







 超级会员免费看
超级会员免费看
 本文介绍了Tableau的快速表计算,包括常见、日期类和特殊类表计算,如年度累计、复合增长率和移动平均等。通过具体示例展示了如何使用表计算函数如total(), running_sum(), window_sum()等,解释了表计算与聚合计算的区别,并探讨了previous_value(expression)函数的作用。"
113496081,10537472,使用Kivy动态监听Python文本框内容变化,"['Python', '图形界面', 'Kivy', '事件处理']
本文介绍了Tableau的快速表计算,包括常见、日期类和特殊类表计算,如年度累计、复合增长率和移动平均等。通过具体示例展示了如何使用表计算函数如total(), running_sum(), window_sum()等,解释了表计算与聚合计算的区别,并探讨了previous_value(expression)函数的作用。"
113496081,10537472,使用Kivy动态监听Python文本框内容变化,"['Python', '图形界面', 'Kivy', '事件处理']
-
快速表计算
Tableau内置了部分常用的表计算,称之为 “快速表计算”,这些快速表计算可以视为是预设好的表计算表达式,我们也可以通过把视图的快速表计算拖入度量中查看具体的表计算公式。
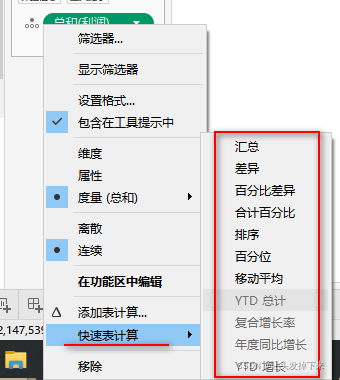
