







摘要
图像描述模型通常遵循编码器-解码器架构,该架构使用抽象图像特征向量作为编码器的输入。最成功的的算法之一使用从目标检测器获得的region proposals中提取的特征向量(这里指的应该是Top-down那篇论文)。在本文中,作者介绍了Object Relation Transformer,它建立在这种方法的基础上,通过几何注意力显式地合并有关输入检测到的对象之间的空间关系的信息。定量和定性结果证明了这种几何关系对于图像描述的重要性,从而改进了MS-COCO数据集上所有常见的描述指标。代码在以下链接获取:代码地址
介绍
虽然基于目标检测的编码器代表了最先进的技术,但是目前它们没有利用有关检测到的对象之间的空间关系的信息,例如相对位置和大小。然而,这些信息通畅对于理解图像中的内容直观重要,并且被人类在推理物理世界时使用。例如:相对位置可以帮助区分“骑着马的女孩”和“站在马旁边的女孩”。同样,相对大小可以帮助区分“弹吉他的女人”和“弹尤克里里的女人”。正如以下文献所示,结合空间关系已被证明可以提高对象检测本身的性能。

此外,在机器翻译编码器中,位置关系通常被编码,特别是在基于注意力的编码器结构Transformer的情况下,因此,使用检测到的物体的相对位置和大小应该也有利于图像描述视觉编码器,如图1所示。

上图是本文作者提出的Object Relation Transformer中自注意力的可视化。检测到的对象及其边界框的透明度与相对于红色轮廓的椅子的注意力权重成正比。本文的模型将这把椅子与左边的同伴椅子,他们下面的海滩以及他们上面的雨伞强烈相关,这些关系显示在生成的标题中。
在这项工作中,作者提出并演示了使用object空间关系建模进行图像描述,特别是在Transformer编码器-解码器架构中。这是通过将上面文献9的Object Relation模块合并到Transformer中实现的。
本文的贡献
- 本文引入了Object Relation Transformer,这是一种专门为图像描述设计的编码器-解码器架构,它通过集合注意力合并了有关输入检测到的对象之间的空间关系的信息。
- 通过基线比较和MS COCO数据集的消融研究定量证明了几何注意力的有用性。
- 作者定性地表明,几何注意力可以改进描述,从而展示出增强的空间信息。
本文方法
本文的图形架构如下图2所示:作者首先使用目标检测器从图像中所有检测到的对象中提取外观和几何特征。此后,作者使用Object Relation Transformer来生成文本描述。
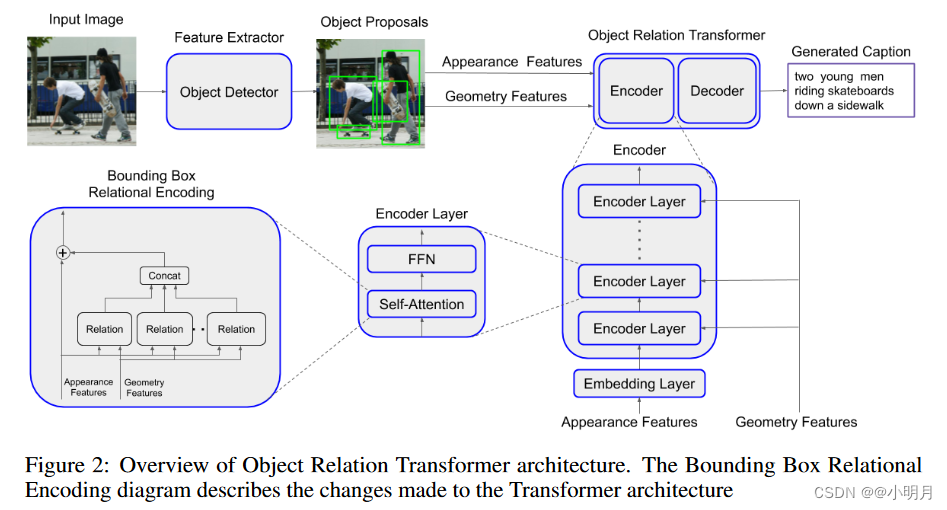
Object Detection
按照Bottom-UP and Top-Down这篇论文,作者使用Faster R-CNN和ResNet-101作为基础CNN进行目标检测和特征提取。使用ResNet-101的中间特征图作为输入,区域提议网络RPN生成object propasals的边界框。使用非极大值抑制,交并集(IoU)超过阈值0.7的重叠边界框将被丢弃,然后使用感兴趣区域region-of-interest(RoI)池化层将所有剩余的边界框转换为相同的空间大小(例如14×14×2048)。应用额外的CNN层来预测每个box proposal的类标签和边界框细化。进一步丢弃类预测概率低于阈值0.2的所有边界框。最后,作者在空间维度上应用均值池,为每个对象边界框生成2048维特征向量,然后将这些特征向量作为Transformer的输入。
Standard Transformer Model
Transformer模型由编码器和解码器组成,两者皆是多层结构。对于图像描述,本文的架构使用来自目标检测器的特征向量作为输入,并生成一系列单词作为输出。
每个图像特征向量先通过输入嵌入层进行处理,该层由一个全连接层组成,用于将维度从2048减少到
d
m
o
d
e
l
d_{model}
dmodel=512,然后是ReLU和dropout层。然后,嵌入的特征向量将用作Transformer模型的第一编码器层的输入tokens,作者将
x
n
x_n
xn表示为一组N个tokens中的第n个token。对于编码器层2到6,作者使用前一个编码器层的输出tokens作为当前层的输入。
每个编码器层由一个多头自注意力层和一个小型前馈神经网络组成。自注意力层本身由8个相同的头组成。首先计算Q,K,V。
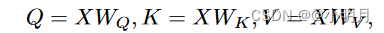
然后计算注意力权重,使用sacaled dot-product方法:
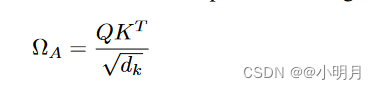
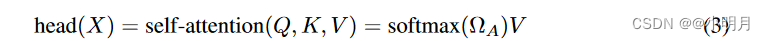
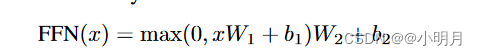
Obiect Relation Transformer
在作者提到的模型中,通过修改上式2中的注意力权重
Ω
A
Ω_A
ΩA来合并相对几何形状。作者将两个对象m和n的基于外观的注意力权重
ω
A
m
n
ω_A^{mn}
ωAmn乘以他们相对位置和大小的学习函数。作者使用文献9中首次引入的相同函数来改进Faster R-CNN目标检测器的分类和极大值抑制阶段。

