







文章目录
2. 控制结构
2.1 select
select 是 Go 在语言层面提供的多路 I/O 复用机制,用于检测多个管道是否就绪(即可读或可写),其特性跟管道息息相关。
用法特性
管道读写
select 只能作用于管道,包括数据读取和写入。每个 case 语句只能操作一个管道。
func selectForChan(c chan string) {
var recv string
send := "Hello"
select {
case recv = <-c:
fmt.Printf("received %s\n", recv)
case c <- send:
fmt.Printf("sent %s\n", send)
}
}
| channel 空间 | channel 占用情况 | select 执行结果 |
|---|---|---|
| 没有缓冲区 | 不能读也不能写 | 阻塞 |
| 有缓冲区 | 可以写入数据 | 写操作对应 case 语句 |
| 有缓冲区 | 缓冲区放满数据 | 读操作对应 case 语句 |
| 有缓冲区 | 有部分数据且可写入数据 | 随机挑选 case 语句执行 |
返回值
select 下 case 读取管道时可以给局部变量赋值,最多两个
func selectAssign(c chan string) {
select {
case <-c:
fmt.Printf("0")
case d := <-c:
fmt.Printf("1: received %s\n", d)
case d, ok := <-c:
if !ok {
fmt.Printf("no data found\n")
break
}
fmt.Printf("2: received %s\n", d)
}
}
default
default 语句不能处理管道读写操作,当所有 case 语句都阻塞时执行 default 语句
使用举例
永久阻塞
func main() {
select {}
}
select 语句不包含 case 语句和 default 语句,协程(main)将陷入永久性阻塞,main 函数不会退出
快速检错
使用 select 语句快速检查管道中是否有错误并且避免陷入循环
// k8s 调度器
select {
case manageJobErr = <-errCh:
if manageJobErr != nil {
break
}
default:
}
为什么通过 select 来检查错误?而不是采用 switch
当对象为管道的时候,确实只能用 select 来操作管道,switch 只能在同一协程内执行
限时等待
ch1 := make(chan string)
// 激活一个goroutine,但5秒之后才发送数据
go func() {
time.Sleep(5 * time.Second)
ch1 <- "put value into ch1"
}()
select {
case val := <-ch1:
fmt.Println("recv value from ch1:", val)
return
// 只等待3秒,然后就结束
case <-time.After(3 * time.Second):
fmt.Println("3 second over, timeover")
}
实现原理
-
为什么每个 case 语句只能处理一个管道?-- 每个 scase 中仅能存放一个管道
-
为什么 case 语句的执行顺序是随机的(多个 case 都就绪的情况下)?
-
为什么在 case 语句中向值为 nil 的管道中写数据不会触发 panic?
数据结构
type scase struct {
c *hchan // 操作的管道
kind uint16 // case 类型
elem unsage.Pointer // data elemen
...
}
const (
caseNil = iota // 管道值为 nil
caseRecv // 读管道 case
caseSend // 写管道 case
caseDefault // default
)
caseNil 表示操作的管道值为 nil,既不可读也不可写,永远不会被命中,在运行时会被忽略而非 panic
default 为特殊类型的 case 语句,不会操作管道,select 中仅可存在一个,可以出现在任意位置
elem 表示数据存放的地址,caseRecv 时表示管道读出的数据的存放地址;caseSend 时表示写入管道的数据存放地址
go 提供了 selectgo() 方法用于处理 select 语句
