







前言
YACC(Yet Another Compiler Compiler),是一个经典的生成语法分析器的工具。yacc生成的编译器主要是用C语言写成的语法解析器(Parser),需要与词法解析器Lex一起使用,再把两部份产生出来的C程序一并编译------《百度百科》
GoYACC是Golang版本的YACC,听说使用上差不多,但我没用过yacc,没法比较具体差别。我将按照自己的理解对GoYacc的使用进行介绍。
简而言之,通过yacc这个工具,我们可以自己设计语法,实现简单或复杂的命令控制。比如,我们假想出了一种控制描述方式,它长这样:
#this is a comment line
ZMoveTo:0
-XMoveTo:30
-YMoveTo:20
Sleep:1#unit:s
-ZMoveTo:40以上命令描述的行为也很简单:‘#’之后的内容为注释,无需关心;首先Z方向移动到0的位置,成功执行,空行我们会跳过,接下来的是X和Y我们会开子线程让他们同时启动,目标位置分别为30和20,之后延时1秒,再运行z方向到40,但是运行方式为子线程模式。
假设现在我们已经拥有了实现上述操作的函数:
func ZMoveTo(z int) error {
fmt.Println("moving z to", z)
time.Sleep(time.Second)
return nil
}
func XMoveTo(x int) error {
fmt.Println("moving x to", x)
time.Sleep(time.Second)
return nil
}
func YMoveTo(y int) error {
fmt.Println("moving y to", y)
time.Sleep(time.Second)
return nil
}
func Sleep(sec int) {
time.Sleep(time.Duration(sec)*time.Second)
}那么接下来就只需要对上述命令进行解析了。我另外的一篇文章我描述了我能想出来的两种比较好理解的命令实现方式:json解析和硬文本解析:Portal。但今天我学会了另一种方式实现---GoYacc。
GoYacc
要想我们的假想代码能够按照我们的预期执行,就必须把我们人对代码的理解转换为计算机能理解的代码(假设没有编译器或解释器能够理解我们凭空想象出来的语法。比如 'ZMoveTo:20' , 而一般编程语言表示为 'ZMoveTo(20)' )。当然,直接翻译成字节码也不现实。我们需要的仅仅是将它翻译成一门已有的编程语言代码即可,所以实际上,我们可以将yacc理解为一个代码自动生成器,它生成的成果是一种翻译器:将按照某种规则(这个规则就是*.y文件的内容)编写的文本(我们凭空设计的语法代码),以规定的方式用yacc的源语言(这里我们是Golang)执行。我们需要编写的有两个部分,第一个是规则定义:*.y文件(它定义遇到不同的TOKEN应该做什么事,TOKEN可以理解为关键字或者值,比如遇到 ‘HELLO’我们就打印个‘HelloWorld!’,而"ZMoveTo:30",这里就有三个TOKEN,分别是ZMoveTo,冒号,30);第二个是称为词法分析器的Lexer,它定义了各种TOKEN长啥样。
直接从一个官方的例子开始看它到底啥样,然后我们照葫芦画瓢,做一个HelloWorld,最后再加亿点点细节,实现我们的命令脚本解析,地址:goyacc。
安装:首先将上面的goyacc代码clone下来,对里面的源码go build编译,然后把编译结果goyacc可执行文件扔到$GOPATH/bin路径中,新建一个终端命令行窗口,输入goyacc回车,确认goyacc命令存在。
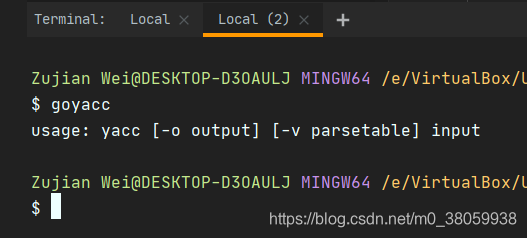
官方的例子在testdata/expr下面,首先看最重要的文件:expr.y
// Copyright 2013 The Go Authors. All rights reserved.
// Use of this source code is governed by a BSD-style
// license that can be found in the LICENSE file.
// This is an example of a goyacc program.
