









KylinKylin即席查询教程
学习目标
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LYxdGzLT-1648282042148)(Kylin.assets/image-20200428085734553.png)]](https://img-blog.csdnimg.cn/381d6624e2954419802da5302158a366.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5bKB5pyI55qE55y4,size_20,color_FFFFFF,t_70,g_se,x_16)
简介
核心概念
数据仓库,OLAP与OLTP,维度和度量,事实表和维度表。星型模型和雪花模型。
数据仓库 DW
这是商业智能(BI)的核心部分,主要是将不同数据源的数据整合到一起,通过多维分析为企业提供决策支持、报表生成等。存入数据仓库的资料必定包含时间属性。
数据仓库和数据库主要区别:用途不同。
| 数据库 | 数据仓库 |
|---|---|
| 面向事务 存储在线的业务数据,对上层业务改变作出实时反映,遵循三范式设计。 | 面向分析 历史数据,主要为企业决策提供支持,数据可能存在大量冗余,但是利于多个维度查询,为决策者提供更多观察视角。 |
一般来说,在传统BI领域里,数据仓库的数据同样是存储在MySQL这样的数据库中。大数据领域最常用的数据仓库就是Hive,我们要学习的Kylin也是以Hive作为默认的数据源的。
OLAP和OLTP
OLAP(Online Analytical Process),联机分析处理,大量历史数据为基础,配合时间点的差异,以多维度的方式分析数据, 一般带有主观的查询需求,多应用在数据仓库。
OLTP(Online Transaction Process),联机事务处理,侧重于数据库的增删查改等常用业务操作。
维度和度量
这两个是数据分析领域中两个常用的概念。维度(`Dimension`)简单来说就是你观察数据的角度,也就是数据记录的一个属性例如时间、地点等。度量(`Measure`)就是基于数据所计算出来的考量值,通常就是一个数据比如总销售额,不同的用户数量。我们就是从不同的维度来审查度量值,以便我们分析找出其中的变化规律。
对应我们的SQL查询,group by的属性通常就是我们考量的维度,所计算出来的比如sum(字段)就是我们需要的度量。
从下面一个简单的例子来看。
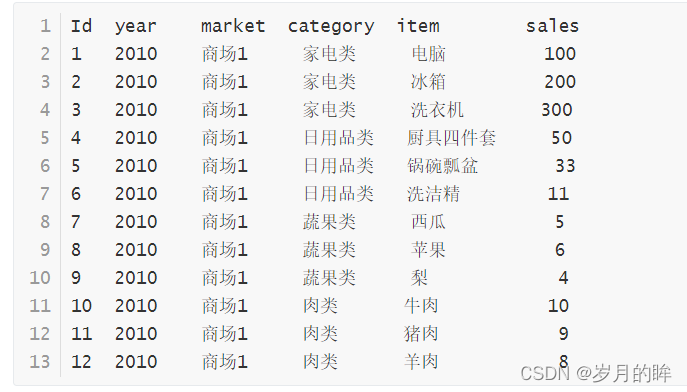
数据包含如下字段:年份,商场名,类别,物品,总销售额
SQL查询分析:
select category,SUM(sales) as sumsales from test group by category;
结果如下:
家电类 600
日用品类 94
肉类 27
蔬果类 15
在这个例子中商品类别就是维度,sum(sales)就是我们的度量。即我们从商品类别的角度来看,各种商品类别的销售额分别是多少。
再加一组数据(商场2)来看。
1 2010 商场1 家电类 电脑 100
2 2010 商场1 家电类 冰箱 200
3 2010 商场1 家电类 洗衣机 300
4 2010 商场1 日用品类 厨具四件套 50
5 2010 商场1 日用品类 锅碗瓢盆 33
6 2010 商场1 日用品类 洗洁精 11
7 2010 商场1 蔬果类 西瓜 5
8 2010 商场1 蔬果类 苹果 6
9 2010 商场1 蔬果类 梨 4
10 2010 商场1 肉类 牛肉 10
11 2010 商场1 肉类 猪肉 9
12 2010 商场1 肉类 羊肉 8
13 2010 商场2 家电类 电脑 200
14 2010 商场2 家电类 冰箱 111
15 2010 商场2 家电类 洗衣机 156
16 2010 商场2 日用品类 厨具四件套 22
17 2010 商场2 日用品类 锅碗瓢盆 20
18 2010 商场2 日用品类 洗洁精 8
19 2010 商场2 蔬果类 西瓜 4
20 2010 商场2 蔬果类 苹果 5
21 2010 商场2 蔬果类 梨 1
22 2010 商场2 肉类 牛肉 22
23 2010 商场2 肉类 猪肉 33
24 2010 商场2 肉类 羊肉 4
SQL查询分析:
select market,SUM(sale) as salesum from test group by market;
结果如下:
商场1 736
商场2 586
在这个例子中,我们换了个维度来看待数据,即我们从商场这个维度来看待,每个商场的销售额是多少。
又或者我们可以结合多个维度来看待数据,从商场和类目的组合维度来统计数据,SQL查询分析,如下:
select market,category,SUM(sales) as sumsales from test group by market,category;
商场1 家电类 600
商场1 日用品类 94
商场1 肉类 27
商场1 蔬果类 15
商场2 家电类 467
商场2 日用品类 50
商场2 肉类 59
商场2 蔬果类 10
从分析的结果,我们可以得出商场1和商场2中,各类别商品的销售额是多少。
对于OLAP系统(数据仓库)就是我们在统计的时候将维度相同的记录聚合在一起,然后应用聚合函数做各种各样的聚合计算。看一下年度销售额是否在正常范围,和往年的同比增幅,都可以一目了然。
Cube和cuboid
我们在确定好了维度和度量之后,我们根据定义好的维度和度量,就可以构建cube(立方体)。也就是所谓的预计算,对原始数据建立的多维度索引。
给定一个数据模型,我们可以对其上的所有维度进行组合。对于N个维度来说,组合的所有可能性共有2^N 种。对于每一种维度的组合,将度量做聚合运算,然后将运算的结果保存为一个物化视图,称为Cuboid。所有维度组合的Cuboid作为一个整体,被称为Cube。
所以简单来说,一个 Cube就是许多按维度聚合的物化视图的集合。
下面来列举一个具体的例子。假定有一个电商的销售数据集,其中维度包括
时间(Time)、商品(Item)、地点(Location)和供应商(Supplier),
度量为销售额(GMV)。那么所有维度的组合就有2^4 =16即16种(如下图所示),比如一维度(1D)的组合有[Time]、[Item]、[Location]、[Supplier]4种; 二维度(2D)的组合有[Time,Item]、[Time,Location]、[Time、Supplier]、 [Item,Location]、[Item,Supplier]、[Location,Supplier]6种;三维度(3D)的 组合也有4种;最后零维度(0D)和四维度(4D)的组合各有1种,总共就有 16种组合。下图为kylin官方图例。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZwvJdK6H-1648282042150)(Kylin.assets/wps1.jpg)]](https://img-blog.csdnimg.cn/439b6ece12904ed2bfa8b0a40f51e214.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5bKB5pyI55qE55y4,size_20,color_FFFFFF,t_70,g_se,x_16)
通过维度聚合销售额来计算cuboid,通过sql语句来表达这样的计算Cuboid[Time,Location],如下:
select Time,Location,SUM(GMV) as GMV from Sales group by Time,Location;
将计算的结构保存为物化视图,即所有的Cuboid物化视图的总称就是Cube。
Cube Segment
见名知意代表的是元数据中的某一个片段计算出的cube数据。通常数据仓库中的数据量会随着时间的增长而增长,而Cube Segment也是按照时间顺序来构建的。
事实表和维度表
事实表(Fact Table)是指存储有事实记录的表,如系统日志、销售记录等;事实表的记录在不断地动态增长,所以它的体积通常远大于其他表。
维度表(Dimension Table)或维表,有时也称查找表(Lookup Table),是与事实表相对应的一种表;它保存了维度的属性值,可以跟事实表做关联;相当于将事实表上经常重复出现的属性抽取、规范出来用一张表进行管理。
常见的维度表有:日期表(存储与日期对应的周、月、季度等的属性)、地点表(包含国家、省/州、城市等属性)等。使用维度表有诸多好处,具体如下:
-
缩小了事实表的大小。
-
便于维度的管理和维护,增加、删除和修改维度的属性,不必对事实表的大量记录进行改动。
-
维度表可以为多个事实表重用,以减少重复工作。
