









数据库的列类型
- 数值
tinyint 十分小的数据 1个字节
smallint 较小的字节 2个字节
mediumint 中等大小的数据 3个字节
int 标准的整数 4个字节 常用
bigint 较大的整数 8个字节
float 浮点数 4个字节
double 浮点数 8个字节
decimal 字符串形式的浮点数 金融计算的时候一般使用decimal
- 字符串
char 字符串固定大小的 0-255
varchar 可变字符串 0-65535 常用的
tinytext 微型文本 2^8-1
text 文本串 2^16-1 保存大文本
- 时间日期
date YYY-MM-DD 日期格式
time HH: mm: ss 时间格式
datetime YYYY-MM-DD HH: mm: ss 最常用的时间格式
timestamp 时间戳, 1970.1.1到现在的毫秒数!也较为常用!
year 年份表示
- null
没有值,未知。且不要使用NULL进行运算
数据库的字段属性(重点)
Unsigned :
●无符号的整数
●声明了该列不能声明为负数
zerofill:
●0填充的
●不足的位数,使用0来填充,int (3),5 — 005
自增(AUTO_INCREMENT):
●自动在上一条记录的基础上+1(默认)
●通常用来设计唯一的主键~index ,必须是整数类型
●可以自定义设计主键自增的七十至和步长


非空:
数据不能为空否则报错
DDL 定义
DML 操作
DQL 查询
DCL 控制
DDL(数据定义语言)
对数据库的操作:
*1.创建数据库:
*create database 数据库名称;
*创建数据库,判断不存在,再创建:
*create database if not exists数据库名称;
*创建数据库,并指定字符集
*create database 数据库名称character set字符集名;
*练习:创建db4数据库, 判断是否存在,并制定字符集为gbk
*create database if not exists db4 character set gbk;
2. R(Retrieve): 查询
*查询所有数据库的名称:
*show databases;
*查询某个数据库的字符集:查询某个数据库的创建语句
show create database 数据库名称;
3.U(Update);修改
*修改数据库的字符集
*alter database 数据库名称character set 字符集名称;
4.D(Delete) :删除
*删除数据库
*drop database数据库名称;
*判断数据库存在,存在再删除
*drop database if exists数据库名称;
5.使用数据库:
*查询当前正在使用的数据库名称
*select database();
*使用数据库
*use数据库名称;
对表的操作:
-
创建表:
*create table 表名(
列名1 数据类型1,
列名2 数据类型2
);注意最后一列,不需要加逗号
1.复制表:
*create table 表名 like 被复制的表名 -
查询某个数据库中所有表的名称
*show tables;
查询表结构:
*desc 表名 -
删除表:
*drop table 表名;
*drop table if exists 表名; -
修改表名:
*alter table rename to 新的表名
修改表的字符集:
*查看创建表的结构 show create table 表名
*alter table 表名 character set utf8
添加一列:
*alter table 表名 add 列名 数据类型;
修改列名称 类型
*alter table 表名 change 列名 新列名 新数据类型
*alter table 表名 modify 列名 新数据类型
*删除列:alter table 表名 drop 列名
DML :增删改表中数据
1. 添加数据:
*语法:
* insert into表名(列名1 ,列名2,…列名n) values(值1,值2,…值n);
*注意:
1.列名和值要- – 对应。
2.如果表名后,不定义列名,则默认给所有列添加值
insert into表名values(值1,值2,…值n);
3.除了数字类型,其他类型需要使用引号(单双都可以)引起来
2.删除数据:
语法:
delete from 表名[where 条件]
*注意:
1.如果不加条件,则删除表中所有记录。
2.如果要删除所有记录
1. delete from表名; --不推荐使用。有多少条记录就会执行多少次删除操作
2. TRUNCATE TABLE表名; --推荐使用,效率更高先删除表,然后再创建一-张一
样的表。
3.修改数据:
*语法:
*update 表名set 列名1 =值1,列名2 =值2,… [where 条件];
DQL :查询表中的记录
select * from 表名;
1.语法:
select
字段列表
from
表名列表
where
条件列表
group by
分组字段
having
分组之后的条件
order by
排序
limit
分页限定
2.基础查询
1.多个字段的查询
select字段名1,字段名2… from表名;
*注意:
如果查询所有字段,则可以使用来替代字段列表。
2.去除重复:
*distinct
3.计算列
*一般可以使用四则运算计算一 些列的值。 (一 般只会进行数值型的计算)
- ifnull(表达式1 ,表达式2) : null参与的运算,计算结果都为null
*表达式1 :哪个字段需要判断是否为null
*如果该字段为null后的替换值。
4.起别名:
*as:as也可以省略
3.条件查询
- where子句后跟条件
2.运算符
*>、<、<=、>=、=、<>
*BETWEEN. . . AND
*IN(集合)
*LIKE
*占位符:- _:单个任意字符
- %:多个任意字符
*IS NULL
*and或&&
*or或||
*not或!