// To build it:
// goyacc -p "expr" expr.y (produces y.go)
// go build -o expr y.go
// expr
// > <type an expression>
%{
package main
import (
"bufio"
"bytes"
"fmt"
"io"
"log"
"math/big"
"os"
"unicode/utf8"
)
%}
%union {
num *big.Rat
}
%type <num> expr expr1 expr2 expr3
%token '+' '-' '*' '/' '(' ')'
%token <num> NUM
%%
top:
expr
{
if $1.IsInt() {
fmt.Println($1.Num().String())
} else {
fmt.Println($1.String())
}
}
expr:
expr1
| '+' expr
{
$$ = $2
}
| '-' expr
{
$$ = $2.Neg($2)
}
expr1:
expr2
| expr1 '+' expr2
{
$$ = $1.Add($1, $3)
}
| expr1 '-' expr2
{
$$ = $1.Sub($1, $3)
}
expr2:
expr3
| expr2 '*' expr3
{
$$ = $1.Mul($1, $3)
}
| expr2 '/' expr3
{
$$ = $1.Quo($1, $3)
}
expr3:
NUM
| '(' expr ')'
{
$$ = $2
}
%%
// The parser expects the lexer to return 0 on EOF. Give it a name
// for clarity.
const eof = 0
// The parser uses the type <prefix>Lex as a lexer. It must provide
// the methods Lex(*<prefix>SymType) int and Error(string).
type exprLex struct {
line []byte
peek rune
}
// The parser calls this method to get each new token. This
// implementation returns operators and NUM.
func (x *exprLex) Lex(yylval *exprSymType) int {
for {
c := x.next()
switch c {
case eof:
return eof
case '0', '1', '2', '3', '4', '5', '6', '7', '8', '9':
return x.num(c, yylval)
case '+', '-', '*', '/', '(', ')':
return int(c)
// Recognize Unicode multiplication and division
// symbols, returning what the parser expects.
case '×':
return '*'
case '÷':
return '/'
case ' ', '\t', '\n', '\r':
default:
log.Printf("unrecognized character %q", c)
}
}
}
// Lex a number.
func (x *exprLex) num(c rune, yylval *exprSymType) int {
add := func(b *bytes.Buffer, c rune) {
if _, err := b.WriteRune(c); err != nil {
log.Fatalf("WriteRune: %s", err)
}
}
var b bytes.Buffer
add(&b, c)
L: for {
c = x.next()
switch c {
case '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', '.', 'e', 'E':
add(&b, c)
default:
break L
}
}
if c != eof {
x.peek = c
}
yylval.num = &big.Rat{}
_, ok := yylval.num.SetString(b.String())
if !ok {
log.Printf("bad number %q", b.String())
return eof
}
return NUM
}
// Return the next rune for the lexer.
func (x *exprLex) next() rune {
if x.peek != eof {
r := x.peek
x.peek = eof
return r
}
if len(x.line) == 0 {
return eof
}
c, size := utf8.DecodeRune(x.line)
x.line = x.line[size:]
if c == utf8.RuneError && size == 1 {
log.Print("invalid utf8")
return x.next()
}
return c
}
// The parser calls this method on a parse error.