多维数据模型
星型模型(star schema)
星型模型就是一张事实表,以及零个或多个维度表;事实表与维度表通过主键外键相关联,维度表之间没有关联,就像很多星星围绕在一个恒星周围,故取名为星形模型。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OvLfxosR-1648282042151)(Kylin.assets/wps2.jpg)]](https://img-blog.csdnimg.cn/9d0efa1a45e0465fa165d60e20a31182.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5bKB5pyI55qE55y4,size_20,color_FFFFFF,t_70,g_se,x_16)
雪花模型(snowFlake schema)
将星形模型中的某些维表抽取成更细粒度的维表,然后让维表之间也进行关联,这种形状酷似雪花的的模型称为雪花模型。
![ [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4EKuhUOD-1648282042153)(Kylin.assets/wps3.jpg)]](https://img-blog.csdnimg.cn/e75f84d792704c1081f31adbef65fa9a.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5bKB5pyI55qE55y4,size_20,color_FFFFFF,t_70,g_se,x_16)
两者间的区别
星型模型因为数据的冗余所以很多统计查询不需要做外部的连接,因此一般情况下效率比雪花型模型要高。星型结构不用考虑很多正规化的因素,设计与实现都比较简单。
雪花型模型由于去除了冗余,有些统计就需要通过表的联接才能产生,所以效率不一定有星型模型高。正规化也是一种比较复杂的过程,相应的数据库结构设计、数据的 ETL、以及后期的维护都要复杂一些。因此在冗余可以接受的前提下,实际运用中星型模型使用更多,也更有效率。
Kylin的由来
Apache Kylin(Extreme OLAP Engine for Big Data)是一个开源的分布式分析引擎,为Hadoop等大型分布式数据平台之上的超大规模数据集通过标准 SQL查询及多维分析(OLAP)功能,提供亚秒级的交互式分析能力。
Apache Kylin,中文名麒麟,是Hadoop动物园中的重要成员。Apache Kylin是一个开源的分布式分析引擎,最初由eBay开发贡献至开源社区。它提供Hadoop之上的SQL查询接口及多维分析(OLAP)能力以支持大规模数据,能够处理TB乃至PB级别的分析任务,能够在亚秒级查询巨大的Hive表,并支持高并发。
Apache Kylin于2014年10月在github开源,并很快在2014年11月加入Apache孵化器,于 2015年11月正式毕业成为Apache顶级项目,也成为首个完全由中国团队设计开发的 Apache顶级项目。于2016年3月,Apache Kylin核心开发成员创建了Kyligence公司,力求更好地推动项目和社区的快速发展。
为什么使用它
在大数据的背景下,Hadoop的出现解决了数据存储问题,但如何对海量数据进行 OLAP查询,却一直令人十分头疼。企业中大数据查询大致分为两种:即席查询和定制查询。
- 即席查询
Hive、SparkSQL等OLAP引擎,虽然在很大程度上降低了数据分析的难度,但它们都只适用于即席查询的场景。它们的优点是查询灵活,但是随着数据量和计算复杂度的增长,响应时间不能得到保证。
- 定制查询
多数情况下是对用户的操作做出实时反应,Hive等查询引擎很难满足实时查询,一般只能对数据仓库中的数据进行提前计算,然后将结果存入Mysql等关系型数据库,最后提供给用户进行查询。
在上述背景下,Apache Kylin应运而生。不同于大规模并行处理Hive等架构,Apache Kylin采用" 预计算"的模式,用户只需要提前定义好查询维度,Kylin将帮助我们进行计算,并将结果存储到HBase 中,为海量数据的查询和分析提供亚秒级返回,是一种典型的空间换时间的解决方案。
Apache Kylin的出现不仅很好地解决了海量数据快速查询的问题,也避免了手动开发和维护提前计算程序带来的一系列麻烦。
Kylin的工作原理
上面章节所描述的对数据模型做Cube预计算就是Kylin的工作原理,典型的空间换时间的例子。利用cube计算的结构加速我们的查询。具体过程如下。
-
指定数据模型,定义维度和度量。
-
预计算
Cube,计算所有Cuboid并保存为物化视图。 -
执行查询时,读取
Cuboid,运算,产生查询结果。
Kylin的查询过程不会扫描原始记录,而是通过预计算预先完成表的关联、聚合等复杂运算,并利用预计算的结果来执行查询,因此相比非预计算的查询技术,其速度一般要快一到两个数量级,并且这点在超大的数据集上优势更明显。当数据集达到千亿乃至万亿级别时,Kylin的速度甚至可以超越其他非预计算技术1000倍以上。
总结:
Kylin的核心思想是Cube预计算,理论基础是空间换时间,把高复杂度的聚合运算、多表连接等操作转换成对预计算结果的查询。
Kylin技术架构
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QkAeGZaY-1648282042157)(Kylin.assets/wps4.jpg)]](https://img-blog.csdnimg.cn/16a9c22f4a394ade9d75b0a2137d5573.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5bKB5pyI55qE55y4,size_20,color_FFFFFF,t_70,g_se,x_16)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Hq6LNOs0-1648282042158)(Kylin.assets/wps5.jpg)]](https://img-blog.csdnimg.cn/84607783259942f08f9f5290581386fa.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5bKB5pyI55qE55y4,size_20,color_FFFFFF,t_70,g_se,x_16)
Kylin系统主要分为在线查询和离线构建两个部分,(第一张图中)橙色线代表在线,灰色线代表离线。
Kylin是一个开源的分布式分析引擎,提供一个标准的sql接口,给我们多维分析(OLAP)提供帮助。你可以把kylin理解为一个数据仓库。对比之前的hive,想要一些计算结果我们可能会写一些脚本实现将结果集算好,但是对应业务复杂,维度变化更多的情况,你用shell脚本就不好控制了。Kylin就是按照你想要的维度给你全部构建好(即说白了你想要怎样的维度组合数据我就帮你算好)。
用户可以从上方查询系统发送SQL进行查询分析。Kylin提供了各种Rest API、JDBC/ODBC接口。无论从哪个接口进入,SQL最终都会来到Rest服务层,再转交给查询引擎进行处理。这里需要注意的是,SQL语句是基于数据源的关系模型书写的,而不是Cube。
Kylin在设计时刻意对查询用户屏蔽了Cube的概念,分析师只需要理解简单的关系模型就可以使用Kylin,没有额外的学习门槛,传统的SQL应用也很容易迁移。查询引擎解析SQL,生成基于关系表的逻辑执行计划,然后将其转译为基于Cube的物理执行计划,最后查询预计算生成的Cube并产生结果。整个过程不会访问原始数据源。
注意: 对于查询引擎下方的路由选择,在设计者曾考虑过将Kylin不能执行的查询引导去Hive中继续执行,但在实践后发现Hive与Kylin的速度差异过大,导致用户无法对查询的速度有一致的期望,很可能大多数查询几秒内就返回结果了,而有些查询则要等几分钟到几十分钟,因此体验非常糟糕。最后这个路由功能在发行版中默认关闭,因此在图中是用虚线表示的。
看图,左侧为数据来源,消息队列、hive等拿到数据之后,通过kylin处理,将hbase作为存储介质,满足一定的实时性要求(Hbase中的每行记录的Rowkey由dimension组成,measure会保存在column family中。为了减小存储代价,这里会对dimension和measure进行编码。查询阶段,利用HBase列存储的特性就可以保证Kylin有良好的快速响应和高并发。Kylin在中间作为媒介,提供rest api使用以及jdbc接口供BI软件做报表的支撑(拓展软件:tableau,superset)。