DQL :查询语句
1.排序查询
*语法: order by子句
*order by排序字段1 排序方式1 ,排序字段2 排序方式2…
*排序方式:
*ASC :升序,默认的。,
- DESC :降序。
*注意:如果有多个排序条件,则当前边的条件值一样时, 才会判断第二条件。
2.聚合函数:将一列数据作为一个整体,进行纵向的计算。
- count :计算个数
- -般选择非空的列:主键
- count(*)
- max:计算最大值
- min:计算最小值
- sum:计算和
- avg:计算平均值
*注意:聚合函数的计算,排除null值。
解决方案:
1.选择不包含非空的列进行计算- IFNULL函数
3.分组查询:
1.语法: group by分组字段;
2.注意:
1.分组之后查询的字段:分组字段、聚合函数
2. where和having 的区别?
1. where在分组之前进行限定,如果不满足条件,则不参与分组。having在分组之后进行限定,如果不满足结果,则不会被查询出来
2. where后不可以跟聚合函数,having可以进行聚合函数的判断。
4.分页查询
1.语法: limit开始的索引,每页查询的条数;
2.公式:开始的索引= (当前的页码 - 1) * 每页显示的条数–每领显示3条记录
SELECTROM student LIMIT 0,3; --第1页
SELECT * FROM student LIMIT 3,3; --第2页
SELECT * FROM student LIMIT 6,3; --第3页
3. limit是一个MySQL"方言
约束
*概念:对表中的数据进行限定,保证数据的正确性、有效性和完整性。
*分类:
1.主键约束: primary key
2.非空约束: not null
3.唯一约束: unique
4.外键约束: foreign key
*非空约束: not null
1.创建表时添加约束
CREATE TABLE stu(
id INT ,
NAME VARCHAR(20) NOT NULL – name为非空);
2.创建表完后,添加啡空约束
ALTER TABLE stu MODIFY NAME VARCHAR(20) NOT NULL;
3.删除name的非空约束
ALTER TABLE stu MODIFY NAME VARCHAR(20);
*唯一约束: unique,值不能重复
1.创建表时,添加唯-约束
CREATE TABLE stu(
id INT,
phone_ number VARCHAR(20) UNIQUE --添加了唯一约束
);
*注意mysq1中,唯一约束限定的列的值可以有多个null
2.删除唯一约束
ALTER TABLE stu DROP INDEX phone_ number ;
在创建表后,添加唯一约束 .
