






一 myBatis常用语法
文档来源参考:https://www.yuque.com/docs/share/a2c36605-0b21-4ad7-adf3-46178613f3b5?# 《crud》
基于xml实现单表CRUD
SQL片段 : 提高代码重用性,简化开发
<sql id="baseColumn">
id,username,real_name,password,phone,email,idcard,birthday,utype
</sql>
添加
<!‐‐ int save(User user); 添加用户并返回主键 ‐‐>
<insert id="save" parameterType="User" useGeneratedKeys="true"keyProperty="id">
INSERT INTO t_user(id,username,real_name,password,phone,
email,idcard,birthday,utype)
VALUE(#{id},#{username},#{realName},#{password},
#{phone},#{email},#{idcard},#{birthday},#{utype})
</insert>
添加并返回主键
<insert id="save2" parameterType="User">
<!‐‐ 指定主键生成策略封装 ‐‐>
<selectKey keyColumn="id" keyProperty="id" order="AFTER" resultType="long">
SELECT LAST_INSERT_ID()
</selectKey>
INSERT INTO t_user(<include refid="baseColumn"/>)
VALUE(#{id},#{username},#{realName},#{password},
#{phone},#{email},#{idcard},#{birthday},#{utype})
</insert>
删除
<!‐‐ int deleteById(Long id); //删除用户 ‐‐>
<delete id="deleteById" parameterType="long">
DELETE FROM t_user WHERE id=#{value}
</delete>
更新 (全字段更新,要求每个字段都要有,使用局限性较大)
<!‐‐ int updateById(User user); //更新用户 ‐‐>
<update id="updateById" parameterType="User">
UPDATE t_user SET
username=#{username},
real_name=#{realName},
password=#{password},
phone=#{phone},
email=#{email},
idcard=#{idcard},
birthday=#{birthday},
utype=#{utype}
WHERE id=#{id}
</update>
简单单表查询
1. 根据id查询单个对象
<!‐‐ User findById(Long id); //根据id来查询 ‐‐>
<select id="findById" parameterType="long" resultType="User">
SELECT <include refid="baseColumn"/> FROM t_user WHERE id=#{id}
</select>
2. 查询所有
<!‐‐ List<User> findAll(); // 查询所有 ‐‐>
<select id="findAll" resultType="User">
SELECT <include refid="baseColumn"/> FROM t_user
</select>
3. 模糊查询
<!‐‐ List<User> findLikeUsername(String username); //根据用户名来模糊查询 ‐‐>
<select id="findLikeUsername" parameterType="string" resultType="User">
SELECT <include refid="baseColumn"/> FROM t_user
WHERE username LIKE #{username}
</select>
<!‐‐ List<User> findLikePhone(String phone); //根据手机号来模糊查询 ‐‐>
<!‐‐SQL注入: select * from t_user where 1=1 OR (user=? and pwd=? an
d utype=?)