比如说,我们在实例中添加了“总额百分比Percent of Total”,然后可以拖入度量生成字段,之后查看它的计算公式,如下图:
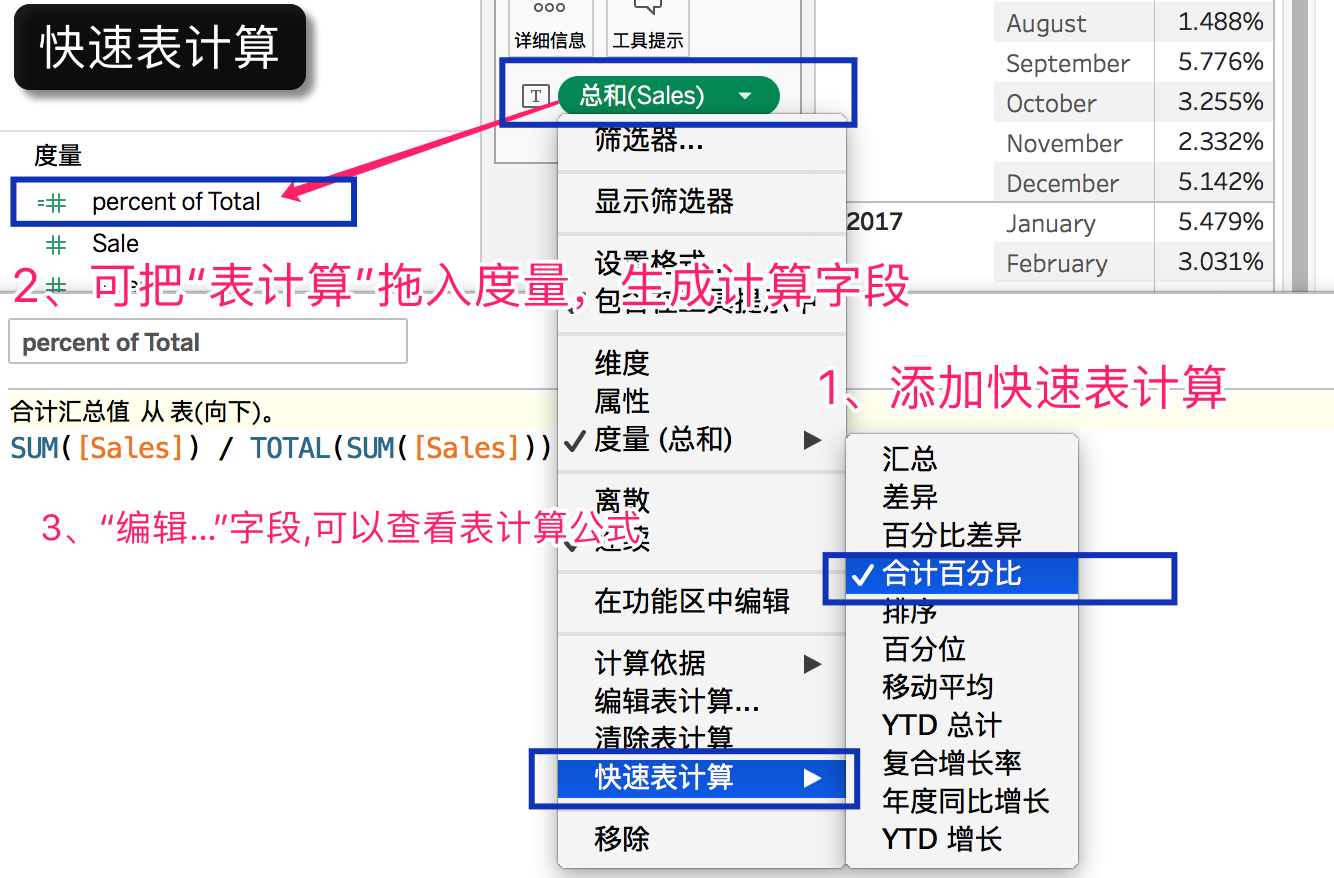
A 常见快速表计算
第一类的快速表计算与日期无关,常见的七种快速表计算的基本对应关系如下:
- 汇总 Running Total=RUNNING_SUM(SUM([Sales]))
- 差异 Difference= ZN(SUM([Sales])) – LOOKUP(ZN(SUM([Sales])), -1)
- 差异百分比 Percent Difference = (ZN(SUM([Sales])) – LOOKUP(ZN(SUM([Sales])), -1)) / ABS(LOOKUP(ZN(SUM([Sales])), -1))
- 总额百分比Percent of Total = SUM([Sales]) / TOTAL(SUM([Sales]))
- 排序 Rank = RANK(SUM([Sales]))
- 百分位 Percentile = RANK_PERCENTILE(SUM([Sales]))
- 移动平均 Moving Average = WINDOW_AVG(SUM([Sales]), -2, 0) (前两位到当前)
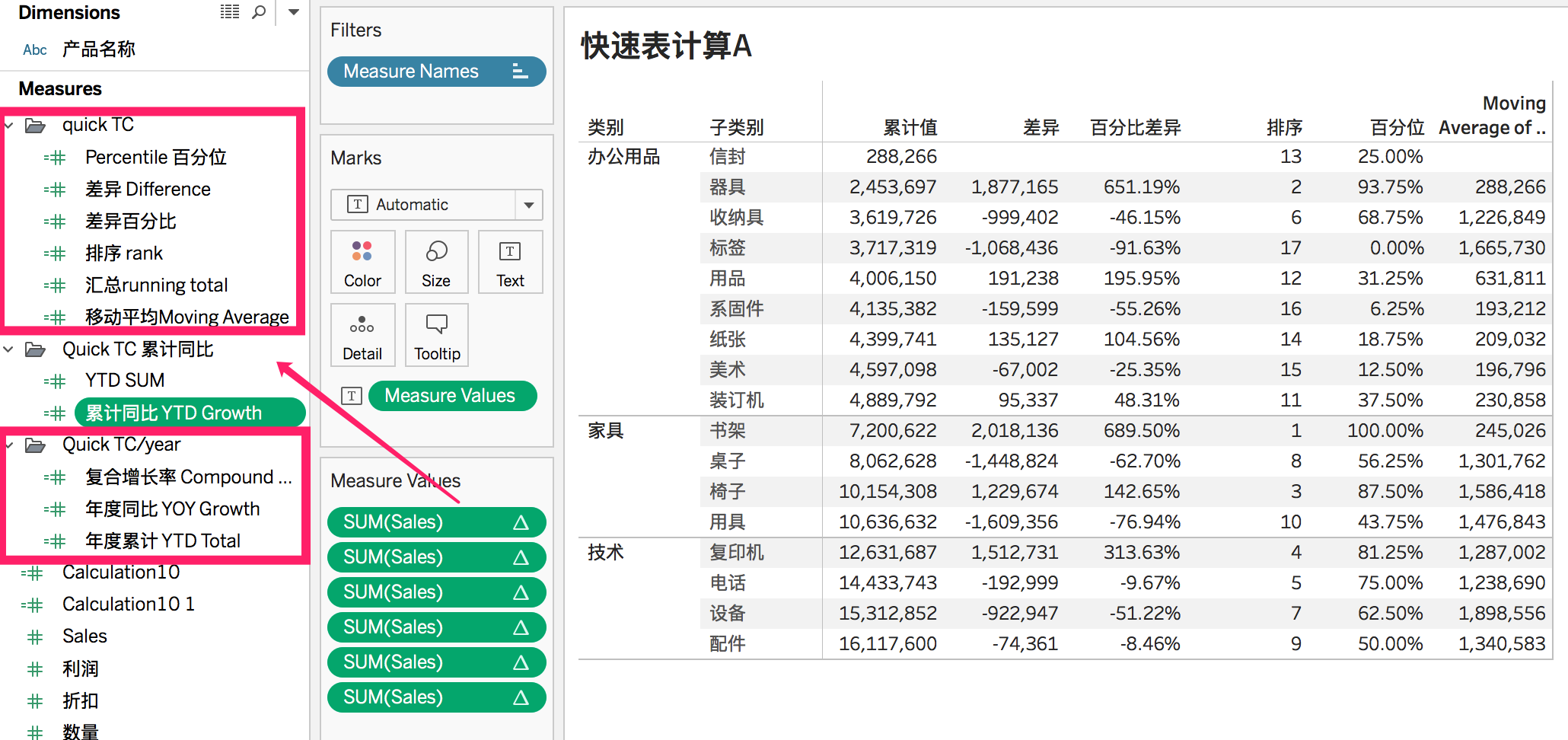
B、日期类快速表计算
