







1.迭代器
//迭代器的迭代过程
Iterator it = a1.iterator()
while(it.hasNext()){
System.out.println(it.next());
}
//for循环不必循环的创建和释放栈内存空间,这种更节省空间内。
for(Iterator it=a1.iterator();it.hasNext();){
sout(it.next())
}
(1)接口型引用只能指向自己的子类对象,这个子类对象被封装在集合内部,通过集合的方法去获取。
(2)什么是迭代器?
-
其实它就是用于取出元素的一种方式。
-
它被封装在集合内部,可以直接对元素操作,因为不同的集合有不同的数据结构,所以它们有不同的操作数据方式,它们将操作数据元素的方式封装成内部类在集合中。
但是即便这样,他们也有操作数据元素的共性,如获取下一个元素,判断元素是否存在等等,所以提取它们等共性,即这些共性就是它们操作的元素符合的一种共同规则,这个规则就是迭代器,对外提供一个方法iterator。
2.Collection集合
(1)集合框架的详细结构如图所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fUNmLZLS-1632324785147)(C:\Users\阐禅\AppData\Roaming\Typora\typora-user-images\image-20210922144055533.png)]
(2)Collection集合有两个子接口(set和List),它们是collection集合的实现而不是继承。
(3)collection集合是单列集合,而map集合存储的是键值对,所以它存储的是双列集合。
(4)collection集合与collections集合的区别是:
-
collection是高度抽象的集合接口
-
collections是操作集合的工具类,它里面的方法都是静态的,它没有提供构造函数,不需要创建对象,因为它的对象中并未封装特有的数据。
它的特有方法有:sort()、max()、binarySearch()、synList()等方法。
3.List集合
(1)List集合共性总结:
- List集合底层是数组结构,它里面的元素是有序的,可以重复的。
- 因为它的底层是数组元素,每个集合元素都有索引,所以所有可以操作角标的方法都是该体系特有的方法。
add(index,element) //增加元素在某个位置
addAll(index,collectopn) //合并集合
remove(index) //根据下标删除元素
set(index,element) //修改元素
get(index) //获取元素
subList(from,to) //获取元素,包含头,不包含尾
-
ListIterator()方法(List特有):
因为在并发过程中,调用集合方法对同一组元素操作,一边添加元素,一边删除元素,会报错,并发修改异常,所以List继承了Iterator方法,它是List集合特有的迭代器子接口。
使用这个子接口可以在并发操作过程中操作元素,同时,它也有自己的特有方法:逆向遍历(hasProvious())。
(2)List作为接口,它有两个三个子接口:
- ArrayList(底层是数组数据结构)(查询快,增删慢,非线性安全的)
- LinkedList(底层是链表数据结构)(查询慢,增删快,非线性安全)
- vector(底层是数组数据结构)(增删和查询都慢,但是是线性安全的)
具体来说:
(3)ArrayList集合:(Jdk1.2出现)
- 它的默认长度是10,是可变长度的数组,在添加元素时,如果超出集合的范围,那么它会重新创建一个集合,集合的大小在原来的基础上扩大1.5倍,并将前集合中的元素复制过来。
- 它遵循List集合的特性,是有序的,可以通过get()方法获取元素。当遍历元素时,它可以使用迭代器遍历元素,而map集合没有迭代器,不能使用迭代器遍历元素。
- ArrayList不是线程安全的,方法间线程是不同步的,在单线程中使用,多线程中使用的话需要同步定义。但是在1.0出现的vector它是线程安全的。
(4)Vector集合:
- 它和ArrayList一样,底层是用数组实现的,它们都是有序集合。
- 与ArrayList不同的是:它是线程安全的,在数据增长扩容时,它每次扩容2.0倍。
- 由于各方面的不突出,以及数据增长时更耗费空间,所以在1.2时被ArrayList取代。
- 它特有的方法是通过枚举遍历集合。
(5)LinkedList集合:
