






腾讯机器狗,登上了Nature子刊封面!

在它的控制下,机器狗的动作和真实世界中的狗越来越像了。
注意看,这里的两只机器狗玩起了“定向越野”,还是带追逐的那种。

游戏当中,两只机器狗分别要扮演追逐者和逃脱者,逃脱者需要在不被抓到的情况下到达指定位置。
一旦它到达了指定位置,两只机器狗就会交换身份,如此来回进行,直到有一只被抓住。
这个游戏的一个难点在于有最大速度限制,两只机器狗都不能单独依靠速度取胜,必须规划出一定策略。
甚至,还有更加困难的障碍赛,战斗更加激烈、场面更加精彩。

这场机器人越野大赛的背后,应用的正是这套全新的控制框架。
该框架采取了分层式策略,并运用生成式模型学习了动物的运动方式,训练数据来自一只拉布拉多犬。
这套方法让机器狗不再依赖物理模型或手工设计的奖励函数,并能像动物一样理解和适应更多的环境与任务。
像真的狗一样运动
这只机器狗名叫MAX,重量为14kg,每条腿上有3个行动器,可提供平均22N·m的持续扭矩,最大能达到30N·m。
MAX的一大亮点,就是实现了对真实世界中狗的模仿。
在室内环境中,MAX挣脱了研究者,然后就开始了自由跑动。

把MAX放到室外,它也能在草地上欢快地奔跑玩耍。

当遇到有障碍的复杂地形时,这种模仿就更加惟妙惟肖了。
向上,MAX可以敏捷飞快地爬上楼梯。

向下,它也能钻过障碍物,挡在它前面的横杆没有被碰到一点。

这一系列的动作背后,都是MAX的控制系统从一只拉布拉多的动作当中学习到的策略。
利用对真狗的模仿,MAX还能规划更高级的策略,完成更为复杂的任务,前面展示的追逐大战就是一个很好的例子。
值得一提的是,除了让两只机器狗相互竞技之外,研究人员也通过手柄控制加入到了这场战斗。
从画面中不难看出,真人控制模式下的机器狗(下图中1号),反而不如纯机器方案(2号)来得灵活。