另外的四个快速表计算是基于连续时间的,其中前三个需要详细级别至少到“年”, 当存在多个日期维度时,分区字段默认为最低的详细级别的字段,比如有年、季度,则以季度计算。
- 年度累计 YTD Total = RUNNING_SUM(SUM([Sales]))
- 复合增长率 Compound Growth Rate = POWER(ZN(SUM([Sales]))/LOOKUP(ZN(SUM([Sales])), FIRST()),ZN(1/(INDEX()-1))) – 1
- 年度同比 YOY Growth = (ZN(SUM([Sales])) – LOOKUP(ZN(SUM([Sales])), -1)) / ABS(LOOKUP(ZN(SUM([Sales])), -1))
! 使用日期类表计算时有一个前提,视图中必须有相应的日期字段。
- 年度累计、年度同比:详细级别必须是 「年」
- YTD累计、YTD同比:详细级别必须是你想要表达的D,比如month或者day,不能是年。
上面的两个分类,可以看一下下面的演示,我把表计算加入到了度量中并分类。
C 特殊类-二次表计算
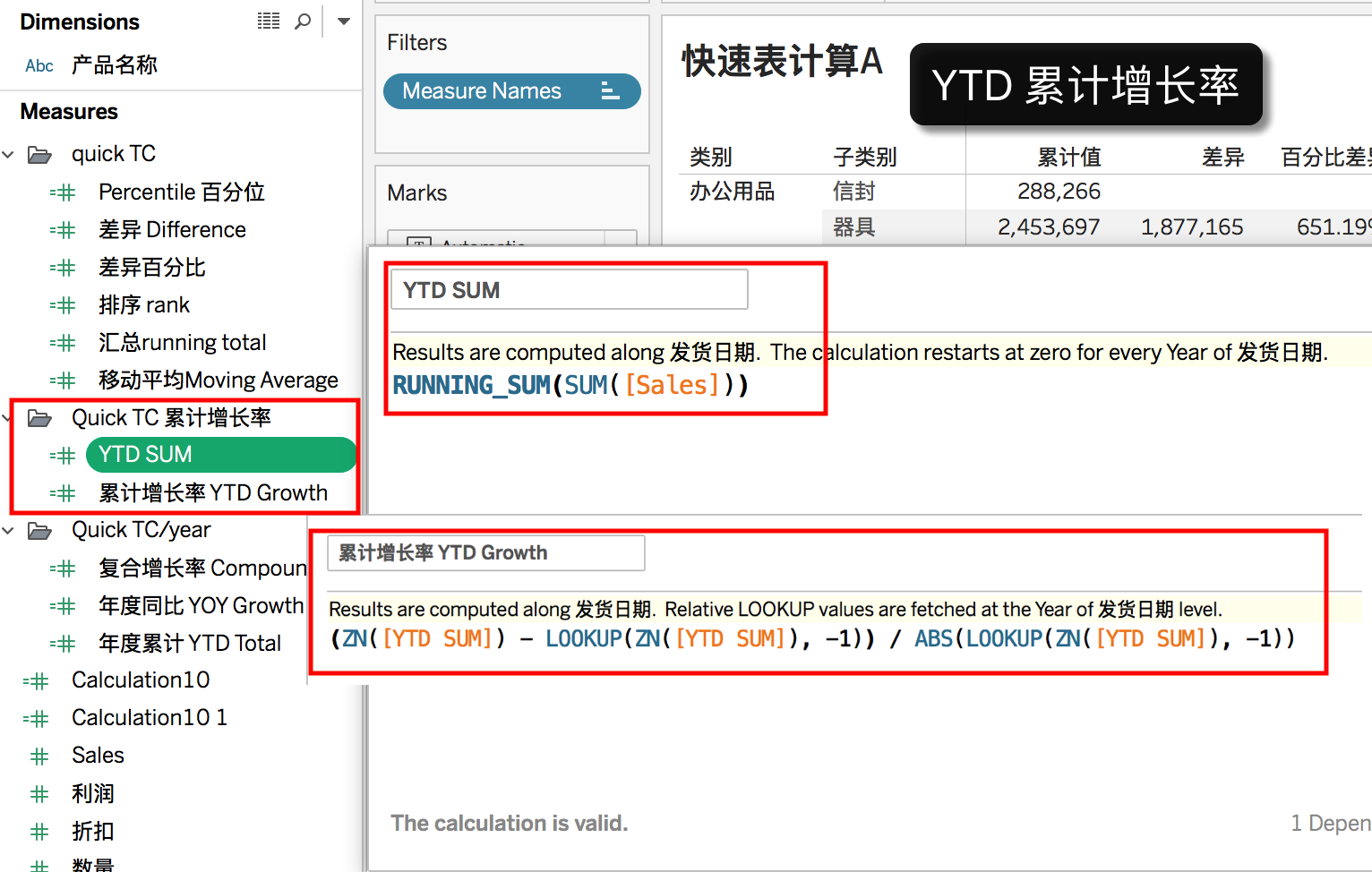
在表计算中,比较特殊的是最后一个“年度累计增长率”,YTD Growth ,当我们添加这个表计算,并拖入到度量中时,会发现度量中出现了两个计算字段,中文下是“计算10”和“计算10 1”(10代表的是第10次通过拖动生成计算字段),英文下就是“calculation 10”和“calculation 10 1”,为什么?