总结:hive查询时间随着数据量的增长而线性增长,kylin使用预计算技术打破了这一点,kylin在数据集规模上的局限性主要取决于维度的个数和基数,而不是数据集的大小,所以Kylin能更好地支持海量数据集的查询。而也正是预计算技术,kylin的查询速度非常快,亚秒级响应。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rubPRGlM-1648282042159)(Kylin.assets/image-20200428164527432.png)]](https://img-blog.csdnimg.cn/476ac49fb3fc4444b4811dec4f4145ce.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5bKB5pyI55qE55y4,size_20,color_FFFFFF,t_70,g_se,x_16)
kylin主要特点
Apache Kylin的主要特点包括支持SQL接口、支持超大数据集、亚秒级响应、可伸缩性、高吞吐率、BI工具集成等。
标准SQL接口
Apache Kylin以标准SQL作为对外服务的主要接口:Kylin使用的查询模型是数据源中的关系模型表,一般而言,也就是指Hive表。终端用户只需要像原来查询Hive表一样编写SQL,就可以无缝地切换到Kylin,几乎不需要额外的学习,甚至原本的Hive查询也因为与SQL同源,大多都无须修改就能直接在Kylin上运行。
支持超大规模集
Apache Kylin对大数据的支撑能力可能是目前所有技术中最为领先的。早在2015年eBay的生产环境中Kylin就能支持百亿记录的秒级查询,之后在移动的应用场景下又有了千亿记录秒级查询的案例。这些都是实际场景的应用,而非实验室中的理论数据。
因为使用了Cube预计算技术,在理论上,Kylin可以支撑的数据集大小没有上限,仅受限于存储系统和分布式计算系统的承载能力,并且查询速度不会随数据集的增大而减慢。Kylin在数据集规模上的局限性主要在于维度的个数和基数。它们一般由数据模型来决定,不会随着数据规模的增长而线性增长,这也意味着Kylin对未来数据的增长有着更强的适应能力。
亚秒级响应
Apache Kylin拥有优异的查询响应速度,这点得益于预计算,很多复杂的计算,比如连接、聚合,在离线的预计算过程中就已经完成,这大大降低了查询时刻所需要的计算量,提高了响应速度。根据可查询到的公开资料可以得知,Apache Kylin在某生产环境中90%的查询可以在3s内返回结果。这并不是说一小部分SQL相当快,而是在数万种不同SQL的真实生产系统中,绝大部分的查询都非常迅速;在另外一个真实的案例中,对1000多亿条数据构建了立方体,90%的查询性能都在1.18s以内,可见Kylin在超大规模数据集上表现优异。
BI及可视化工具集成
Apache Kylin提供了丰富的API,以与现有的BI工具集成,具体包括如下内容。
ODBC接口:与Tableau、Excel、Power BI等工具集成。JDBC接口:与Saiku、BIRT等Java工具集成。Rest API:与JavaScript、Web网页集成。
分析师可以沿用他们最熟悉的BI工具与Kylin一同工作,或者在开放的API上做二次开发和深度定制。
总结
传统技术,如大规模并行计算和列式存储的查询速度都在O(N)级别,与数据规模增长呈线性关系。
如果数据规模增长10倍,那么O(N)的查询速度就会下降到十分之一,无法满足日益增长的数据需求。依靠Apache Kylin,我们不用再担心查询速度会随着数据量的增长而减慢。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Ck7WUrl6-1648282042161)(Kylin.assets/image-20200428164151630.png)]](https://img-blog.csdnimg.cn/b68d74666e144b7d938cf7478fd73044.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5bKB5pyI55qE55y4,size_20,color_FFFFFF,t_70,g_se,x_16)
Kylin集群安装部署
kylin的安装
Kylin安装很简单,但是它需要一个极度健康的hadoop集群。我们必须把所依赖的hadoop、hive、hbase、zookeeper都安装好。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3dPUd0Kr-1648282042164)(Kylin.assets/wps8.jpg)]](https://img-blog.csdnimg.cn/11e28101f87d4c84bffd9395ba511368.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5bKB5pyI55qE55y4,size_20,color_FFFFFF,t_70,g_se,x_16)
https://archive.apache.org/dist/kylin/ 选择对应版本。
第一步:软件的下载与解压
tar -zxvf apache-kylin-2.5.0-bin-hbase1x.tar.gz
# 修改目录名称:
mv apache-kylin-2.5.0-bin-hbase1x kylin
注意:这里我们需要将原先的0.98版hbase替换成1.x的,这里选的是hbase-1.3.5.
替换hbase需要注意的事项:
第二步:配置kylin相关环境变量
export HIVE_HOME=/usr/local/src/hive-1.2.1
export HBASE_HOME=/usr/local/src/hbase-1.3.5
export HIVE_CONF_HOME=$HIVE_HOME/conf
export HCAT_HOME=$HIVE_HOME/hcatalog
export HADOOP_CONF_DIR=/usr/local/src/hadoop-2.6.5/etc/hadoop
export PATH=$HCAT_HOME/bin:$PATH
export KYLIN_HOME=/usr/local/src/kylin
export PATH=$HIVE_HOME/bin:$PATH
export PATH=$KYLIN_HOME/bin:$PATH
Tips:Kylin 会自动从环境中读取 Hadoop 配置(core-site.xml),Hive 配置(hive-site.xml)和 HBase 配置(hbase-site.xml)
第三步:修改配置文件
修改kylin.properties配置文件。此步骤在单节点时这一步可以忽略掉。
#配置节点类型(kylin节点模式分为all、query(查询模式)、job(任务构建模式))
kylin.server.mode=all
#kylin集群节点配置 (这里选一台)
kylin.server.cluster-servers=node03:7070
如果是集群多台节点配置的话,只能是由一台是job/all,其他台是query模式 。如下图所示:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YmktCOFq-1648282042168)(Kylin.assets/wps10.jpg)]](https://img-blog.csdnimg.cn/1807291e965b4bad94b8831d00cfee28.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5bKB5pyI55qE55y4,size_20,color_FFFFFF,t_70,g_se,x_16)
Kylin启动
使用kylin的前提是,kylin要有操作所有东西的权限,包括hdfs读写权限,hive创建表权限等各种权限,所以我们这边为了方便学习直接使用root用户来操作。
第一步:zookeerper启动
第二步:hadoop集群启动, jobhistoryserver启动
#启动集群:
start-all.sh
#启动jobhistory:
mr-jobhistory-daemon.sh start historyserver
Tips:MR的历史任务日志配置参数如下:
第三步:hbase集群启动
第四步 :hive启动
别忘记启动mysql服务。
service mysqld start
那么到这边,所有的依赖就算开启完毕了,可以通过check-env.sh进行检查。
确认无误后kylin.sh start 启动kylin服务。通过ip:7070/kylin的url地址进行访问。默认的用户名和密码为ADMIN和KYLIN