func (x *exprLex) Error(s string) {
log.Printf("parse error: %s", s)
}
func main() {
in := bufio.NewReader(os.Stdin)
for {
if _, err := os.Stdout.WriteString("> "); err != nil {
log.Fatalf("WriteString: %s", err)
}
line, err := in.ReadBytes('\n')
if err == io.EOF {
return
}
if err != nil {
log.Fatalf("ReadBytes: %s", err)
}
exprParse(&exprLex{line: line})
}
}
这些代码似乎看上去既陌生又熟悉:Golang代码之间貌似夹杂了些其他的东西。我们将上述代码文件进行简化:
//文档注释
%{
//golang代码的包名定义
//引入golang代码包依赖
%}
//一些看起来像是类型定义的东西
%%
//一些看起来像是匹配规则的东西
%%
//纯golang代码接下来我们结合例子,试着理解一下他们到底什么意思。
Example
首先,尽管我们不知道这些代码是什么意思,但我们不难猜出,这个例程的目的是一个简易的计算器。在开始接触一样新东西前,先上手试试结果是我喜欢的探索方式。那么按照文档注释,试着运行一下:
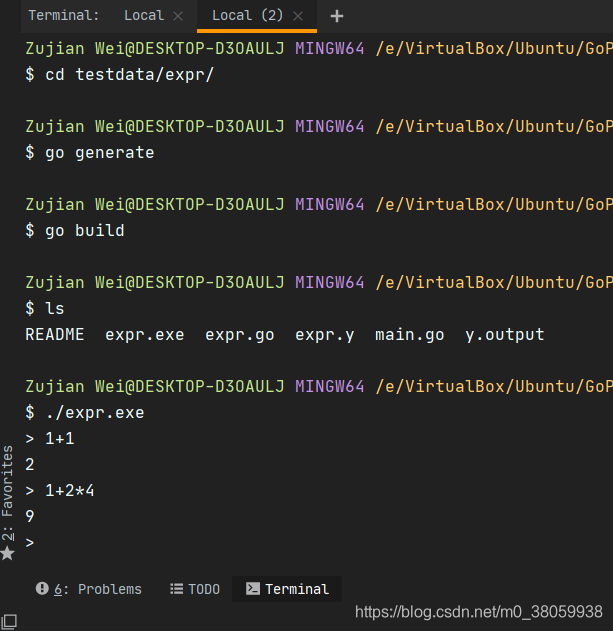
结果果然和我们猜的一样,果真是一个计算器,而且支持表达式运算。想当初我做的一个简单计算器,真就只能两个数加减乘除。现在看到这个工具,我已经不想再去用压栈出栈实现运算优先级处理了,因为这个YACC看起来使用好似挺简单:通过各种规则匹配来完成不同的操作。
现在先忘掉上面的计算器的例子,我们来完成一个最简HelloWorld,文件名为hello.y:
%{
package main
import "fmt"
%}
%union {
type_string string
}
%type <type_string> expression
%token <type_string> PRINT HELLO
%%
expression: HELLO
{
fmt.Println("Hello World!")
}
%%开始解释:
1、在'%{' 和 '%}'之间的部分会原封不动地被拷贝到生成的go代码中,这里我们只需要定义包名和基本依赖。
2、在'%}'和第一个'%%'之间的部分我们称之为类型定义。
%union: 这个很容易联想到c语言中的联合体,这里它其实是定义了一个go的struct:xxSymType。这个struct主要有两个作用:
第一,定义表达式和TOKEN的类型。表达式是什么呢?表达式其实就是单个或者多个TOKEN 的组合。第二就是储存变量,什么意思往后再说。
%type <some_type> expr: 这句话表示,*.y中的expr将在go代码中表示为xxSymType.some_type ,%token同理。
3、两个%%之间的部分就是我们的语法规则,这里我们定义一种表达式expression的匹配规则为只有一个HELLO作为TOKEN,然后在后边用打括号把这种表达式的行为用Golang写出来
4、第二个%%后面可以直接写Lexer,毕竟和%{ %}之间的内容一样,这部分的内容也会被复制到生成代码中去。但为了清楚起见,我们另起一个文件编写。
在*.y文件完成之后,我们需要执行goyacc命令,生成包含被称为Parser的代码:
goyacc -o hello.go -p hello hello.y
这句代码表示使用的y源文件为hello.y,生成的目标Parser代码为hello.go,而生成的SymType名字为helloSymType得到:
//line hello.y:2
package main
import __yyfmt__ "fmt"
//line hello.y:2
import "fmt"
//line hello.y:7
type helloSymType struct {
yys int
some_type string
}
const PRINT = 57346
const HELLO = 57347
var helloToknames = [...]string{
"$end",
"error",
"$unk",
"PRINT",
"HELLO",
}
var helloStatenames = [...]string{}
const helloEofCode = 1
const helloErrCode = 2
const helloInitialStackSize = 16
//line hello.y:21
//line yacctab:1
var helloExca = [...]int{
-1, 1,
1, -1,
-2, 0,
}
const helloPrivate = 57344
const helloLast = 2
var helloAct = [...]int{
2, 1,
}
var helloPact = [...]int{
-5, -1000, -1000,
}
var helloPgo = [...]int{
0, 1,
}
var helloR1 = [...]int{
0, 1,
}
var helloR2 = [...]int{
0, 1,
}
var helloChk = [...]int{
-1000, -1, 5,
}
var helloDef = [...]int{
0, -2, 1,
}
var helloTok1 = [...]int{
1,
}
var helloTok2 = [...]int{
2, 3, 4, 5,
}
var helloTok3 = [...]int{
0,
}
var helloErrorMessages = [...]struct {
state int
token int
msg string
}{}
//line yaccpar:1
/* parser for yacc output */
var (
helloDebug = 0
helloErrorVerbose = false
)
type helloLexer interface {
Lex(lval *helloSymType) int
Error(s string)
}
type helloParser interface {
Parse(helloLexer) int
Lookahead() int
}
type helloParserImpl struct {
lval helloSymType
stack [helloInitialStackSize]helloSymType