ALTER TABLE stu MODIFY phone_ number VARCHAR(20) UNIQUE ;
主键约束: primary key。
I.注意:
1.含义:非空且唯一
2.一张表只能有一个字段为主键
3.主键就是表中记录的唯一标识
2.在创建表时,添加主键约束
create table stu(
id int primary key,–给id添加主键约束
name varchar( 20)
);
3.删除主键
错误的:alter table stu modify id int ;
ALTER TABLE stu DROP PRIMARY KEY;
4.创建完表后,添加主键
ALTER TABLE stu MODIFY id INT PRIMARY KEY;
5.自动增长:
1.概念:如果某一列是数值类型的,使用auto__increment 可以来完成值得自动增长
2.在创建表时,添加主键约束,并且完成主键自增长 create table stu( id int primary key auto_ increment,-- 给id添加主键约束 name varchar( 20) );
3.删除自动增长 ALTER TABLE stu MODIFY id INT;I
4.添加自动增长 ALTER TABLE stu MODIFY id INT AUTO_ INCREMENT;
*外键约束: foreign key,让表于表产生关系,从而保证数据的正确性。
1.在创建表时,可以添加外键
*语法:
create table表名(
……
外键列
constraint外键名称foreign key (外 键列名称) references 主表名称(主表列名称)
);
2.删除外键
ALTER TABLE表名DROP FOREIGN KEY 外键名称;
3.创建表之后,添加外键
ALTER TABLE 表名ADD CONSTRAINT 外键名称FOREIGN KEY (外键字段名称) REFERENCES 主表名称(主表列名称);
4.级联操作
1.添加级联操作
语法: ALTER TABLE表名ADD CONSTRAINT 外键名称
FOREIGN KEY (外键字段名称) REFERENCES 主表名称(主表列名称) ON UPDATE CASCADE ON DELETE CASCADE;
2.分类:
1.级联更新: ON UPDATE CASCADE
2.级联删除: ON DELETE CASCADE
范式分类:
1.第一范式(1NF) :每一列都是不可分割的原子数据项
2.笫二范式(2NF) : 在1NF的基础上,非码属性必须完全依赖于码(在1NF基础_上消除非主属性对主码的部分函数依赖)
几个概念:
1.函数依赖: A–>B,如果通过A属性(属性组)的值,可以确定唯一B属性的值 。则称B依赖于A
例如:学号–>姓名。(学号, 课程名称) --> 分数
2.完全函数依赖: A–>B,如果A是一属性组,则B属性值得确定出要依赖于A属性组中所有的属性值。
例如: (学号, 课程名称) --> 分数
3.部分函数依赖: A–>B,如果A是 一个属性组,则B属性值得确定只需要依赖于A属性组中某一些值即可。
例如: (学号,课程名称) – >姓名,
4.传递函数依赖: A–>B, B – >C .如果通过A属性(属性组)的值, 可以确定唯一 B属性的值,在通过B属性(属性组)的值可以确定唯一C
属性的值,则称C传递函数依赖于A
例如:学号–>系名,系名–>系主任
5.码:如果在- -张表中,一个属性或属性组,被其他所有属性所完全依赖,则称这个属性(|属性组)为该表的码
例如:该表中码为: (学号, 课程名称)
*主属性:码属性组中的所有属性
非主属性:除过码属性组的属性
3.第三范式(3NF) : 在2NF基础上,任何非主的性不依赖于其它非主小性(在2NF基础 上消除传递依赖)
*多表查询的分类:
1.内连接查询:
1.隐式内连接:使用where条件消除无用数据
2.显式内连接:
*语法: select字段列表from表名1 [inner] join表名2 on条件
例如:
* SELECT * FROM emp INNER JOIN dept ON emp.‘dept_ id’ = dept. ‘id’;
* SELECT * FROM emp JOIN dept ON emp.‘dept_ id’ = dept.’ id’ ;

2.外链接查询:
1.左外连接:
语法: select字段列表from 表1 left [outer] join 表2 on条件;
查询的是左表所有数据以及其交集部分。
例子:
–查询所有员工信息,如果员工有部门,则查询部门名称,没有部门,则不显示部门名称
SELECTt1.,t2.'name’FROM emp t1 LEFT JOIN dept t2 ON t1.‘dept_ id’ = ‘t2. id’ ;
2.右外连接:
*语法: select 字段列表from表1 right [outer] join表2 on条件;
*查询的是右表所有数据以及其交集部分。
例子:
SELECT FROM dept t2 RIGHT JOIN emp t1 ON t1.‘dept_ id’ = t2.‘id’;
1
3.子查询:
*概念:查询中嵌套查询,称嵌套查询为子查询。
–查询工资最高的员工信息
–查询最高的工资是多少9000
SELECT MAX(salary) FROM emp;
– 2查询员工信息,并且工资等于9000的
SELECT * FROM emp WHERE emp." salary" = 9000;
– -条sql就完成这个操作子查询
SELECT * FROM emp WHERE emp." salary" = (SELECT MAX(salary) FROM emp);
*子查询不同情况
1.子查询的结果是单行单列的:
子查询可以作为条件,使用运算符去判断。运算符 : > >= < <= =
--查询员工工资小于平均工资的人
SELECT * FROM emp WHERE emp.salary < (SELECT AVG(salary) FROM emp);
2.子查询的结果是多行单列的:
*子查询可以作为条件,使用运算符in来判断
--查询'财务部'和'市场部'所有的员工信息
SELECT id FROM dept WHERE NAME = '财务部' OR NAME = ' 市场部' ;
SELECT * FROM emp WHERE dept_ id = 3 OR dept_ id = 2;
--子查询
SFLECT * FROM emp WHERE dept_ id IN (SELECT id FROM dept WHERE NAME = '财务部' OR NAME = ' 市场部')
3.子查询的结果是多行多列的:
*子查询可以作为一-张虚拟表参与查询
-_查询员工入职日期是2011-11-11日之后的员工信息和部门信息
-_子查询
SELECT * FROM dept t1 ,(SELECT * FROM emp WHERE emp." join_ date^ >‘ 2011-11-11') t2
WHERE t1.id = t2.dept_ _id;
普通内连接
SELECT* FROM emp t1,dept t2 WHERE t1. dept_ id~ = t2. id AND t1.~ join_ date^ > ' 2011-11-11.
