






分享爬取Matlab中文论坛基础讨论的源代码
学习Matlab的过程中,中文论坛是一个很不错的地方
为了方便搜索、查看论坛,很有必要把感兴趣的版块给爬取下来
当然爬取中文论坛可以做为一次爬虫练习,从中能体验到具体的过程:
- 网页请求
- 正则表达式匹配期望得到的数据
- 结果保存
Matlab基础讨论版块的请求地址是:https://www.ilovematlab.cn/forum.php?mod=forumdisplay&fid=6&typeid=606&typeid=606&filter=typeid&page=
其中参数page的值为当前网页的页码,截止目前,这一板块已经有了506页的问答信息了

整体思路是用google浏览器打开网页后,按F12进行网页分析后就可以爬取我们需要的数据了。

下面是整个源代码:
clear
clc
PageNum = 100;
titleInfo = {'主题', '地址', '回复人数', '阅读人数'};
allInfo.data = [];
options = weboptions('Timeout', 20);
options.UserAgent = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36';
tic
for ii = 1 : PageNum
url = ['https://www.ilovematlab.cn/forum.php?mod=forumdisplay&fid=6&typeid=606&typeid=606&filter=typeid&page=', num2str(ii)];
htmlContent = webread(url, options);
% The url of theam
theamUrl = regexp(htmlContent, '(?<=</font></a>]</em> <a href=").*?(?="\s)', 'match');
theamUrl = strrep(theamUrl, 'amp;', '')';
theamUrl = regexprep(theamUrl, 'forum', 'https://www.ilovematlab.cn/forum');
% The title of theam
