









1 HDFS概述
1)HDFS是什么
源自于Google的GFS论文,发表于2003年10月,HDFS是GFS克隆版
易于扩展的分布式文件系统。运行在大量普通廉价机器上,提供容错机制。 为大量用户提供性能不错的文件存取服务
适合一次写入,多次读取的场景,不支持文件的修改,适合用来做数据分析,不适合做网盘应用
2)HDFS的优点
高容错性:数据自动保存多个副本(默认3个副本),副本丢失后自动恢复
适合批处理:移动计算而非数据,数据位置暴露给计算框架
适合大数据处理:GB、TB、甚至PB级数据,百万规模以上的文件数量,10K+节点规模。
流式文件访问:一次性写入,多次读取,保证数据一致性。
可构建在廉价机器上:通过多副本提高可靠性,提供了容错和恢复机制
3)HDFS的缺点:
低延迟数据访问达不到
比如毫秒级,低延迟与高吞吐率
小文件存取
占用NameNode大量内存,寻道时间超过读取时间
并发写入、文件随机修改
一个文件只能有一个写者,仅支持append
2 HDFS架构设计
存储:分块存储





3 HDFS数据块(block):
1)文件被切分成固定大小的数据块
默认数据块大小为128MB,可配置,若文件大小不到128MB,则单独存成一个block
2)为何数据块如此之大
数据传输时间超过寻道时间(高吞吐率)
3) 一个文件存储方式
按大小被切分成若干个block,存储到不同节点上,默认情况下每个block有三个副本
4 HDFS读写流程
读

写

HDFS典型物理拓扑

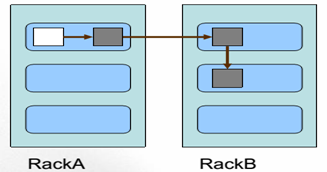
4 Block副本放置策略
副本1:同Client的节点上
副本2:不同机架中的节点上
副本3: 与第二个副本同一机架的另一个节点上
其他副本:随机挑选
一个文件划分成多个block,每个block存多份,如何为每个block选择节点存储这几份数据?
5 HDFS可靠性策略
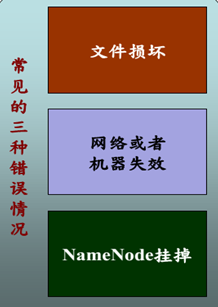
文件完整性
—CRC32校验
—用其他副本取代损坏文件
Heartbeat
—Datanode定期向Namenode发heartbeat
元数据信息
—FSImage(文件系统镜像)、Editlog(操作 日志)
—多份存储
—主备NameNode实时切换
HDFS不适合存储小文件,元信息存储在NameNode内存中, 一个节点的内存是有限的,存取大量小文件消耗大量的寻道时间,类比拷贝大量小文件与拷贝同等大小的一个大文件。 NameNode存储block数目是有限的,一个block元信息消耗大约150byte内存,存储一亿个block,大约需要20GB内存,如果一个文件大小为10K,则一亿个文件大小仅为1TB(但要消耗掉NameNode20GB内存)。
6 HDFS访问方式
HDFS Shell命令
HDFS Java API
HDFS Fuse:实现了fuse协议
HDFS lib hdfs:C/C++访问接口
HDFS其他语言编程API
使用thrift实现
支持C++、Python、php、C#等语言
7 HDFS Shell命令一概览

8 hadoop fs 命令一文件操作命令:

HADOOP Shell命令一文件操作命令
将本地文件上传到HDFS上
bin/hadoop fs –copyFromLocal /local/data /hdfs/data
删除文件/目录
bin/hadoop fs –rm /hdfs/data
创建目录
bin/hadoop fs –mkdir /hdfs/data
HDFS Shell命令一管理命令

9 HDFS Shell命令一管理脚本
HDFS Shell命令一文件管理命令fsck
检查hdfs中文件的健康状况
查找缺失的块以及过少或过多副本的块
查看一个文件的所有数据块位置
删除损坏的数据块

HDFS Shell命令一文件管理命令fsck

HDFS Shell命令一数据均衡器balancer
数据块重分布
bin/start-balancer.sh-threshold
percentage of disk capacity
HDFS达到平衡状态的磁盘使用率偏差值
值越低各节点越平衡,但消耗时间也更长
10 HDFS Java API介绍及示例
configuration类:
该类的对象封装了配置信息,这些配置信息来自core-*.xml
FileSystem类:
文件系统类,可使用该类的方法对文件/目录进行操作。一般通过FileSystem的静态方法get获得一个文件系统对象
FSDataInputStream和FSDataOutputStream类:
HDFS中的输入输出流。分别通过FileSystem的Open方法和create方法获得
以上类均来自java包:org.apache.hadoop.fs
HDFS Java程序示例
将本地文件拷贝到HDFS上
Configution config=new Configution();
FileSystem hdfs = FileSystem.get(config);
Path srcPath = new Path(srcFile);
Path dstPath = new Path(dstFile);
hdfs.copyFromLocalFile(srcPath, dstPath);


























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