最终的结果是,在开了挂(人类控制的机器狗最大限速更高)的情况下,人类仍然以0:2的比分彻底输给了机器。
除了能让机器狗灵活运动,该框架最大的优势就是通用性,可以针对不同的任务场景和机器人形态进行预训练和知识复用。
未来,团队还计划把该系统迁移至人形机器人和多智能体协作的场景。
所以,Robotics X实验室的研究人员是如何打造出这套方案的呢?
加入生成式模型的分层框架
研究人员设计这套控制框架的核心思路,就是模仿真实动物的运动、感知和策略。
该框架通过构建可预训练、可重用和可扩展的原始级、环境级和策略级知识,使机器人能够像动物一样从更广泛的视角理解和适应环境与任务。
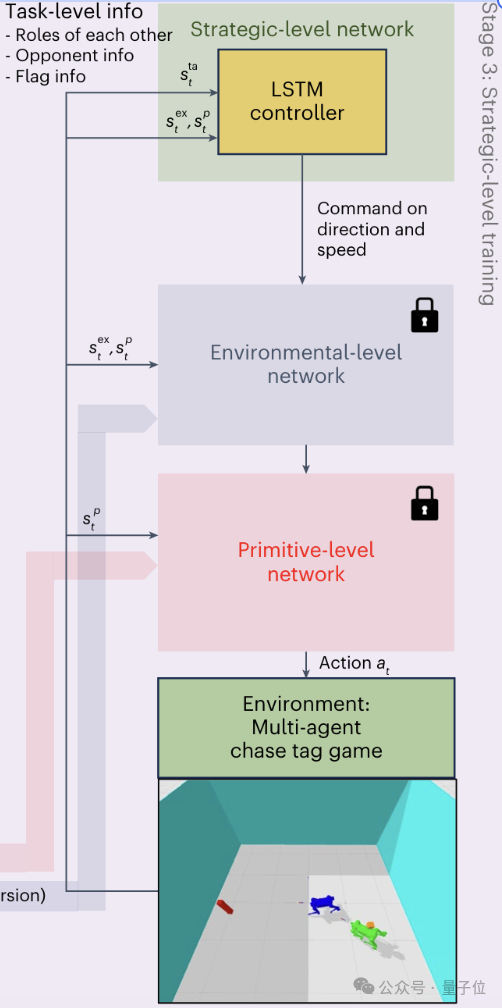
具体实现上,该框架也采用了分层式的控制方式,之中的三个层级——原始运动控制器(PMC)、环境适应控制器(EPMC)和策略控制器(SEPMC)——分别与原始级、环境级和策略级知识形成了对应。
首先,人类会发出一个高级的指令(比如告诉机器竞速追逐游戏的规则和目标),这也是(运行过程)全程唯一需要人参与的地方。
这个高级指令会被SEPMC接收,并根据当前情况(如机器人角色、对手位置等)制定策略,然后生成包括移动方向、速度等信息的导航命令。
导航命令接下来会传给EPMC,然后结合环境感知信息(如地形高度图、深度信息等),选择适当的运动模式,形成一个类别分布,同时选择合适的离散潜在表示。
最后,PMC又把这种潜在表示与机器人当前的状态(如关节位置、速度等)结合,得到电机控制信号,并最终交付执行。
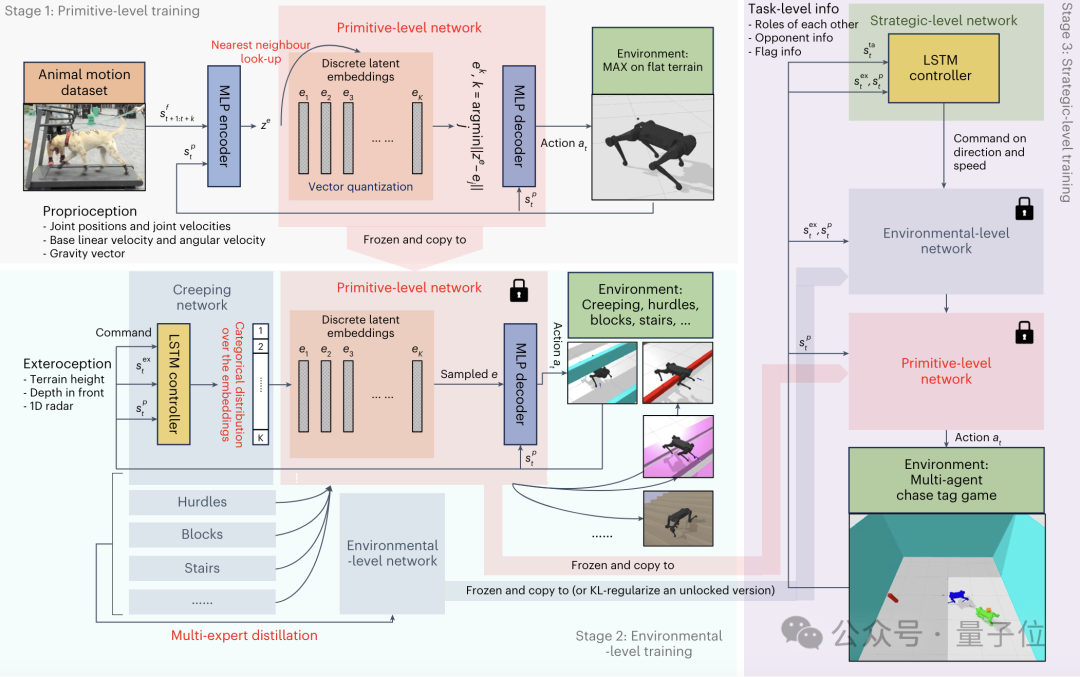
训练的顺序则刚好与之相反——从PMC开始,到SEPMC结束。
第一阶段PMC的训练,也就是原始级训练,是为了建立基础的运动能力。
该阶段的训练数据来自对一只训练有素的中型拉布拉多犬的运动捕捉。
通过指导狗狗完成各种动作,作者收集了大约半小时的不同步态(如行走、奔跑、跳跃、坐下等)的运动序列,以每秒120帧的频率采样。
狗狗在捕捉过程中遵循直线、方形、圆形等不同的路径轨迹。此外,作者还专门收集了约9分钟的上下楼梯的运动数据。
为了弥合动物和机器人的骨骼结构差异,作者使用逆运动学方法将狗狗的关节运动数据重定向到机器人关节。
通过进一步的人工调整,最终得到了与四足机器人兼容的参考运动数据。

