







1. 内存的物理机制很简单
内存实际上是一种名为内存IC的电子元件。
内存IC中有电源、地址信号,数据信号、控制信号等用于输入输出的大量引脚(IC的引脚),通过为其指定地址(address),来进行数据的读写。
图4-1是内存IC(在这里假设它为RAM)的引脚配置示例。
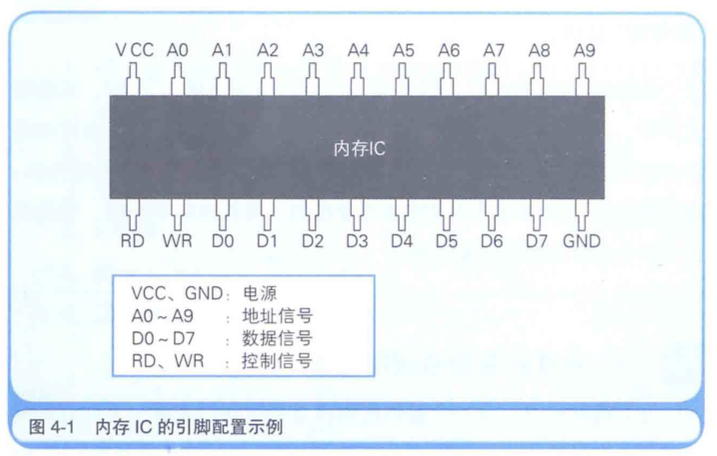
虽然这是一个虚拟的内存IC,但它的引脚和实际的内存IC是一样的。
VCC和GND是电源,A0~A9是地址信号的引脚,D0~D7是数据信号的引脚,RD和WR是控制信号的引脚。
将电源连接到VCC和GND后,就可以给其他引脚传递比如0或者1这样的信号。
大多数情况下,+5V的直流电压表示1,0V表示0。
数据信号引脚有DO~D7共八个,表示一次可以输入输出8位(=1字节)的数据。
此外,地址信号引脚有A0~A9共十个,表示可以指定0000000000-1111111111共1024个地址。
而地址用来表示数据的存储场所,因此这个内存IC中可以存储1024个1字节的数据。
因为1024=1K,所以该内存IC的容量就是1KB。
通常情况下,计算机使用的内存IC中会有更多的地址信号引脚,这样就能在一个内存IC中存储数十兆字节的数据。
刚才所说的1KB的内存IC,首先,假设要往该内存IC中写入1字节的数据。
为了实现该目的,可以给VCC接入+5V,给GND接入0V的电源,并使用A0~A9的地址信号来指定数据的存储场所,然后再把数据的值输入给D0~D7的数据信号,井把WR(wite-写入的简写)信号设定成1。
读出数据时,只需通过A0~A9的地址信号指定数据的存储场所,然后再将RD(read=读出的简写)信号设成1即可。
执行完这些操作,指定地址中存储的数据就会被箱出到DO~D7的数据信号引脚中。
另外,像WR和RD这样可以让IC运行的信号称为控制信号。其中,当WR和RD同时为0时,写入和读出的操作都无法进行。
2. 内存的逻辑模型是楼房
内存为1KB时,表示的是如图4-3所示的有1024层的楼房(这里地址的值是从上往下逐渐变大,不过也有与此相反的情况)。

编程语言中的数据类型表示存储的是何种类型的数据。从内存来看,就是占用的内存大小(占有的楼层数)的意思。
下面来看一个具体的示例。如代码清单4-1所示,这是一个往a、b、c这3个变量中写入数据123的C语言程序。

