







Python爬虫技术系列-06requests完成yz网数据采集V01
1.yz网数据爬取概述
药智网在医药领域,有着很多的数据,在一次编书过程中,需要需要相关中药材数据,就通过使用爬虫技术获取部分数据。
由于官方对爬虫类文章的限制,所以本文不进行过多展示。
2. 案例实现
2.1 模拟登录页面分析
登录页:
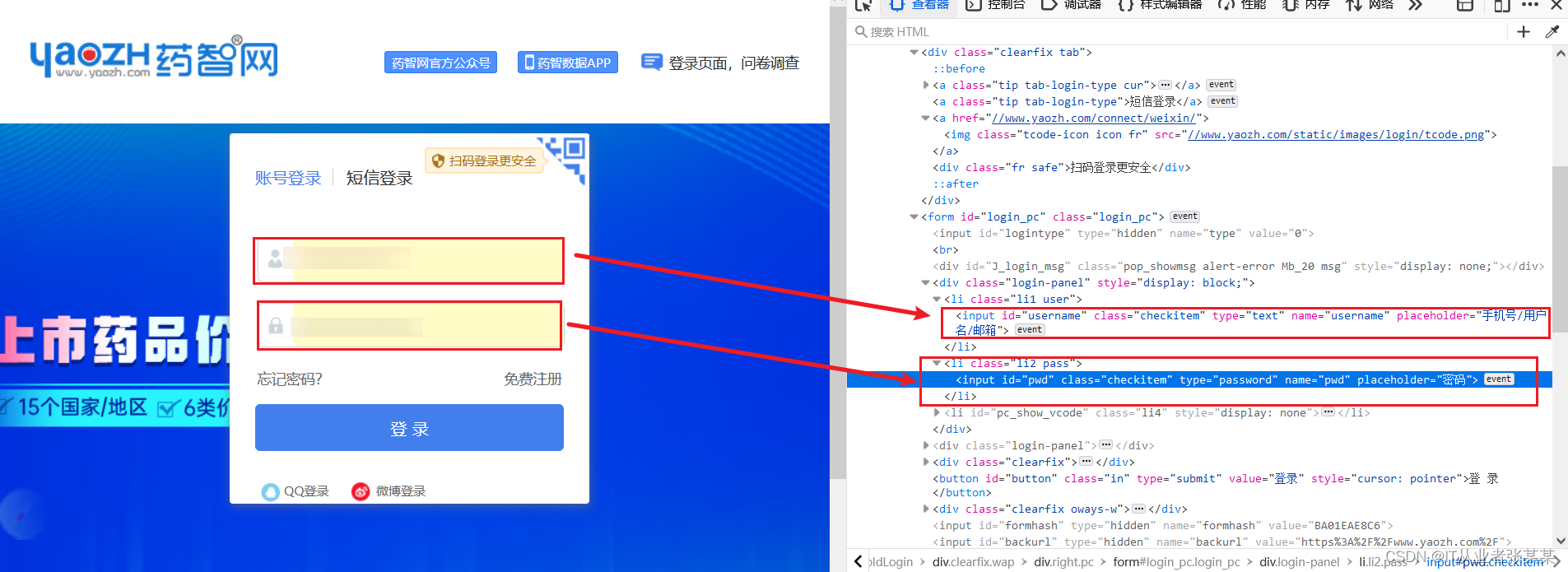
登录提交页面:
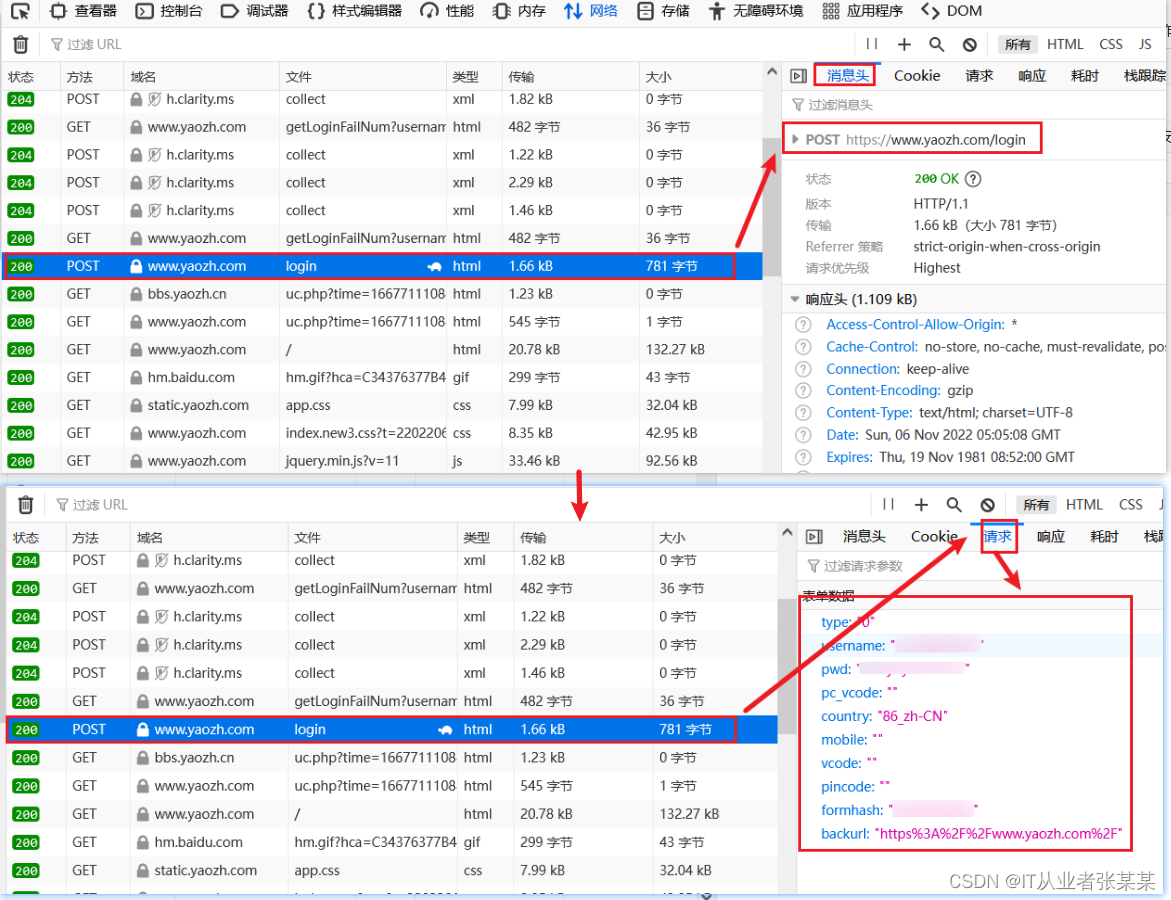
可以看到需要提交的数据
2.2 模拟登录实现
import requests
import sys
import time
import bs4
# 初始化headers数据
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:106.0) Gecko/20100101 Firefox/106.0",
"Referer":"https://www.yaozh.com/login/proxy?time={}".format(str(time.time_ns())[0:13]),
"Cookie":"",