△资料图,不代表训练数据来源
基于这些数据,作者使用了生成式模型VQ-VAE编码器来压缩和表示动物的运动模式,构建了PMC的离散潜在空间。
通过向量量化技术,这些连续的潜在表示离散化为预定义的离散嵌入向量,解码器则基于选定的离散嵌入和当前机器人状态生成具体的运动控制信号。
在VQ-VAE的基础上,PMC的训练目标,是最小化生成的运动轨迹与参考轨迹之间的偏差。
同时,作者引入了优先级采样机制,根据不同运动模式的难易程度动态调整其在训练中的权重,确保网络对所有参考数据都能很好地拟合。
通过不断迭代和优化,PMC逐步学习到一组能够有效表达复杂动物运动的离散表征,直至收敛。
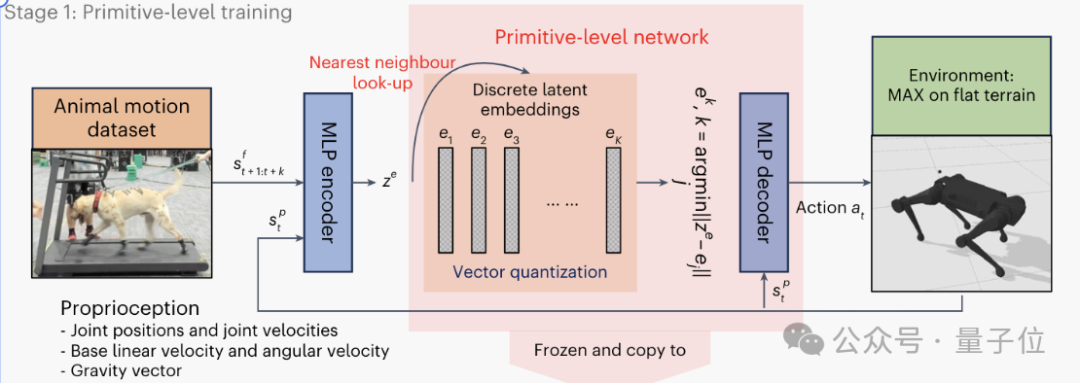
PMC阶段的结果,为EPMC生成更高级别的运动控制信息提供了基础。
EPMC在PMC的基础上引入了环境感知模块,接收来自视觉、雷达等传感器的信息,使得策略网络能够根据当前环境状态动态调整运动模式。
EPMC的核心是一个概率生成网络,根据当前的感知信息和指令信号,在PMC提供的离散潜在空间上生成一个概率分布。
这个分布决定了应该激活哪些原始运动模式,以最好地适应当前环境和任务。
EPMC的训练,通过最小化环境适应和任务完成的损失函数来实现,逐步学习优化运动策略,提高机器人的适应能力和鲁棒性。
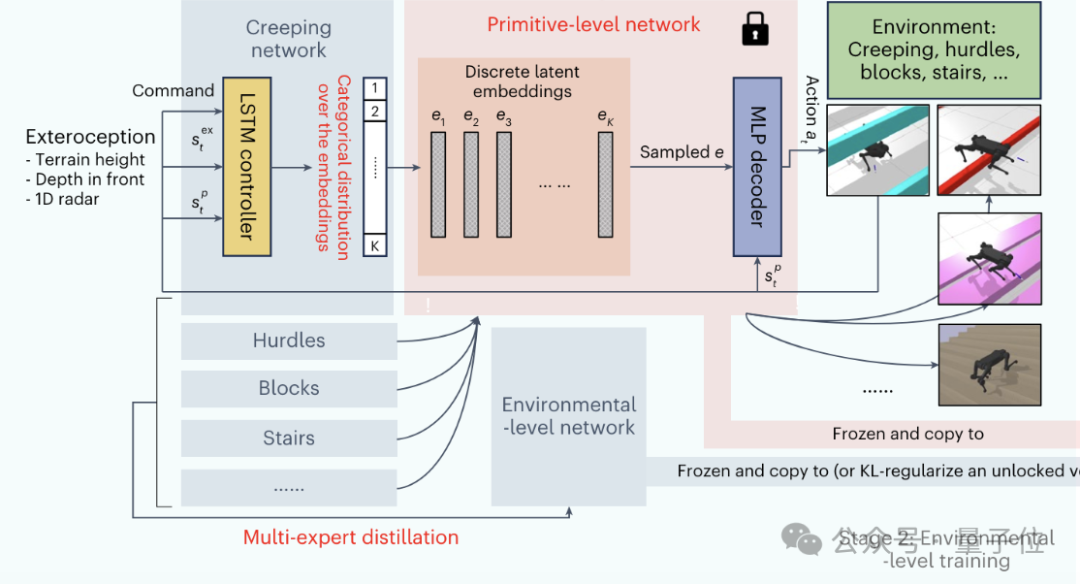
最后的SEPMC训练阶段进一步提升了机器人的认知和规划能力,使其能够在多智能体交互环境中制定和执行高层策略。
SEPMC在EPMC的基础上,根据当前的游戏状态(如自身和对手位置等)和历史交互记录,生成高层的策略决策(如追逐、躲避)。
MAX机器人玩的追逐式定向越野游戏,也正是SEPMC的训练方式。
在该阶段,作者采用了先进的多智能体强化学习算法PFSP,通过自我博弈不断提升机器人的策略水平。
训练过程中,当前策略不断与历史上的强对手进行对抗,迫使其学习更加鲁棒和高效的策略。
得益于前两个阶段打下的坚实基础,这种复杂策略的学习是非常高效的,即使在稀疏奖励的情况下也能快速收敛。
值得一提的是,这样的多智能体方案当中,还可以引入一些模拟人类的智能体,从而实现机器间或人机间的协作配合。
以上的训练过程都是在仿真环境中完成,然后以零样本迁移到真实环境。
在仿真中,物理参数可以自由控制,作者随机化了大量物理参数(包括负载、地形变化等),通过强化学习得到的策略必须能够应对这些变化,得到稳定和通用的控制能力。
另外,作者在控制框架中的每一层都使用了LSTM,使得各个层级都具备一定的时序记忆和规划能力。
传感器方面,目前作者主要验证了使用Motion Capture系统,或仅基于Depth Camera的视觉感知可以完成一系列复杂的任务。
为了处理更加开放和复杂的环境,作者未来将进一步整合LiDAR、Audio等感知输入,进行多模态理解,更好的应对环境。
论文地址:
https://www.nature.com/articles/s42256-024-00861-3
项目主页:
https://tencent-roboticsx.github.io/lifelike-agility-and-play/
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









