







文章目录
相关文章:
《Linux 虚拟网络设备 veth-pair》 linux基础
《Linux虚拟网络设备之veth(arp incomplete)》
Docker网络(veth、网桥、host、container、none) docker上网络概述
Docker的网络配置 1 初识 docker 精讲
Docker的网络配置 2 配置 DNS和主机名
Docker的网络配置 3 user-defined网络
Docker的网络配置 4 内嵌的DNS server
Docker的网络配置 5 将容器与外部世界连接
Docker的网络配置 6 docker-proxy
【云原生】网络之桥接(网卡对) openshift下的网络桥接模式
1. veth-pair 是什么
veth-pair 就是一对的虚拟设备接口,和 tap/tun 设备不同的是,它都是成对出现的。一端连着协议栈,一端彼此相连着。如下图所示:
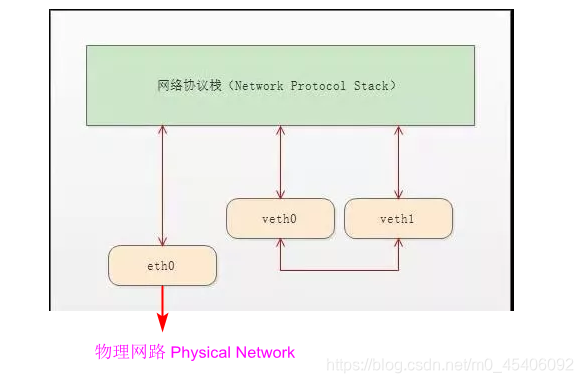
正因为有这个特性,它常常充当着一个桥梁,连接着各种虚拟网络设备,典型的例子像“两个 namespace 之间的连接”,“Bridge、OVS 之间的连接”,“Docker 容器之间的连接” 等等,以此构建出非常复杂的虚拟网络结构,比如 OpenStack Neutron。
2 veth-pair 的连通性
我们给上图中的 veth0 和 veth1 分别配上 IP:10.1.1.2 和 10.1.1.3,然后从 veth0 ping 一下 veth1。理论上它们处于同网段,是能 ping 通的,但结果却是 ping 不通。
抓个包看看,tcpdump -nnt -i veth0
root@ubuntu:~# tcpdump -nnt -i veth0
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on veth0, link-type EN10MB (Ethernet), capture size 262144 bytes
ARP, Request who-has 10.1.1.3 tell 10.1.1.2, length 28
ARP, Request who-has 10.1.1.3 tell 10.1.1.2, length 28
可以看到,由于 veth0 和 veth1 处于同一个网段,且是第一次连接,所以会事先发 ARP 包,但 veth1 并没有响应 ARP 包。
经查阅,这是由于我使用的 Ubuntu 系统内核中一些 ARP 相关的默认配置限制所导致的,需要修改一下配置项:
echo 1 > /proc/sys/net/ipv4/conf/veth1/accept_local
echo 1 > /proc/sys/net/ipv4/conf/veth0/accept_local
echo 0 > /proc/sys/net/ipv4/conf/all/rp_filter
echo 0 > /proc/sys/net/ipv4/conf/veth0/rp_filter
echo 0 > /proc/sys/net/ipv4/conf/veth1/rp_filter
完了再 ping 就行了:
root@ubuntu:~# ping -I veth0 10.1.1.3 -c 2
PING 10.1.1.3 (10.1.1.3) from 10.1.1.2 veth0: 56(84) bytes of data.
64 bytes from 10.1.1.3: icmp_seq=1 ttl=64 time=0.047 ms
64 bytes from 10.1.1.3: icmp_seq=2 ttl=64 time=0.064 ms
--- 10.1.1.3 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 3008ms
rtt min/avg/max/mdev = 0.047/0.072/0.113/0.025 ms
我们对这个通信过程比较感兴趣,可以抓包看看。
对于 veth0 口:
root@ubuntu:~# tcpdump -nnt -i veth0
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on veth0, link-type EN10MB (Ethernet), capture size 262144 bytes
ARP, Request who-has 10.1.1.3 tell 10.1.1.2, length 28
ARP, Reply 10.1.1.3 is-at 5a:07:76:8e:fb:cd, length 28
IP 10.1.1.2 > 10.1.1.3: ICMP echo request, id 2189, seq 1, length 64
IP 10.1.1.2 > 10.1.1.3: ICMP echo request, id 2189, seq 2, length 64
IP 10.1.1.2 > 10.1.1.3: ICMP echo request, id 2189, seq 3, length 64
IP 10.1.1.2 > 10.1.1.3: ICMP echo request, id 2244, seq 1, length 64
对于 veth1 口:
root@ubuntu:~# tcpdump -nnt -i veth1
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on veth1, link-type EN10MB (Ethernet), capture size 262144 bytes
ARP, Request who-has 10.1.1.3 tell 10.1.1.2, length 28
ARP, Reply 10.1.1.3 is-at 5a:07:76:8e:fb:cd, length 28
IP 10.1.1.2 > 10.1.1.3: ICMP echo request, id 2189, seq 1, length 64
IP 10.1.1.2 > 10.1.1.3: ICMP echo request, id 2189, seq 2, length 64
IP 10.1.1.2 > 10.1.1.3: ICMP echo request, id 2189, seq 3, length 64
IP 10.1.1.2 > 10.1.1.3: ICMP echo request, id 2244, seq 1, length 64
奇怪,我们并没有看到 ICMP 的 echo reply 包,那它是怎么 ping 通的?
