




一、概述
布隆过滤器(Bloom Filter)主要用来检索一个元素是否在一个集合中。它是一种数据结构bitMap,优点是高效的插入和查询,而且非常节省空间。缺点是存在误判率和删除困难。
二、应用场景
1、避免缓存穿透,当redis做缓存,没有命中会查询数据库,若量很大,流量打在数据库,会造成压力。若缓存空值避免穿透,量大需要缓存大量的key,若空值过期,造成不一致情况,故不推荐。另外一种用hashMap存储,但是key值量大,会占用内存飙升,也不建议。推荐使用 Bloom Filter,节省空间,也是当前主流做法
2、判断用户是否是刷单用户,是否在黑名单池内。如1一亿 个垃圾 email ,5kw+黑名单池。存数据库耗空间,查询速度慢且高频查询。哈希表查询效率O(1),哈希表的做法:首先,哈希函数将一个email地址映射成8字节信息指纹;考虑到哈希表存储效率通常小于50%(哈希冲突);因此消耗的内存:8 * 2 * 1亿 字节 = 1.6G 内存。非常大,故布隆过滤器(Bloom Filter)就解决此类问题
3、RocketMQ通过布隆过滤器防止消息重复消费:防止RocketMQ消息重复消费,我们发送消息时可以对每个消息设置唯一的key,然后在消费者处利用布隆过滤器对消息的key检索,如果存在则说明消息已经消费过,不消费。不存在则进行消费,然后插入布隆过滤器
二、布隆过滤器Bloom Filter原理和数据结构
数据结构:
布隆过滤器是由很长的二进制向量(即可以理解成很长的0、1数组)与一系列随机映射函数(Hash函数)构成。BloomFilter 是由一个固定大小的二进制向量或者位图(bitmap)和一系列映射函数组成的。在初始状态时,对于长度为 m 的位数组,它的所有位都被置为0。因此我们可以将布隆过滤器理解成下图这种很长的一个二进制数组:
优点:布隆过滤器的数据结构仅需要存储“0”或“1”,因此所占用内存极少
检索和插入原理:
1、Hash函数:把输入值通过特定方式(hash函数) 处理后 生成一个值,这个值等同于存放数据的地址
2、插入(增加)数据的原理:Hash函数是 y=x²&(len-1),这里y是指最终在布隆过滤器的数据结构(二进制数组)中存放的下标位置,x指我们传入的值,len指数组的长度。那么如果当数组长度为100(举个例子,实际上数组长度是很长的),传入的值为5,则我们通过Hash函数得到的下标为25。那么此时我们便将下标25的值从0标为1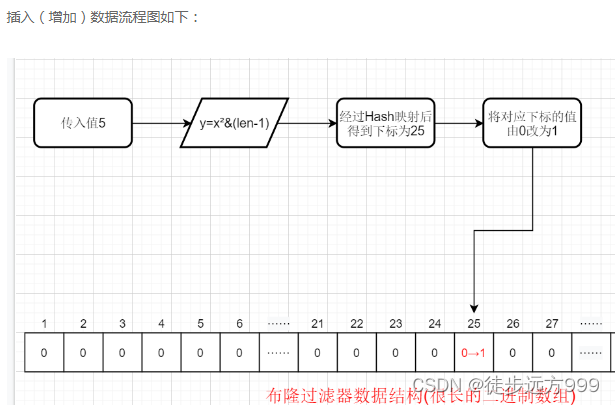
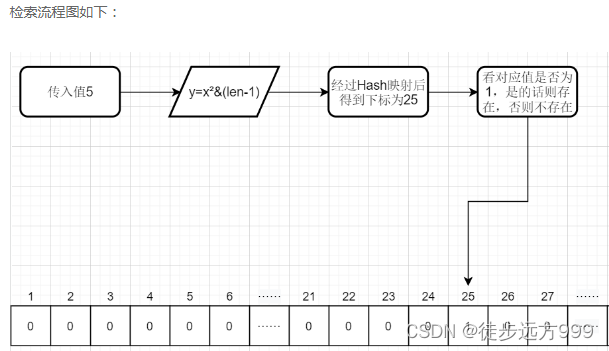
3、检索原理:当我们下次再输入这个值的时候,我们会得到当前数组对应下标的值为1,说明我们有这个数字
误判原理:
Hash函数F(key)得到的结果的作为地址去存放当前的value值,但是却发现算出来的地址上已经被占用了,这就是所谓的hash冲突
在经过上述流程后,我们数组下标为25的值是1。此时我们传入一个值25,那么通过我们上述举例的Hash算法计算后得到的数组下标值也为25,那么此时布隆过滤器是不是就会认为值25是存在的!但是实际上是因为5和25经过Hash映射后得到同一个地址,导致了误判!
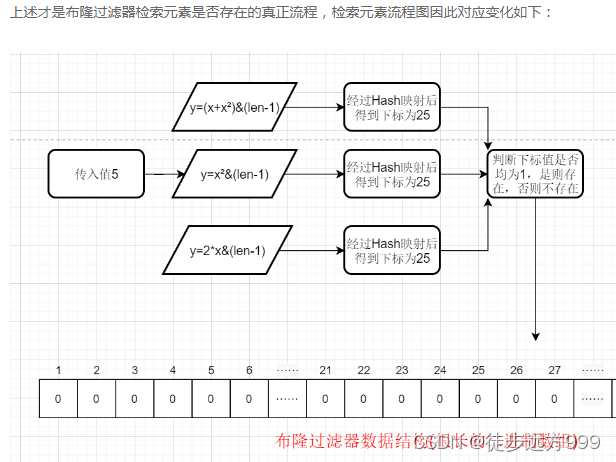
在真实的判断流程中,当然不止一个函数来判断,是一系列函数。 来判断是否在某个集合中。
检索流程变为:将key值传入一系列Hash函数得到对应的一系列数组地址(索引下标),注意这里一般来说有几个Hash函数就会得到几个地址,然后去判断这几个索引下标对应的值是否均为1,是的话则说明存在,否则不存在。
误判率:
布隆过滤器会有一定误判率。当一个不存在的元素,对应的一系列映射后的地址的值为1,即出现误判
布隆过滤器参数:
布隆过滤器的时候能通过设置两个参数:①预期数据量 ②误判率期望值。我们可以通过设置“误判率期望值”来达到我们能接受的误判率
三、布隆过滤器代码实现
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-spring-boot-starter</artifactId>
<version>3.13.6</version>
</dependency>
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-spring-data-21</artifactId>
<version>3.13.6</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.14.4</version>
</dependency>
import lombok.Data;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Configuration;
/**
* @ClassName: RedisConfig
* @Description:
* @Author: Admin 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 8423
8423

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