注意:查看kylin.log时若有如下错误:
[Thread-10] curator.ConnectionState:201 : Connection timed out for connection string (node01:2181:2181,node02:2181:2181,node03:2181:2181) and timeout (15000) / elapsed (57045)org.apache.curator.CuratorConnectionLossException: KeeperErrorCode = ConnectionLoss
这是由于:读取的是配置文件hbase-site.xml的hbase.zookeeper.quorum,该项只需配置Host不需要配置端口号Port,改回来之后重启hbase就好了。
![下图为登录页面 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iTSxPJ5V-1648282042169)(Kylin.assets/wps12.jpg)]](https://img-blog.csdnimg.cn/0c760dce375a4d6090d7389826151f35.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5bKB5pyI55qE55y4,size_20,color_FFFFFF,t_70,g_se,x_16)
Kylin的使用
简单案例
具体操作步骤
-
通过同步数据源
-
建立
project->建立model->建立cube->build cube。
导入Hive表
在我们本地机器上有一张kylin_sale表中数据为
1,2019-08-08,商场1,家电类,电脑,2,9000
2,2019-08-08,商场1,家电类,冰箱,3,3000
3,2019-08-08,商场1,家电类,洗衣机,6,3000
4,2019-08-08,商场1,日用品类,厨具四件套,10,500
5,2019-08-08,商场1,日用品类,锅碗瓢盆,5,200
6,2019-08-08,商场1,日用品类,洗洁精,8,240
7,2019-08-08,商场2,家电类,电脑,7,35000
8,2019-08-08,商场2,家电类,冰箱,4,4000
9,2019-08-08,商场2,家电类,洗衣机,5,5000
10,2019-08-08,商场2,日用品类,厨具四件套,8,500
11,2019-08-08,商场2,日用品类,锅碗瓢盆,9,360
12,2019-08-08,商场2,日用品类,洗洁精,10,900
13,2019-08-09,商场1,家电类,电脑,3,15000
14,2019-08-09,商场1,家电类,冰箱,4,3000
15,2019-08-09,商场1,家电类,洗衣机,5,3000
16,2019-08-09,商场1,日用品类,厨具四件套,6,500
17,2019-08-09,商场1,日用品类,锅碗瓢盆,7,350
18,2019-08-09,商场1,日用品类,洗洁精,8,240
19,2019-08-09,商场2,家电类,电脑,9,35000
20,2019-08-09,商场2,家电类,冰箱,5,3000
21,2019-08-09,商场2,家电类,洗衣机,8,5000
22,2019-08-09,商场2,日用品类,厨具四件套,3,300
23,2019-08-09,商场2,日用品类,锅碗瓢盆,8,320
24,2019-08-09,商场2,日用品类,洗洁精,9,900
Hive执行如下操作。创建kylin库及下kylin_sale表。
create database if not exists kylin;
use kylin;
create table kylin_sale(
id int,
day date,
market string,
category string,
item string,
number int,
sales int
)
row format delimited fields terminated by ','
lines terminated by '\n';
加载数据:
load data local inpath '/root/kylin_sale' overwrite into table kylin_sale;

创建project
第一步:在kylinweb页面创建project
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-L5yQXesi-1648282042171)(Kylin.assets/image-20200429151420257.png)]](https://img-blog.csdnimg.cn/9cf390690dfb47adb9fe2c2f8f9a06e6.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5bKB5pyI55qE55y4,size_20,color_FFFFFF,t_70,g_se,x_16)

第二步:将hive中事实表数据导入kylin;
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-c2nv9C1H-1648282042173)(Kylin.assets/image-20200429151734574.png)]](https://img-blog.csdnimg.cn/ee37ff56319345e18a978c932d0005f6.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5bKB5pyI55qE55y4,size_20,color_FFFFFF,t_70,g_se,x_16)
第三步:选择要加载的哪些实例库中的哪些表,这里加载kylin_sale表;
选择该表数据点击sync同步。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7D0vGqqc-1648282042176)(Kylin.assets/image-20200429152139959.png)]](https://img-blog.csdnimg.cn/b050b6ab75d545dbae21098e87a121e5.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5bKB5pyI55qE55y4,size_20,color_FFFFFF,t_70,g_se,x_16)
查看页面:
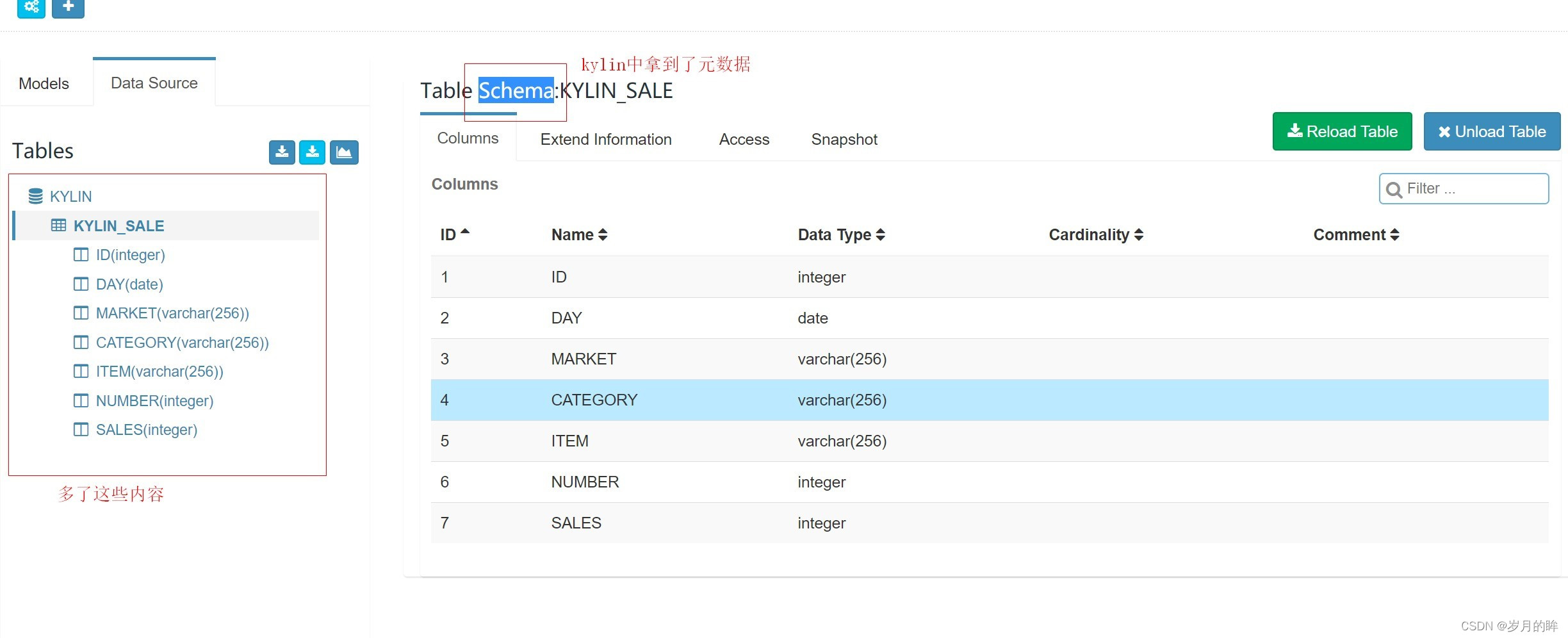
创建模型model
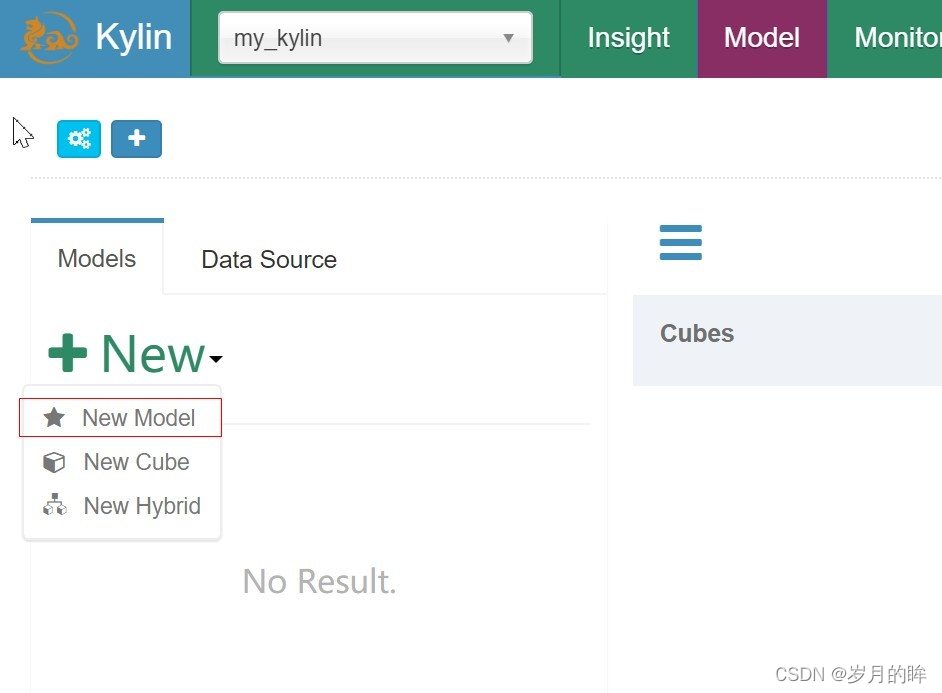
如上图:点击 new model,出现以下视图:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MBsgnW6f-1648282042180)(Kylin.assets/image-20200429152424329.png)]](https://img-blog.csdnimg.cn/cb8565afa9d94a19816bb39490e5d921.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5bKB5pyI55qE55y4,size_20,color_FFFFFF,t_70,g_se,x_16)
给model起个名字,然后点击next;
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CIiX32vn-1648282042181)(Kylin.assets/image-20200429152512415.png)]](https://img-blog.csdnimg.cn/b75df78932634d54ae4e96ea28ae14a7.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5bKB5pyI55qE55y4,size_20,color_FFFFFF,t_70,g_se,x_16)
如上图所示:选择事实表。然后进入下一步,进入到选择维度字段页面,如下图所示:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-c2tM9RpV-1648282042184)(Kylin.assets/image-20200429152648002.png)]](https://img-blog.csdnimg.cn/f791ba441c5a45e19625805586113433.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5bKB5pyI55qE55y4,size_20,color_FFFFFF,t_70,g_se,x_16)