首先,根据边界框m和n的几何特征(
x
m
x_m
xm,
y
m
y_m
ym,
w
m
w_m
wm,
h
m
h_m
hm)和(
x
n
x_n
xn,
y
n
y_n
yn,
w
n
w_n
wn,
h
n
h_n
hn)(中心坐标、宽度和高度)计算其位移向量γ(m,n):
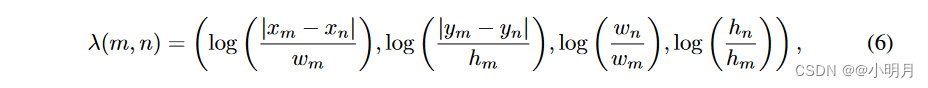
几何注意力权重计算为

其中Emb(·)按照Attention is all you need这篇论文中描述的函数P
E
p
o
s
E_{pos}
Epos计算高维嵌入,其中为每个γ(m,n)值计算正弦函数。此外,作者将嵌入与学习向量
W
G
W_G
WG相乘,以投影到标量并应用ReLU非线性。然后根据以下公式将集合注意力权重
ω
G
m
n
ω_G^{mn}
ωGmn纳入注意力机制中。
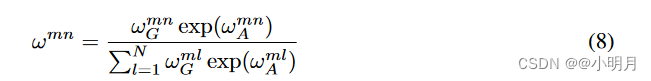
头部的输出可以计算为:
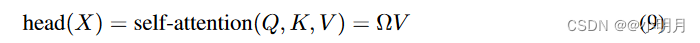
其中Ω是N×N矩阵,其元素由
ω
m
n
ω^{mn}
ωmn给出。
实验细节
本文的算法是在Pytorch中开发的,性能最佳的模型使用ADAM优化器进行了30个epoch的预训练,采用了softmax交叉熵损失,学习率如原始 Transformer论文中定义,具有20000个预热步骤,批量大小为10.使用自我批判强化学习优化CIDEr-D分数的30个周期,并提前停止以在验证集上获得最佳性能。
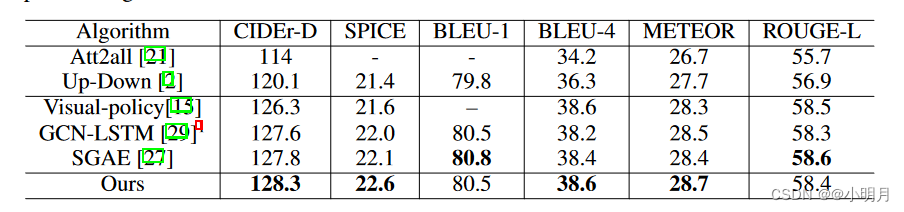
可视化结果




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