}
# 请求的登录路径
post_url = "https://www.yaozh.com/login"
# 传入的参数
post_data = {
"username":"xxx",
"pwd":"XXX",
"type":"0",
"pc_vode":"",
"country":"86_zh-CN",
"mobile":"",
"vcode":"",
"pincode":"",
"formhash":"https://www.yaozh.com/login",
"backurl":"https://www.yaozh.com/login"
}
# 构建session
session = requests.session()
# 通过session发送post请求
session.post(post_url,post_data,headers=headers)
2.3 构建待爬取的药材名称
zy_list = [
"巴戟天","白芍","白术","萹蓄","苍耳子","炒白术","车前子","川芎",
"大黄","大云","当归","党参","翟麦","茯苓","腹毛","甘草","狗脊",
"枸杞","故之子","海金沙","黑杜仲","黑芋头","红花","黄柏","黄精",
"黄连","黄芪","鸡血藤","姜黄","韭子","鹿茸","没药","牡丹皮",
"木瓜","木通","木香","年见","牛膝","全虫","人参","乳香","桑寄生",
"山药","山芋肉","伸筋草","生地","石楠藤","石韦","熟地","锁阳",
"葶苈子","菟丝子","文术","西吉","细辛","香附","辛夷","续断",
"阳起石","淫羊藿","元参","元胡","云苓","枝子","枳壳"
]
2.4 药材查询页面分析
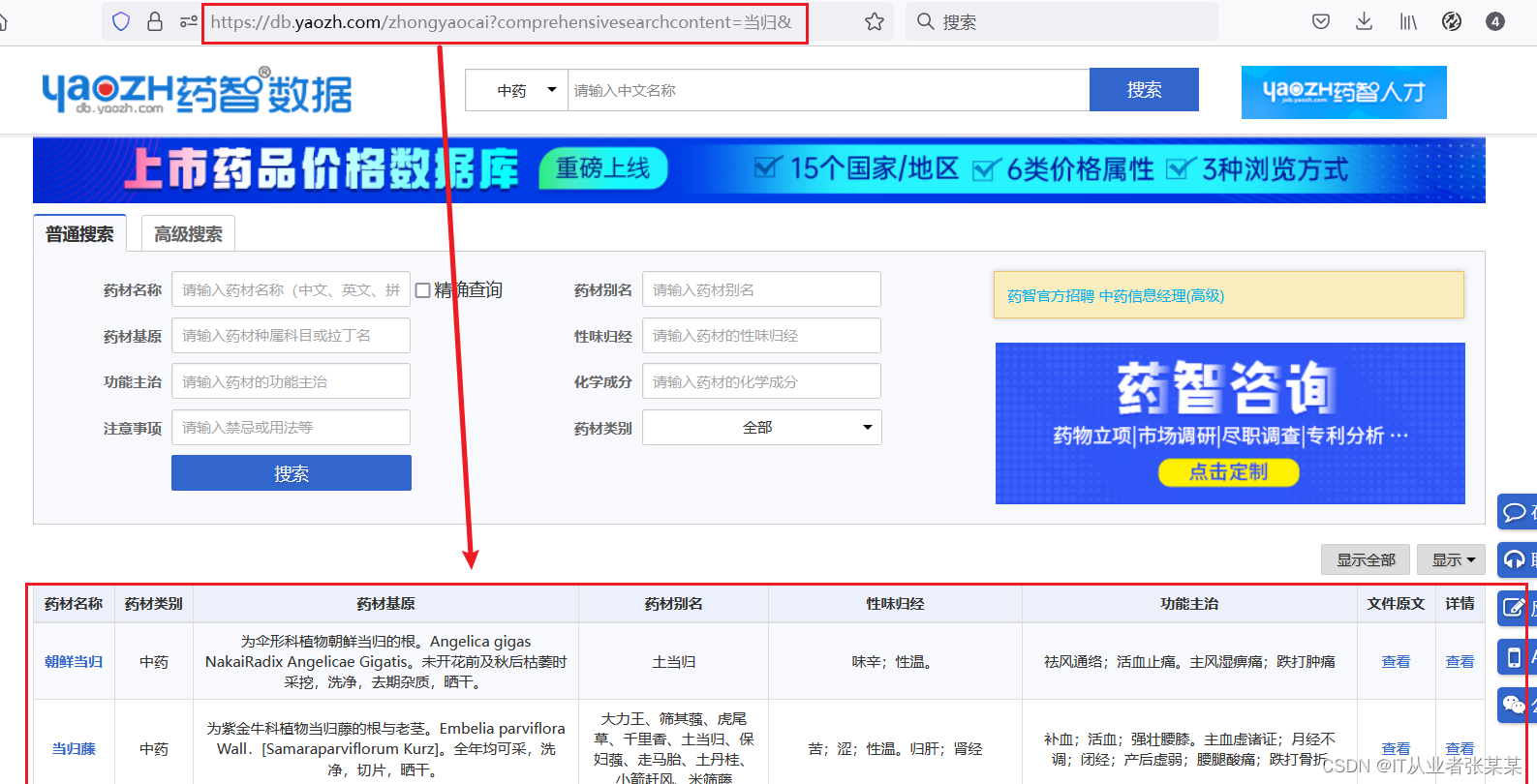
基本网址为:
https://db.yaozh.com/zhongyaocai?comprehensivesearchcontent=当归&
换一个中药,只需要更新当归即可。
每个中药的页面为:
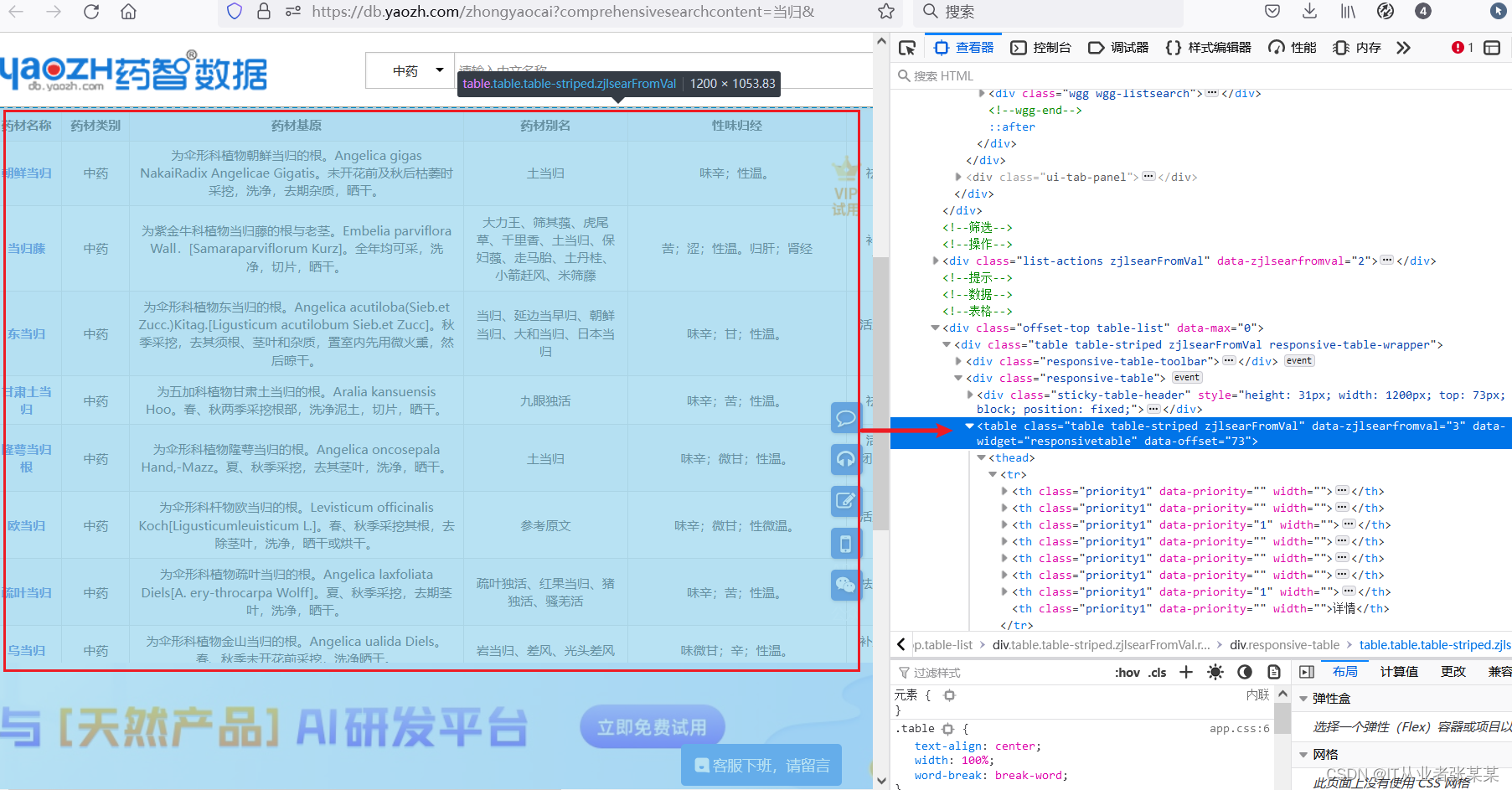
2.3 拼接网址,并获取数据
import time
content_dict = {}
for zy_name in zy_list:
time.sleep(10)