在这里,我们选择day,market,category,item四个维度,即我们将从这四个维度来统计分析商品的销售额情况.
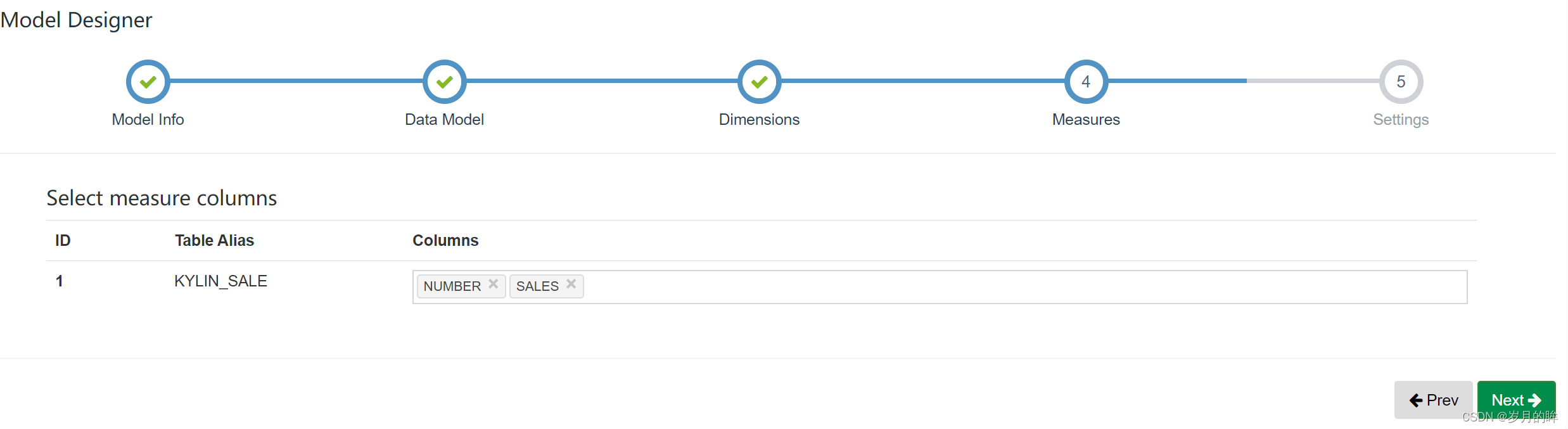
点击next进入到measure(度量)页面,在这里我们选择number和sales字段,即我们将统计商品数量和商品销售额两个指标。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CVsyXFUK-1648282042185)(Kylin.assets/image-20200429152721951.png)]](https://img-blog.csdnimg.cn/89354d11512f44bf8a3d781eb19ebbe7.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5bKB5pyI55qE55y4,size_20,color_FFFFFF,t_70,g_se,x_16)
最后进入到设置页面,我们可以选择分区字段,选择格式化时间方式, 下面的filter可以添加where条件对数据源中的数据做过滤,最后点击save保存,既model创建成功。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-u3ycU89M-1648282042187)(Kylin.assets/image-20200429153010608.png)]](https://img-blog.csdnimg.cn/06c81070ea8d41b6ab1087733768514a.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5bKB5pyI55qE55y4,size_20,color_FFFFFF,t_70,g_se,x_16)
创建cube
![ [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eF1DFUhW-1648282042189)(Kylin.assets/image-20200429153301040.png)]](https://img-blog.csdnimg.cn/200882d7439b43de8f57c11bef9e4984.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5bKB5pyI55qE55y4,size_20,color_FFFFFF,t_70,g_se,x_16)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lIKmBkJb-1648282042191)(Kylin.assets/image-20200429153437790.png)]](https://img-blog.csdnimg.cn/a2d7bab9d5884d338394d8467eff0127.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5bKB5pyI55qE55y4,size_20,color_FFFFFF,t_70,g_se,x_16)
如上图所示:指明要创建的cube在哪个model下,并且对cube进行命名,然后点击下一步。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Mn9yof8I-1648282042194)(Kylin.assets/image-20200429153617721.png)]](https://img-blog.csdnimg.cn/6742ff6a6239477b9fdc0efe2969fd12.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5bKB5pyI55qE55y4,size_20,color_FFFFFF,t_70,g_se,x_16)
如上图所示,对本次cube添加计算的维度,进入到如下页面,我们选择select all 所有4个维度。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NmlWa0n4-1648282042195)(Kylin.assets/image-20200429153557040.png)]](https://img-blog.csdnimg.cn/496e7aa2b6e14b84bb0c768a36d0d15c.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5bKB5pyI55qE55y4,size_20,color_FFFFFF,t_70,g_se,x_16)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uTLesjbe-1648282042197)(Kylin.assets/image-20200429153654650.png)]](https://img-blog.csdnimg.cn/c7cccd33ea8e494aa937d23a798be007.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5bKB5pyI55qE55y4,size_20,color_FFFFFF,t_70,g_se,x_16)
指定要进行计算的度量指标(Measures)如下图:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Ci5yxPCT-1648282042198)(Kylin.assets/image-20200429153744428.png)]](https://img-blog.csdnimg.cn/9122a972ef4e47b2a81439d4378590bf.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5bKB5pyI55qE55y4,size_20,color_FFFFFF,t_70,g_se,x_16)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Wqb2K37z-1648282042202)(Kylin.assets/image-20200429153925119.png)]](https://img-blog.csdnimg.cn/f1ae17f57d004edabe47411d17a5e275.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5bKB5pyI55qE55y4,size_20,color_FFFFFF,t_70,g_se,x_16)
在这里,我们先创建一个销售额度指标,即对销售字段进行sum累加,如上图所示 1,2,3,4步骤。同时我们再创建一个商品数量指标如下图所示:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OnPIxtHz-1648282042203)(Kylin.assets/image-20200429154033084.png)]](https://img-blog.csdnimg.cn/d098791c60f8446387d9d423ac06fa1d.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5bKB5pyI55qE55y4,size_20,color_FFFFFF,t_70,g_se,x_16)
最终我们会看见两个度量指标(measures)如下图:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AMc4TVIH-1648282042205)(Kylin.assets/image-20200429154355061.png)]](https://img-blog.csdnimg.cn/4f3322016ec24003b030ab4bdc0a3af6.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5bKB5pyI55qE55y4,size_20,color_FFFFFF,t_70,g_se,x_16)
