







5. 格式化I/O
5.1 printf的三种形式
函数printf具有三种不同的形式:

函数printf通常将输出直接写入标准输出。
函数fprintf与printf基本相同,只是以一个FILE指针作为第一个参数,并将其输出写入该文件。
而函数sprintf则以一个字符数组作为第一个参数,并将printf调用要显示的字符写入该数组。函数sprintf的调用函数应确保数组空间足够大以容纳输出数据。
除输出的目的地不同外,三种形式的printf的工作方式是相同的:
它们将control string中的内容逐字符地复制到指定的目的地。
如果该字符串中包含一个百分号(%),则该字符标志着格式码的开始,由函数printf中下一个参数中的字符串代替。
输出的格式由格式码末尾的字母决定,它包括指明字段宽度、精度和对齐方式的修饰符。
5.2 scanf函数
与printf函数相对应,scanf函数使程序轻松读入不同基本类型的值。
由于C语言的规则以及输出方向的不同转换,printf和scanf有着很多不对称的地方,这使它们的用法变得易混淆。
scanf和printf最重要的不对称性在于,printf需要从其调用函数处获得多个值,而scanf则要将多个值返回给它的调用函数。但C语言并不能很好地支持返回多个值的操作,因为这需要频繁地使用指针。
和printf一样, scanf也有三种不同的形式:

第一种形式从标准输入中读取数据,
第二种形式从由输入流参数指定的FILE指针处读入,
第三种形式从指定的字符串中读入。
三种形式都从某个来源读入字符,并按照控制字符串中指明的方式进行转化。数据值则存入由调用函数通过额外的参数指定的内存中。
控制字符串后的每个参数都应该是一个指针。
在大多数情况下,可以在变量名前用一个取址运算符(&)来将变量转化为它的地址,但必须注意字符数组的数组名已经是一个指针了,因为无需再对它进行取址操作。
scanf的控制字符串由三类字符组成:
-
作为空格出现的字符。
scanf通常跳过空白字符去读下一个非空白的字符。这样的字符在C语言中被称为空白字符(white-space character),ctype.h中的谓词函数isspace遇到这些字符时返回TRUE。最常见的空白符主要有空格字符、制表符和换行符。在
scanf的控制字符串中,空格的数量与输入中空格的数量相同。 -
百分号以及跟在其后的转换说明。
-
其他字符,这些字符必须与输入中的下一个字符相匹配。这使得程序能够检查所需的标点符号,如两个数字之间的逗号等。
常见错误:
scanf在控制字符串后的每个参数都必须是一个指针。
对于简单变量来说,前面的&表明取的是它的地址。但如果该参数是一个字符数组,则该变量的名称已经自动解释为指针,因此无需再使用&。
scanf的转换说明由以下的几种选项组成,必须遵循下面的顺序:
-
由星号(*)表示的赋值屏蔽标志,该标志表明不将输入流中的值读入参数指定的地方。
-
一个可选的数字字段宽度,指出该字段可以读入的最大的字符个数。
-
大小的说明,
h表示short类型的整数值,l表示long类型的整数或double类型的浮点数。 -
转换说明符,通常为表15-1中所示的某一种说明符。