# https://db.yaozh.com/zhongyaocai?comprehensivesearchcontent=%E9%BB%84%E8%8A%AA&
# 拼接药材信息网址
zy_url = "https://db.yaozh.com/zhongyaocai?comprehensivesearchcontent={}&".format(zy_name)
try:
res = session.get(zy_url)
res.encoding = res.apparent_encoding
content_all = res.text
# 把药材详情页加载为dom文档
soup = bs4.BeautifulSoup(content_all,"html.parser")
# 获取每个药材页面的数据
tbody = soup.select('.table > tbody:nth-child(2) > tr')
# 遍历页面
for tr in tbody:
num = 0
content = []
for cell in tr:
num += 1
# 如果为偶数 提取其内容 把内容追加到列表中
if num % 2 == 0:
content.append(cell.get_text())
if num == 17:
# 把当前数据追加到字典中 并其用中药名作为key
content_dict[content[0]] = content
print("content:=====>",content)
except:
print("当前行有问题{}".format(zy_name))
# 查看保存的数据
print(content_dict)
输出为:
{'巴戟天': ['巴戟天', '中药', '本品为茜草科植物巴戟天Morinda officinalis How 的干燥根。全年均可采挖,\n洗净,除去须根,晒至六、七成干,轻轻捶扁,晒干。', '巴戟、巴吉天、戟天、巴戟肉、鸡肠风、猫肠筋、兔儿肠', '甘、辛,微温。归肾、肝经。', '补肾阳,强筋骨,祛风湿。用于阳痿遗精,宫冷不孕,月经不调,少腹冷痛,风湿痹痛,筋骨痿软。', '查看', '查看'],
'白芍': ['白芍', '中药', '本品为毛茛科植物芍药Paeonia tacti lora Pall.的干燥根。夏、秋二季采挖,洗净,除去头尾和细根,置沸水中煮后除去外皮或去皮后再煮,晒干。', '白芍药、金芍药。', '苦、酸,微寒。归肝、脾经。', '养血调经,敛阴止汗,柔肝止痛,平抑肝阳。用于血虚萎黄,月经不调,自汗,盗汗,胁痛,腹痛,四肢挛痛,头痛眩晕。', '查看', '查看'],