${value} : 显示出具体的内容(不带" ",直接显示内容,会导致SQL注入)
#{phone} : 解析成 ? (占位符的替换, 以 "内容" 被填充),防止SQL注入
${value} 使用场景
select ... from report_${year} where kw like '%关键字%' ORDER BY ${orderCondition};
‐‐>
<select id="findLikePhone" parameterType="string"
resultType="User">
SELECT <include refid="baseColumn"/> FROM t_user
WHERE phone LIKE CONCAT('%',#{phone},'%')
<!‐‐ WHERE phone LIKE '%${value}%' ‐‐>
<!‐‐ WHERE phone LIKE "%"#{phone}"%" ‐‐>
</select>
4. 查询总记录数
<!‐‐ Long findCount(); // 查询总记录数 ‐‐>
<select id="findCount" resultType="long">
SELECT COUNT(*) FROM t_user
</select>单表易错查询
1. 多个入参 (<select> 中的入参类型不指定)
接口 : User findRealnameAndPhone(@Param("realname")String realna
me,@Param("phone")String phone); //根据真实姓名及手机号查询
<select id="findRealnameAndPhone" resultType="User">
SELECT <include refid="baseColumn"/> FROM t_user WHERE real_name=#{realname}
and phone=#{phone}
<!‐‐ SELECT <include refid="baseColumn"/> FROM t_user WHERE real_name=#{param1} and
phone=#{param2} ‐‐>
<!‐‐ SELECT <include refid="baseColumn"/> FROM t_user WHERE real_name=#{0}
and phone=#{1} ‐‐>
</select>
2. 查询记录以map形式返回
@MapKey("id") // 将查询到的id列的值作为map中的key
Map<Integer, Employee> findEmpById(Integer id);
<select id="findEmpById" parameterType="int" resultType="com.h
wua.entity.Employee">
SELECT <include refid="baseColumn"/> FROM crm_emp WHERE id=#{id}
</select>二 连接
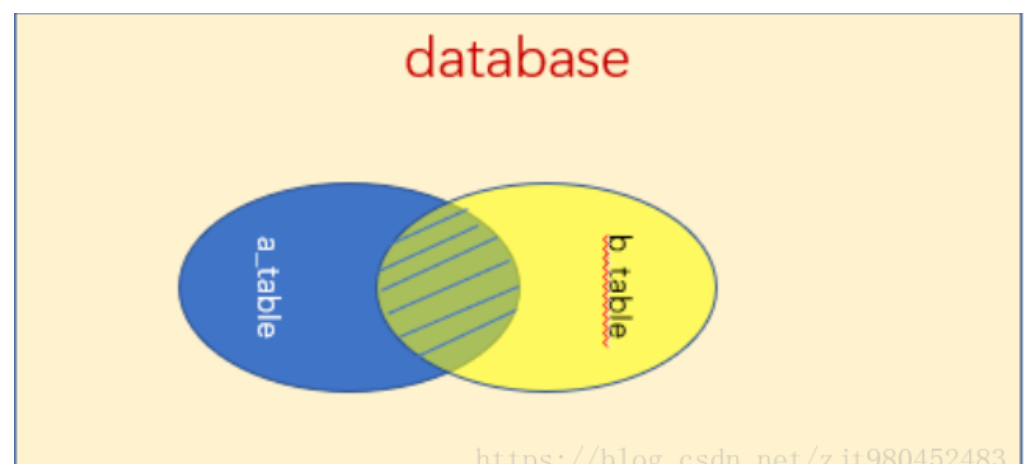
2.1内连接 inner join
关键字:inner join on