- LinedList集合的底层是链表数据结构。
- 它只有自身的含义。
- 它的特有方法:
addFirst();
addList();
poll(); //删除元素,如果为空,返回空。
删除获取获取第一个或者最后一个元素,如果列表为空,会报错,NosuchElementException
4.Set集合
Set集合的特点:(单列集合)
-
set集合是无序的,它里面的元素是不能重复的。
-
它的存取元素的顺序是不一样的,因为实现它子类的数据结构不同。
-
set集合的功能和collection是一致的,没有特定的方法。
-
它的常用子接口有:hashSet和TreeSet
hashSet集合:
-
底层数据结构是哈希表结构。
-
它是无序的,即放入元素和取出元素是不一致的。同时它还是元素不可重复的集合。
-
关于它的存取元素:
在堆中定义一个集合,每个对象都有它的哈希值,然后在顶一个的集合中存入哈希值,但是存储的顺序并不是按照你存入的顺序定义,而是按照哈希值的大小存取(哈希值会自动排序)
在哈希表中,如果哈希值相同的话,它还有一次校验方式:equals判断元素是否相同,如果不是一个对象,但是哈希值相同,那么会在哈希表中相同位置向下顺延,生成一个链表。
-
关于判断元素是否相同:
元素存在哈希表中,如果元素的哈希值相同,那么会通过equals判断是否是同一个元素,如上面所说,如果同值不同对象,那么,向下顺延。
如果,根据哈希值判断你的对象是否下相同不符合你自己的心意,那么可以使用hashcode的返回值来自定义你的判断对象。如年龄或者名字都可以。
-
当使用contains()方法判断元素中是否存在某一个数字时,那么就会调用hashcode()方法和equals()方法。
-
ArrayList集合依赖的是equals方法,而hashSet依赖的是equlas和hashcode方法。
TreeSet集合:
(1)特点:
- 底层数据结构是二叉树。
- 相对于List集合来说,它是无序且唯一的。但是对于hashSet集合来说,它是有序的。
- 线程安全来说,它也是你非同步的。
- 它会按照元素中的元素进行排序,自然顺序(字母的自然顺序)。
(2)关于TreeSet集合的无序中的有序性:
- TreeSet集合往里存对象,必须具备比较性。
(3)关于排序的两种方法:
①让元素自身具备比较性,实现comparebale接口,强制让对象具有比较性,重写comparTo方法,自定义条件比较排序。主要条件相同按照次要条件比较,次要条件相同,则对象相同。String自己实现了Comapreable接口。
②当元素不具备比较性时,或者具备的比较性不是所需要的,这时就需要让集合自身具备比较性,在集合一初始化时就具备比较性。定义一个比较器,将比较对象作为参数传递TreeSet集合构造函数。
定义一个类,实现comparator,实现它的方法compare方法。
- 如果二者都具备比较性时,按照比较器来。
(4)关于TreeSet的存储:
- 排序无非就是相互比较,元素越多,比较的次数就越多,效率就越低,为了优化,TreeSet采用了二叉树的存储方式。
- 以进来的第一个元素为根结点,如果比结点大的则放在右子树的位置,如果比节点小,则放在左子树的位置,这样可以减少比较次数,提高效率。
- 二叉树元素多的话,如果从根节点开始遍历比较也是比较耗费时间的,所以在元素多了之后,它会自动采取折中取值(从中间向两别散发)。
(5)关于二叉树的取值:
- 取元素的时候从左子树 最下面开始,遍历(中序遍历)左子树–》根结点–》右子树(从小到大取)。
- 二叉树取值时如何存如何取,怎么才能做到?让comparTo方法返回1,那么二叉树都在右子树上,它按照从小到大排序,从小到大取。
- 二叉树的逆序:返回-1;
- 二叉树的元素的唯一性:compareTo返回0。
5.泛型
泛型概述
(1)集合中可以封装对象而不可以分装几倍呢数据类型,但是JDk1.5之后可以,因为Java可以让基本数据自动封装成基本数据封装类。
(2)泛型用户解决安全问题,是一个安全机制。
- 如果定义元素的时候就能明白是什么数据类型,就不会出现安全问题,如:类型强转问题(int---->String),提前定义好类型,如果出现类型问题,就会在编译器发现,而不必要等到运行时才发现。
(3)泛型的好处:
- 将classCastException转到了编译期,方便解决问题,让运行事情减少,比较安全。
- 集合使用迭代器取元素的时候,将元素取到迭代器中,迭代器也会出现不兼容的问题,所以迭代器中的类型也要提前定义好。
- 避免了强制转换的麻烦。
泛型类
(1)什么时候定义泛型?