接着一直点击下一步,最终保存cube。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-m1tQzOM3-1648282042206)(Kylin.assets/image-20200429154334830.png)]](https://img-blog.csdnimg.cn/2d713887b01149c785d242f910b12f17.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5bKB5pyI55qE55y4,size_20,color_FFFFFF,t_70,g_se,x_16)
构建cube
新创建的Cube只有定义,而没有计算的数据,它的状态是DISABLED,是不会被查询引擎挑中的。要想让Cube有数据,还需要对它进行构建build。Cube的构建方式通常有两种:全量构建和增量构建;两者的构建步骤是完全一样的,区别只在于构建时读取的数据源是全集还是子集。
点击build,对定义好的cube进行构建计算。构建计算完cube后,就可以在Insight页面进行查询操作。
Kylin的Cube创建过程详解
-
创建临时的
Hive平表(从Hive读取数据)。 -
计算各维度的不同值,并收集各
Cuboid的统计数据。 -
创建并保存字典。
-
保存
Cuboid统计信息。 -
创建
HTable。 -
计算
Cube(一轮或若干轮MapReduce)。 -
将
Cube的计算结果转成HFile。 -
加载
HFile到HBase。 -
更新
Cube元数据。 -
垃圾回收。
kylin查询api
之前我们成功创建了kylin的cube,并且可以使用web ui查询.但除了通过web ui进行操作,我们还可以使用api调用。
RestFul API
在使用之前,我们要先进行认证,目前Kylin使用basic Authentication。Basic Authentication是一种非常简单的访问控制机制,它先对账号密码基于Base64编码,然后将其作为请求头添加到HTTP请求头中,后端会读取请求头中的账号密码信息以进行认证。
以Kylin默认的账号密码ADMIN/KYLIN为例,对相应的账号密码进行编码后,结果为Basic QURNSU46S1lMSU4=,那么HTTP对应的头信息 则为Authorization:Basic QURNSU46S1lMSU4=。
查询SQL
curl -X POST -H "Authorization: Basic QURNSU46S1lMSU4=" -H 'Content-Type: application/json' http://localhost:7070/kylin/api/query -d '{
"sql":"select market,sum(sales) from kylin_sale group by market",
"offset":0,
"limit":10,
"acceptPartial":false,
"project":"my_kylin"
}'
参数解释:
sql:必填,字符串类型,请求的SQL。offset:可选,整型,查询默认从第一行返回结果,可以设置该参数以决定返回数据从哪一行开始往后返回。limit:可选,整型,加上limit参数后会从offset开始返回对应的行数, 返回数据行数小于limit的将以实际行数为准。acceptPartial:可选,布尔类型,默认是true,如果为true,那么实际上最多会返回一百万行数据;如果要返回的结果集超过了一百万行,那么 该参数需要设置为false。project:可选,字符串类型,默认为DEFAULT,在实际使用时,如 果对应查询的项目不是DEFAULT,那就需要设置为自己的项目。
Put提交cube
curl -X PUT -H "Authorization: Basic QURNSU46S1lMSU4=" -H 'Content-Type: application/json' http://localhost:7070/kylin/api/cubes/my_cube/build -d '{
"startTime":0,
"endTime":"$endTime",
"buildType":"BUILD"
}'
上面的内容里面,url里面的my_cube是你自己的cube名,endTime是你需要去指定的,startTime : 当cube中不存在segment时,可以将其设置为0,那么就会从头开始算。做增量时,startTime 要设置为上一次build的endTime。endTime:时间精确到毫秒(例1388563200000)。
buildType:可选BUILD,MERGE,REFRESH 。
注意点
我们在通过RESTful API向kylin进行build和rebuild的时候一定要观察kylin的web界面下面的Montior进程,否知一不小心运行太多进程导致服务器崩掉。
我们可以通过
curl -X GET -H "Authorization: Basic xxxxxxxx=" -H 'Content-Type: application/json' http://localhost:7070/kylin/api/jobs/{job_uuid}
来跟踪任务状态返回的 job_status 代表job的当前状态。Uuid是cube提交build时返回的json格式数据中获得。形如:7da54847-ce51-1e43-156a-a9c92a7123e0。
如果构建过程中出现错误,执行如下进行任务的重新执行。指定对应uuid的任务。
curl -X PUT -H "Authorization: Basic xxxxxxxx=" -H "Content-Type: application/json" http://localhost:7070/kylin/api/jobs/{job_uuid}/resume
JAVA API
JDBC连接方式
和hive、mysql很相似。
package com.xxxx.kylin;
import java.io.IOException;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.Properties;
import org.apache.kylin.jdbc.Driver;
public class KylinJdbc {
public void connentJdbc()
throws InstantiationException, IllegalAccessException, ClassNotFoundException, SQLException {
Driver driver = (Driver) Class.forName("org.apache.kylin.jdbc.Driver").newInstance();
Properties info = new Properties();
info.put("user", "ADMIN");
info.put("password", "KYLIN");
Connection conn = driver.connect("jdbc:kylin://*.*.*.*:7070/learn_kylin", info);
Statement state = conn.createStatement();
ResultSet resultSet = state.executeQuery("select * from kylin_account limit 1000");
while (resultSet.next()) {
String i = resultSet.getString(3);
System.out.println(i);
}
}
public static void main(String[] args)
throws IOException, InstantiationException, IllegalAccessException, ClassNotFoundException, SQLException {
KylinJdbc ky = new KylinJdbc();
ky.connentJdbc();
}
}
增量Cube
Cube划分为多个Segment,每个Segment用起始时间和结束时间来标志。Segment代表一段时间内源数据的预计算结果。在大部分情况下一个Segment的起始时间等于它之前那个Segment的结束时间,同理,它的结束时间等于它后面那个Segment的起始时间。
同一个Cube下不同的Segment除了背后的源数据不同之外,其他如结构定义、构建过程、优化方法、存储方式等都完全相同。
为什么要增量构建