func selectgo(cas0 *scase, order0 *uint16, ncases int) (int, bool)
cas0:case 语句数组地址,长度为 ncases
order0:整型数组地址,长度为 case 个数的 2 倍。是 case 执行随机性的关键
-
过滤管道值为 nil 的case
-
生成 case 的随即顺序,保存到 pollorder 中。fastrandn()
-
循环遍历各个 case。管道就绪即进行读写操作
使用 select 读取管道时,尽量检查读取是否成功,以便及时发现管道异常
for-range
for-range 表达式用于遍历集合元素,比传统的 for 循环更简洁、更直观
特性
作用对象:数组、切片、string、map、channel
string
for-range 遍历过程中每次迭代均会执行一次赋值操作,在 string 类型时考虑使用下标而不是赋值,避免内存拷贝影响性能。
range 作用于 string 返回的下标可能不连续,因为 string 底层使用 unicode 编码,对于中文等一个字符占用字节数 >1。
map
range 作用于 map 时,返回每个元素的 key 和 value
map 没有顺序,遍历顺序随机。因此不要在循环过程中修改 map
channel
channel 元素没有下标的概念,最多只能返回一个元素。range 会阻塞等待 cahnnel 中的数据,直到 channel 被关闭。range 作用于值为 nil 的 channel 时,则会永久阻塞。
for idx := range array <==> for idx, _ := range array
实现原理
for-range ——> 传统 for 循环
3. 协程
概念
协程术语:coroutine
Go 在语言层面直接提供对协程的支持称为 goroutine
基本概念
进程
进程是应用程序的启动实例,每个进程都有独立的内存空间,不同进程通过进程间的通信方式来通信。
线程
线程从属于进程,每个进程至少包含一个线程,线程是 CPU 调度的基本单位,多个线程之间可以共享进程的资源,并通过共享内存等线程间的通信方式来通信。
协程
协程可理解为一种轻量级线程,与线程相比,协程不受操作系统调度,协程调度器由用户应用程序提供,协程调度器按照调度策略把协程调度到线程中运行。Go 应用程序的协程调度器由 runtime 包提供,用户使用 go 关键字即可创建协程,这也就是在语言层面直接支持协程的含义。
协程的优势
高并发场景频繁创建和销毁线程会造成不必要的开销——>线程池
线程池由操作系统进行调度。如果线程任务发生系统调用,操作系统将线程置为阻塞状态,线程池的消费能力下降。如果大部分任务都进行系统调用,任务队列中的任务就会产生堆积。通过增加线程池中线程的数量可以一定程度解决问题,但是随着线程增多,过多线程争抢 CPU 资源,导致上下文切换开销变大。
线程池——>协程
协程工作在用户态,能大大减少上下文切换的开销。协程调度器把可运行的协程逐个调度到线程中执行,同时及时把阻塞的协程调度出线程,避免线程的频繁切换,达到少量线程实现高并发效果。
线程由操作系统调度,在内核态,系统调用时阻塞;协程由协程调度器调度,在用户态,能及时切换阻塞中的任务,提高执行效率。
多个协程分享操作系统分给线程的时间片,从而达到充分利用 CPU 算力的目的。
调度模型
线程模型
线程可分为用户线程和内核线程
-
N:1 模型,N 个用户线程运行在 1 个内核线程中,优点是用户线程上下文切换快,缺点是无法充分利用 CPU 多核算例
-
1:1 模型,每个用户线程对应一个内核线程,优点是充分利用 CPU 算力,缺点是线程上下文切换较慢
-
M:N 模型,Go 实现模型,M 个用户线程(协程)运行在 N 个线程中。优点充分利用 CPU 算力且协程上下文切换快,缺点是模型的调度算法较为复杂
Go 调度器模型
三个关键实体
-
machine:工作线程,由操作系统调度
-
processor:处理器,包含运行 Go 代码的必要资源,也有调度 goroutine 的能力
-
goroutine:Go 协程,每个 go 关键字都会创建一个协程
M 必须持有 P 才可以执行代码,M 也会被系统调用阻塞
P 的个数在程序启动时决定,默认等同 CPU 的核数,也可以通过配置 GOMAXPROCS
export GOMAXPROCS=80
runtime.GOMAXPROCS(80)
M 的个数通常稍大于 P 的个数,因为除了运行 Go 代码,runtime 包还有其他内置任务需要处理

早期只有全局队列,处理器需要争抢锁来调度,严重影响并发执行效率,后来引入局部 runqueues,每个处理器访问自己的本地队列不需要加锁
调度策略