因为年度累计增长率是二次表计算,虽然也可以在一个公式中表明,但这样更有助于用户看清楚。我们把两个表计算改为 “YTD SUM”计算累计绝对值,和“累计增长率YTD growth”两个字段。
- YTD SUM = RUNNING_SUM(SUM([Sales]))
- 累计同比 YTD Growth = (ZN([YTD SUM]) – LOOKUP(ZN([YTD SUM]), -1)) / ABS(LOOKUP(ZN([YTD SUM]), -1))
-
表计算函数
Tableau的表计算分为几类,重点是前面三类。
- 索引排序函数:index()、size()、first()、last() ——这四个不需要参数; rank()及延伸函数,如rank_dense(),rank_modified()等;
- 移动计算函数:running_x ,比如 running_sum, running_avg, running_max等;
- 范围计算函数:window_x,比如window_sum,window_avg,window_max,等
- R语言相关计算函数:script_bool()等(我没用过)。
1、聚合计算与表计算
sum() 是聚合计算,是基于数据源的计算,它的参数就是数据源的字段,比如 sum([sales]),它代表把数据源的每一行的数据都对[sales]字段执行累加计算;
而widown_sum(), running_sum(), total() 都是表计算函数,表计算的特征之一是基于视图中聚合数据的二次聚合计算,因此括号中的参数必须是聚合,比如说 total( sum([sales]) )。
- 聚合计算:对数据源行级别数据的聚合
- 表计算:对视图中数据聚合结果的二次聚合
2、total(expression)
total(expression) 、 running_sum(expression)这两个表计算的参数都只有一个,就是要执行视图中数据数据的二次聚合。比如
- TOTAL(SUM([数量]))
- RUNNING_SUM(SUM([数量]))
区别在于,total()是为每个分区返回同一个结果。我们知道,表计算的逻辑是 分区+寻址,total为各个分区求和,每个分区返回同一个数值。而running_sum()则可以为每个分区的每一行返回一个数值。前者是对聚合的聚合,后者这是对聚合的移动聚合。
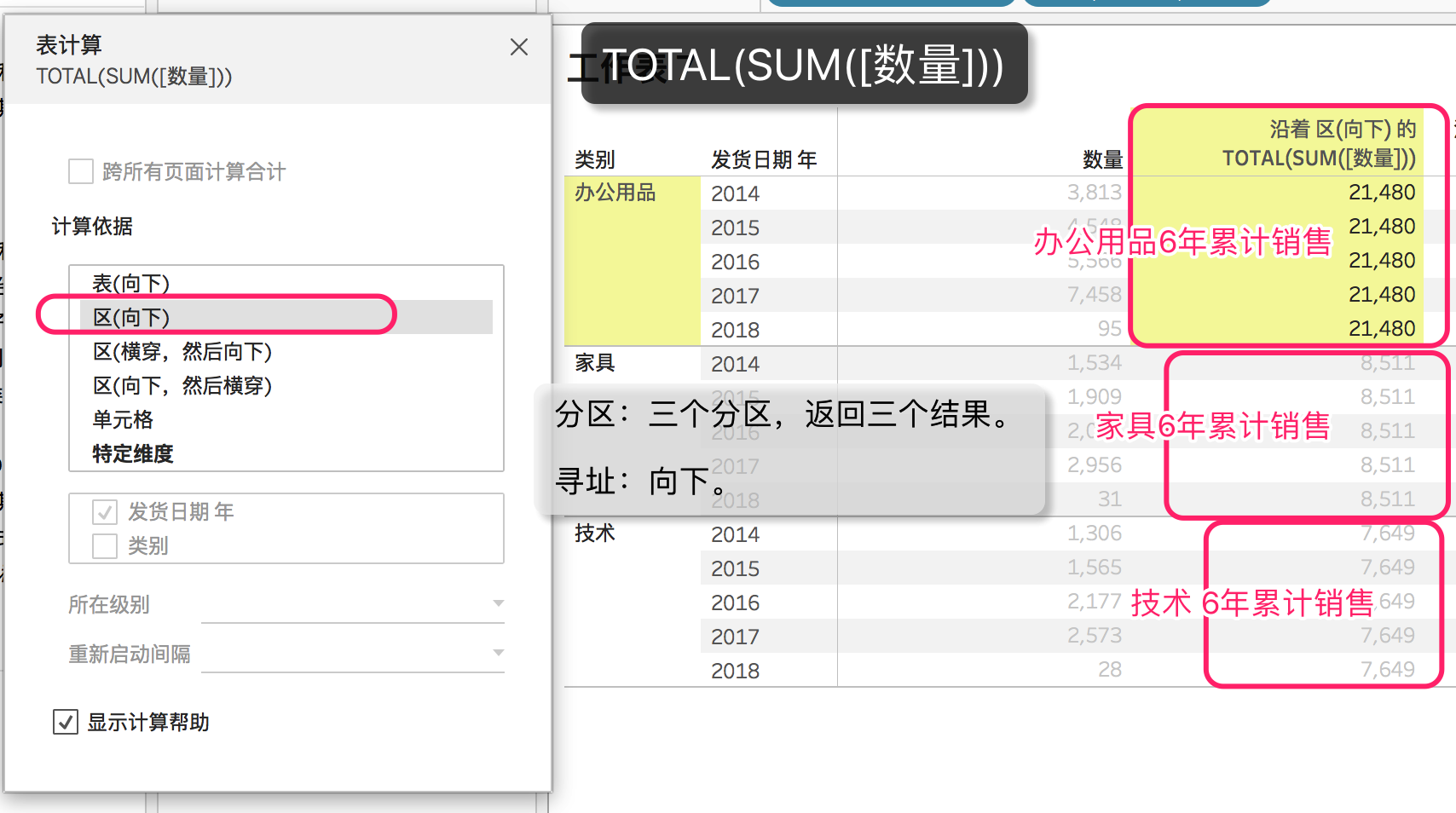
为了更好的理解total,可以参考一下“总计百分比”这个表计算,它的公式就是sum/total,也就是聚合除以聚合的聚合,从而计算每一行在分区中的占比;因此对于多个行数据而言,一个分区的total结果是一样的。
合计百分比 表计算 : SUM([数量]) / TOTAL(SUM([数量]))