...
}
2.4 保存数据
import pandas as pd
df1 = pd.DataFrame(content_dict,index = ['药材名称', '药材类别', '药材基原', '药材别名', '性味归经', '功能主治', '文件原文', '详情'])
df1
输出为:
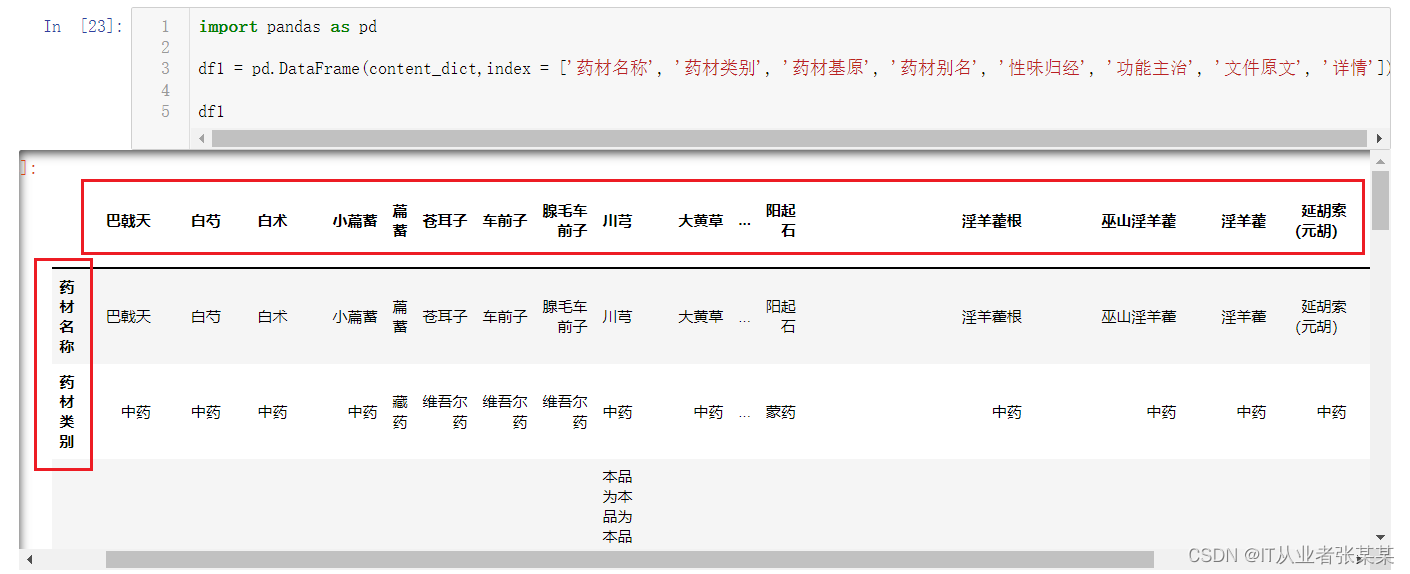
2.5 保存数据
df_t = df1.T
df_t.to_excel("./zhongyao.xlsx",engine = "openpyxl")
df_t
输出为:
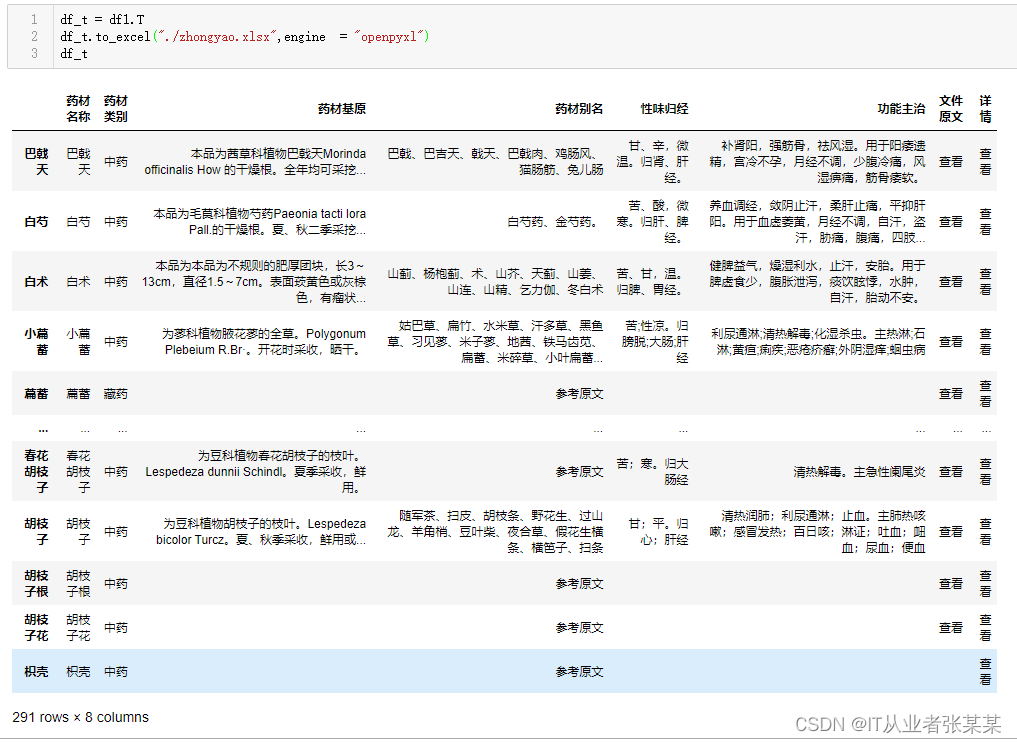
2.6 总结
尽管该网站对外公开的,但使用的过程中一定要注意采集数据的频率,不要给该网站带来性能压力。

















 950
950











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