其实这里 echo reply 走的是 localback 口,不信抓个包看看:
root@ubuntu:~# tcpdump -nnt -i lo
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on lo, link-type EN10MB (Ethernet), capture size 262144 bytes
IP 10.1.1.3 > 10.1.1.2: ICMP echo reply, id 2244, seq 1, length 64
IP 10.1.1.3 > 10.1.1.2: ICMP echo reply, id 2244, seq 2, length 64
IP 10.1.1.3 > 10.1.1.2: ICMP echo reply, id 2244, seq 3, length 64
IP 10.1.1.3 > 10.1.1.2: ICMP echo reply, id 2244, seq 4, length 64
为什么?
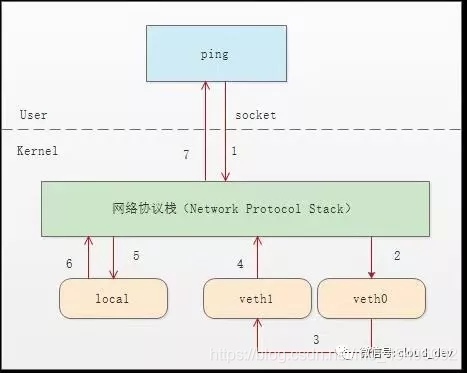
我们看下整个通信流程就明白了。
- 首先 ping 程序构造 ICMP echo request,通过 socket 发给协议栈。
- 由于 ping 指定了走 veth0 口,如果是第一次,则需要发 ARP 请求,否则协议栈直接将数据包交给 veth0。
- 由于 veth0 连着 veth1,所以 ICMP request 直接发给 veth1。
- veth1 收到请求后,交给另一端的协议栈。
- 协议栈看本地有 10.1.1.3 这个 IP,于是构造 ICMP reply 包,查看路由表,发现回给 10.1.1.0 网段的数据包应该走 localback 口,于是将 reply 包交给 lo 口(会优先查看路由表的 0 号表,ip route show table 0 查看)。
- lo 收到协议栈的 reply 包后,啥都没干,转手又回给协议栈。
- 协议栈收到 reply 包之后,发现有 socket 在等待包,于是将包给 socket。
- 等待在用户态的 ping 程序发现 socket 返回,于是就收到 ICMP 的 reply 包。
整个过程如下图所示:
3 两个 namespace 之间的连通性#
namespace 是 Linux 2.6.x 内核版本之后支持的特性,主要用于资源的隔离。有了 namespace,一个 Linux 系统就可以抽象出多个网络子系统,各子系统间都有自己的网络设备,协议栈等,彼此之间互不影响。
如果各个 namespace 之间需要通信,怎么办呢,答案就是用 veth-pair 来做桥梁。
根据连接的方式和规模,可以分为“直接相连”,“通过 Bridge 相连” 和 “通过 OVS 相连”。
3.1 直接相连
直接相连是最简单的方式,如下图,一对 veth-pair 直接将两个 namespace 连接在一起。
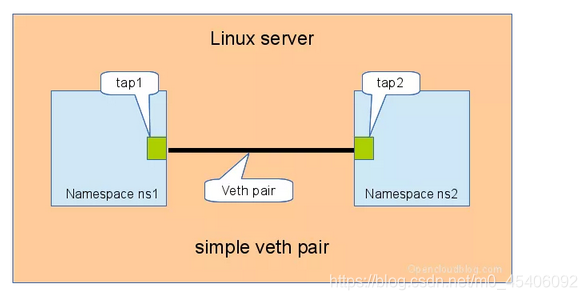
图3-1
给 veth-pair 配置 IP,测试连通性:
# 创建 namespace
ip netns a ns1
ip netns a ns2
# 创建一对 veth-pair veth0 veth1 ,l是link缩写,a是add缩写
ip l a veth0 type veth peer name veth1
# 将 veth0 veth1 分别加入两个 ns,l是link缩写,s是set缩写
ip link set veth0 netns ns1
ip link set veth1 netns ns2
# 给两个 veth0 veth1 配上 IP 并启用 , ip a a 是ip addr add 缩写
ip netns exec ns1 ip a a 10.1.1.2/24 dev veth0
ip netns exec ns1 ip l s veth0 up
ip netns exec ns2 ip a a 10.1.1.3/24 dev veth1
ip netns exec ns2 ip l s veth1 up
# 从 veth0 ping veth1
[root@localhost ~]# ip netns exec ns1 ping 10.1.1.3
PING 10.1.1.3 (10.1.1.3) 56(84) bytes of data.
