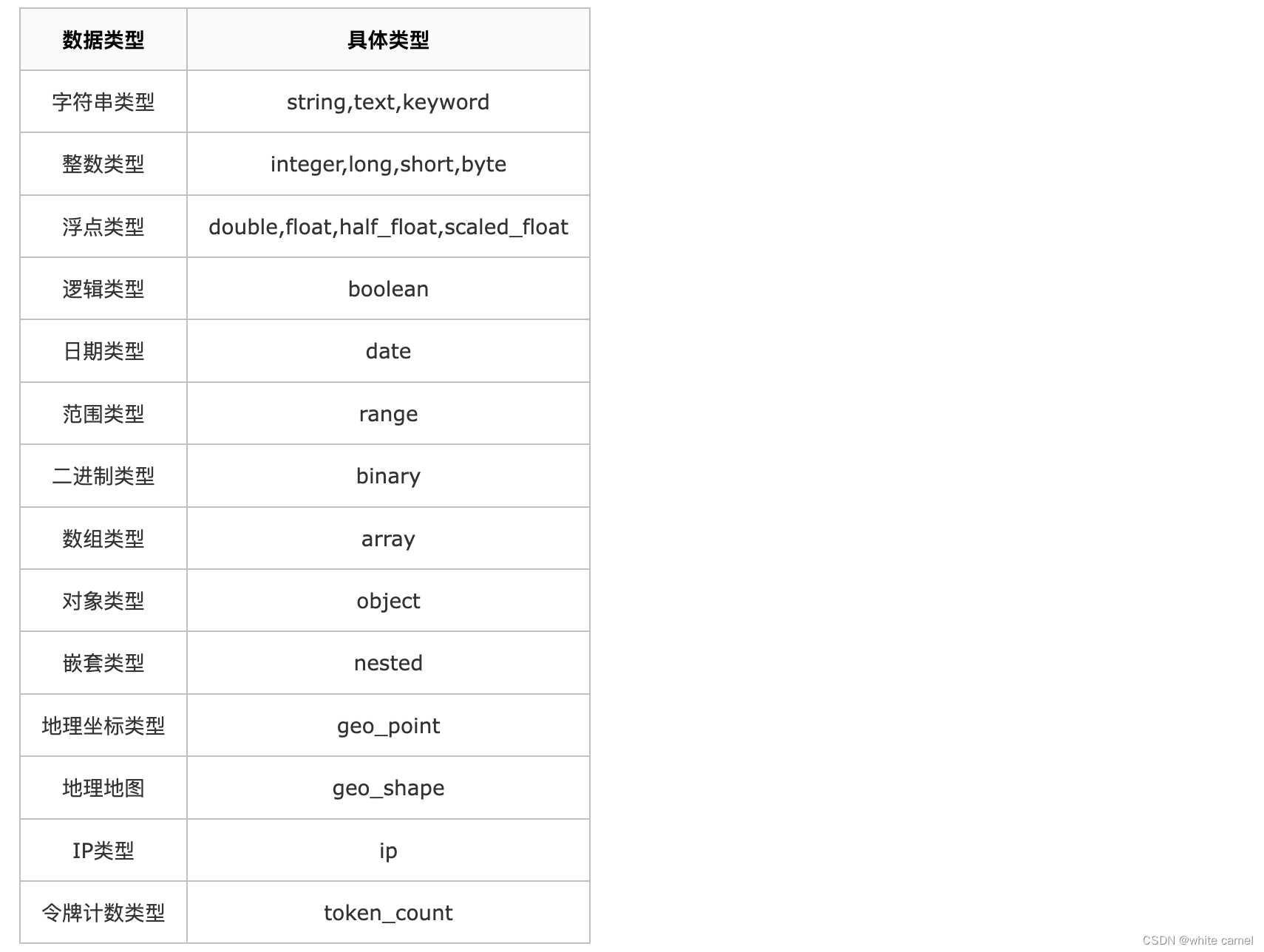
注意事项关于字符串类型:
string类型: 在ElasticSearch 旧版本中使用较多,从ElasticSearch 5.x开始不再支持string,由text和keyword类型替代。
- text类型的字段不用于排序,很少用于聚合,需要分词设置text类型
- keyword类型适用于索引结构化的字段,keyword类型的字段只能通过精确值搜索到。不需要分词设置keyword类型
补充:对text类型的字段,会先使用分词器分词,生成倒排索引,用于之后的搜索。对keyword类型的字段,不会分词,搜索时只能精确查找
文档(document)
一个文档是一个可被索引的最小单元,类似于表中的一条记录。 比如,你可以拥有某一个员工的文档,也可以拥有某个商品的一个文档。文档以采用了轻量级的数据交换格式JSON(Javascript Object Notation)来表示。
- 文档类比关系数据库一条记录
- 每个文档有一个唯一的ID,类比关系数据库主键ID
- json对象由filed构成,filed类比关系数据库column
{
"_index": "user",
"_type": "_doc",
"_id": "qbuOs4AB1VH6WaY_OsFW",
"_version": 1,
"_score": 1,
"_source": {
"name": "张三",
"address": "广东省深圳市",
"remark": "他是一个程序员",
"age": 28,
"salary": 8800,
"birthDate": "1991-10-05",
"createTime": "2019-07-22T13:22:00.000Z"
}
}
上图为 ES 一条文档数据,而一个文档不只有基础数据,它还包含了元数据(metadata)——关于文档的信息,也就是用下划线开头的字段,它是官方提供的字段:
- _index :文档所属索引名称,即文档存储的地方。
- _type :文档所属类型名(此处已默认为_doc)。
- _id :文档的唯一标识。在写入的时候,可以指定该 Doc 的 ID 值,如果不指定,则系统自动生成一个唯一的 UUID 值。
- _score :顾名思义,得分,也可称之为相关性,在查询是 ES 会 根据一些规则计算得分,并根据得分进行倒排。除此之外,ES 支持通过 Function score query 在查询时自定义 score 的计算规则。
- _source :文档的原始 JSON 数据。
字段(field)
相当于是数据表的字段,字段在ES中可以理解为JSON数据的键,是文档中的基本单位,以键值对的形式存在。在下面的JSON数据中,键都是一个字段。
{
"name": "张三",
"address": "广东省深圳市",
"remark": "他是一个程序员",
"age": 28,
"salary": 8800,
"birthDate": "1991-10-05",
"createTime": "2019-07-22T13:22:00.000Z"
}
ES和DB的关系


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