char int
}
func (p *helloParserImpl) Lookahead() int {
return p.char
}
func helloNewParser() helloParser {
return &helloParserImpl{}
}
const helloFlag = -1000
func helloTokname(c int) string {
if c >= 1 && c-1 < len(helloToknames) {
if helloToknames[c-1] != "" {
return helloToknames[c-1]
}
}
return __yyfmt__.Sprintf("tok-%v", c)
}
func helloStatname(s int) string {
if s >= 0 && s < len(helloStatenames) {
if helloStatenames[s] != "" {
return helloStatenames[s]
}
}
return __yyfmt__.Sprintf("state-%v", s)
}
func helloErrorMessage(state, lookAhead int) string {
const TOKSTART = 4
if !helloErrorVerbose {
return "syntax error"
}
for _, e := range helloErrorMessages {
if e.state == state && e.token == lookAhead {
return "syntax error: " + e.msg
}
}
res := "syntax error: unexpected " + helloTokname(lookAhead)
// To match Bison, suggest at most four expected tokens.
expected := make([]int, 0, 4)
// Look for shiftable tokens.
base := helloPact[state]
for tok := TOKSTART; tok-1 < len(helloToknames); tok++ {
if n := base + tok; n >= 0 && n < helloLast && helloChk[helloAct[n]] == tok {
if len(expected) == cap(expected) {
return res
}
expected = append(expected, tok)
}
}
if helloDef[state] == -2 {
i := 0
for helloExca[i] != -1 || helloExca[i+1] != state {
i += 2
}
// Look for tokens that we accept or reduce.
for i += 2; helloExca[i] >= 0; i += 2 {
tok := helloExca[i]
if tok < TOKSTART || helloExca[i+1] == 0 {
continue
}
if len(expected) == cap(expected) {
return res
}
expected = append(expected, tok)
}
// If the default action is to accept or reduce, give up.
if helloExca[i+1] != 0 {
return res
}
}
for i, tok := range expected {
if i == 0 {
res += ", expecting "
} else {
res += " or "
}
res += helloTokname(tok)
}
return res
}
func hellolex1(lex helloLexer, lval *helloSymType) (char, token int) {
token = 0
char = lex.Lex(lval)
if char <= 0 {
token = helloTok1[0]
goto out
}
if char < len(helloTok1) {
token = helloTok1[char]
goto out
}
if char >= helloPrivate {
if char < helloPrivate+len(helloTok2) {
token = helloTok2[char-helloPrivate]
goto out
}
}
for i := 0; i < len(helloTok3); i += 2 {
token = helloTok3[i+0]
if token == char {
token = helloTok3[i+1]
goto out
}
}
out:
if token == 0 {
token = helloTok2[1] /* unknown char */
}
if helloDebug >= 3 {
__yyfmt__.Printf("lex %s(%d)\n", helloTokname(token), uint(char))
}
return char, token
}
func helloParse(hellolex helloLexer) int {
return helloNewParser().Parse(hellolex)
}
func (hellorcvr *helloParserImpl) Parse(hellolex helloLexer) int {
var hellon int
var helloVAL helloSymType
var helloDollar []helloSymType
_ = helloDollar // silence set and not used
helloS := hellorcvr.stack[:]
Nerrs := 0 /* number of errors */
Errflag := 0 /* error recovery flag */
hellostate := 0
hellorcvr.char = -1
hellotoken := -1 // hellorcvr.char translated into internal numbering
defer func() {
// Make sure we report no lookahead when not parsing.