- 当类中要操作的数据类型不确定时,早期(jdk1.5之前)使用Object来对完成扩展,现在定义泛型来完成扩展。
- 泛型在操作实限定了数据的类型,但是保证了数据的安全性。
(2)泛型方法
-
在类上定义的泛型在整个类中有效,为了让不同方法可以操作不同的类型,可以将泛型定义在方法上,那么泛型只在这个方法上有效。
-
在泛型类中定义泛型方法,泛型方法的类型可以与泛型类不同,但是,其他没有定义的方法都要遵循泛型类。
-
静态方法不可以访问类上定义的泛型,如果静态方法操作的数据类型不确定,可以将泛型定义在方法上,如:
public static <T> void method(T t){} //定义在返回值类型前面。
(3)泛型限定:
- 如在主函数中定义两个不同类型的泛型,用迭代器遍历集合,如给定迭代器的类型,就只能传递一个集合,但是使用通配符的话,可以传递不同的参数。
public static void PrintAll(ArrayList<?> a1){
Iterator<?> it =a1.iterator();
}
//如果定义成ArrayList<T>,则需要在返回值前面加一个<T>的类型,T代表一个具体的类型,?代表不明确的类型,表示一个占位符。
-
泛型限定的优劣:可以提高扩展性,但是不能使用类型特有的方法,多态也是同样如此。
-
泛型限定:使用泛型限定,可以打印一定范围的类,如:
ArrayList<? extend person> //能传递person以及它的子类。 上限定:? extend E------------(E或者它的子类) 下限定:?super E--------------(E类型或者它的父类型)
6.Map集合
map集合的特点:
-
双列集合。
-
该集合存储键值对,一对一的往里存,而且要保证键的唯一性。
-
常用的子类集合:hashMap、hashtable、TreeMap。
-
共性方法:put(),get()
可以通过get的返回值来判断一个键是否存在,特殊的HashMap可以存空键或者值,通过get(null)来判断这个值是否存在。
map.values(),返回一个集合collection
添加元素:如果出现添加元素相同的键时,那么后添加的值会覆盖掉原有键对应的值,并且put方法会返回被覆盖掉的值。
HashTable
特点:底层时哈希表数据结构,不可以存null值和键,该集合(从1.0出现)是线程同步的,线程安全的,效率比较低。
HashMap
- 底层是哈希表数据结构,并允许使用null值和键,线程不同步,效率比较高。
- 除了不允许使用空键值以及线程同步与否之外,hashMap和HashTable大致相同。
TreeMap
- 底层是二叉树数据类型结构,线程不同步,可以用于给map集合中的元素进行排序。
- 和set集合很像,其实set集合底层就是使用了二叉树结构。
Map共性方法
(1)keySet
- map集合没有迭代器,所以不能使用迭代方法。
- 通过keySet方法获取map集合中所有的key,将它存在set集合中,然后通过set集合的迭代器获取set集合中的元素的值。
(2)entrySet
- 将map集合中的映射关系存到set集合中,而这个数据类型的关系就是map.Entry
set<map.Entry<String,String>> entrySet=map.entrySet();
Iterator<map.Entry<String,String>> it =entrySet.iterator();
while(it.hasNext){
map.Entry<String,String> me=it.next();
key=me.getkey();
values=me.get(key);
}
- 这个映射关系就是map.Entry类型,那么关系对象map.Entry()获取到之后,就可以通过关系对象中的getkey和getvalues()来获取关系中的键和值。
- map.Entry中其实Entry也是一个接口,它是map接口中的内部接口。
(3)map练习:获取字符串中字母出现的次数,并按照顺序将之打印出来。
//获取字符串中字母出现的次数,并将它打印成a(2)b(3)....等的方式
package com.chanchan.java;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
import java.util.TreeMap;
public class getString {
public static void main(String[] args) {
System.out.println(getstr( "abcbcdacg" ));
}
public static String getstr(String str) {
//第一步,将字符串转化成字符数组
char[] chars = str.toCharArray();
//出啊构建一个集合,用来存储字符以及它们的映射关系
//因为字符串和出现的次数是映射关系,字符出现也有顺序,所以使用treeMap集合来存储
//同时,集合中存储的都是对象的引用类型,所以要将对象的基本数组类型转化成他们的封装数据类型
TreeMap<Character,Integer> tm=new TreeMap<Character, Integer>();
//第二步,遍历数组元素,将数组元素存入对应的集合中,首先要进行判断
int count=0; //这个count也可以放在里面,但是这样的话耗费内存,每次都开辟内存再释放,开辟释放循环.
for(int i=0;i<chars.length;i++){
//如果字符串中出现了非字母元素,可以添加一层判断,去除掉非字母元素.