3、 running_sum(expression)递归计算
我们看一下running_sum(),同样是分区和寻址,假定分区和上面total一样,也是每个类别一个分区;寻址也是向下。但是,对于同一个分区的不同行,running_sum()返回了不同的数值,这就是它的魅力。
在统计上,这就递归运算(recursion),递归运算的结果依赖于它自己。
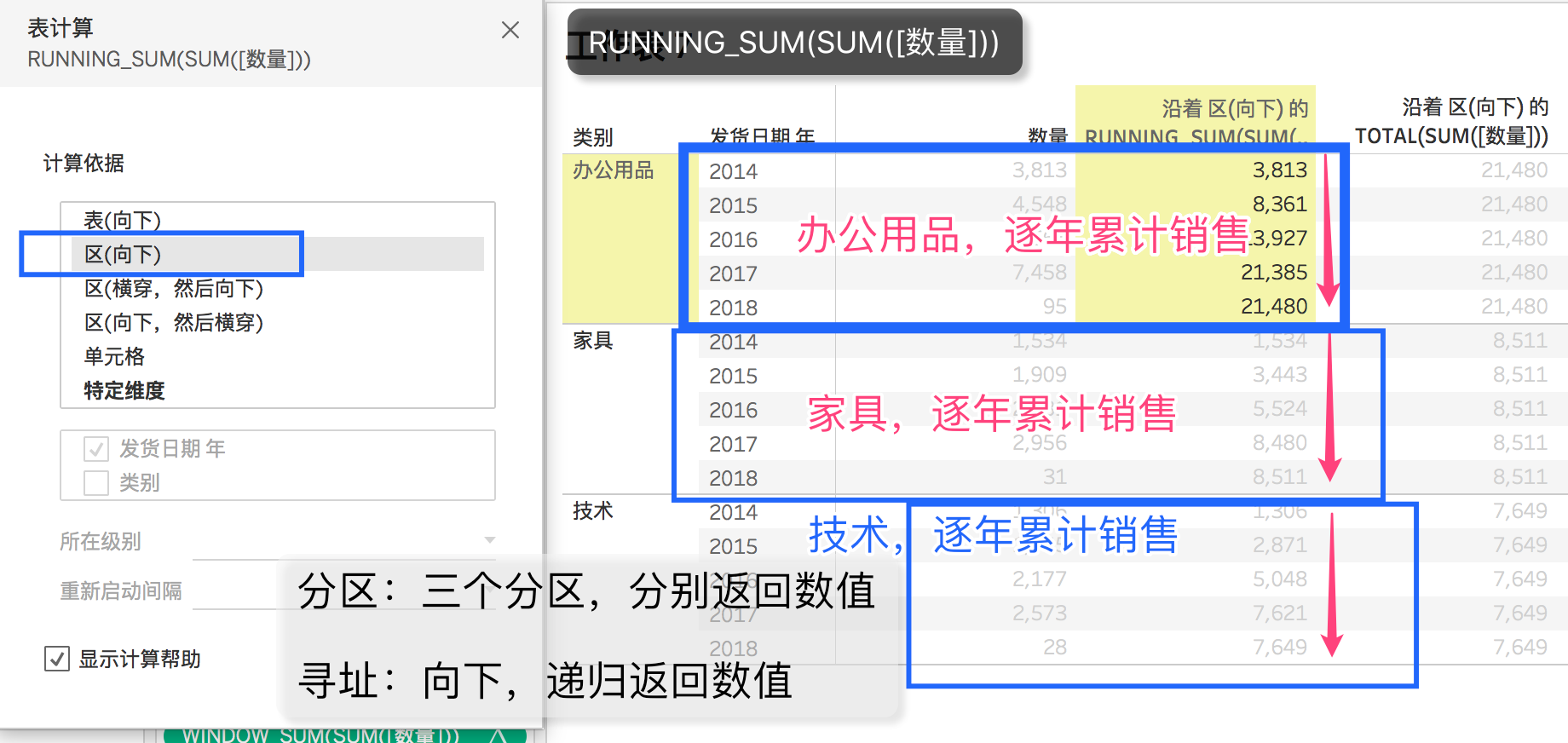
如果要在视图中计算随着时间增长的累计利润,或者累计会员数量,这种需求,只能通过表计算来完成。
4、window_sum(expression,[start,end] )
在手动表计算中,window_XXX函数是使用最多的,汇总计算、移动平均都是特殊情形下的窗口计算。窗口计算的重要特点是,默认有三个参数,分别代表聚合表达式、起始位置、结束位置。
- total 表计算相当于没有指定起止位置的window-sum窗口计算;
- running-sum表计算,即于从开始到当前位置的window-sum窗口计算;
- 移动平均,即制定了起止位置的的window-avg窗口计算。
完整的函数是window_sum(expression,[start,end] ),默认的起止位置用first和last代替,可以省略。
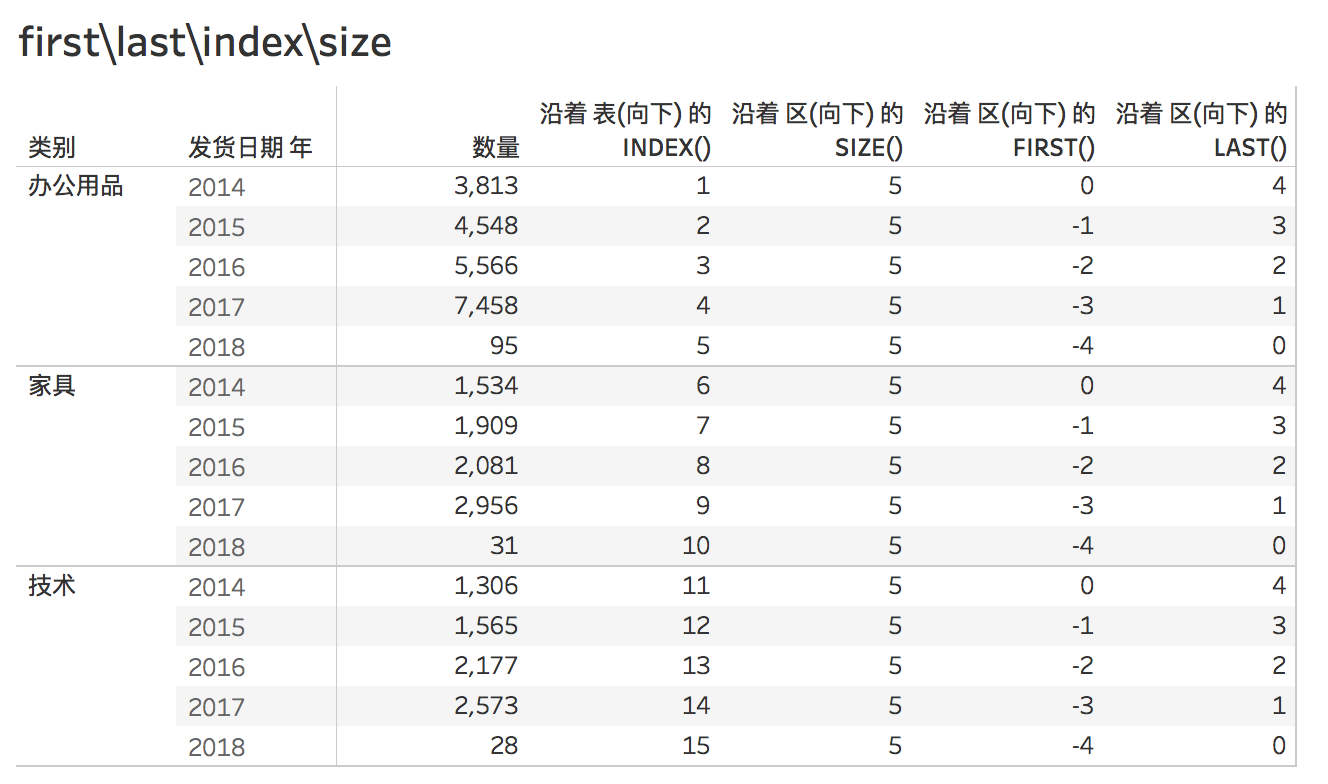
- first(),返回当前行到分区中第一行的偏移行数。