hellostate = -1
hellorcvr.char = -1
hellotoken = -1
}()
hellop := -1
goto hellostack
ret0:
return 0
ret1:
return 1
hellostack:
/* put a state and value onto the stack */
if helloDebug >= 4 {
__yyfmt__.Printf("char %v in %v\n", helloTokname(hellotoken), helloStatname(hellostate))
}
hellop++
if hellop >= len(helloS) {
nyys := make([]helloSymType, len(helloS)*2)
copy(nyys, helloS)
helloS = nyys
}
helloS[hellop] = helloVAL
helloS[hellop].yys = hellostate
hellonewstate:
hellon = helloPact[hellostate]
if hellon <= helloFlag {
goto hellodefault /* simple state */
}
if hellorcvr.char < 0 {
hellorcvr.char, hellotoken = hellolex1(hellolex, &hellorcvr.lval)
}
hellon += hellotoken
if hellon < 0 || hellon >= helloLast {
goto hellodefault
}
hellon = helloAct[hellon]
if helloChk[hellon] == hellotoken { /* valid shift */
hellorcvr.char = -1
hellotoken = -1
helloVAL = hellorcvr.lval
hellostate = hellon
if Errflag > 0 {
Errflag--
}
goto hellostack
}
hellodefault:
/* default state action */
hellon = helloDef[hellostate]
if hellon == -2 {
if hellorcvr.char < 0 {
hellorcvr.char, hellotoken = hellolex1(hellolex, &hellorcvr.lval)
}
/* look through exception table */
xi := 0
for {
if helloExca[xi+0] == -1 && helloExca[xi+1] == hellostate {
break
}
xi += 2
}
for xi += 2; ; xi += 2 {
hellon = helloExca[xi+0]
if hellon < 0 || hellon == hellotoken {
break
}
}
hellon = helloExca[xi+1]
if hellon < 0 {
goto ret0
}
}
if hellon == 0 {
/* error ... attempt to resume parsing */
switch Errflag {
case 0: /* brand new error */
hellolex.Error(helloErrorMessage(hellostate, hellotoken))
Nerrs++
if helloDebug >= 1 {
__yyfmt__.Printf("%s", helloStatname(hellostate))
__yyfmt__.Printf(" saw %s\n", helloTokname(hellotoken))
}
fallthrough
case 1, 2: /* incompletely recovered error ... try again */
Errflag = 3
/* find a state where "error" is a legal shift action */
for hellop >= 0 {
hellon = helloPact[helloS[hellop].yys] + helloErrCode
if hellon >= 0 && hellon < helloLast {
hellostate = helloAct[hellon] /* simulate a shift of "error" */
if helloChk[hellostate] == helloErrCode {
goto hellostack
}
}
/* the current p has no shift on "error", pop stack */
if helloDebug >= 2 {
__yyfmt__.Printf("error recovery pops state %d\n", helloS[hellop].yys)
}
hellop--
}
/* there is no state on the stack with an error shift ... abort */
goto ret1
case 3: /* no shift yet; clobber input char */
if helloDebug >= 2 {
__yyfmt__.Printf("error recovery discards %s\n", helloTokname(hellotoken))
}
if hellotoken == helloEofCode {
goto ret1
}
hellorcvr.char = -1
hellotoken = -1
goto hellonewstate /* try again in the same state */
}
}
/* reduction by production hellon */
if helloDebug >= 2 {
__yyfmt__.Printf("reduce %v in:\n\t%v\n", hellon, helloStatname(hellostate))
}
hellont := hellon
hellopt := hellop
_ = hellopt // guard against "declared and not used"
hellop -= helloR2[hellon]
// hellop is now the index of $0. Perform the default action. Iff the
// reduced production is ε, $1 is possibly out of range.
