







目录
2.6 RDD转换为DataSet 、DataSet转换为RDD
3.1.3 在idea中构建 DataFrame对象,进行sql查询
3.1.5 RDD、 DataFrame、DataSet在idea中的相互转换
3.3.1 弱类型 UDAF继承 UserDefinedAggregateFunction
3.3.3 使用强类型UDAF实现聚合继承Aggregator[IN,BUFF,OUT]
一、数据模型介绍及区别
SparkSQL的两种数据模型:DataFrame、DataSet
1. DataFrame:DataFrame是一种以RDD为基础的分布式数据集,类似于传统数据库中的二维表格。DataFrame与RDD的主要区别在于,前者带有schema元信息,即DataFrame所表示的二维表数据集的每一列都带有名称和类型。
DataFrame是为数据提供了Schema的视图。可以把它当做数据库中的一张表来对待
DataFrame也是懒执行的,但性能上比RDD要高,主要原因:优化的执行计划,即查询计划通过Spark catalyst optimiser进行优化。
2. DataSet是分布式数据集合。DataSet是Spark 1.6中添加的一个新抽象,是DataFrame的一个扩展。
DataFrame是DataSet的特例,DataFrame=DataSet[Row] ,所以可以通过as方法将DataFrame转换为DataSet。Row是一个类型。
二、SparkSQL编程
2.1 创建DataFrame
1)从Spark数据源创建:Spark支持从多种文件中读取数据创建DataFrame
例子:从json文件创建 DataFrame
val df = spark.read.json("data/user.json")
df.show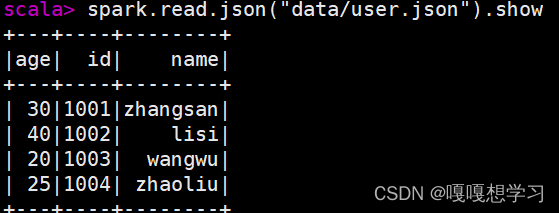
2.2SQL语法
根据上边构建的DataFrame,创建临时视图
1)创建临时视图(不可跨会话查询)
df.createOrReplaceTempView("user")2)SQL查询
spark.sql("SELECT * FROM user")注意:普通临时表是Session范围内的,如果想应用范围内有效,可以使用全局临时表。使用全局临时表时需要全路径访问,如:global_temp.user
3) 对于DataFrame创建一个全局表
df.createGlobalTempView("user")4) 通过SQL语句实现查询全表
spark.sql("SELECT * FROM global_temp.user").show()注意:全局视图查询时需要添加global_temp
5) 全局视图的跨会话查询
spark.newSession().sql("SELECT * FROM global_temp.user").show()2.3 DSL语法
DataFrame提供一个特定领域语言(domain-specific language, DSL)去管理结构化的数据。
1)查看DataFrame的Schema信息
df.printSchema 
3)查看特定的列的数据(age)
df.select("age").show4)查看"name"列数据以及"age+1"数据
注意:涉及到运算的时候, 每列都必须使用$, 或者采用引号表达式:单引号+字段名
df.select($"name",$"age" + 1).show
df.select('name, 'age + 1).show()5)数据过滤操作filter
df.filter($"age">30).show6) 数据分组统计操作groupBy、count
df.groupBy("age").count.show2.4RDD转换为DataFrame
创建RDD
val rdd = sc.textFile("data/id.txt")转换(参数为指定字段名)
rdd.toDF("id")开发中一般使用样例类进行转换
case class User(name:String, age:Int)