theamTitle = (regexp(htmlContent, '(?<=class="s xst">).*?(?=</a>)', 'match'))';
% The number of read
theamReadNum = (regexp(htmlContent, '(?<=</a><em>)\d+(?=</em></td>)', 'match'))';
% The number of request
theamRequestNum = (regexp(htmlContent, '(?<=class="xi2">)\d+(?=</a><em>)', 'match'))';
theamContent = [theamTitle, theamUrl, theamRequestNum, theamReadNum];
clear theamTitle theamUrl theamRequestNum theamReadNum
allInfo.data = [allInfo.data; theamContent];
disp(['正在爬取第', num2str(ii), '页'])
end
if ~exist('result', 'dir')
mkdir('result');
end
% sort info with the number of read
[~, indx] = sort(str2double(allInfo.data(:, 4)), 'descend');
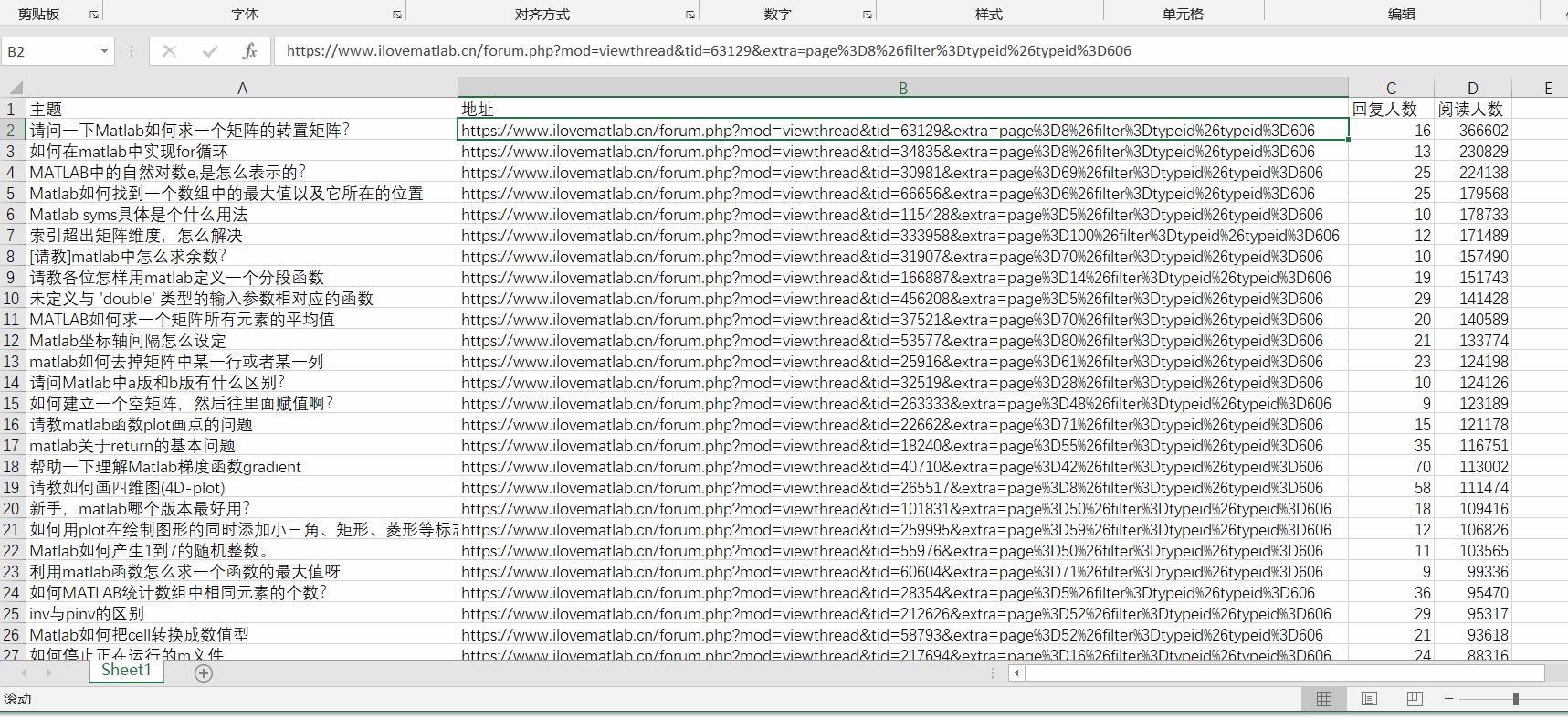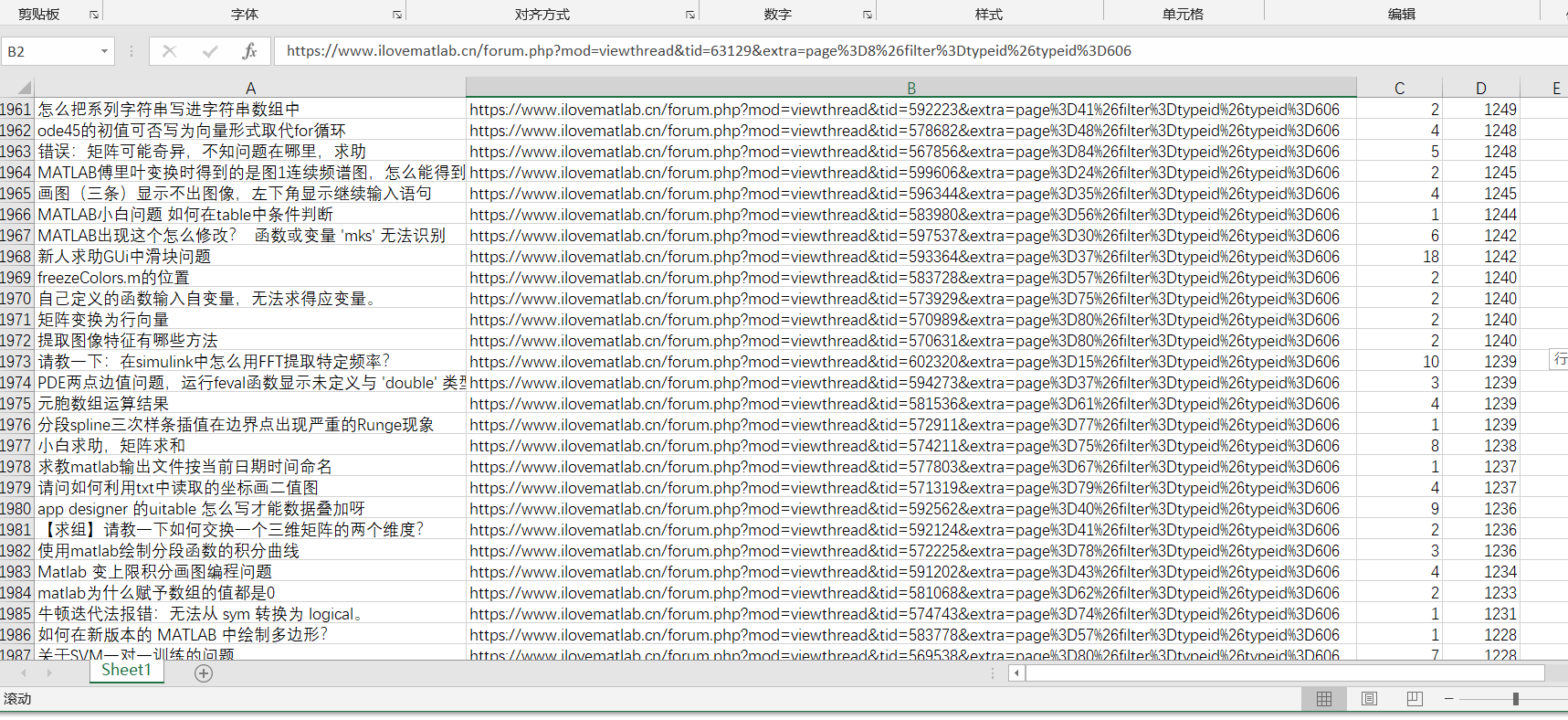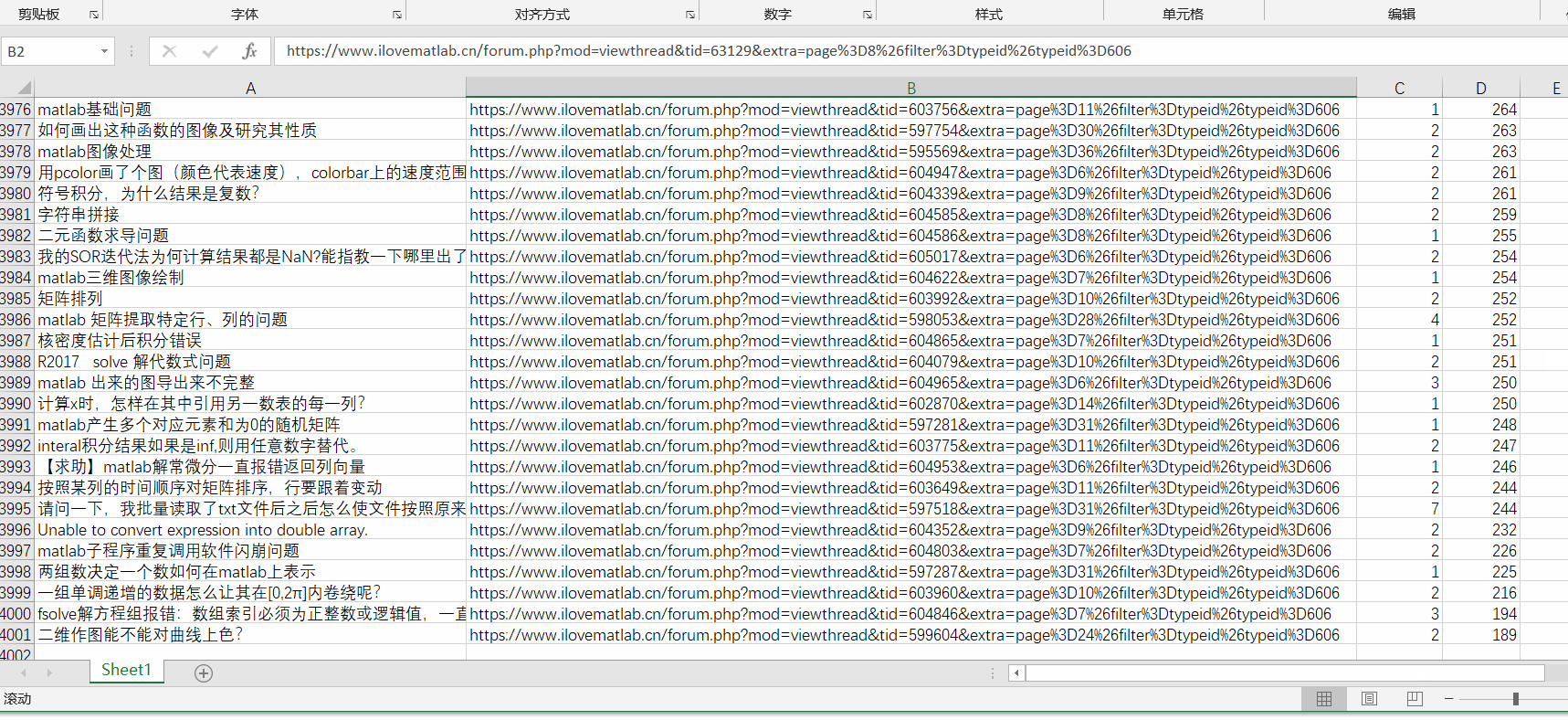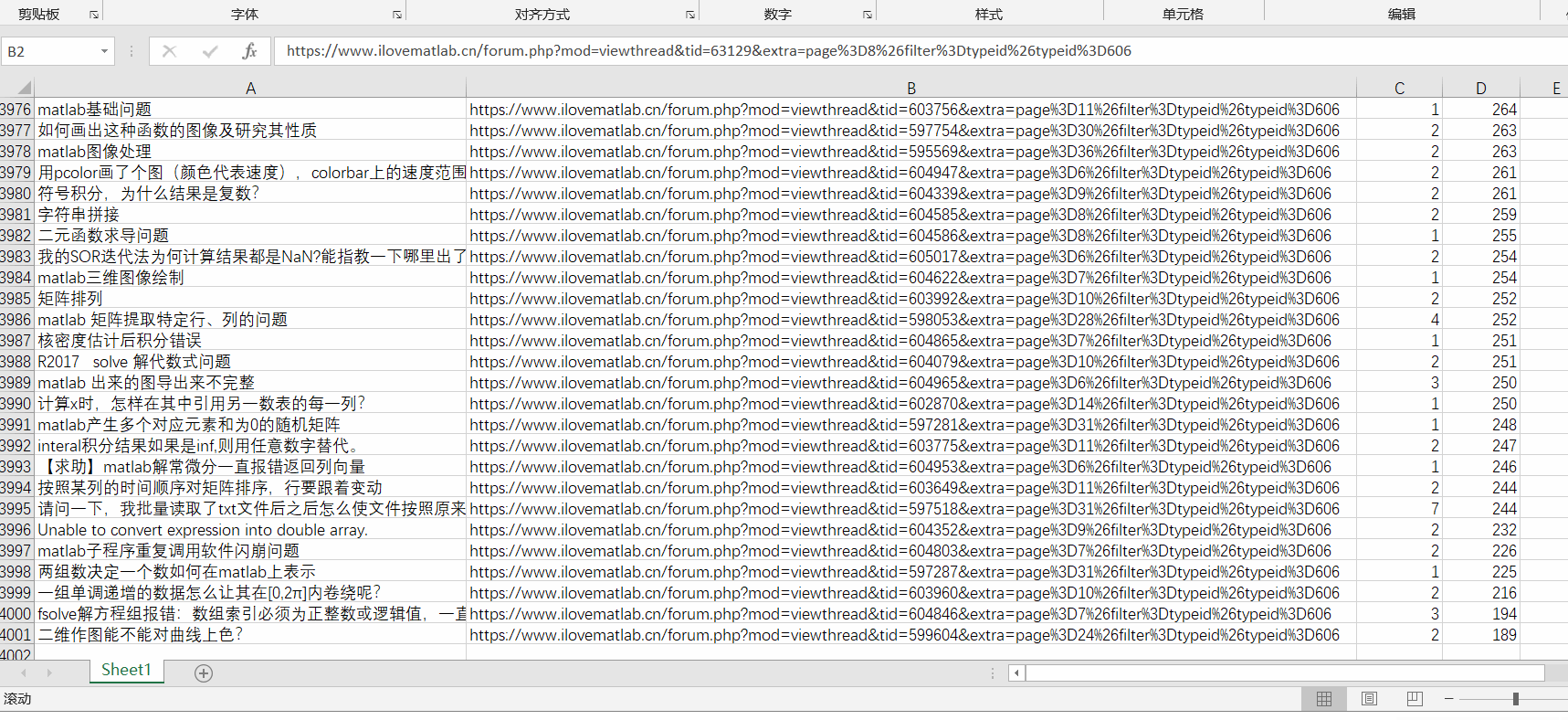
xlswrite('result/matlabForumSolveProblem.xls', [titleInfo; allInfo.data(indx, :)]);
toc
为了方便演示,这里只爬取了前100页的数据
今天的分享就到这里了,感兴趣的朋友们可以对源代码进行优化,以更快的方法爬取,祝好!















 1518
1518











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