if hellop+1 >= len(helloS) {
nyys := make([]helloSymType, len(helloS)*2)
copy(nyys, helloS)
helloS = nyys
}
helloVAL = helloS[hellop+1]
/* consult goto table to find next state */
hellon = helloR1[hellon]
hellog := helloPgo[hellon]
helloj := hellog + helloS[hellop].yys + 1
if helloj >= helloLast {
hellostate = helloAct[hellog]
} else {
hellostate = helloAct[helloj]
if helloChk[hellostate] != -hellon {
hellostate = helloAct[hellog]
}
}
// dummy call; replaced with literal code
switch hellont {
case 1:
helloDollar = helloS[hellopt-1 : hellopt+1]
//line hello.y:17
{
//when meet something likes PRINT : VALUE
fmt.Println("Hello World!")
}
}
goto hellostack /* stack new state and value */
}
这里面我们只需要注意:
type helloLexer interface {
Lex(lval *helloSymType) int
Error(s string)
}我们需要自己手写一个helloLexer的实现。
首先看Error(s string),这个是我们输入的文本无法在y文件中找到对应的匹配的时候应该做啥,我们目前只需要打印出s信息就好。
然后是Lex(lval *helloSymType) int:
这个方法的作用是:对输入的一行命令执行逐字符扫描,每扫到一个TOKEN就返回这个TOKEN对应的值(这个值已经被goyacc自动生成了,常量名为y文件中定义的%token名,比如就是HELLO),直到完全go through完输入的文本。在我们的hello例子里面,我们会输入一个字符串:“HELLO”,Lexer依次会扫描到HELLO中的每个字母,直到扫描完“O”时,才返回HELLO对应的值。
这个是粗暴的实现:
//这个文件是lexer.go
/*
Created By wzj at 2020/10/21 下午8:19
*/
package main
import (
"fmt"
"time"
)
type myLexer struct {
//待解析指令暂时存input里面,用byte数组方便逐字符操作
input []byte
//当前扫描到字符的索引
index int
//存储已经扫描到的内容,当内容为hello时,返回HELLO
buffer string
}
func (m *myLexer) Lex(lval *helloSymType) int {
if len(m.input) == 0 {
return 0 //表示已经解析完所有的内容了
}
for i := 0; i < len(m.input); i++ {
char := m.input[i]
switch char {
case 'h', 'e', 'l', 'o':
m.buffer += string(char)
}
if m.buffer == "hello" {
return HELLO
}
}
return 0
}
func (m *myLexer) Error(s string) {
fmt.Println(s)
}
func main() {
//正确使用
helloParse(&myLexer{
input: []byte("hello"),
index: 0,
buffer: "",
})
time.Sleep(time.Second)
//未定义语法,会报错
helloParse(&myLexer{
input: []byte("hhhhhh"),
index: 0,
buffer: "",
})
}
最后执行:go run *.go
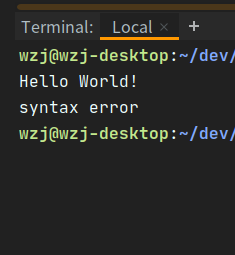
如果到这里已经成功了,那就可以开始进阶了:如何实现ZMoveTo:20?