scanf的三种形式都会返回成功转换后的数据,而忽略由*号屏蔽掉的数据。如果在转换之前读到文件结束标志,则scanf返回EOF。
5.3 用scanf读入字符串
表15-1中包含了几个用于读入字符串的转换符——%s、%[…]和%[^…]。
使用这几个转换说明时,调用程序必须负责分配足够的空间来存放数据。
因此,scanf中用来存放字符串的参数应该为调用程序声明的一个数组。
例如,为了读入一个由空白字符界定的字符串,必须事先声明一个数组来存放字符串,声明如下:
#define MaxLine 25
char word[MaxLine];
一旦获得用于存放结果的空间,程序就可以通过下面的语句读入字符串了:
fprintf(infile, "%s", word);
要注意, 在变量名的前面没有&字符。函数fscanf要求它的所有参数都为指向存储空间的指针。而数组名已经是一个指向第一个元素的指针了,因此不必使用&运算符。
为了阻止缓冲区溢出,可以指定一个字段宽度,表示要读入的最大字符数:
fprintf(infile, "%24s", word);
这个函数调用仅将最开始的24个字符存入数组,这样就可以保证不占用数组之外的其他空间。
由于MaxWord定义为25, 因此数组中仍有空间写人’\0以表示字符串结束°。
在读入具有特定格式的输入时,转换选项%[…]和%[^…]特别有用。
例如,为了读入具有下列格式的信息:
name: value
其中,name为一个字符串,而value为一个整型值,就可以按照下面的代码调用fscanf:
fscanf(infile, "%[^:]: %d", name, &value);
遗憾的是,不能重复使用该语句以同一种形式读入多行数据。
问题在于,当程序读入与value相对应的整型值后,表示数据结束的换行符仍然留在输入流中,并将被作为下一个字被读入。
像下面代码所示的那样在控制字符串的最后增加一个换行符:
fscanf(infile, "%[^:]: %d\n", name, &value);
通常可以解决此问题,但并没有达到我们的要求。
包含一个换行字符不要求fscanf的输入流中有相匹配的换行符。相反,换行符被看作一个空白字符,使scanf跳过输入流中的任何空白字符。
如果假设换行符总是紧跟在数字后面,那么一切正常。
另一方面,如果希望程序能够检测出格式不正确的输入文件,则需要用其他的方法。
一种比较安全的方法是在调用fscanf时读人一个额外的字符,并检测它,确保它是一个换行符,如下面的循环所示:
while (TRUE) {
nscan = fscanf(infile, "%[^:] %d%c", name, &value, &termch);
if (nscan == EOF) break;
if ((nscan != 3) || (termch != '\n')) Error("Bad input line");
}
当使用这种方法时,程序同样也保证了fscanf正好读入了三个项目:名称、值以及终止字符。
如果需要知道在出现错误时已读人多少文件内容,最好用fgets读入一个完整行,然后调用sscanf函数转换结果字符串中的字段,如下所示:
while (fgets(line, MaxLine, infile) != NULL) {
nscan = sscanf(line, "%[^:] %d%c", name, &value, &termch);
if (nscan == EOF) break;
if ((nscan != 3) || (termch != '\n')) Error("Bad input line");
}
5.4 格式化I/O的一个实例
假设需要从文件elements.dat中读入数据,该文件为每一个化学元素列出下列信息:
- 元素名称,通常不超过15个字符。
- 化学符号,通常不超过2个字符。
- 原子序号,表示原子核中质子数的一个整数。
- 原子量,一个浮点数(用来表示该元素的各同位素的平均质量)。
文件的前十行如下所示:

假设现在要从上面的文件中读取数据,并以下列表格形式输出:
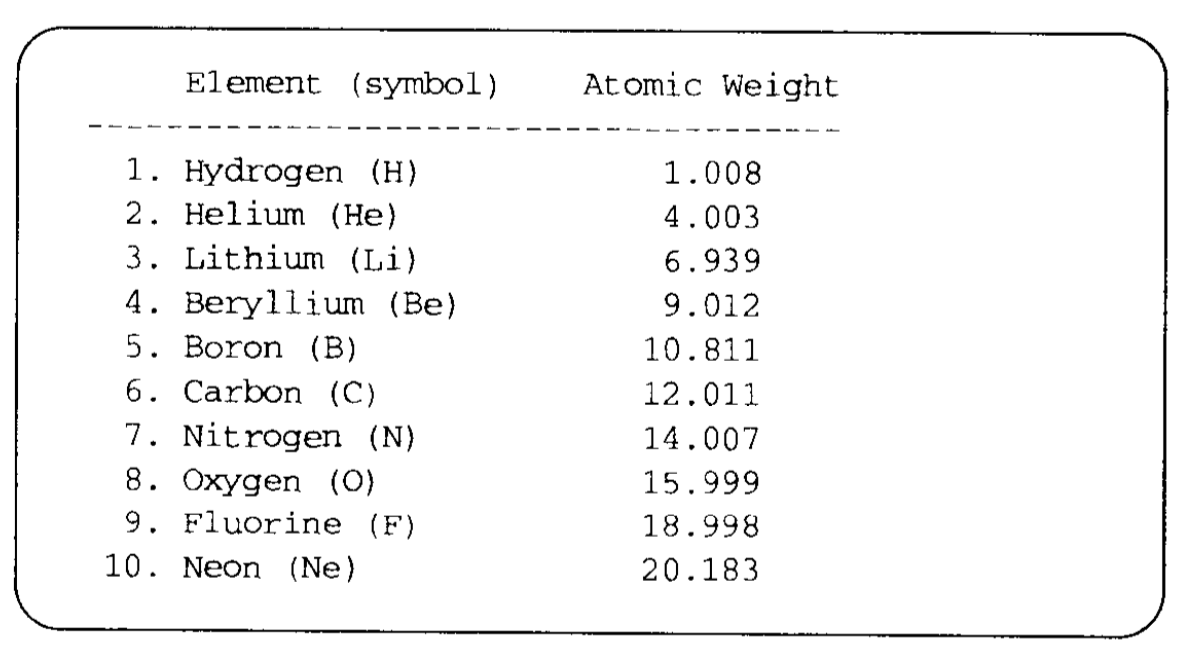
在输出中,首先出现原子序号,然后是元素名称、化学符号,这两个内容显示在一个固定宽度的字段中,最后是原子量。
第一步是为fscanf设计一个控制字符串,以便正确地从文件中读入一行。
输入行由元素名称开始,元素名称是用逗号标志结束的字符串。最简单的方法是利用转换符号%15[^,]来读入第一个逗号前出现的字符。字段宽度为15保证了elementName的缓冲区不溢出。
控制字符串中在此转换符后应该跟一个逗号,与输入流中的内容相对应,此后为一个空格,用来跳过逗号后面的所有空格。
化学符号通过转换说明%2[^,]来读入,只是字段宽度较小。
最后两个字段分别为int和double型的数值。为读入这些内容,控制字符串中还应包括转换说明号d和号lf。
在行结束处 需要将原子量后面的字符也读入,并确保其为一个换行符。
因此,完整的fscanf应如下所示:
nscan = fscanf(infile, "%15[^,], %2[^], %d, %lf%c", elementName, elementSymbol, &atomicNumber, &atomicweight, &termch);
fscanf中的前两个变量为字符数组,已经被视为地址。
而变量atomicNumber、weight和termch变量都不是数组,因此需要在它们前面加上&来进行取址操作。
格式化I/O函数在生成输出表时也很有用。
表中元素名称和它相对应的化学符号显示在一个字段内。
而为了使原子量一栏能够精确地对齐,就需要确保名称和符号字段有固定的宽度。
这可以通过使用函数strlen计算每一个字符串的长度, 然后将其写入合适的空间。
或者可以用sprintf将两段合并为一个字符串,然后通过printf中的标准字段宽度生成正确的输出。
具体代码实现如下:
#include <stdio.h>
#include <stdbool.h>
#include <ctype.h>
#include "strlib.h"
#include "string.h"
#include "simpio.h"
#define ElementsFile "elements.dat"
#define MaxElementName 15
#define MaxSymbolName 2
/* Main Program */
main() {
FILE *infile;
char elementName[MaxElementName+1];
char elementSymbol[MaxSymbolName+1];
char namebuf[MaxElementName+MaxSymbolName+4];
int atomicNumber;
double atomicWeight;
char termch;
int nscan;
infile = fopen(ElementsFile, "r");
if (infile == NULL) printf("Can't open %s", ElementsFile);
printf(" Element (symbol) Atomic weight\n");
printf("-------------------------------------\n");
while (TRUE) {
nscan = fscanf(infile, "%15[^,], %2[^], %d, %lf%c", elementName, elementSymbol, &atomicNumber, &atomicWeight, &termch);
if (nscan == EOF) break;
if ((nscan != 5) || (termch != '\n')) printf("Improper file format");
sprintf(namebuf, "%s (%s)", elementName, elementSymbol);
printf("%3d. %-2-s %8.3f\n", atomicNumber, namebuf, atomicWeight);
}
}
- nscan运行等于0?
5.5 使用scanf的局限
scanf的优势在于为读取固定格式的输入提供了一个简便的方法。
通常只要确定一个正确的转换说明,就可通过调用一个函数来读取很多数据项。
特别是需要编写测试应用的代码并且读入一些测试数据时,不失为一个很好的工具。
但是,scanf函数往往对于无法控制来源的输入流束手无策。
如果输入数据中可能存在错误,程序就必须测试这些输人数据,确保它具有正确的格式。但是,使用scanf时通常不可能彻底检查输入数据。
参考
《C语言的科学和艺术》 —— 15 文件















 755
755











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









