







一 环境
ubuntu14+pycharm+python3.6+spark2.3
二 目的
使用NC程序作为套接字服务端数据源,实现wordcount功能
三 步骤
1.启动socket服务器端:打开shell交互式窗口,执行命令:nc -lk 9999,监听9999端口
2.编写Socket.py文件作为socket客户端,接收三个参数:self、主机地址、端口号
# python3
# -*- coding:utf-8 -*-
# @Time: 9/5/19 10:25 AM
# @Author: Damon
# @Software: PyCharm
'''
1.此程序为socket客户端,向服务端发送连接请求(服务端事先监听某个端口),源源不断的从服务端获取数据,使用套接字流作为数据源
2.构建socket服务端:在shell交互式环境中输入命令启动nc程序:nc -lk 9999 监听9999端口
'''
from __future__ import print_function
import sys
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
if __name__=="__main__":
if len(sys.argv)!=3:
print("Usage:Socket.py <hostname> <port>",file=sys.stderr)
exit(-1)
sc=SparkContext(appName="PythonStreamingSocket")
sc.setLogLevel("ERROR")
ssc=StreamingContext(sc,1)
#1.流计算数据源
lines=ssc.socketTextStream(sys.argv[1],int(sys.argv[2]))
#2.流计算计算
counts=lines.flatMap(lambda line:line.split(" ")).map(lambda x:(x,1)).reduceByKey(lambda a,b:a+b)
counts.pprint(50)
#3.启动流计算
ssc.start()
#4.终止流计算
ssc.awaitTermination()
四 运行结果
1.在shell中运行Socket.py程序,进入Socket.py所在目录,执行命令:
#/usr/local/spark为spark安装目录
/usr/local/spark/bin/spark-submit Socket.py localhost 9999
2.在启动的nc服务器端输入单词,并enter键
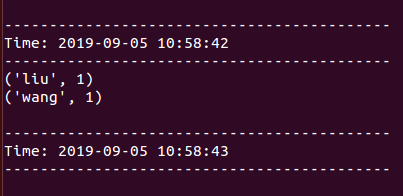
3.在启动Socket.py程序的窗口显示结果:















 175
175











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