为什么要增量构建存在唯一的一个Segment,该Segment没有分割时间的概念,因此也就没有起始时间和结束时间。全量构建和增量构建各有其适用的场景,用户可以根据自己的业务场景灵活地进行切换。全量构建和增量构建的详细对比如下图:
对于全量构建来说,每当需要更新Cube数据的时候,它不会区分历史数据和新加入的数据,也就是说,在构建的时候会导入并处理所有的原始数据。
而增量构建只会导入新Segment指定的时间区间内的原始数据,并只对这部分原始数据进行预计算。
设计增量构建的前提
并非所有的Cube都适用于增量构建,Cube的定义必须包含一个时间维度,用来分割不同的Segment,我们将这样的维度称为分割时间列 (Partition Date Column)。分割时间列既可以是Hive中的Date类型、也可以是Timestamp类型或 String类型。无论是哪种类型,Kylin都要求用户显式地指定分割时间列的数据格式,例如精确到年月日的Date类型(或者String类型)的数据格式可能是yyyyMMdd或yyyy-MM-dd,如果是精确到时分秒的Timestamp类型(或者String类型),那么数据格式可能是YYYY-MM-DD HH:MM:SS。
触发增量构建
在Web UI上触发Cube的增量构建与触发全量构建的方式基本相同。在Web UI的Model页面中,选中想要增量构建的Cube,单击 Action→Build。
不同于全量构建,增量构建的Cube会在此时弹出对话框让用户选择End Date。 Kylin要求增量Segment的起始时间等于 Cube中最后一个Segment的结束时间,因此当我们为一个已经有Segment 的Cube触发增量构建的时候,Start Date的值已经被确定,且不能修改。
仅当Cube中不存在任何Segment,或者不存在任何未完成的构建任务 时,Kylin才接受该Cube上新的构建任务。
而如果不是web GUI触发,你通过restAPI触发的话,那么要确保你给定的时间,不重合。

自动合并
在Cube Designer的Refresh Settings的页面中有Auto Merge Thresholds和Retention Threshold两个设置项可以用来帮助管理Segment碎片。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LL8DzJ6d-1648282042211)(Kylin.assets/image-20200425111356937.png)]](https://img-blog.csdnimg.cn/72b4b6d239894d7b80361635abb2721c.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5bKB5pyI55qE55y4,size_20,color_FFFFFF,t_70,g_se,x_16)
Auto Merge Thresholds允许用户设置几个层级的时间阈值,层级越靠后,时间阈值就越大。举例来说,用户可以为一个Cube指定(7天、28天)这样的层级。每当Cube中有新的Segment状态变为READY的时候,就会触发一次系统试图自动合并的尝试。系统首先会尝试最大一级的时间阈值,结合上面的(7天、28天)层级的例子,首先查看是否能将连续的若干个Segment合并成为一个超过28天的大Segment,在挑选连续Segment的过程中,如果遇到已经有个别Segment的时间长度本身已经超过了28天,那么系统会跳过该Segment,从它之后的所有Segment中挑选连续的累积超过28天的Segment。如果满足条件的连续Segment还不能够累积超过28天,那么系统会使用下一个层级的时间阈值重复寻找的过程。每当找到了能够满足条件的连续Segment,系统就会触发一次自动合并Segment的构建任务,在构建任务完成之后,新的Segment被设置为READY状态,自动合并的整套尝试又需要重新再来一遍。
举例来说,如果现在有A~H8个连续的Segment,它们的时间长度分别 为28天(A)、7天(B)、1天(C)、1天(D)、1天(E)、1天(F)、1天(G)、1天 (H)。此时第9个Segment I加入,它的时间长度为1天,那么现在Cube中总 共存在9个Segment。系统首先尝试能否将连续的Segment合并到28天这个阈值上,由于Segment A已经超过28天,它会被排除。
接下来的B到H加起 来也不足28天,因此第一级的时间阈值无法满足,退一步系统尝试第二级的时间阈值,也就是7天。系统重新扫描所有的Segment,发现A和B已经超过7天,因此跳过它们,接下来发现将Segment C到I合并起来可以达到7 天的阈值,因此系统会提交一个合并Segment的构建请求,将Segment C到I 合并为一个新的Segment X。X的构建完成之后,Cube中只剩下三个 Segment,分别是原来的A(28天),B(7天)和新的X(7天)。由于X的加入,触发了系统重新开始整个合并尝试,但是发现已经没有满足自动合并的条件,既没有连续的、满足条件的、累积超过28天的Segment,也没有连续的、满足条件的、累积超过7天的Segment,尝试终止。
保留Segment
从碎片管理的角度来说,自动合并是将多个Segment合并为一个 Segment,以达到清理碎片的目的。保留Segment则是从另外一个角度帮助实现碎片管理,那就是及时清理不再使用的Segment。
在很多业务场景 中,只会对过去一段时间内的数据进行查询,例如对于某个只显示过去1 年数据的报表,支撑它的Cube事实上只需要保留过去一年内的Segment即可。由于数据在Hive中往往已经存在备份,因此无需再在Kylin中备份超过一年的历史数据。
在这种情况下,我们可以将Retention Threshold设置为365。每当有新的Segment状态变为READY的时候,系统会检查每一个Segment:如果它的结束时间距离最晚的一个Segment的结束时间已经大于Retention Threshold,那么这个Segment将被视为无需保留。系统会自动地从Cube中 删除这个Segment。
如果启用了Auto Merge Thresholds,那么在使用Retention Threshold的时候需要注意,不能将Auto Merge Thresholds的最大层级设置得太高。假设我们将Auto Merge Thresholds的最大一级设置为1000天,而将Retention Threshold设置为365天,那么受到自动合并的影响, 新加入的Segment会不断地被自动合并到一个越来越大的Segment之中,但是这样会导致kylin要去不断地更新这个大Segment的结束时间,从而导致这个大 Segment永远不会得到释放。因此,推荐自动合并的最大一级的时间不要超过1年。
数据持续更新
在实际应用场景中,我们常常会遇到这样的问题:由于ETL过程的延迟,业务每天都需要刷新过去N天的Cube数据。
举例来说,客户有一个报表每天都需要更新,但是每天的源数据更新不仅包含了当天的新数据, 还包括了过去7天内数据的补充。
一种比较简单的方法是,每天在Cube中增量构建一个长度为一天的Segment,这样过去7天的数据就会以7个 Segment的形式存在于Cube之中。Cube的管理员除了每天要创建一个新的 Segment代表当天的新数据(BUILD操作)以外,还需要对代表过去7天的7个Segment进行刷新(REFRESH操作,Web UI上的操作及Rest API参数与 BUILD类似,这里不再详细展开)。这样的方法固然可以奏效,但是每天为每个Cube触发的构建数量太多,容易造成Kylin的任务队列堆积大量未能完成的任务。
上述简单方案的另外一个弊端是,每天一个Segment也会让Cube中迅速地累积大量的Segment,需要Cube管理员手动地对历史已经超过7天的 Segment进行合并,期间还必须小心地操作,不能错将7天内的Segment一 起合并了。
举例来说,假设现在有100个Segment,每个Segment代表过去的一天的数据,Segment按照起始时间排序。在合并时,我们只能挑选前面 93个Segment进行合并,如果不小心把第94个Segment也一起合并了,那么 当我们试图刷新过去7天(94100)的`Segment`的时候,会发现为了刷新第94天的数据,不得不将193的数据一并重新计算,这对于刷新来说是一种极大的浪费。而且最差的情况就是即使使用之前所介绍的自动合并的功能,类似的问题也仍然存在。
解决思路:
不以日为单位创建新的Segment, 而是以N天为单位创建新的Segment。