模糊查询
| 运算符 | 语法 | 描述 |
|---|---|---|
| IS NULL | a is null | 如果操作符为NULL,结果为真 |
| IS NOT | a is not null | 如果操作符不为null,结果为真 |
| BETWEEN | a between b and c | 若a再b和c之间,则结果为真 |
| LIKE | a like b | SQL匹配,如果a匹配b,则结果为真 |
| IN | a in (a1,a2,a3,…) | 假设a在a1,或者a2…其中的某一个值中,结果为真 |
LIKE结合 %(代表0到任意个字符) _(代表一个字符)
事务
事务原则: ACID原则 原子性,一致性,隔离性,持久性 (脏读,幻读…)
原子性:指事务是一个不可分割的工作单位,事务中的操作要么一起发生,要么都不发生。
持久性:表示事务结束后的数据不随着外界原因呆滞数据丢失。如果事务没有提交没回复到原装,事务已经提交,持久化到数据库
一致性:事务前后的数据完整性要保证一致。
隔离性:针对多个用户同时操作,只要是排除其他事务对本次事务的影响。
因为隔离所导致的一些问题
脏读:
指一个事务读取了另外一个事务未提交的数据
不可重复读:
子啊一个事务内读取表中的某一行数据,多次读取结果不同(这个不一定是错误的,只是某些场合不对)
虚读(幻读):
是指在一个事务读取到了别的事务插入的数据。导致前后读取不一致
--MySQL是默认开启事务自动提交的--
SET AUTOCOMMIT =0 #关闭
SET AUTOCOMMIT =1 #开启(默认的)
--事务开启
START TRANSACTION --标记一个事务的开始,从这个之后sql都在同一个事务内
--提交:持久化
COMMIT
--回滚:回到原来的样子
ROLLBACK
--事务结束
SET AUTOCOMMIT =1 --开启自动提交
SAVEPOINT 保存点名--设置一个事务的保存点
ROLLBACK TO SAVEPOINT 保存点名 --回滚到保存点
RELEASE SAVEPOINT 撤销保存点
测试实例:
索引
MySQL官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构。提取句子主干,就可以得到索引的本质:索引是数据结构。
索引分类:
主键索引:
&nbps;&nbps;&nbps;&nbps;&nbps;&nbps; 唯一的标识,主键不可重复,只能有一列作为主键
唯一索引:
&nbps;&nbps;&nbps;&nbps;&nbps;&nbps;避免重复的列出现,唯一索引可以重复,多个列都可以标识位 唯一索引
常规索引:
&nbps;&nbps;&nbps;&nbps;&nbps;&nbps;默认的,index,key关键字设置
全文索引:
&nbps;&nbps;&nbps;&nbps;&nbps;&nbps;在特定的数据库引擎下才有, MyISAM
,快速定位数据。
模糊查询的时候,第一个通配符使用的是%,这个时候索引是失效的。
索引的使用:
查看sql语句的执行计划
explain + sql语句
创建索引:
1) 使用 CREATE INDEX 语句
可以使用专门用于创建索引的 CREATE INDEX 语句在一个已有的表上创建索引,但该语句不能创建主键。
语法格式:
CREATE <索引名> ON <表名> (<列名> [<长度>] [ ASC | DESC])
语法说明如下:
<索引名>:指定索引名。一个表可以创建多个索引,但每个索引在该表中的名称是唯一的。
<表名>:指定要创建索引的表名。
<列名>:指定要创建索引的列名。通常可以考虑将查询语句中在 JOIN 子句和 WHERE 子句里经常出现的列作为索引列。
