






做了两年多的故障演练, 一直想聊聊自己对故障演练的理解,但是每次提起笔都不知道写一些什么。
什么是故障演练

为什么要做故障演练
在没做故障演练之前,我想很多人可能和我有一样的想法,我的系统跑了好多年,也没出什么问题,认为自己写的代码挺牛逼的,稳定性贼强。但是做过故障演练之后就会发现“什么垃圾东西”。
故障演练的演练场景非常广泛,小到代码,大到机房。能够覆盖绝大多数故障场景。如:
- 磁盘读/写满载故障,验证应用在磁盘高负载情况下的容错能力(如:磁盘满载导致服务 rt 升高。)。
- 网络抖动故障,验证在网络异常的情况下应用的容错能力(如:服务无法链接数据库)。
- 方法异常,验证代码异常情况下服务的纠错能力(如:数据库查询异常)。
- 方法抛出异常,验证核心方法异常后的容错能力。(如:创建订单抛出异常)
- ……(基础故障见下图)
 如上,通过故障演练不单单可以验证代码层面的异常,也可以检测磁盘、网络等各种异常场景下服务的容灾能力并验证预案是否有效。保障我们在真实故障发生时能够从容面对,并高效解决问题。
如上,通过故障演练不单单可以验证代码层面的异常,也可以检测磁盘、网络等各种异常场景下服务的容灾能力并验证预案是否有效。保障我们在真实故障发生时能够从容面对,并高效解决问题。
历史事件
如何做故障演练
故障注入时机
根据故障发生过程分为前,中,后三个阶段
- 故障发生前(验证在故障发生时应用的容灾能力、预案的可用性)
- 故障发生中(红蓝对抗 之 给故障填一把火)
- 故障发生后(故障复现)
故障发生前 - 故障验证
现阶段经过的大量的经验沉淀,绝大部分故障都能够做到提前预防,所以绝大多数场景下进行的故障演练都发生在故障发生前。流程大致如下
- 对可能发生的故障场景进行分析,输出故障类型、故障预计影响范围。
- 故障编排 编排故障,(需要多个故障的场景,组合多个故障)配置故障目标
- 故障注入
- 观测故障注入后实际对应用的影响。(如关注 avgRt,maxRt,errors,tps 等各种指标但根据故障的不同,验证内容的不同观测的指标也不尽相同,需结合实际场景。)
