







最近不少网友私信我,想要抖音取关的自动化脚本,奈何上次写的脚本已经好几个月没有更新了,导致可能部分代码已经失效,而且唐丁没有给大家详细的安装和使用教程,导致不少朋友拿到脚本后也不知道如何使用。今天唐丁就一次性给大家演示一下。
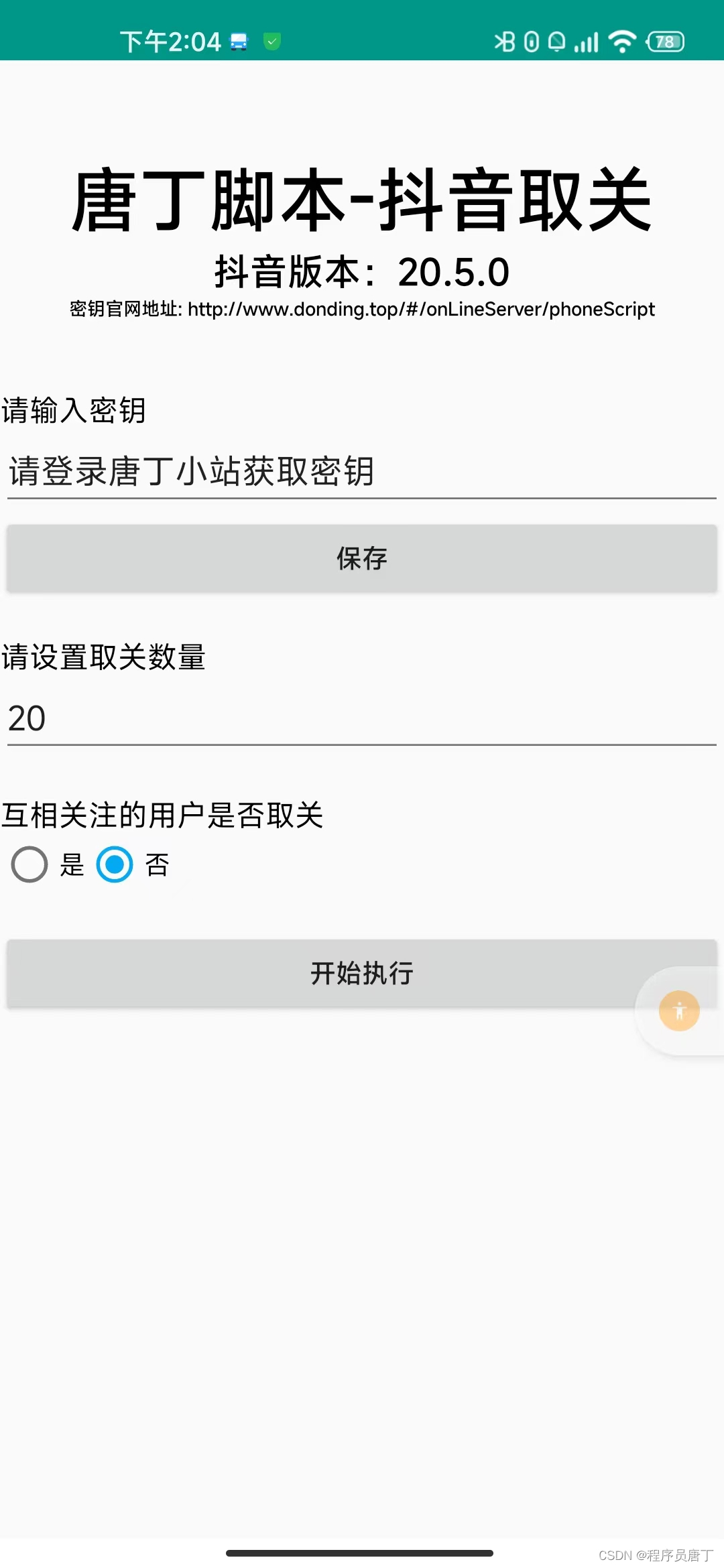
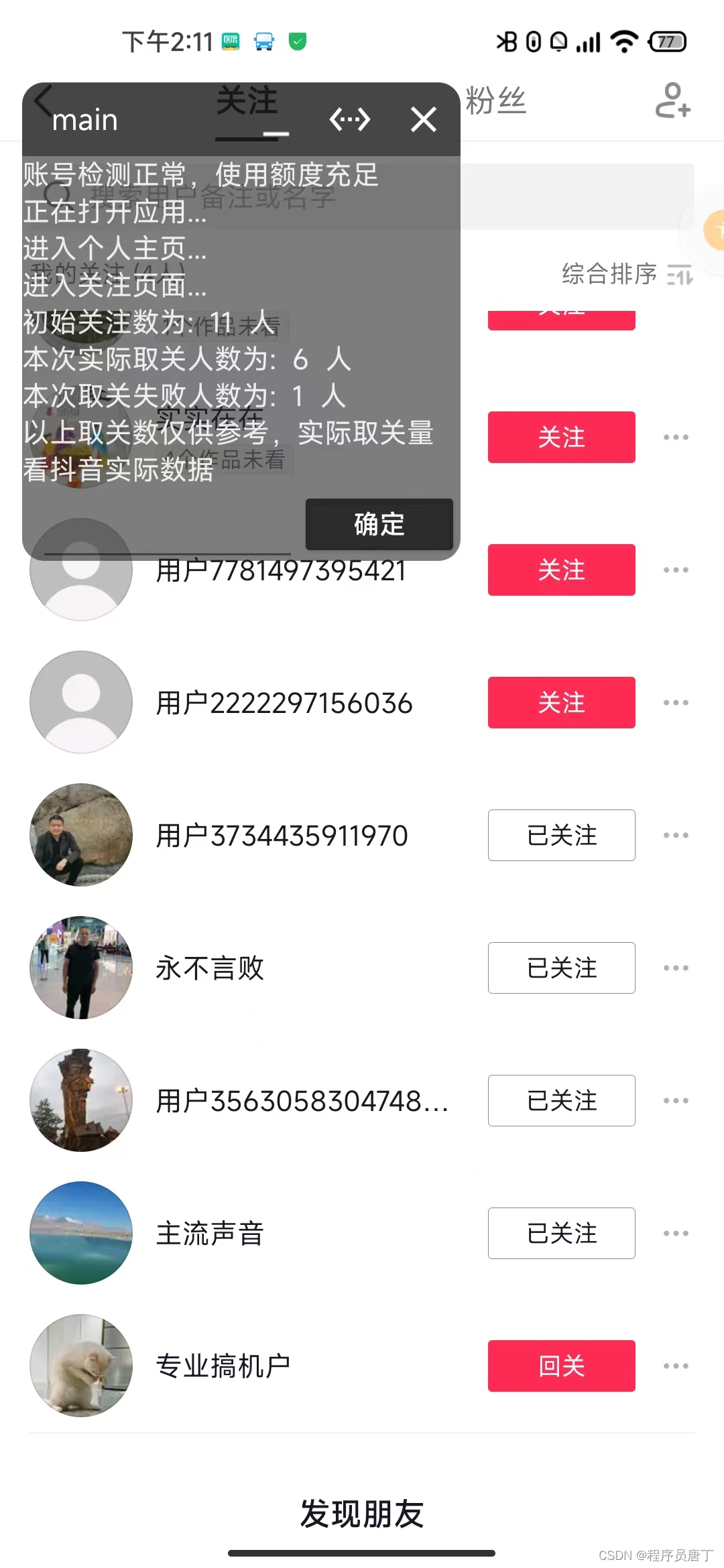
唐丁最近完善了一下后台管理系统,增加了一些对脚本的支持接口,方便后面对脚本的发布、使用、升级等做统一的管理。今天就在这里一次性把脚本的使用流程说清楚,方便后续大家的安装和使用。
1、所有脚本都以安卓应用(apk)的形式发布,大家下载到手机上安装即可(安装过程可能提示病毒之类的异常,直接忽略即可)
2、安装后需要给予软件两个权限: 无障碍(软件正常运行的基础)和悬浮窗(日志查看)
从公众号(程序员唐丁)回复关键词获取脚本链接下载后,里面包括脚本软件和使用说明文档两部分,不清楚的同学可以直接安装说明文档进行操作。
当前脚本的种类还不算丰富,唐丁正在抓紧完善当中,后续所有的功能脚本会集成在一个安卓应用当中,大家可以直接在界面中选择需要的功能,配置相关参数后即可使用。这边再解释一下密钥相关的东西,获取密钥需要登录上述页面中的网站,注册并开通脚本账号后会自动生成一个密钥,一个账号只有一个密钥,密钥对唐丁的所有脚本都是通用的,新注册的用户有10次免费体验的机会。欢迎大家使用~~


















 4460
4460

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