语句:select * from a_table a inner join b_table b on a.a_id = b.b_id;
说明:组合两个表中的记录,返回关联字段相符的记录,也就是返回两个表的交集(阴影)部分。
2.2左连接 left join
关键字:left join on / left outer join on
语句:SELECT * FROM a_table a left join b_table b ON a.a_id = b.b_id;
说明: left join 是left outer join的简写,它的全称是左外连接,是外连接中的一种。 左(外)连接,左表(a_table)的记录将会全部表示出来,而右表(b_table)只会显示符合搜索条件的记录。右表记录不足的地方均为NULL。
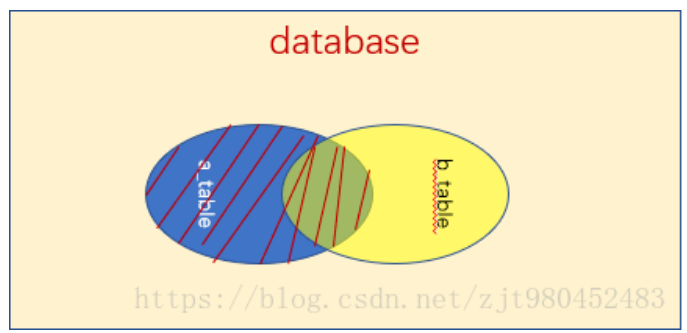
2.3右连接 right join
关键字:right join on / right outer join on
语句:SELECT * FROM a_table a right outer join b_table b on a.a_id = b.b_id;
说明:right join是right outer join的简写,它的全称是右外连接,是外连接中的一种。与左(外)连接相反,右(外)连接,左表(a_table)只会显示符合搜索条件的记录,而右表(b_table)的记录将会全部表示出来。左表记录不足的地方均为NULL。
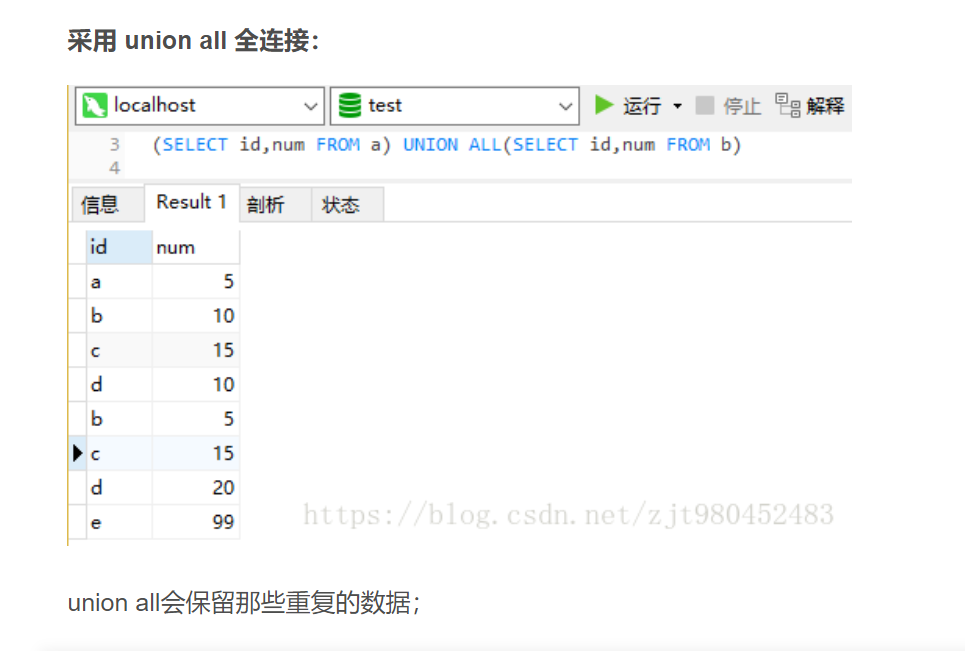
2.4全连接 union
关键字:union /union all
语句:(select colum1,colum2...columN from tableA ) union (select colum1,colum2...columN from tableB )
或 (select colum1,colum2...columN from tableA ) union all (select colum1,colum2...columN from tableB );
union语句注意事项:
1.通过union连接的SQL它们分别单独取出的列数必须相同;
2.不要求合并的表列名称相同时,以第一个sql 表列名为准;
3.使用union 时,完全相等的行,将会被合并,由于合并比较耗时,一般不直接使用 union 进行合并,而是通常采用union all 进行合并;
4.被union 连接的sql 子句,单个子句中不用写order by ,因为不会有排序的效果。但可以对最终的结果集进行排序;
eg:
(select id,name from A order by id) union all (select id,name from B order by id); //没有排序效果(select id,name from A ) union all (select id,name from B ) order by id; //有排序效果
![9ESQ]L9L(CION`J1N%7KBPC.png](https://img-blog.csdnimg.cn/img_convert/e8448647e9f97f1b2d3cdfe8a7716e12.png)
三 常用函数
1、CONCAT(str1,str2,...)
