







错误描述
Tesseract-OCR的英文识别模式(leng='eng')可以运行,但中文简体模式及其他语言模式不行,比如:
pytesseract.image_to_string(im_crop,lang = 'chi_sim') TesseractError: (1, 'Error opening data file C:\\Program Files\\Tesseract-OCR\\tessdata\\chi_sim.traineddata Please make sure the TESSDATA_PREFIX environment variable is set to your "tessdata" directory. Failed loading language \'chi_sim\' Tesseract couldn\'t load any languages! Could not initialize tesseract.')
尝试解决
按报错提示和网上教程添加环境变量:

![]()
但并没有解决...
最终解决
重新下载所需要的.traineddata文件,在tessdata文件中替换原来的,运行成功!https://github.com/tesseract-ocr/tessdata![]() https://github.com/tesseract-ocr/tessdata
https://github.com/tesseract-ocr/tessdata
原因探讨
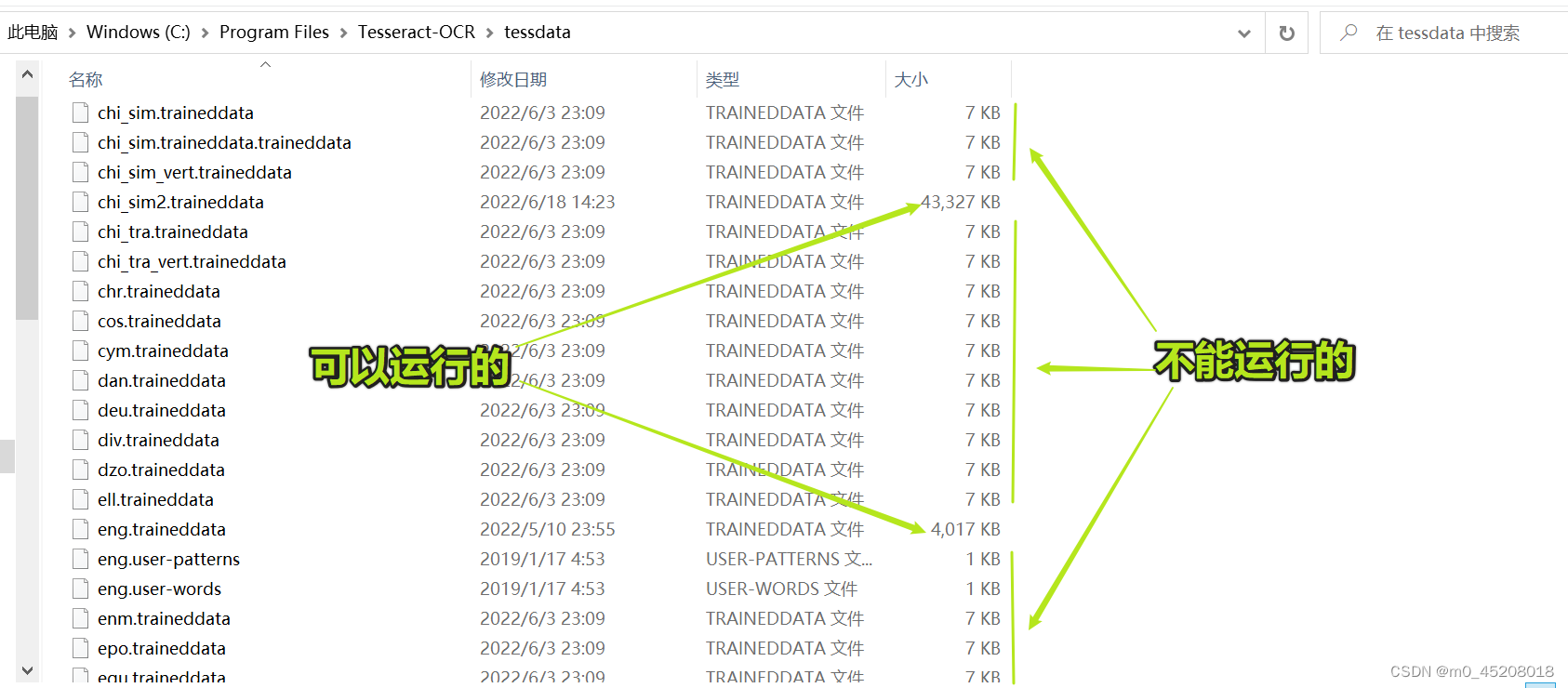
我的tessdata中的文件都是安装Tesseract-OCR时自动生成的,虽然看起来想要的traineddata格式的文件它都有,但除了eng.traineddata外,每个都只有7kb,而在Github上下载则发现每个文件需40兆左右......于是才猜到是文件的问题,只是不知道为什么会一直报环境变量的错。















 338
338











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