这3个变量表示的是内存的特定区域。通过使用变量,即便不指定物理地址,也可以在程序中对内存进行读写。
这是因为,在程序运行时,Windows等操作系统会自动决定变量的物理地址。
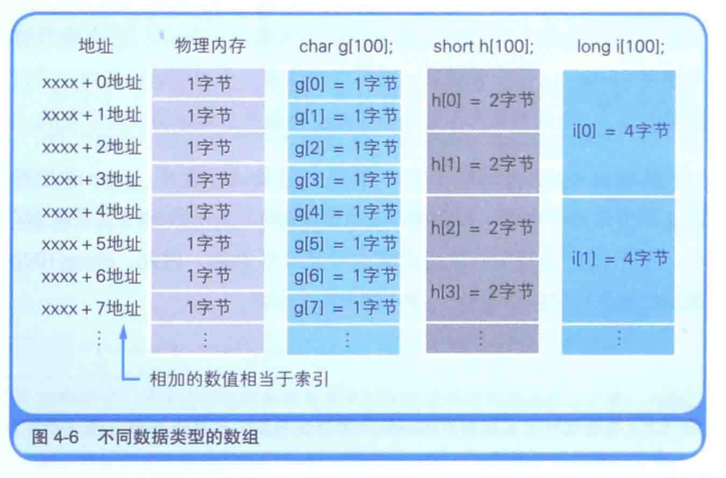
这3个变量的数据类型分别是,表示1字节长度的char,表示2字节长度的short,以及表示4字节长度的long。
因此,虽然同样是数据123,存储时其所古用的内存大小是不一样的。
这里,假定采用的是将数据低位存储在内存低位地址的低字节序(little endian)方式(图4-4)。

根据程序中所指定的变量的数据类型的不同,读写的物理内存大小也会随之发生变化。
在不同的编程语言中,变量可以指定的数据类型的最大长度也不相同。
C语言中,8字节(=64位)的double类型是最大的。
3. 简单的指针
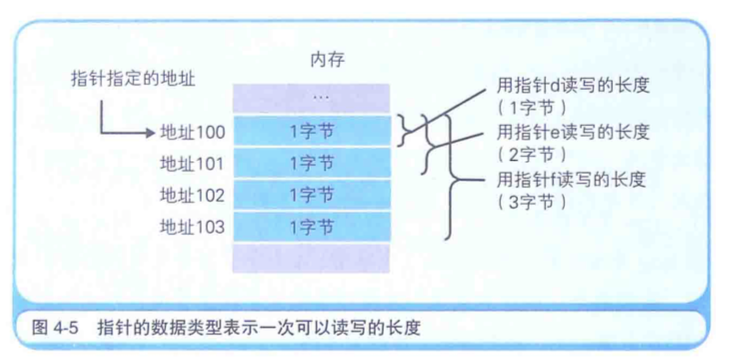
指针也是一种变量,它所表示的不是数据的值,而是存储着数据的内存的地址。
通过使用指针,就可以对任意指定地址的数据进行读写。
大家在Windows计算机上使用的程序通常都是32位(4字节)的内存地址。
这种情况下,指针变量的长度也是32位。
代码清单4-2,是定义了d、e、f这3个指针变量的C语言程序。