返回来自于参数连结的字符串。如果任何参数是NULL,返回NULL。可以有超过2个的参数。一个数字参数被变换为等价的字符串形式。select CONCAT('My', 'S', 'QL');--'MySQL'
select CONCAT('My', NULL, 'QL'); -> NULL
2 LENGTH(str) 返回字符串str的长度。
select LENGTH('text'); -> 43 LOCATE(substr,str) 和 POSITION(substr IN str)
返回子串substr在字符串str第一个出现的位置,如果substr不是在str里面,返回0.select LOCATE('bar', 'foobarbar'); -> 4
select LOCATE('xbar', 'foobar'); -> 0LOCATE(substr,str,pos)
返回子串substr在字符串str第一个出现的位置,从位置pos开始。如果substr不是在str里面,返回0。
select LOCATE('bar', 'foobarbar',5); -> 74 INSTR(str,substr)
返回子串substr在字符串str中的第一个出现的位置。这与有2个参数形式的LOCATE()相同,除了参数 被颠倒。
select INSTR('foobarbar', 'bar'); -> 4
select INSTR('xbar', 'foobar');-> 05 LPAD(str,len,padstr)
返回字符串str,左面用字符串padstr填补直到str是len个字符长。
mysql> select LPAD('hi',4,'??');
-> '??hi'6 RPAD(str,len,padstr)
返回字符串str,右面用字符串padstr填补直到str是len个字符长。
mysql> select RPAD('hi',5,'?');
-> 'hi???'
7 LEFT(str,len)
返回字符串str的最左面len个字符。
mysql> select LEFT('foobarbar', 5);
-> 'fooba'8 RIGHT(str,len)
返回字符串str的最右面len个字符。
mysql> select RIGHT('foobarbar', 4);
-> 'rbar'
9 SUBSTRING(str,pos,len)
从字符串str返回一个len个字符的子串,从位置pos开始。使用FROM的变种形式是ANSI SQL92语法。
mysql> select SUBSTRING('Quadratically',5,6);
-> 'ratica'
10 LTRIM(str)
返回删除了其前置空格字符的字符串str。
mysql> select LTRIM(' barbar');
-> 'barbar'11 RTRIM(str)
返回删除了其拖后空格字符的字符串str。
mysql> select RTRIM('barbar ');
-> 'barbar'12 TRIM(str)
mysql> select TRIM(' bar ');
-> 'bar'13 SPACE(N)
返回由N个空格字符组成的一个字符串。
mysql> select SPACE(6);
-> ' '14 REPLACE(str,from_str,to_str)
返回字符串str,其字符串from_str的所有出现由字符串to_str代替。
mysql> select REPLACE('www.mysql.com', 'w', 'Ww');
-> 'WwWwWw.mysql.com'
15 REPEAT(str,count)
返回由重复countTimes次的字符串str组成的一个字符串。如果count <= 0,返回一个空字符串。如果str或count是NULL,返回NULL。
mysql> select REPEAT('MySQL', 3);
-> 'MySQLMySQLMySQL'
16 REVERSE(str)
返回颠倒字符顺序的字符串str。
mysql> select REVERSE('abc');
-> 'cba'
17 INSERT(str,pos,len,newstr)
返回字符串str,在位置pos起始的子串且len个字符长得子串由字符串newstr代替。
mysql> select INSERT('Quadratic', 3, 4, 'What');
-> 'QuWhattic
18 ELT(N,str1,str2,str3,...)
如果N= 1,返回str1,如果N= 2,返回str2,等等。如果N小于1或大于参数个数,返回NULL。
mysql> select ELT(1, 'ej', 'Heja', 'hej', 'foo');
-> 'ej'
mysql> select ELT(4, 'ej', 'Heja', 'hej', 'foo');
-> 'foo'