- 撤销故障
- 验证故障撤销后应用是否恢复 输出故障报告(故障实际影响范围,预案是否生效、撤销后是否恢复等数据)
- 项目优化
以上是一个基础的故障注入流程,比较重要的是:
- 一定要在故障注入前先评估故障影响范围,因为有些故障是不可逆的,可能造成不可挽回的损失,比如你注入了一个 cpu满载、磁盘满载故障、或者网卡网络延迟故障,这些故障都可能导致故障无法撤销,只能通过 reboot 。
- 确定本次故障注入是否有意义,防止做无用功。盲目的进行故障演练并不会提升系统的稳定性,健壮性,只会增加负担。
- 故障撤销后故障并未结束,确保故障撤销后应用恢复。
故障发生中 - 红蓝对抗 之 给故障填一把火
这部分内容扔在探索进行中,以下是本人的一些拙见。
红蓝对抗这个概念应该也并不陌生,在军事上进行红蓝对抗验证军队攻守能力、现代化作战能力等,在互联网行业,同样可以进行无硝烟的红蓝对抗。
(注:红军为进攻方,蓝军为防守方。不同公司对红蓝的定义并不相同)
故障演练只能作为攻放,也就是进攻方搞破坏的一方。
如何成为一个合格红军
基础标准:
- 随时 - 注入时间随机
- 随地 - 注入目标随机
- 随机 - 注入故障随机
进阶标准:
- 结合监控 - 能够动态的分析当前目前服务情况,如发现某台机器网络延迟高扩到范围,让更多的机器网络故障
- 结合链路 - 根据链路信息,实现一条链路上多点、多异常同时故障
- 结合AIGC - 实现进攻场景智能构建。
根据以上定义,其实总结下来就一个字 坏。
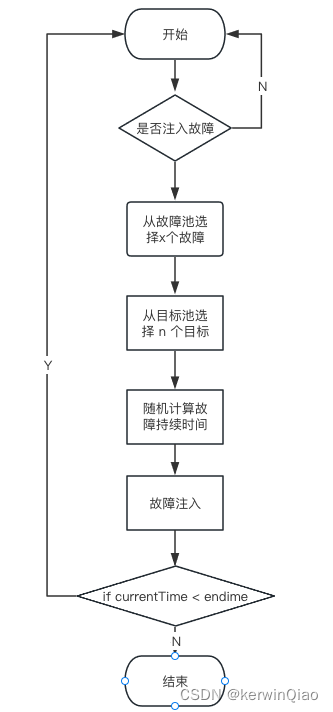
以上是我设计的一个比较简单且容易实现的流程,第一部配置一个故障池、一个目标池,然后开始任务接下来全都交给随机数。在这个流程下故障注入的影响范围是不可控的,就达到了足够坏的目标。但是同样因为是不可控的所以存在故障注入过度,也存在故障注入达不到目标的风险。
如果通过增加逻辑做限制的方式到最后就像一件乞丐服缝缝补补。