d、e、f都是用来存储32位(4字节) 的地址的变量。
指定char(1字节)、short(2字节)、long(4字节) 这些数据类型,表示的是从指针存储的地址中一次能够读写的数据字节数。
4. 数组是高效使用内存的基础
数组是指多个同样数据类型的数据在内存中连续排列的形式。
作为数组元素的各个数据会通过连续的编号被区分开来,这个编号称为索引(index)。
指定索引后,就可以对该索引所对应地址的内存进行读写操作而索引和内存地址的变换工作则是由编译器自动实现的。
数组的定义中所指定的数据类型,也表示一次能够读写的内存大小。
之所以说数组是内存的使用方法的基础,是因为数组和内存的物理构造是一样的。
可以指定任意数据类型来定义数组。这和将1层=1单元的楼房改造成多个楼层=1单元的楼房是同一个道理(图4-6)。
5. 栈、队列以及环形缓冲区
栈和队列,都可以不通过指定地址和索引来对数组的元素进行读写。
需要临时保存计算过程中的数据、连接在计算机上的设备或者输入输出的数据时,都可以通过这些方法来使用内存。
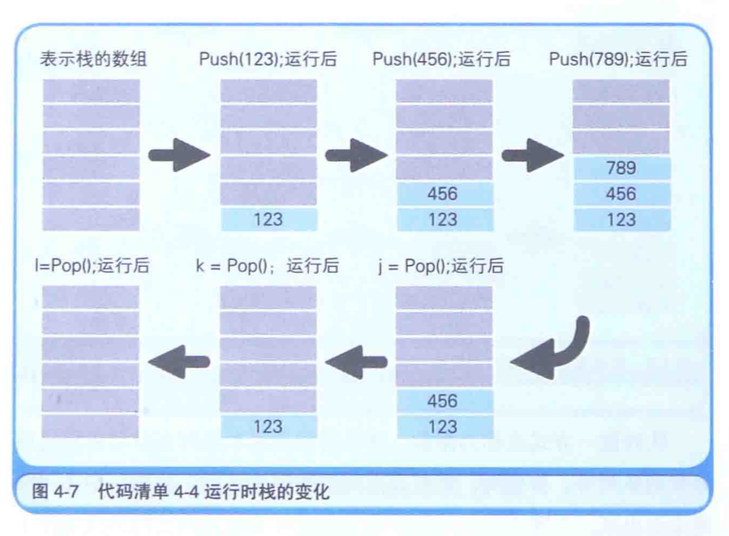
栈和队列的区别在于数据出入的顺序是不同的。
在对内存数据进行读写时,栈用的是LIFO(Last Input First Out,后入先出)方式,而队列用的赠是FIFO(Fist Input Fint Out,先入先出)方式。
如果要在程序中实现栈和队列,就需要以适当的元素数来定义一个用来存储数据的数组,以及对该数组进行读写的函数对。
暂且把往中写入数据的函数命名为Push,把从栈中读出数据的函数命名为Pop,把往队列中写入数据的函数命名为
EnQueue,把从队列中读出数据的函数命名为DeQueue。
Puh和EnQueue用于为函数的参数传递要写入的数据。Pop和DeQueue用于将读出的数据作为函数返回值返回。
通过使用这些函数,可以将数据临时保存(写入),然后再在需要时候把这些数据读出来(代码清单4-4、代码清单4-5)。

栈及队列是如何使用内存的?
在栈中,LIFO方式表示栈的数组中所保存的最后面的数据(Last in)会被最先读取出来(First Out)。
与栈相对的是队列,顾名思义,FIFO方式表示队列的数组中所保存的最初数据(First Input)会最先被读取出来(First Out)。
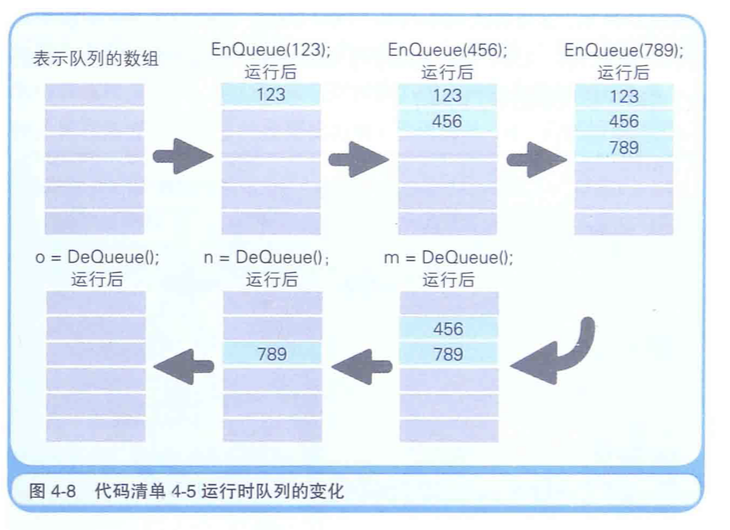
队列一般是以环状缓冲区(ring buffer)的方式来实现的。
假设我们要用有6个元素的数来实现一个队列。
这时可以从数组的起始位置开始有序地存储数据,然后再拉照存储时的顺序把数据读出。
在数组的末尾写入数据后,后一个数据就会被写入数组的起始位置(此时数据已经被读出所以该位置是空的),这样,数组的末尾就和开头连接了起来,数据的写入和读出也就循环起来了(图4.9)。
6. 链表使元素的追加和删除更容易
在数组的各个元素中,除了数据的值之外,通过为其附带上下一个元素的索引,即可实现链表。
数据的值和下一个元素的索引组合在一起,就构成了数组的一个元素。这样,数组元素相连就构成了念珠似的链表。
由于链表末尾的元素没有后续的数据,因此就需要用别的值(在这里是-1)来填充(图4-10)。