19 FIELD(str,str1,str2,str3,...)
返回str在str1, str2, str3, ...清单的索引。如果str没找到,返回0。FIELD()是ELT()反运算。
mysql> select FIELD('ej', 'Hej', 'ej', 'Heja', 'hej', 'foo');
-> 2
mysql> select FIELD('fo', 'Hej', 'ej', 'Heja', 'hej', 'foo');
-> 0
20 LOWER(str)
返回字符串str,根据当前字符集映射(缺省是ISO-8859-1 Latin1)把所有的字符改变成小写。该函数对多字节是可靠的。
mysql> select LCASE('QUADRATICALLY');
-> 'quadratically'
21 UPPER(str)
返回字符串str,根据当前字符集映射(缺省是ISO-8859-1 Latin1)把所有的字符改变成大写。该函数对多字节是可靠的。
mysql> select UCASE('Hej');
-> 'HEJ'
---------------------------------------------------------------------------------------------------------------------------------------------------mysql 时间函数:
1 DAYOFWEEK(date)
返回日期date的星期索引(1=星期天,2=星期一, ……7=星期六)。这些索引值对应于ODBC标准。
mysql> select DAYOFWEEK('1998-02-03');
-> 32 WEEKDAY(date)
返回date的星期索引(0=星期一,1=星期二, ……6= 星期天)。
mysql> select WEEKDAY('1997-10-04 22:23:00');
-> 5
3 DAYOFMONTH(date)
返回date的月份中日期,在1到31范围内。
mysql> select DAYOFMONTH('1998-02-03');
-> 34 DAYOFYEAR(date)
返回date在一年中的日数, 在1到366范围内。
mysql> select DAYOFYEAR('1998-02-03');
-> 34
5 MONTH(date)
返回date的月份,范围1到12。
mysql> select MONTH('1998-02-03');
-> 26 DAYNAME(date)
返回date的星期名字。
mysql> select DAYNAME("1998-02-05");
-> 'Thursday'7 MONTHNAME(date)
返回date的月份名字。
mysql> select MONTHNAME("1998-02-05");
-> 'February'8 QUARTER(date)
返回date一年中的季度,范围1到4。
mysql> select QUARTER('98-04-01');
-> 29 WEEK(date)
10 WEEK(date,first)
对于星期天是一周的第一天的地方,有一个单个参数,返回date的周数,范围在0到52。2个参数形式WEEK()允许你指定星期是否开始于星期天或星期一。如果第二个参数是0,星期从星期天开始,如果第二个参数是1,从星期一开始。
mysql> select WEEK('1998-02-20');
-> 7
mysql> select WEEK('1998-02-20',0);
-> 7
mysql> select WEEK('1998-02-20',1);
-> 811 YEAR(date)
返回date的年份,范围在1000到9999。
mysql> select YEAR('98-02-03');
-> 199812 HOUR(time)
返回time的小时,范围是0到23。
mysql> select HOUR('10:05:03');
-> 1013 MINUTE(time)
返回time的分钟,范围是0到59。
mysql> select MINUTE('98-02-03 10:05:03');
-> 514 SECOND(time)
回来time的秒数,范围是0到59。
mysql> select SECOND('10:05:03');
-> 315 PERIOD_ADD(P,N)
增加N个月到阶段P(以格式YYMM或YYYYMM)。以格式YYYYMM返回值。注意阶段参数P不是日期值。
mysql> select PERIOD_ADD(9801,2);
-> 19980316 PERIOD_DIFF(P1,P2)
返回在时期P1和P2之间月数,P1和P2应该以格式YYMM或YYYYMM。注意,时期参数P1和P2不是日期值。
mysql> select PERIOD_DIFF(9802,199703);
-> 11
17 DATE_ADD(date,INTERVAL expr type)
18 DATE_SUB(date,INTERVAL expr type)
19 ADDDATE(date,INTERVAL expr type)
20 SUBDATE(date,INTERVAL expr type)SECOND 秒 SECONDS
MINUTE 分钟 MINUTES
HOUR 时间 HOURS
DAY 天 DAYS