- last(),返回当前行到分区中最后一行的偏移行数。
first和last显示的是首行、尾行和相当于当前位置的偏移;如果是当前行,first和last都会返回的是0 。为了方便对比,我们和另外两个表计算 一起对比看看,
- size(),返回分区的行数;有点像total+count+分区,计算分区中行的计数。
- index(),返回分区的当前行的索引,与任何数值无关。
这四个表计算都不需要参数,完全依靠分区和寻址来控制。比如下图,index默认为表(向下),其他我们修改为区(向下),我们以类别为分区,看一下结果。 first和last正好是相对应的。
回来说window_sum(),没有起止范围的window_sum(),同一个分区情况下,结果和total()是一样的。
WINDOW_SUM(SUM([数量]),FIRST(),last()) = TOTAL(SUM([数量]))
我们写一个新的表计算,把last()改为0,绝对值0代表当前行的索引,也就是如下:
WINDOW_SUM(SUM([数量]),FIRST(), 0 )
这个的意思是说,返回分区中,从第一行到当前行的总计求和。我们看一下结果:
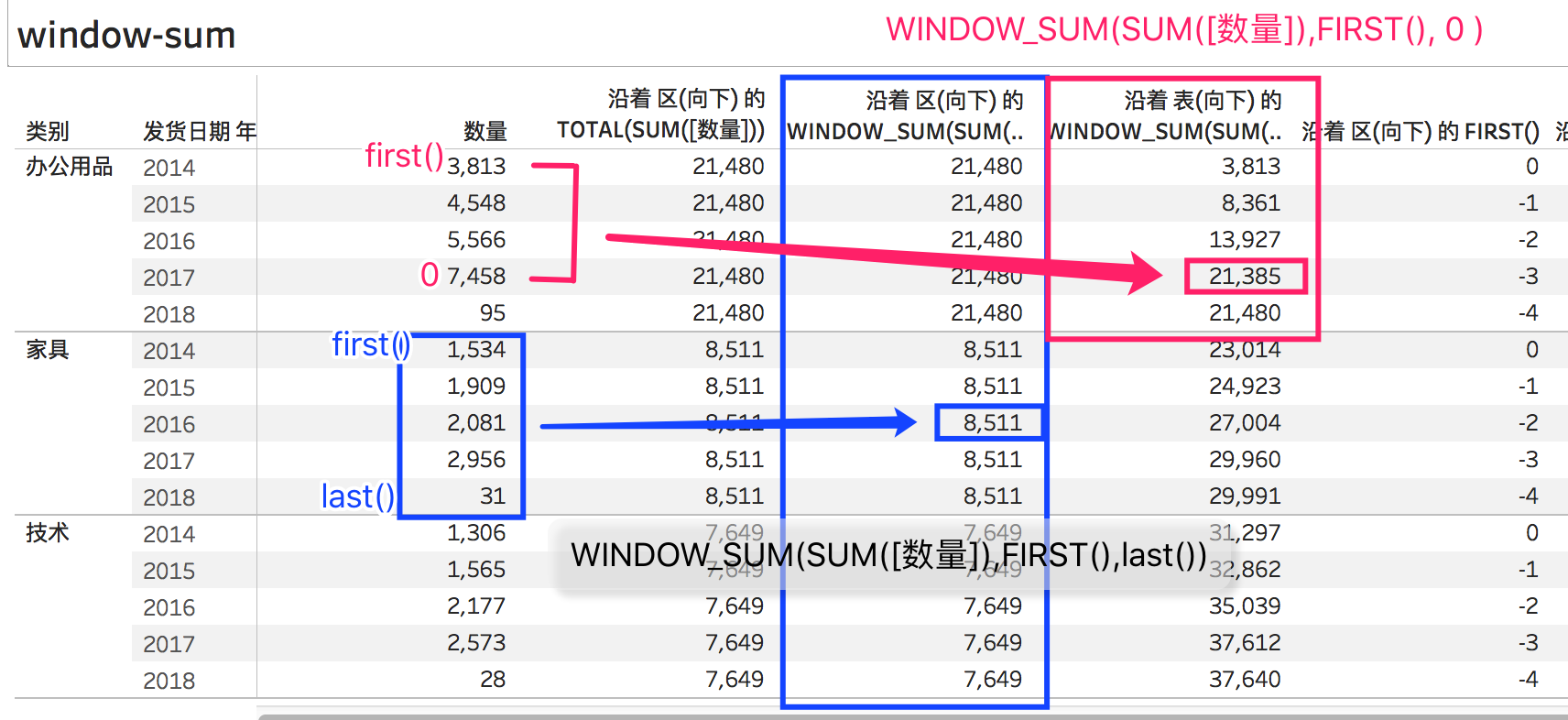
上面红色部分是到当前行的window_sum(),你也许会发现,这个结果,和running_sum()的结果是一样的。
从分区第一行,到当前行的总计求和(累计求和)