sc.makeRDD(List(("zhangsan",30), ("lisi",40))).map(t=>User(t._1, t._2)).toDF.show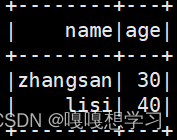
2.5DataFrame 转换为RDD
val df = sc.makeRDD(List(("zhangsan",30), ("lisi",40))).map(t=>User(t._1, t._2)).toDF
val rdd = df.rdd.collect2.6 RDD转换为DataSet 、DataSet转换为RDD
case class User(name:String, age:Int)
val ds = sc.makeRDD(List(("zhangsan",30), ("lisi",49))).map(t=>User(t._1, t._2)).toDS
ds.rdd
2.7 DataFrame和DataSet 互相转换
case class User(name:String, age:Int)
//rdd => df
val df = sc.makeRDD(List(("zhangsan",30), ("lisi",49))).toDF("name","age")
//df => ds
df.as[User]
//ds => df
ds.toDF2.8三者的互相转换
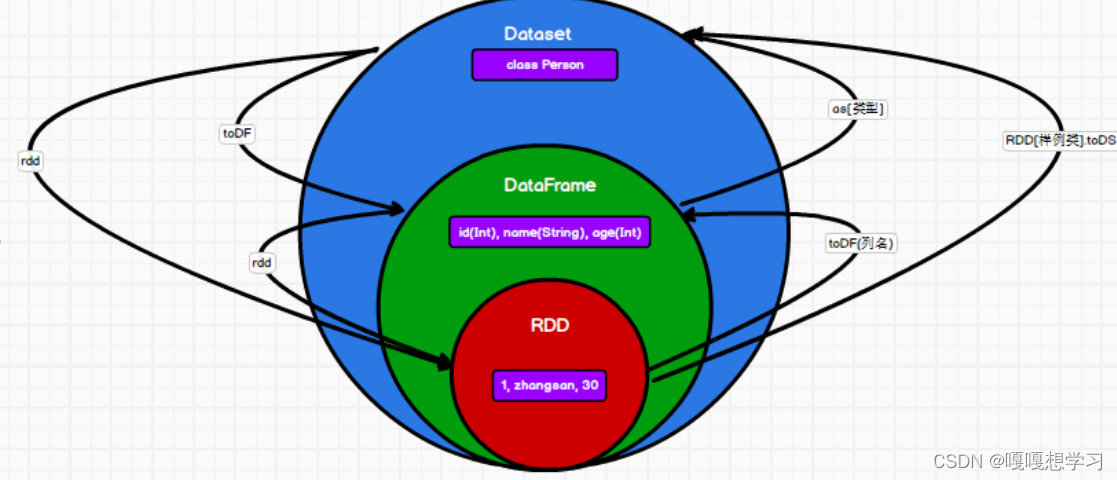
三、IDEA开发SparkSQL
3.1.1添加依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.0.0</version>
</dependency>3.1.2 构建SparkSQL上下文环境
object SparkSQL01_Env {
def main(args: Array[String]): Unit = {
//TODO SparkSQL环境
//SparkSession的构造比较繁琐,所以不能直接构造
//构建器设计模式
val pre = SparkSession.builder().master("local[*]").appName("SparkSQL")
val session: SparkSession = pre.getOrCreate()
session.stop()
}
}3.1.3 在idea中构建 DataFrame对象,进行sql查询
object SparkSQL02_DataFrame {
def main(args: Array[String]): Unit = {
//TODO DataFrame
val pre = SparkSession.builder().master("local[*]").appName("SparkSQL")
val spark: SparkSession = pre.getOrCreate()
//TODO 1.准备json文件
//json文件要求,整个文件的格式要符合json的格式
//多条数据的集合用[]包起来,元素之间用,隔开
//但是SparkSQL读取文件使用的时hadoop读文件的方式,按行读取,需要每一行的数据都要符合json格式
val df: DataFrame = spark.read.json("data/user.json")
df.show()
//TODO 2.将DataFrame数据转换为表(视图)进行sql的访问
df.createTempView("user")
spark.sql(
"""
|select
|*
|from user
|""".stripMargin).show()
spark.stop()
}
}3.1.4 DSL查询
当使用到数据的运算时需要导入spark.implicits._ ,这里导入的是对象不是方法
object Spa 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