MONTH 月 MONTHS
YEAR 年 YEARS
MINUTE_SECOND 分钟和秒 "MINUTES:SECONDS"
HOUR_MINUTE 小时和分钟 "HOURS:MINUTES"
DAY_HOUR 天和小时 "DAYS HOURS"
YEAR_MONTH 年和月 "YEARS-MONTHS"
HOUR_SECOND 小时, 分钟, "HOURS:MINUTES:SECONDS"
DAY_MINUTE 天, 小时, 分钟 "DAYS HOURS:MINUTES"
DAY_SECOND 天, 小时, 分钟, 秒 "DAYS HOURS:MINUTES:SECONDS"例如: select adddate('1997-12-31',interval 1 month);
select date_add('1997-12-31',interval 1 month);
21 TO_DAYS(date)
给出一个日期date,返回一个天数(从0年的天数)。 0000
mysql> select TO_DAYS('1997-10-07');
-> 72966922 FROM_DAYS(N)
给出一个天数N,返回一个DATE值。
mysql> select FROM_DAYS(729669);
-> '1997-10-07'23 DATE_FORMAT(date,format)
根据format字符串格式化date值。下列修饰符可以被用在format字符串中: %M 月名字(January……December)
%W 星期名字(Sunday……Saturday)
%D 有英语前缀的月份的日期(1st, 2nd, 3rd, 等等。)
%Y 年, 数字, 4 位
%y 年, 数字, 2 位
%a 缩写的星期名字(Sun……Sat)
%d 月份中的天数, 数字(00……31)
%e 月份中的天数, 数字(0……31)
%m 月, 数字(01……12)
%c 月, 数字(1……12)
%b 缩写的月份名字(Jan……Dec)
%j 一年中的天数(001……366)
%H 小时(00……23)
%k 小时(0……23)
%h 小时(01……12)
%I 小时(01……12)
%l 小时(1……12)
%i 分钟, 数字(00……59)
%r 时间,12 小时(hh:mm:ss [AP]M)
%T 时间,24 小时(hh:mm:ss)
%S 秒(00……59)
%s 秒(00……59)
%p AM或PM
%w 一个星期中的天数(0=Sunday ……6=Saturday )
%U 星期(0……52), 这里星期天是星期的第一天
%u 星期(0……52), 这里星期一是星期的第一天
%% 一个文字“%”。所有的其他字符不做解释被复制到结果中。
mysql> select DATE_FORMAT('1997-10-04 22:23:00', '%W %M %Y');
-> 'Saturday October 1997'
mysql> select DATE_FORMAT('1997-10-04 22:23:00', '%H:%i:%s');
-> '22:23:00'
mysql> select DATE_FORMAT('1997-10-04 22:23:00',
'%D %y %a %d %m %b %j');
-> '4th 97 Sat 04 10 Oct 277'
mysql> select DATE_FORMAT('1997-10-04 22:23:00',
'%H %k %I %r %T %S %w');
-> '22 22 10 10:23:00 PM 22:23:00 00 6'
MySQL3.23中,在格式修饰符字符前需要%。在MySQL更早的版本中,%是可选的。24 TIME_FORMAT(time,format)
这象上面的DATE_FORMAT()函数一样使用,但是format字符串只能包含处理小时、分钟和秒的那些格式修饰符。其他修饰符产生一个NULL值或025 Mysql取系统函数:
Select curtime();
Select curdate():
Select sysdate():
select now();
------------------------------------------------------------------------------------------------------------------------------------------------------------------
流程控制函数:1 IFNULL(expr1,expr2)
如果 expr1 为非 NULL 的,IFNULL() 返回 expr1,否则返回 expr2。
2 NULLIF(expr1,expr2)如果 expr1 = expr2 为真,返回 NULL,否则返回 expr1
3 IF(expr1,expr2,expr3) 如果 expr1 为真(expr1 <> 0 以及 expr1 <> NULL),那么 IF() 返回 expr2,否则返回 expr3
参考资料来源:https://blog.csdn.net/weixin_37519463/article/details/114792084















 740
740











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