1. 队列轮转
G 执行完毕后,P 会调度本地队列的另一个 G 到 M 中执行,同时会周期性地查看全局队列中是否由 G 待运行将其调度到 M 中执行。避免“饿死”
2. 系统调用
M 的个数通常稍大于 P 的个数,当 G 即将进入系统调用时,M 释放 P,从冗余的 M 接管 P,继续执行 P 中剩下的 G。
3. 工作量窃取
本地队列为空——全局队列为空——偷取其他 P 的协程(一半的任务)
当某个处理器 P 没有需要调度的协程时,从其他处理器中偷取协程。
4. 抢占式调度
类似时间片轮转,调度器会监控每个协程的执行时间,一旦执行时间过长且有其他协程在等待时,会把协程暂停,转而调度等待的协程。
1.14 前在函数调用间隙检查是否可被抢占,没有函数调用时会无限占用执行权
1.14 后引入基于信号的抢占机制解决
5. GOMAXPROCS
由于旧的 M 被阻塞和新的 M 得到运行之间有一定间隔,在 I/O 密集型应用中可以把 GOMAXPROCS 的值设置大一些
4. 内存管理
Go 在某些应用场景下垃圾回收会暂时停止程序的运行,影响程序性能。
内存分配
C 语言通过内存分配器调用 malloc() 方法动态申请内存,Go 也实现了内存分配器,原理与 tcmalloc 类似,维护一块大的全局内存,每个线程(Go 中为处理器 P)维护一块小的私有内存,私有内存不足时再从全局申请。
基础概念
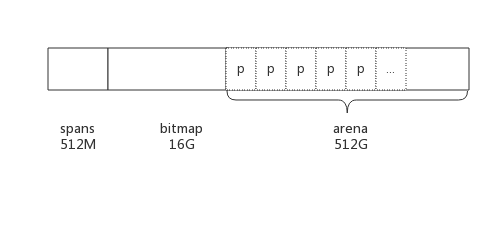
内存划分
- arena:实际内存
大小 512GB,划分为一个个 page 页,每个页大小为 8KB,共有 512GB/8KB 页
- span:存放 span 指针,对应一个或多个 page
大小 512MB,即 (512GB/8KB)*指针大小(8byte)
- bitmap:主要用于 GC
大小 512GB
SPAN
用于管理 arena 页,span 内部划分粒度更小的块,每个 span 用于管理特定的 class 对象
// class bytes/obj bytes/span objects waste bytes
// 1 8 8192 1024 0
// 2 16 8192 512 0
// 3 32 8192 256
// ...
// 10 144 8192 56 128
// ...
class:classID,span 数据结构中的 spanclass,表示该 span 可处理的对象类型
bytes/obj:该 class 代表对象的字节数
bytes/span:每个 span 占用堆的字节数,页数 x 页大小(1*8KB)
objects:每个 span 可分配的对象个数,span/obj
waste bytes:每个 span 产生的内存碎片,span%obj
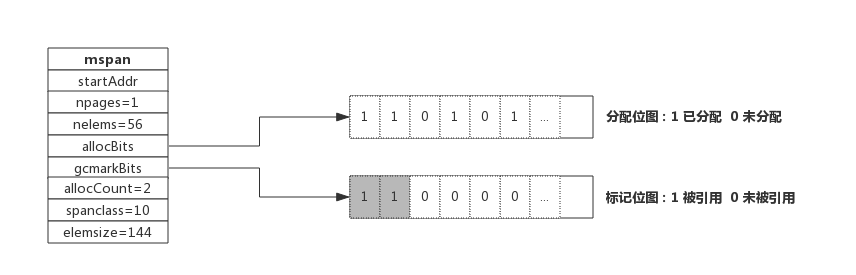
- 数据结构
type mspan struct {
next *mspan //链表后向指针,用于将span链接起来
prev *mspan //链表前向指针,用于将span链接起来
startAddr uintptr // 起始地址,也即所管理页的地址
npages uintptr // 管理的页数
nelems uintptr // 块个数,也即有多少个块可供分配
allocBits *gcBits //分配位图,每一位代表一个块是否已分配
allocCount uint16 // 已分配块的个数
spanclass spanClass // class表中的class ID
elemsize uintptr // class表中的对象大小,也即块大小
}

CACHE
由于 span 只能存储特定 class,是内存管理的基本单位,因此需要有用来管理 span 的结构,即 mcentral。各线程需要内存时从 mcentral 管理的 span 中申请内存,为了避免多线程申请内存不断加锁,Go 为每个线程分配了 span 的缓存,即 mcache
type mcache struct {
alloc [67*2]*mspan // 按class分组的mspan列表
}
span 共有 67 种 calss 类型,每种 class 类型都有两组 span 列表,第一组对象包含指针,第二组对象不包含指针,这么做是为了提高 GC 扫描性能,对于不包含指针的 span 列表无需扫描。根据对象是否包含指针分为 noscan 和 scan 两类

初始化时 cache 没有任何 span,在使用过程中动态从 central 获取并缓存下来
CENTRAL
cache:线程的私有资源管理,针对单个线程
central:全局资源管理,为多个线程服务