WINDOW_SUM(SUM([数量]),FIRST(), 0 ) = RUNNING_SUM(SUM([数量]))
换一个需求,如果我们要计算从当前行到最后一行的总计呢?那就是把first()改为0,以last结束,相当于runnig_sum()汇总+指定倒序运算。我们可以看一下对比图。
WINDOW_SUM(SUM([数量]),0,LAST())
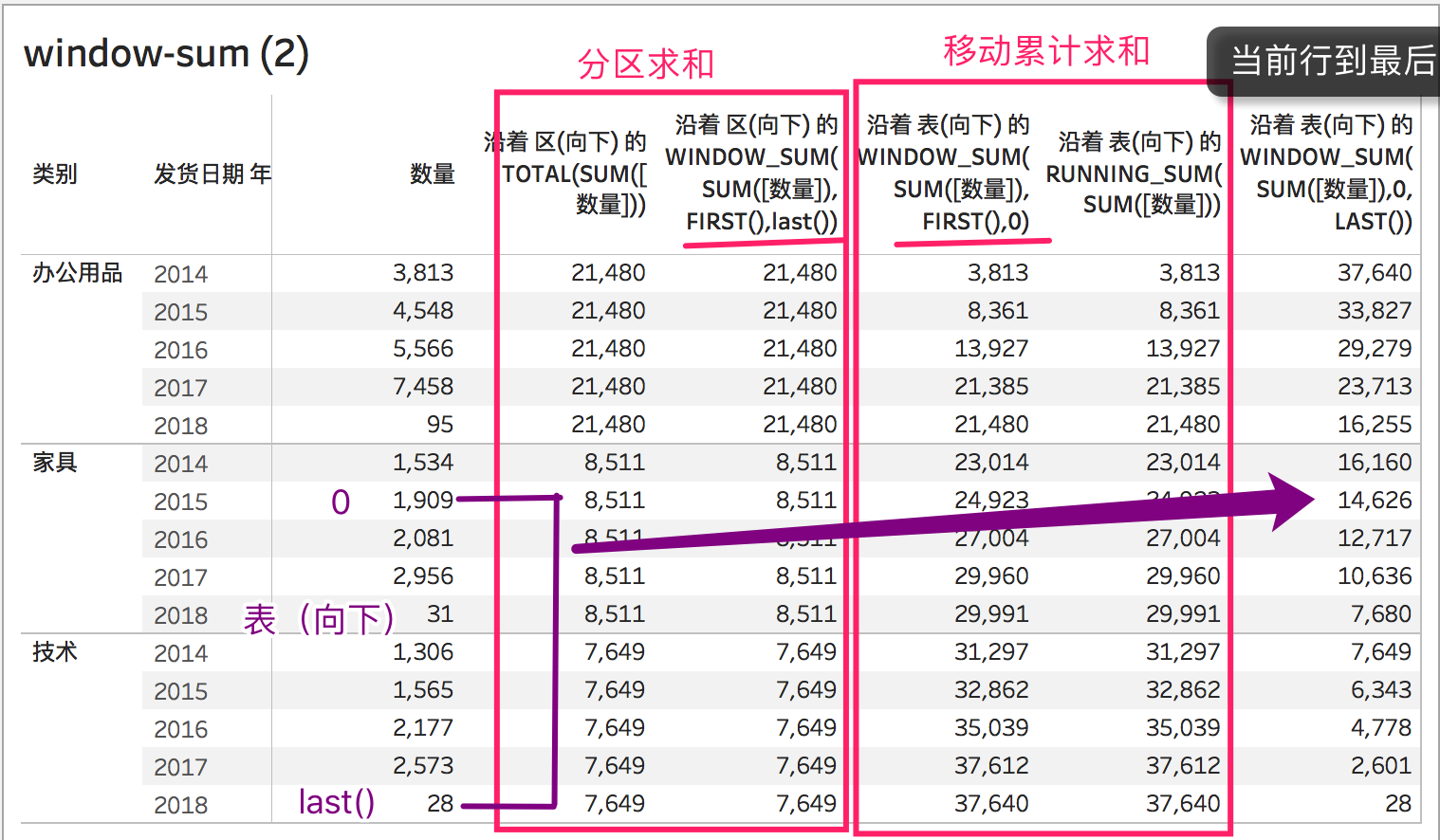
我们看一下上面的结果,最后一行,每一行的结果,返回的是当前行到最后一行last()的总计求和。

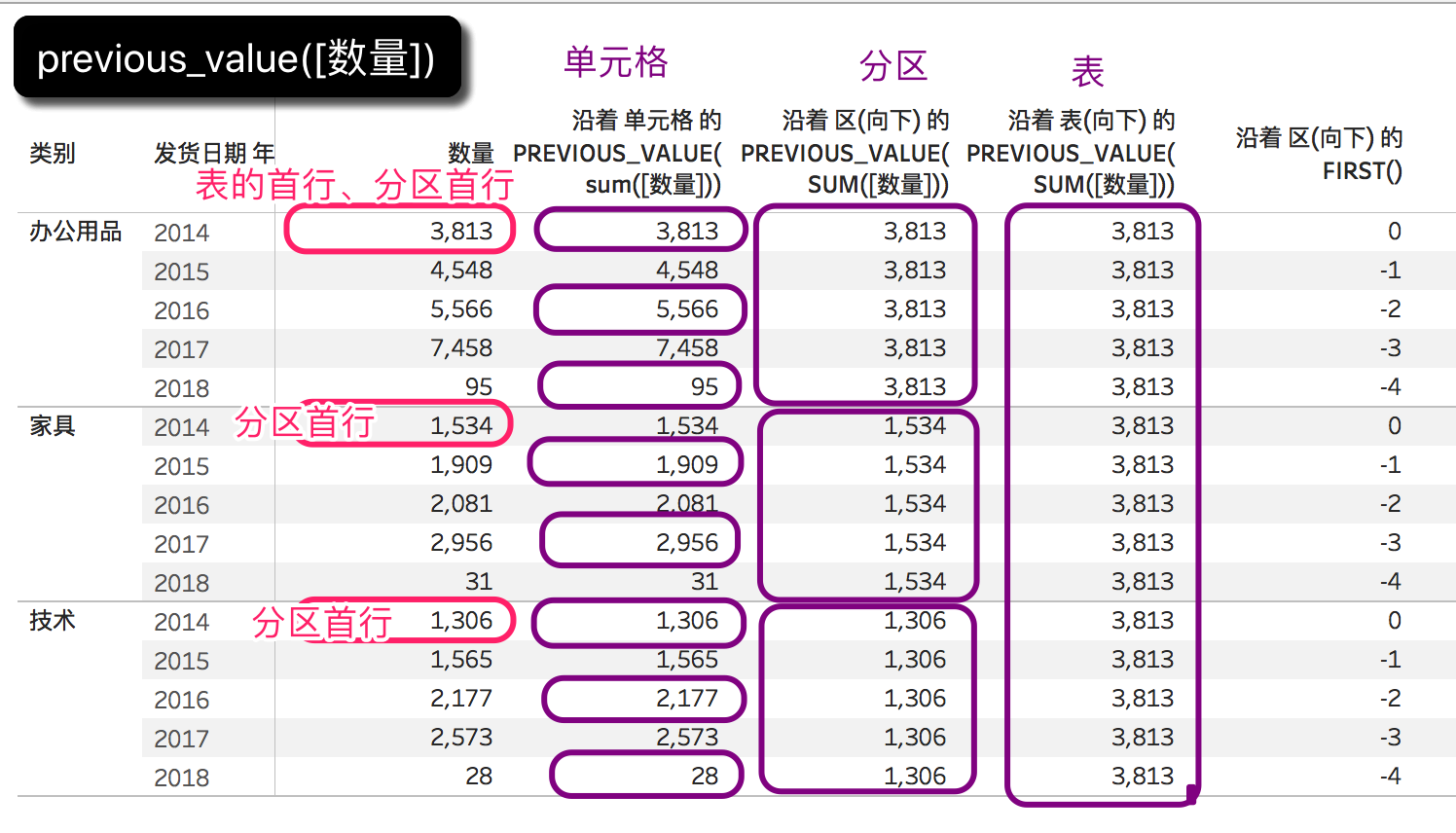
5、previous_value(expression) 返回前一个值
还有最后一个重要的表计算函数,那就是previous_value(expression),它用来返回此计算在上一行的值,如果当前行是首行,那就返回首行数值。我们做一个demo,分别设置不同的分区。
- 以单元格为分区,previous_value(expression)返回每个单元格数值;
- 以类别为分区,previous_value(expression)返回每个分区的首行;
- 以整个表为分区,previous_value(expression)返回整个表的首行。
-



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