可以通过功能设计做一些优化,在配置好故障和故障目标后,生成一个演练场景,这个场景就是在一条时间线上各个时间点做的动作。用户对这个场景可以做一些变更操作。审批通过后根据这个场景进行故障注入。
探索中后续有进展再跟进
故障发生后(故障复现)
这一部分就不想详细介绍了,几乎没遇到过通过故障注入复现故障场景的情况。
强弱依赖
服务的强弱依赖信息对于服务治理,容灾体系的设计都至关重要,而强弱依赖的真实情况只能在故障发生时才能得到验证。
字节跳动依赖验证方案
优点:智能自动化,降低人工成本,链路分析、依赖验证实现功能闭环,智能的指标分析。
无阈值指标分析
- 数据准备:收集和整理需要进行异常检测的历史数据,包括指标名称、时间戳和指标值等信息。
- 特征工程:对数据进行特征提取和转换,将数据转化为机器学习算法可以处理的格式。例如,可以对时间戳进行分解,提取出小时、天、周等时间特征,以及计算出指标的统计特征,如均值、方差、中位数等。
- 模型训练:选择适合数据特点的机器学习算法,如聚类、异常检测、回归等,并使用历史数据进行模型训练。在训练过程中,需要设置合适的参数和超参数,以及对模型进行交叉验证和调参,以提高模型的准确性和泛化能力。
- 异常检测:使用训练好的模型对新数据进行异常检测。对于每个时间点的指标值,可以根据模型预测出其正常范围内的值域,并将超出范围的值视为异常。
- 可视化展示:将异常检测结果以可视化的形式展示出来,便于用户进行观察和分析。可以采用图表、报表等方式,呈现异常指标的趋势和影响。
业务逻辑
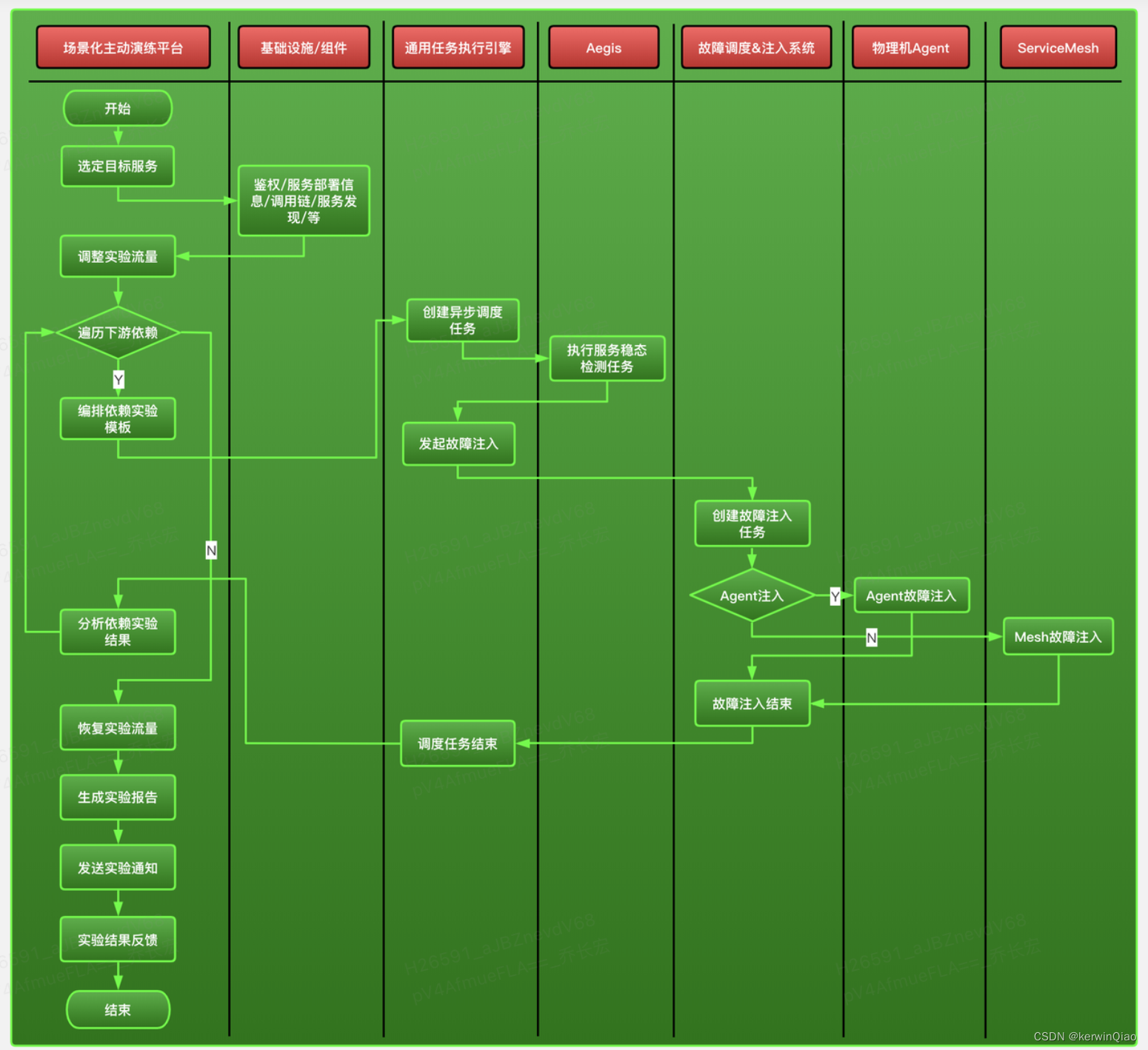
实现一个基础的强弱依赖
架构设计
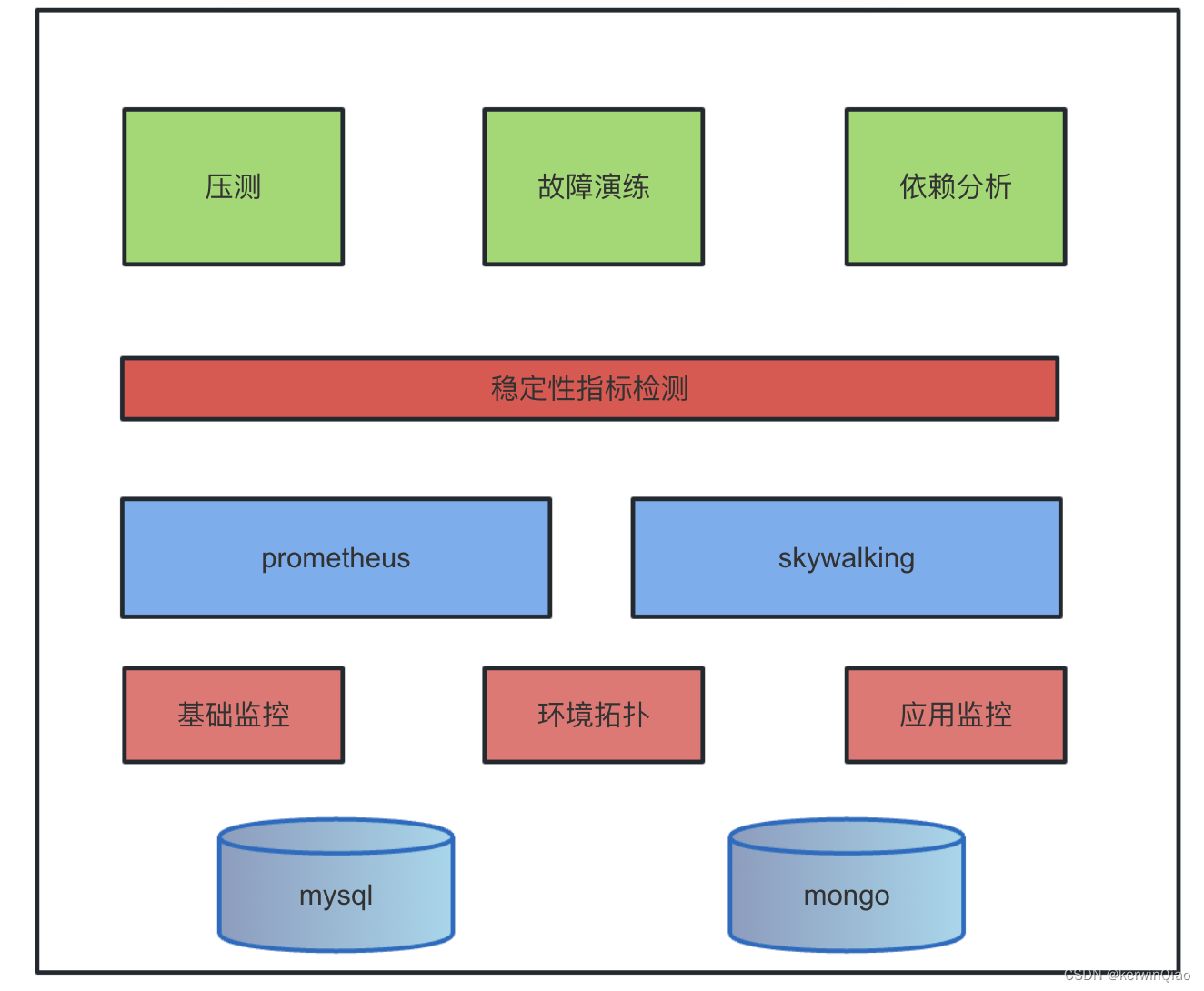
核心能力
服务拓扑
- 通过skywalking获取环境拓扑信息
- 根据拓扑中每一个节点ip获取对应pod信息
- 得到一个应用的拓扑关系
故障注入
基于 chaosblade实现故障注入
背景流量
基于压测平台,将压测流量作为背景流量
稳定性检测
常见的指标:
- 可用性(Availability):指服务在规定时间内能够正常使用的时间比例。通常以百分比的形式表示,例如,99.9%表示服务每年最多只能停机约8.7小时。