type mcentral struct {
lock mutex //互斥锁
spanclass spanClass // span class ID
nonempty mSpanList // non-empty 指还有空闲块的span列表
empty mSpanList // 指没有空闲块的span列表
nmalloc uint64 // 已累计分配的对象个数
}
获取 span:加锁——从 nonempty 去除可用 span,将其从链表删除——将 span 加入 empty 列表——span 给到线程——解锁——span 放入 cache
归还 span:加锁——span 从 empty 列表删除——span 加入 nonempty 列表——解锁
HEAP
每个 mcentral 对象只管理特定 class 规格的 span,每种 class 都会对应一个 mcentral,用于管理 mcentral 集合的为 mheap
type mheap struct {
lock mutex
spans []*mspan // 指向 spans 区域,用于映射 span 和 page 的关系
bitmap uintptr //指向bitmap首地址,bitmap是从高地址向低地址增长的
arena_start uintptr //指示arena区首地址
arena_used uintptr //指示arena区已使用地址位置
central [67*2]struct {
mcentral mcentral
pad [sys.CacheLineSize - unsafe.Sizeof(mcentral{})%sys.CacheLineSize]byte
}
}
mheap 管理着全部的内存,事实上 Go 就是通过一个 mheap 类型的全局变量进行内存管理的

内存分配
针对待分配对象的大小不同有不同的分配逻辑:
- (0, 16B) 且不包含指针的对象: Tiny 分配
- (0, 16B) 包含指针的对象:正常分配
- [16B, 32KB] : 正常分配
- (32KB, -) : 大对象分配 其中 Tiny 分配和大对象分配都属于内存管理的优化范畴,这里暂时仅关注一般的分配方法。
以申请 size 为 n 的内存为例,分配步骤如下:
- 获取当前线程的私有缓存 mcache
- 根据 size 计算出适合的 class 的 ID
- 从 mcache 的 alloc [class] 链表中查询可用的 span
- 如果 mcache 没有可用的 span 则从 mcentral 申请一个新的 span 加入 mcache 中
- 如果 mcentral 中也没有可用的 span 则从 mheap 中申请一个新的 span 加入 mcentral
- 从该 span 中获取到空闲对象地址并返回
mspan——mcache——mcentral——mheap 资源不足时逐级申请
垃圾回收
垃圾回收算法
- 引用计数
每个对象维护一个引用计数,当引用对象被销毁时计数减一,计数为 0 时回收该对象
优点:对象可以很快被回收,不会出现内存耗尽或达到阈值才回收
缺点:不能很好地处理循环引用,实时维护引用计数也有一定代价
代表语言:Python、PHP、Swift
- 标记-清除
从跟变量开始遍历所有引用的对象,引用的对象标记为”被引用“,没有标记地对象被回收
优点:解决了引用计数地缺点
缺点:需要 STW(Stop The World),即暂时停止程序运行
代表语言:Go(三色标记法)
- 分代收集
按照对象生命周期长短划分不同的代空间,生命周期长地放入老年代,短地放入新生代,不同代有不同的回收算法和回收效率。
优点:回收性能好
缺点:算法复杂
代表语言:Java
Go 垃圾回收
- 原理
垃圾回收的核心就是标记出被引用的内存和未被引用的内存,把未被引用的内存回收,供后续内存分配使用

垃圾回收开始时从 root 对象开始扫描,把 root 对象引用的内存标记为 “被引用”,考虑到内存块中存放的可能是指针,所以还需要递归的进行标记,全部标记完成后,只保留被标记的内存,未被标记的全部标识为未分配即完成了回收。
- 内存标记(Mark)
span 下存在 allocBits 和 gcmarkBits,两者的数据结构完全一样,allocBits 表示内阁内存块的分配情况,gcmarkBits 标记内存块被引用的情况。
标记阶段:gcmarkBits 对每块内存进行标记,有对象引用标记为 1,没有标记为 0
标记结束:allocBits 指向 gcmarkBits,标记为 1 的才是存活的内存块
- 三色标记法
需要一个标记队列对标记对象进行存放,按照顺序对每个对象进行标记
灰色:对象还在标记队列中等待