进阶
先看:
%union {
expr string
cmd string
params string
needGo bool
}
%type <expr> expr
%type <params> expr1
%token ';' ':' '#' '-'
%token <cmd> PRINT ZMOVE
%token <params> PARAM VAL
%%
start:
{
}
| '#'
{
//COMMENT, DO NOTHING
}
| expr
{
fmt.Printf($1)
}
expr:
PRINT expr1
{
fmt.Printf($2)
}
| ZMOVE expr1
{
z, err := strconv.Atoi(strings.Trim($2, " "))
if err != nil {
panic(err)
}
ZMoveTo(z)
}
expr1:
':' PARAM
{
$$ = $2
}
这里定义了3个expr表达式:start,expr,expr1,它们的匹配优先级为:start最高,expr1最低。
一个表达式可能允许多种语法,比如能匹配start表达式的有三种情况:
1、我们啥也没有填,表示匹配到空字符串输入时,就行对应的大括号中的一样,啥也不做。
2、匹配到‘#’时,这被我们定义为注释了,也啥都不做。
3、然后就是expr了,而expr的定义又匹配另外两个表达式。。。以此类推。
如果我们要实现一个Print函数,则需要获取打印的值。我们看到最后的expr1的匹配行为:$$=$2,表示expr1对应的SymType中的值被赋值成了PARAM TOKEN所表示的值(第n个token就用$n表示)。所以在expr中,fmt.Printf($2)相当于打印了对应结构体中的params成员的值。
再看Lexer:
const eof = 0
type exprLex struct {
line []byte
pos int
st bool
}
func (x *exprLex) Lex(yylval *exprSymType) int {
var buff bytes.Buffer
if len(x.line) == 0 {
return eof
}
for {
c := x.next()
switch c {
case eof:
return eof
case ':':
x.st = true
return int(c)
case ';':
return int(c)
case '#':
x.pos = len(x.line)
return int(c)
case '-':
return int(c)
default:
buff.WriteRune(c)
if buff.String() == "Print" && x.peek() == ':' {
yylval.cmd = buff.String()
buff = bytes.Buffer{}
return PRINT
}else if buff.String() == "ZMoveTo" && x.peek() == ':' {
yylval.cmd = buff.String()
buff = bytes.Buffer{}
return ZMOVE
}else if buff.String() == "XMoveTo" && x.peek() == ':' {
yylval.cmd = buff.String()
buff = bytes.Buffer{}
return XMOVE
}else if buff.String() == "YMoveTo" && x.peek() == ':' {
yylval.cmd = buff.String()
buff = bytes.Buffer{}
return YMOVE
}else if buff.String() == "Sleep" && x.peek() == ':' {
yylval.cmd = buff.String()
buff = bytes.Buffer{}
return SLEEP
} else if x.peek() == ':' {
if yylval.cmd == "" {
panic("unknown command:" + buff.String())
}
}
yylval.params = buff.String()
if (x.peek() == eof || x.peek() == '#') && x.st {
return PARAM
}else if x.peek() == eof && !x.st {
return VAL
}
}
}
}
func (x *exprLex) next() rune {
if x.pos == len(x.line) {
return eof
}
defer func() {
x.pos++
}()
return rune(x.line[x.pos])
}
func (x *exprLex) peek() rune {
if x.pos == len(x.line) {
return eof
}
return rune(x.line[x.pos])
}
func (x *exprLex) Error(s string) {
fmt.Printf("error: %s\n", s)
}其关键在于,Lex扫描时,要根据已扫描内容并同时兼顾后面的内容。比如扫描到PRINT后,且下一个字符为':',我们才能承认它是一个PRINT TOKEN。
最后放出完整的代码:
expr.y:
%{
package main
import (
"fmt"
"strconv"
"strings"
)
%}
%union {
expr string
cmd string
params string
}
%type <expr> expr
%type <params> expr1
%token ';' ':' '#' '-'
%token <cmd> PRINT ZMOVE XMOVE YMOVE SLEEP
%token <params> PARAM VAL
%%
start:
{
}
| '#'
{
//COMMENT, DO NOTHING
}
| expr
{
fmt.Printf($1)
}
expr:
PRINT expr1
{
fmt.Printf($2)
}
| ZMOVE expr1
{
z, err := strconv.Atoi(strings.Trim($2, " "))
if err != nil {
panic(err)
}
ZMoveTo(z)
}
| '-' ZMOVE expr1
{
z, err := strconv.Atoi(strings.Trim($3, " "))
if err != nil {
panic(err)
}
fmt.Println("z go")
go ZMoveTo(z)
}
| XMOVE expr1
{
x, err := strconv.Atoi(strings.Trim($2, " "))
if err != nil {
panic(err)
}
XMoveTo(x)
}
| '-' XMOVE expr1
{
x, err := strconv.Atoi(strings.Trim($3, " "))
if err != nil {