- 故障率(Failure rate):指服务在一段时间内出现故障的次数。通常以每小时故障数(Failures per Hour,FPH)的形式表示。
- 平均修复时间(Mean Time to Repair,MTTR):指故障发生后,服务恢复正常运行所需的平均时间。通常以分钟或小时的形式表示。
- 平均故障间隔时间(Mean Time Between Failures,MTBF):指服务正常运行期间,两次故障之间的平均时间间隔。通常以小时或天的形式表示。
- 响应时间(Response Time):指服务响应请求所需的平均时间。通常以毫秒或秒的形式表示。
- 吞吐量(Throughput):指服务在一定时间内处理的请求量。通常以每秒请求数(Requests per Second,RPS)的形式表示。
- 错误率(Error Rate):指服务在一定时间内处理请求时发生错误的比例。通常以百分比的形式表示。
指标计算注意事项:
- 少量流量得到的指标结果不具备准确性
- 不同的业务指标不同(计算方式不同、阈值不同)
- 增加指标适配器 用于处理复杂多变的指标
解决方案:
- 因为不同用户的稳定性指标运算逻辑可能均不相同。可以增加稳定性指标运算模块作为适配器,兼容业务。
- 定义基础指标:
- 压测的RTO、ERROR 作为数据源 计算在‘一段时间内’的平均值/均值。
- 压测的RTO、ERROR 作为数据源 计算RTO、ERROR 重新达到阈值的时间。
- 使用压测平台作为指标数据源带来的问题:
- 如何建立npt接口与服务之间的关联关系
- 整个依赖检查任务使用一个压测任务作为背景流量 还是每两个服务都绑定一个压测任务
开源工具
chaosblade
//TODO
chaosmesh
//TODO














 3776
3776











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