黑色:对象已被标记,gcmarkBits 对应的位为 1(不会在本次 GC 中被清理)
白色:对象未被标记,gcmarkBits 对应的位为 0(对象会在本次 GC 中被清理)
- STW
为了避免回收过程中指针传递引起内存引用关系的变化,GC 时停止所有的 goroutine
STW 时间的长短直接影响了应用的执行
垃圾回收优化
- 写屏障(Write Barrier)
写屏障类似一种开关,在 GC 特定时机开启,开启后指针传递时会标记指针,本轮不回收。
写屏障可以让 goroutine 与 GC 同时运行。虽然写屏障不能完全消除 STW,但可以大大缩短 STW 的时间
- 辅助 GC(Mutator Assist)
为了防止内存分配过快,在 GC 执行过程中,如果 goroutine 需要分配内存,那么这个 goroutine 会参与一部分 GC 的工作,即帮助 GC 做一部分工作,这个机制叫作 Mutator Assist。
垃圾回收触发时机
- 内存分配量达到阈值
阀值 = 上次GC内存分配量 * 内存增长率
内存增长率由环境变量 GOGC 控制,默认为 100,即每当内存扩大一倍时启动 GC。
- 定期出发 GC
默认情况下,最长 2 分钟触发一次 GC
// src/runtime/proc.go:forcegcperiod
var forcegcperiod int64 = 2 * 60 * 1e9
- 手动触发
使用 runtime.GC() 手动触发,主要用于 GC 的性能测试和统计。
GC 性能优化
GC 性能与对象数量负相关,对象越多 GC 性能越差
优化思路
-
减少对象分配的个数,比如对象复用或使用大对象组合多个小对象等
-
注意内存逃逸现象
逃逸分析
所谓逃逸分析(Escape analysis)是指由编译器决定内存分配的位置,不需要程序员指定。 函数中申请一个新的对象
- 如果分配在栈中,则函数执行结束可自动将内存回收;
- 如果分配在堆中,则函数执行结束可交给 GC(垃圾回收)处理;
逃逸分析还跟闭包息息相关
逃逸策略
在函数中新申请对象时,编译器会自动决定是否逃逸
-
函数外部没有引用,优先放到栈中,执行结束自动内存回收
-
函数外部存在引用,必定放到堆中,由 GC 处理
仅在函数内部使用的变量也有可能放到堆中,比如内存过大超过栈的存储能力。
逃逸场景
- 指针逃逸
package main
type Student struct {
Name string
Age int
}
func StudentRegister(name string, age int) *Student {
s := new(Student) //局部变量s逃逸到堆
s.Name = name
s.Age = age
return s
}
func main() {
StudentRegister("Jim", 18)
}
go build -gcflags=-m
# .\main.go:9: new(Student) escapes to heap
- 栈空间不足逃逸
package main
func Slice() {
s := make([]int, 1000, 10000)
for index, _ := range s {
s[index] = index
}
}
func main() {
Slice()
}
- 动态类型逃逸
很多函数参数为 interface 类型,比如 fmt.Println (a …interface {}),编译期间很难确定其参数的具体类型,也会产生逃逸。
package main
import "fmt"
func main() {
s := "Escape"
fmt.Println(s)
}
s escapes to heap
- 闭包引用对象逃逸
func Fibonacci() func() int {
a, b := 0, 1
return func() int {
a, b = b, a+b
return a
}
}
小结
-
栈上分配内存比堆中分配内存有更高的效率
-
栈上分配的内存不需要 GC 处理
-
堆上分配的内存使用完毕会交给 GC 处理
-
逃逸分析的目的是决定分配地址是栈还是堆
-
逃逸分析在编译阶段完成
函数传递指针真的比传值效率高吗?
传递指针可以减少底层值的复制,但如果复制的数据量小,由于指针传递会产生逃逸,可能会使用堆,也可能增加 GC 的负担,所以传递指针不一定是高效的。
——>大对象用指针,小对象用值















 281
281











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