if(!(chars[i] >'a' &&chars[i]<'z' || chars[i]>'A' && chars[i]<'Z') )
continue;
//判断数组中的元素在集合中是否存在,如果不存在,添加,如果存在,取出key让key加一,再将元素重新存入
Integer value=tm.get( chars[i] );
/*
if (tm.get(chars[i])==null){
tm.put( chars[i],1 );
}else {
value=value+1;
tm.put( chars[i],value );
}
*/
if(value!=null) //优化后的结果
count=value;
count++;
tm.put( chars[i],count );
count=0; //每次调用过程之后清零
}
System.out.println(tm);
//定义一个StringBuilder
StringBuilder sb=new StringBuilder();
//将字符串存储在集合之后,在打印出来,使用StringBuilder,首先要遍历这个集合,使用entrySet方法
//使用entrySet方法,将map的数据银蛇关系存储到set集合中
Set<Map.Entry<Character, Integer>> entr = tm.entrySet();
//通过迭代器遍历set集合
Iterator<Map.Entry<Character, Integer>> it = entr.iterator();
while (it.hasNext()){
Map.Entry<Character,Integer> ch= it.next();
Character key = ch.getKey();
Integer value = ch.getValue();
sb.append( key+"("+value+")" );
}
return sb.toString();
}
}
7.集合框架总结比较
-
Map接口和collection接口是所有集合框架的父接口,如图(引用牛客上的一个大佬的图):
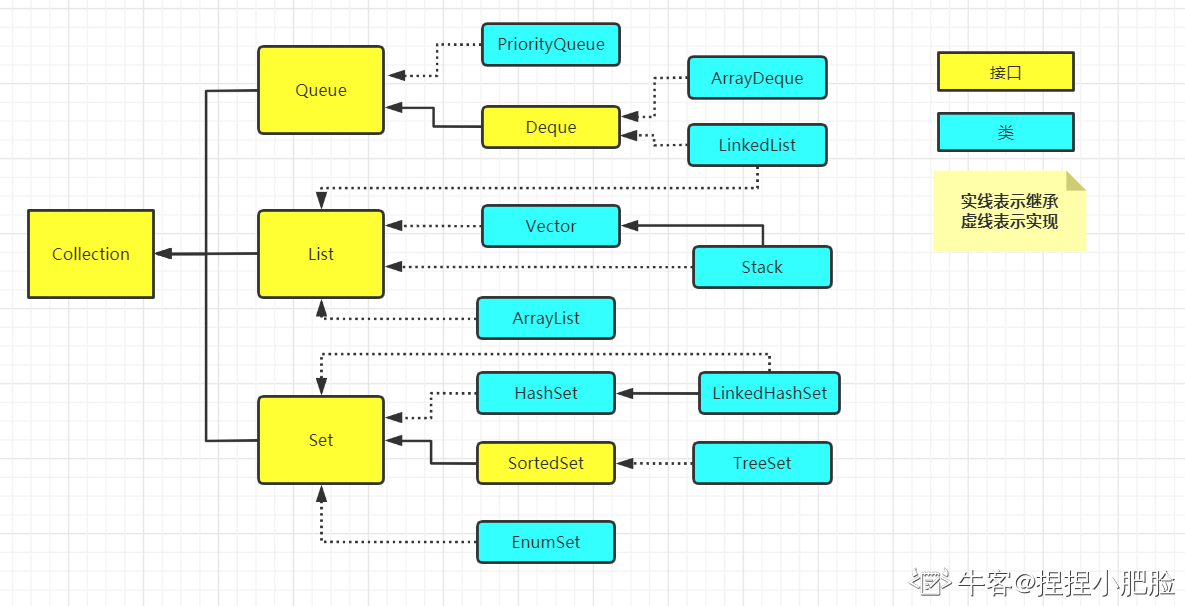
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5yBdoOdz-1632324785154)(file://C:\Users\阐禅\AppData\Roaming\Typora\typora-user-images\image-20210922144055533.png?lastModify=1632322833)]
(1)List、map、set集合的区别:
- List:有序集合(存取的顺序一样,而不是按照某种特性排列的),元素不唯一,可以存储多个重复元素,可以存储多个null值。
- set:无序集合(存取的顺序不一定相同,因为它是按照hashcode存取数据元素的),元素唯一,只能存取一个null值。
- map:存取的是双列集合(kv键值对),key是唯一的,value不是唯一的。它的接口子类hashmap可以存取null值。
(2)常用结合框架底层数据结构:
-
List
- ArrayList:数组
- LinkedList:双线链表
- vector:数组
-
set:
- hashSet:哈希表
- TreeSet:二叉树(红黑树)
-
map:
(3)哪些集合类是线程安全的?
- 实现了List接口的vector
- 实现了map接口的hashTable
- stack(继承自vector)
- 枚举(Enumeration)














 133
133











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









