









如何完整处理一个故障,聊聊我的思路。
技术人人都可以磨炼,但处理问题的思路和角度各有不同,希望这篇文章可以抛砖引玉。

一、问题背景
某业务模块反馈系统涉及提交保存类的操作异常缓慢,应用运维的兄弟排查说update相关的操作卡住了,卡在了数据库。
卡在了数据库...留给我一句这,真让人头大。
数据库环境:Oracle 19c RAC
操作系统:CentOS Linux release 7.6.1810 (Core)
存储:EMC存储
二、故障现象
-
业务系统提交保存类操作异常,应用几乎宕机。
三、故障说明
-
通过数据库和OS 的监控数据,判断出故障链:节点1等待lgwr进程-->active session升高, 阻塞源lgwr进程在节点2-->io 等待-->操作系统IO使用率100% -->io流量很小,硬件故障。
-
硬件故障,导致问题的诱因不可控。
-
追溯监控数据,数据库监控关键指标act 和locktop,在故障出现以后出现升高,偏离正常值,这些关键指标,运维平台仪表盘可以用来做为数据库健康度参考指标。
四、疑问点排查及分析思路
1、什么时间点开始有异常?异常前有没有做过变更?
应用运维的兄弟反映昨天开始出现异常,而且系统已经很久没有做过变更了。
ps:很多系统故障都是由变更引发的,提前了解系统做过什么操作对追根溯源很重要
2、提交和保存类操作慢,DB是不是有阻塞会话?
节点1

节点2
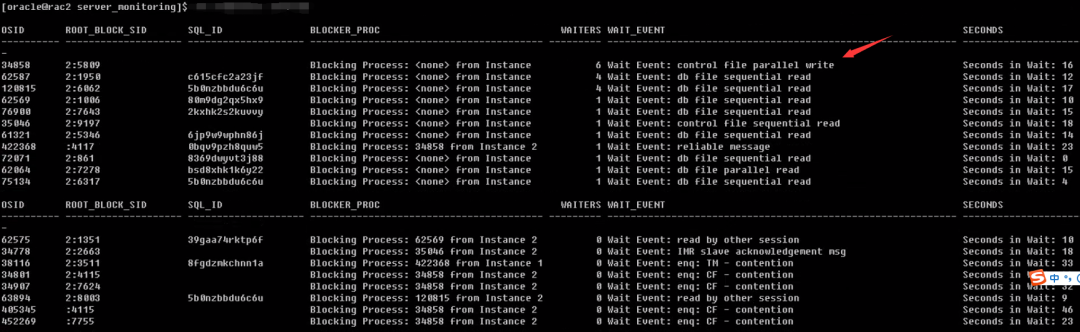
3、阻塞会话等待什么?
两个节点等待和lgwr、control write有关,多次查询等待时有时无。
查看pid为34852的会话
节点1

节点2

可以看到节点2卡在了lgwr进程上。
检查节点2的io等待情况
节点2

查看节点2的io流程情况,io绝对值并不大

对比节点1的io流量

两个节点的io流量绝对值都不大,怀疑是硬件故障
查看节点2的io空闲率
节点2
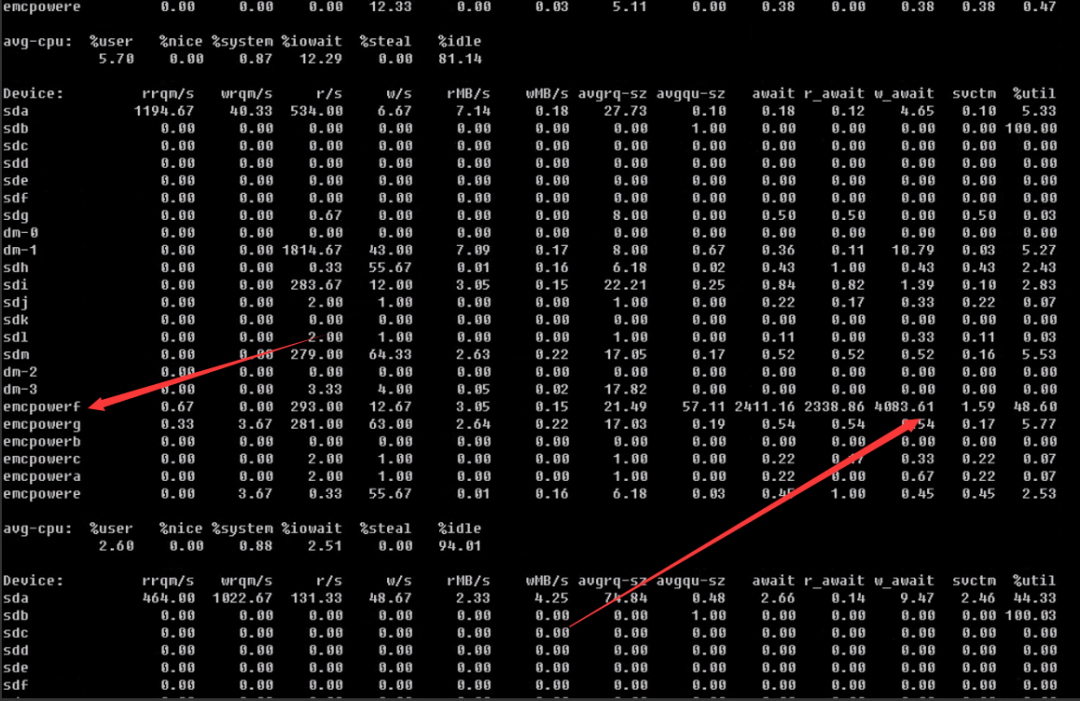
排查到当前这一步,基本上可以断定存储故障,为了验证一下这个思路,我关闭了节点2实例,业务层面再次发起提交保存类操作速度恢复正常。
4、解决?
rac的io链路是比较长的,如主机上的hba卡,光纤,san交换机,存储控制器,前端口等,都有可能出现问题,我的工作到此结束,解决硬件故障那是服务器厂商的事 。
。
长舒一口气,故障处理结束,故障分析处理方案整理成册,争取著作等身。
全文结束。
![]()
聚焦技术与人文,分享干货,共同成长!
更多内容请关注“数据与人”
















 438
438











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