<长度>:可选项。指定使用列前的 length 个字符来创建索引。使用列的一部分创建索引有利于减小索引文件的大小,节省索引列所占的空间。在某些情况下,只能对列的前缀进行索引。索引列的长度有一个最大上限 255 个字节(MyISAM 和 InnoDB 表的最大上限为 1000 个字节),如果索引列的长度超过了这个上限,就只能用列的前缀进行索引。另外,BLOB 或 TEXT 类型的列也必须使用前缀索引。
ASC|DESC:可选项。ASC指定索引按照升序来排列,DESC指定索引按照降序来排列,默认为ASC。
2) 使用 CREATE TABLE 语句
索引也可以在创建表(CREATE TABLE)的同时创建。在 CREATE TABLE 语句中添加以下语句。语法格式:
CONSTRAINT PRIMARY KEY [索引类型] (<列名>,…)
在 CREATE TABLE 语句中添加此语句,表示在创建新表的同时创建该表的主键。
语法格式:
KEY | INDEX [<索引名>] [<索引类型>] (<列名>,…)
在 CREATE TABLE 语句中添加此语句,表示在创建新表的同时创建该表的索引。
语法格式:
UNIQUE [ INDEX | KEY] [<索引名>] [<索引类型>] (<列名>,…)
在 CREATE TABLE 语句中添加此语句,表示在创建新表的同时创建该表的唯一性索引。
语法格式:
FOREIGN KEY <索引名> <列名>
在 CREATE TABLE 语句中添加此语句,表示在创建新表的同时创建该表的外键。
在使用 CREATE TABLE 语句定义列选项的时候,可以通过直接在某个列定义后面添加 PRIMARY KEY 的方式创建主键。而当主键是由多个列组成的多列索引时,则不能使用这种方法,只能用在语句的最后加上一个 PRIMARY KRY(<列名>,…) 子句的方式来实现
3) 使用 ALTER TABLE 语句
CREATE INDEX 语句可以在一个已有的表上创建索引,ALTER TABLE 语句也可以在一个已有的表上创建索引。在使用 ALTER TABLE 语句修改表的同时,可以向已有的表添加索引。具体的做法是在 ALTER TABLE 语句中添加以下语法成分的某一项或几项。
语法格式:
ADD INDEX [<索引名>] [<索引类型>] (<列名>,…)
在 ALTER TABLE 语句中添加此语法成分,表示在修改表的同时为该表添加索引。
语法格式:
ADD PRIMARY KEY [<索引类型>] (<列名>,…)
在 ALTER TABLE 语句中添加此语法成分,表示在修改表的同时为该表添加主键。
语法格式:
ADD UNIQUE [ INDEX | KEY] [<索引名>] [<索引类型>] (<列名>,…)
在 ALTER TABLE 语句中添加此语法成分,表示在修改表的同时为该表添加唯一性索引。
语法格式:
ADD FOREIGN KEY [<索引名>] (<列名>,…)
在 ALTER TABLE 语句中添加此语法成分,表示在修改表的同时为该表添加外键。
删除索引对象:
drop index 索引名称 on 表名;
索引底层采用数据结构是:B+tree
索引的实现原理?
通过BTree缩小扫描范围,底层索引进行了排序,分区,索引会携带数据在表中的“物理地址”,通过物理地址定位表中的数据,效率是最高的。
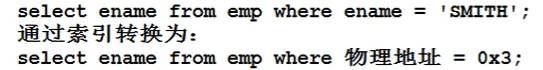
最终通过索引检索导数据|
什么时候考虑给字段添加索引:
1、数据量庞大
2、该字段很少的DML操作
3、该字段经常出现在where字句中
在创建表的时候末尾加上)
















 1485
1485











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