在需要追加或删 除数据的情况下,使用链表是很高效的。
在图4-10表示的链表中,假设要利除从起始位置开始的第3个元素。
此时,只需要把第2个元素的“下一个元素:2"变成“下一个元素:3“即可。
当第2个元素的下一个元素变成第4个元素后,那么第3个元素就被删除了。
虽然第3个元素在物理内存上还残留着,但在逻辑上则确实被删除了。
假设要在图4-10的链表的第5位前追加一个新数据。
此时,只需要在刚才消除的第3个元素的位置中保存新的数据,并将第4个元素的“下一个元素:5”变成“下一个元素:2”,以使新追加的元素的索引信息变成“下一个元素:5”即可。
虽然新追加的元素在物理上是第3个,但从逻辑上看来则是第5个。
7. 二叉查找树使数据搜索更有效
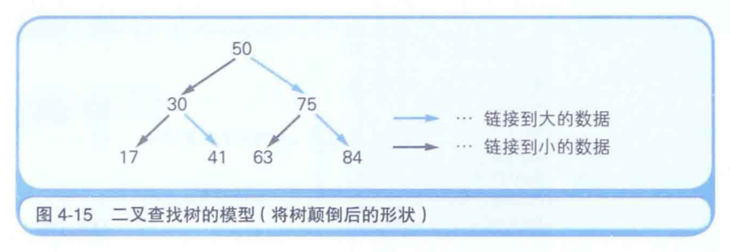
二叉查找树是指在链表的基础上往数组中追加元素时,考虑到数据的大小关系,将其分成左右两个方向的表现形式。
例如,假设我们事先把50这个值保存到了数组中。那么,如果接下来的值比先前保存的数值大的话,就要将其放到右边,反之如果小的话就放在左边。
但实际的内存并不会分成两个方向,这是在程序逻辑上实现的(图4-15)。
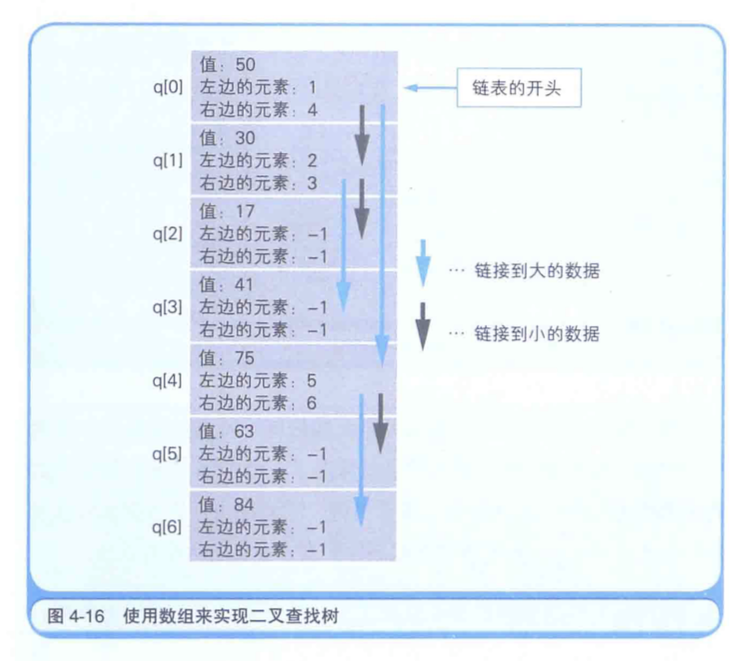
为了实现二又查找树,数组的每个元素中只要有数据的值和两个索引信息就可以了。
图4-16向我们展示了如何用数组来实现图4-14中的二义查找树。
二叉查找树是由链表构造发展面来的表现形式,因此在追加或除元素方面也同样是有效的。
使用二叉查找树的便利之处在于可以使数据的搜索等更有效率。
参考
《程序是怎样跑起来的》 —— 4. 熟练使用有棱有角的内存















 2810
2810











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









