







1.多个Partitions有什么好处?
①多个 partition ,能够对 broker 上的数据进行分片,通过减少消息容量来提升 IO 性能;
②为了提高消费端的消费能力,一般情况下会通过多个 conusmer 去消费 同一个 topic 中的消息,即实现消费端的负载均衡。
2.针对多个Partition,消费者该消费哪个分区的消息?
Kafka 存在 消费者组 group.id 的概念,组内的所有消费者协调在一起来消费订阅的 topic 中的消息(消息可能存在于多个分区中)。那么同一个 group.id 组中的 consumer 该如何去分配它消费哪个分区里的数据。
针对下图中情况,3 个分区(test-0 ~ test-3),3 个消费者(ConsumerA ~ C),哪个消费者应该消费哪个分区的消息呢??
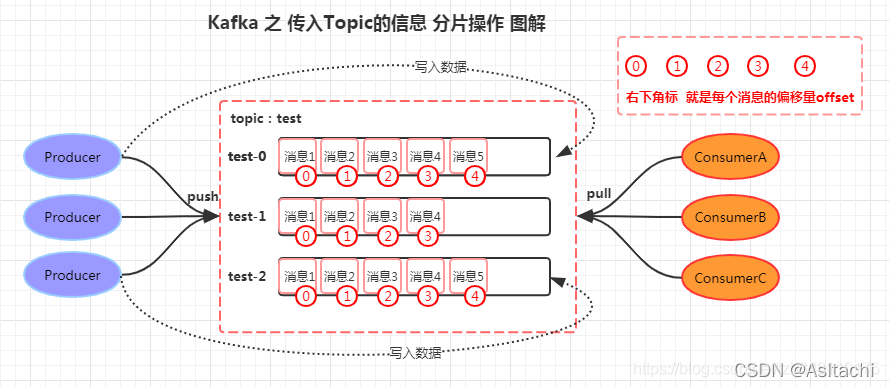
对于如上这种情况,3 个分区, 3 个消费者。这 3 个消费者都会分别去消费 test 中 topic 的 3 个分区,也就是每个 Consumer 会消费一个分区中的消息。
如果 4 个消费者消费 3 个分区,则会有 1 个消费者无法消费到消息;如果 2 个消费者消费 3 个分区,则会有 1 个消费者消费 2 个分区的消息。针对这种情况,分区数 和 消费者数 之间,该如何选择?此处就涉及到 Kafka 消费端的分区分配策略了。
1.什么是分区分配策略
通过如上实例,我们能够了解到,同一个 group.id 中的消费者,对于一个 topic 中的多个 partition 中的消息消费,存在着一定的分区分配策略。
在 kafka 中,存在着两种分区分配策略。一种是 RangeAssignor 分配策略(范围分区),另一种是 RoundRobinAssignor分配策略(轮询分区)。默认采用 Range 范围分区。 Kafka提供了消费者客户端参数 partition.assignment.strategy 用来设置消费者与订阅主题之间的分区分配策略。默认情况下,此参数的值为:org.apache.kafka.clients.consumer.RangeAssignor,即采用RangeAssignor分配策略
1.1 RangeAssignor 范围分区
Range 范围分区策略是对每个 topic 而言的。首先对同一个 topic 里面的分区按照序号进行排序,并对消费者按照字母顺序进行排序。假如现在有 10 个分区,3 个消费者,排序后的分区将会是0,1,2,3,4,5,6,7,8,9;消费者排序完之后将会是C1-0,C2-0,C3-0。通过 partitions数/consumer数 来决定每个消费者应该消费几个分区。如果除不尽,那么前面几个消费者将会多消费 1 个分区。
例如,10/3 = 3 余 1 ,除不尽,那么 消费者 C1-0 便会多消费 1 个分区,最终分区分配结果如下:

Range 范围分区的弊端:
如上,只是针对 1 个 topic 而言,C1-0消费者多消费1个分区影响不是很大。如果有 N 多个 topic,那么针对每个 topic,消费者 C1-0 都将多消费 1 个分区,topic越多,C1-0 消费的分区会比其他消费者明显多消费 N 个分区。这就是 Range 范围分区的一个很明显的弊端了
由于 Range 范围分区存在的弊端,于是有了 RoundRobin 轮询分区策略,如下介绍↓↓↓
1.2 RoundRobinAssignor 轮询分区
RoundRobin 轮询分区策略,是把所有的 partition 和所有的 consumer 都列出来,然后按照 hascode 进行排序,最后通过轮询算法来分配 partition 给到各个消费者。
轮询分区分为如下两种情况:①同一消费组内所有消费者订阅的消息都是相同的 ②同一消费者组内的消费者锁定月的消息不相同
①如果同一消费组内,所有的消费者订阅的消息都是相同的,那么 RoundRobin 策略的分区分配会是均匀的。
例如:同一消费者组中,有 3 个消费者C0、C1和C2,都订阅了 2 个主题 t0 和 t1,并且每个主题都有 3 个分区(p0、p1、p2),那么所订阅的所以分区可以标识为t0p0、t0p1、t0p2、t1p0、t1p1、t1p2。最终分区分配结果如下:
消费者C0 消费 t0p0 、t1p0 分区
消费者C1 消费 t0p1 、t1p1 分区
消费者C2 消费 t0p2 、t1p2 分区
②如果同一消费者组内,所订阅的消息是不相同的,那么在执行分区分配的时候,就不是完全的轮询分配,有可能会导致分区分配的不均匀。如果某个消费者没有订阅消费组内的某个 topic,那么在分配分区的时候,此消费者将不会分配到这个 topic 的任何分区。
例如:同一消费者组中,有3个消费者C0、C1和C2,他们共订阅了 3 个主题:t0、t1 和 t2,这 3 个主题分别有 1、2、3 个分区(即:t0有1个分区(p0),t1有2个分区(p0、p1),t2有3个分区(p0、p1、p2)),即整个消费者所订阅的所有分区可以标识为 t0p0、t1p0、t1p1、t2p0、t2p1、t2p2。具体而言,消费者C0订阅的是主题t0,消费者C1订阅的是主题t0和t1,消费者C2订阅的是主题t0、t1和t2,最终分区分配结果如下:

RoundRobin轮询分区的弊端:
从如上实例,可以看到RoundRobin策略也并不是十分完美,这样分配其实并不是最优解,因为完全可以将分区 t1p1 分配给消费者 C1。
所以,如果想要使用RoundRobin 轮询分区策略,必须满足如下两个条件:
①每个消费者订阅的主题,必须是相同的
②每个主题的消费者实例都是相同的。(即:上面的第一种情况,才优先使用 RoundRobin 轮询分区策略)
2.什么时候触发分区分配策略
当出现以下几种情况时,Kafka 会进行一次分区分配操作,即 Kafka 消费者端的 Rebalance 操作
① 同一个 consumer 消费者组 group.id 中,新增了消费者进来,会执行 Rebalance 操作
② 消费者离开当期所属的 consumer group组。比如 主动停机 或者 宕机
③ 分区数量发生变化时(即 topic 的分区数量发生变化时)
④ 消费者主动取消订阅
Kafka 消费端的 Rebalance 机制,规定了一个 Consumer group 下的所有 consumer 如何达成一致来分配订阅 topic 的每一个分区。而具体如何执行分区策略,就是上面提到的 Range 范围分区 和 RoundRobin 轮询分区 两种内置的分区策略。
Kafka 对于分区分配策略这块,也提供了可插拔式的实现方式,除了上面两种分区分配策略外,我们也可以创建满足自己使用的分区分配策略,即:自定义分区策略
3.Kafka实现自定义分区策略
实现一个用于审计功能的分区策略:假设我们有两类消息,其中一类消息的key为audit,用于审计,放在最后一个分区中,其他消息在剩下的分区中随机分配。
先创建一个三个分区三个副本的主题audit-test:
bin/kafka-topics.sh --create --zookeeper localhost:2181,localhost:2812,localhost:2183 --topic audit-test
--partitions 3 --replication-factor 3
//查看
bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic audit-test
然后实现Kafka客户端提供的Partitioner接口:
复制代码
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import org.apache.kafka.common.PartitionInfo;
import java.util.List;
import java.util.Map;
import java.util.Random;
/***
*
* 实现一个自定义分区策略:
*
* key含有audit的一部分消息发送到最后一个分区上,其他消息在其他分区随机分配
*
*
*
*/
public class PartitionerImpl implements Partitioner {
private Random random;
public void configure(Map<String, ?> configs) {
//做必要的初始化工作
random = new Random();
}
//分区策略
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
String keyObj = (String) key;
List<PartitionInfo> partitionInfoList = cluster.availablePartitionsForTopic(topic);
int partitionCount = partitionInfoList.size();
System.out.println("partition size: " + partitionCount);
int auditPartition = partitionCount - 1;
return keyObj == null || "".equals(keyObj) || !keyObj.contains("audit") ? random.nextInt(partitionCount - 1) : auditPartition;
}
public void close() {
//清理工作
}
}
接下来设定启动类参数:
//实现类
properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG,"cn.org.fubin.PartitionerImpl");
String topic = "audit-test";
Producer<String,String> producer = new KafkaProducer<String, String>(properties);
ProducerRecord nonKeyRecord = new ProducerRecord(topic,"non-key record");
//这类消息需要放在最后一个分区
ProducerRecord auditRecord = new ProducerRecord(topic,"audit","audit record");
ProducerRecord nonAuditRecord = new ProducerRecord(topic,"other","non-audit record");
try {
producer.send(nonAuditRecord).get();
producer.send(nonAuditRecord).get();
producer.send(auditRecord).get();
producer.send(nonAuditRecord).get();
producer.send(nonAuditRecord).get();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
最后验证:多推送几次消息,查看每个分区的消息数
bin/kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list localhost:9092 --topic audit-test














 2484
2484











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