64 bytes from 10.1.1.3: icmp_seq=1 ttl=64 time=0.073 ms
64 bytes from 10.1.1.3: icmp_seq=2 ttl=64 time=0.068 ms
--- 10.1.1.3 ping statistics ---
15 packets transmitted, 15 received, 0% packet loss, time 14000ms
rtt min/avg/max/mdev = 0.068/0.084/0.201/0.032 ms
3.2 通过 Bridge 相连
Linux Bridge 相当于一台交换机,可以中转两个 namespace 的流量,我们看看 veth-pair 在其中扮演什么角色。
如下图,两对 veth-pair 分别将两个 namespace 连到 Bridge 上。

图3-2
注意:上图中,ns1中的tap1 和ns2中的tap2 虚拟网卡需要设置ip,而br-tap1和br-tap2在加入网桥后,作为网桥的网卡,工作在链路层,通过广播进行转发,是不需要ip的地址的(此时只是传播介质,不再是独立的设备)。如果上面有地址的话,可以删掉。不删也没关系,只是浪费。与此相反,图3-1中,两端都要设置ip,否则ping 不会有响应
同样给 veth-pair 配置 IP,测试其连通性:
# 首先创建 bridge br0
ip l a br0 type bridge
ip l s br0 up
# 然后创建两对 veth-pair
ip l a veth0 type veth peer name br-veth0
ip l a veth1 type veth peer name br-veth1
# 分别将两对 veth-pair 加入两个 ns 和 br0
ip l s veth0 netns ns1
ip link set br-veth0 master br0 //brctl 的另一种语法
ip l s br-veth0 up
ip l s veth1 netns ns2
ip l s br-veth1 master br0
ip l s br-veth1 up
# 给两个 ns 中的 veth 配置 IP 并启用
ip netns exec ns1 ip a a 10.1.1.2/24 dev veth0
ip netns exec ns1 ip l s veth0 up
ip netns exec ns2 ip a a 10.1.1.3/24 dev veth1
ip netns exec ns2 ip l s veth1 up
# veth0 ping veth1
[root@localhost ~]# ip netns exec ns1 ping 10.1.1.3
PING 10.1.1.3 (10.1.1.3) 56(84) bytes of data.
64 bytes from 10.1.1.3: icmp_seq=1 ttl=64 time=0.060 ms
64 bytes from 10.1.1.3: icmp_seq=2 ttl=64 time=0.105 ms
--- 10.1.1.3 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 999ms
rtt min/avg/max/mdev = 0.060/0.082/0.105/0.024 ms
3.3 通过 OVS 相连
OVS 是第三方开源的 Bridge,功能比 Linux Bridge 要更强大,对于同样的实验,我们用 OVS 来看看是什么效果。
如下图所示:
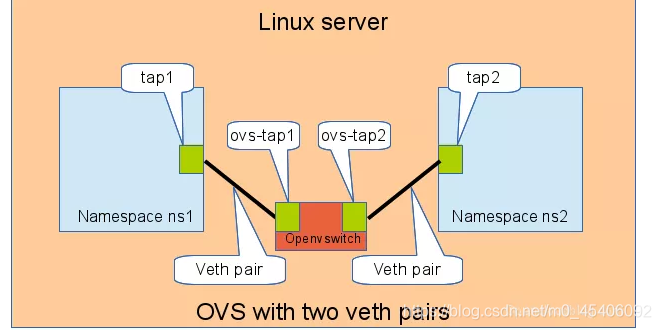
同样测试两个 namespace 之间的连通性:
# 用 ovs 提供的命令创建一个 ovs bridge
ovs-vsctl add-br ovs-br
# 创建两对 veth-pair
ip l a veth0 type veth peer name ovs-veth0
ip l a veth1 type veth peer name ovs-veth1
# 将 veth-pair 两端分别加入到 ns 和 ovs bridge 中
ip l s veth0 netns ns1
ovs-vsctl add-port ovs-br ovs-veth0
ip l s ovs-veth0 up
ip l s veth1 netns ns2
ovs-vsctl add-port ovs-br ovs-veth1
ip l s ovs-veth1 up
# 给 ns 中的 veth 配置 IP 并启用
ip netns exec ns1 ip a a 10.1.1.2/24 dev veth0
ip netns exec ns1 ip l s veth0 up
ip netns exec ns2 ip a a 10.1.1.3/24 dev veth1
ip netns exec ns2 ip l s veth1 up
# veth0 ping veth1
[root@localhost ~]# ip netns exec ns1 ping 10.1.1.3
PING 10.1.1.3 (10.1.1.3) 56(84) bytes of data.
64 bytes from 10.1.1.3: icmp_seq=1 ttl=64 time=0.311 ms
64 bytes from 10.1.1.3: icmp_seq=2 ttl=64 time=0.087 ms
^C
--- 10.1.1.3 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 999ms
rtt min/avg/max/mdev = 0.087/0.199/0.311/0.112 ms
4. 总结
veth-pair 在虚拟网络中充当着桥梁的角色,连接多种网络设备构成复杂的网络。
veth-pair 的三个经典实验,直接相连、通过 Bridge 相连和通过 OVS 相连。














 9320
9320











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