panic(err)
}
fmt.Println("x go")
go XMoveTo(x)
}
| YMOVE expr1
{
y, err := strconv.Atoi(strings.Trim($2, " "))
if err != nil {
panic(err)
}
YMoveTo(y)
}
| '-' YMOVE expr1
{
y, err := strconv.Atoi(strings.Trim($3, " "))
if err != nil {
panic(err)
}
fmt.Println("y go")
go YMoveTo(y)
}
| SLEEP expr1
{
sec, err := strconv.Atoi($2)
if err != nil {
panic(err)
}
Sleep(sec)
}
expr1:
':' PARAM
{
$$ = $2
}
| ':' PARAM ';'
{
$$ = $2
}
| VAL
{
$$ = $1
}
| VAL ';'
{
$$ = $1
}
| ':' PARAM '#' VAL
{
$$ = $2
}
| ':' PARAM '#'
{
$$ = $2
}
%%
func.go:
/*
Created By wzj at 2020/9/23 下午5:22
*/
package main
import (
"fmt"
"time"
)
func ZMoveTo(z int) error {
fmt.Println("moving z to", z)
time.Sleep(time.Second)
return nil
}
func XMoveTo(x int) error {
fmt.Println("moving x to", x)
time.Sleep(time.Second)
return nil
}
func YMoveTo(y int) error {
fmt.Println("moving y to", y)
time.Sleep(time.Second)
return nil
}
func Sleep(sec int) {
time.Sleep(time.Duration(sec)*time.Second)
}lex.go:
package main
import (
"bufio"
"bytes"
"fmt"
"io"
"log"
"os"
"strings"
)
const eof = 0
type exprLex struct {
line []byte
pos int
st bool
}
func (x *exprLex) Lex(yylval *exprSymType) int {
var buff bytes.Buffer
if len(x.line) == 0 {
return eof
}
for {
c := x.next()
switch c {
case eof:
return eof
case ':':
x.st = true
return int(c)
case ';':
return int(c)
case '#':
x.pos = len(x.line)
return int(c)
case '-':
return int(c)
default:
buff.WriteRune(c)
if buff.String() == "Print" && x.peek() == ':' {
yylval.cmd = buff.String()
buff = bytes.Buffer{}
return PRINT
}else if buff.String() == "ZMoveTo" && x.peek() == ':' {
yylval.cmd = buff.String()
buff = bytes.Buffer{}
return ZMOVE
}else if buff.String() == "XMoveTo" && x.peek() == ':' {
yylval.cmd = buff.String()
buff = bytes.Buffer{}
return XMOVE
}else if buff.String() == "YMoveTo" && x.peek() == ':' {
yylval.cmd = buff.String()
buff = bytes.Buffer{}
return YMOVE
}else if buff.String() == "Sleep" && x.peek() == ':' {
yylval.cmd = buff.String()
buff = bytes.Buffer{}
return SLEEP
} else if x.peek() == ':' {
if yylval.cmd == "" {
panic("unknown command:" + buff.String())
}
}
yylval.params = buff.String()
if (x.peek() == eof || x.peek() == '#') && x.st {
return PARAM
}else if x.peek() == eof && !x.st {
return VAL
}
}
}
}
func (x *exprLex) next() rune {
if x.pos == len(x.line) {
return eof
}
defer func() {
x.pos++
}()
return rune(x.line[x.pos])
}
func (x *exprLex) peek() rune {
if x.pos == len(x.line) {
return eof
}
return rune(x.line[x.pos])
}
func (x *exprLex) Error(s string) {
fmt.Printf("error: %s\n", s)
}
func main() {
f, err := os.Open("./sample.sc")
if err != nil {
panic(err)
}
defer f.Close()
in := bufio.NewReader(f)
for {
line, err := in.ReadBytes('\n')
if err == io.EOF {
return
}
if err != nil {
log.Fatalf("ReadBytes: %s", err)
}
exprParse(&exprLex{line: []byte(strings.Replace(string(line), "\n", "", -1))})
}
}
sample.sc:
#this is a comment line
ZMoveTo:0
-XMoveTo:30
-YMoveTo:20
Sleep:1#unit:s
-ZMoveTo:40
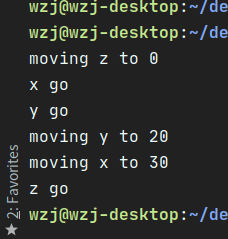
使用验证:
goyacc -o expr.go -p expr expr.y
go run *.go

















 4061
4061

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