举例来说,假设用户每天更新Cube 的时候,前面7天的数据都需要更新一下,也就是说,如果今天是01-08, 那么用户不仅要添加01-08的新数据,还要同时更新01-01到01-07的数据。在这种情况下,可设置N=7作为最小Segment的长度。在第一天01-01, 创建一个新的Segment A,它的时间是从01-01到01-08,我们知道Segment 是起始时间闭,结束时间开,因此Segment A的真实长度为7天,也就是01-01到01-07。即使在01-01当天,还没有后面几天的数据,Segment A也能正 常地构建,只不过构建出来的Segment其实只有01-01一天的数据而已。从 01-02到01-07的每一天,我们都要刷新Segment A,以保证1日到7日的数据保持更新。由于01-01已经是最早的日期,所以不需要对更早的数据进行更新。
到01-08的时候,创建一个新的Segment B,它的时间是从01-08到01-15。此时我们不仅需要构建Segment B,还需要去刷新Segment A。因为01-01到01-07中的数据在01-08当天仍然可能处于更新状态。在接下来的01-09到01-14,每天刷新A、B两个Segment。等到了01-15这天的时候,首先创建一个新的Segment C,它的时间是从01-15到01-22。在01-15当天, Segment A的数据应当已经被视作最终状态,因为Segment A中的最后一天 (01-07)已经不再过去N天的范围之内了。因此此时接下来只需要照顾 Segment B和Segment C即可。
由此可以看到,在任意一天内,我们只需要同时照顾两个Segment, 第一个Segment主要以刷新近期数据为主,第二个Segment则兼顾了加入新数据与刷新近期数据。这个过程中可能存在少量的多余计算,但是每天多余计算的数据量不会超过N天的数据量。这对于Kylin整体的计算量来说是可以接受的。根据业务场景的不同,N可能是7天,也有可能是30天,我们可以适度地把最小的Segment设置成比N稍微大一点的数字。
例如N为7的时候,我们可以设置为10天,这样即使ETL有时候没有能够遵守N=7的约定,也仍然能够刷新足够的数据。
cuboid以及cube优化
再来回顾一下kylin中这两个名词的描述。
Cuboid = one combination of dimensions
Cube = all combination of dimensions (all cuboids)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tIjIPwNL-1648282042212)(Kylin.assets/image-20200425112343171.png)]](https://img-blog.csdnimg.cn/ed4025e19ff24de1b482fcf0c6954d4d.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5bKB5pyI55qE55y4,size_20,color_FFFFFF,t_70,g_se,x_16)
按照dimension大小顺序排序,从Base Cuboid开始,依次基于上一层Cuboid的结果进行再聚合。每一层的计算都是一个单独的Map Reduce(Spark)任务。
理论上来说,一个N维的Cube,便有2的N次方种维度组合,参考kylin官网上的一个例子,一个Cube包含time, item, location, supplier四个维度,那么组合(Cuboid)便有16种。
一个Cube中,当维度数量N超过一定数量后,空间以及计算消耗将会非常大,比如说10维那就是1024个cuboid,但我们真正查询的时候可能只会用到其中的100个cuboid,如果不做优化那么会出现以下几个问题
-
会使得
Build出来的Cube Size很大,从而占用大量的磁盘空间; -
Cube Building的时间会很长 ; -
会占用集群的计算资源 。
Cube剪枝优化
聚合组Aggravation Group
Kylin在定义Cube时候,可以将维度拆分成多个聚合组(Aggregation Groups)这也就是我们在web页面创建cube时的第5步可以做,只在组内计算Cube,聚合组内查询效率高,跨组查询效率较差,所以需要根据业务场景,将常用的维度组合定义到一个聚合组中,提高查询性能,这也是Kylin中查询性能优化的一个重要方面。
举例:
业务场景有4个维度,分别为ABCD,如果聚合组含有的维度为ABCD的话,它的Cuboid为24=16个。但是此时如果AB是一个聚合组,CD是一个聚合组,那么Cuboid的个数就是22+22=8个,相当于缩减了一半。即原来2(K+M+N)个Cuboid可以减少到2K+2M+2^N个。
查看cube所生成的cuboid个数命令如下:
kylin.sh org.apache.kylin.engine.mr.common.CubeStatsReader CubeName
强制维度(Mandatory Dimensions)
如果一个维度被定义为强制维度,那么这个分组产生的所有Cuboid中每一个Cuboid都会包含该维度。如果根据这个分组的业务逻辑,相关的查询一定会在过滤条件或分组条件中,则可以在该分组中把该维度设置为强制维度。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3ljG8482-1648282042214)(Kylin.assets/image-20200425112650302.png)]](https://img-blog.csdnimg.cn/15a2a3040a764c27bb4a0e46e6c33c78.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5bKB5pyI55qE55y4,size_20,color_FFFFFF,t_70,g_se,x_16)
层次维度(Hierarchy Dimensions)
何为层次维度,具有上下级层次关系的维度,例如时间维度 年—>月—>日,和地区维度 国家(country)—>省份(province)—> 城市(city)。将有这样关系的维度设置为层次关系,并且将它们设置为层次维度的话,cuboid数量将下降。
举例:
如果有三个维度A,B,C 设置为层次维度,那么Cuboid数量将由2^3减为3+1(ABC、AB、A、空)。
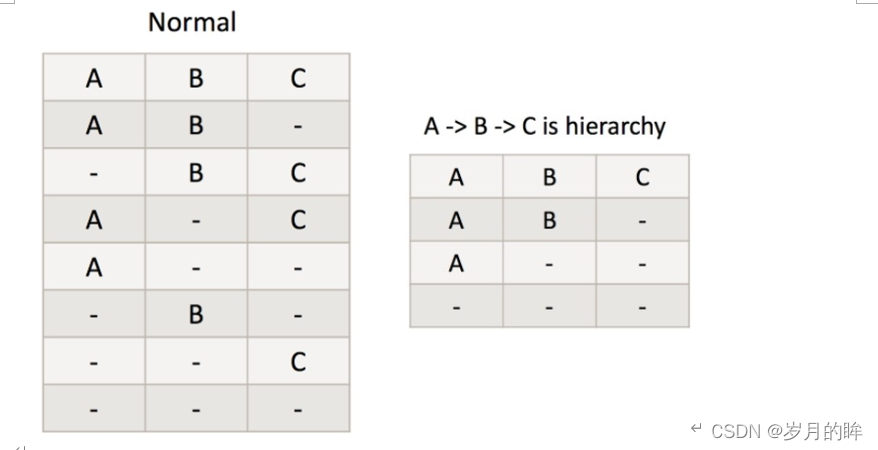
对应的group by就变成了如下三种情况
group by country, province, city(等同于 group by country, city 或者group by city)
group by country, province(等同于group by province)
group by country。
Hive里面的数据以时间作为分区,每天处理增量数据,那么我们kylin也要每天增量写入数据。
联合维度(Joint Dimensions)
每个联合中包含两个或更多个维度,如果某些列形成一个联合,那么在该分组产生的任何Cuboid中,这些联合维度要么一 起出现,要么都不出现。如果根据这个分组的业务逻辑,多个维度在查询中总是同时出现,则可以在该分组中把这些维度设置为联合维度。
例子:如有 A B C D 四个维度, B C维度作为联合维度,则最后只要生成7个维度,如下图所示:其中红色维度为无需生成的维度,黑色维度为需要生成的维度
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-o3OiNb0v-1648282042216)(Kylin.assets/image-20200425112931453.png)]](https://img-blog.csdnimg.cn/bdd0612120ba40aab88162a2eed5d787.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5bKB5pyI55qE55y4,size_20,color_FFFFFF,t_70,g_se,x_16)
衍生维度
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2onjW6c9-1648282042219)(Kylin.assets/image-20200425112945443.png)]](https://img-blog.csdnimg.cn/5e5cdde93c82472b8ac4f9bbe0f45c90.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5bKB5pyI55qE55y4,size_20,color_FFFFFF,t_70,g_se,x_16)
时间维度表,里面充斥着用途各异的时间维度,例如每个日期所处的季度、月份等。这些维度可以被地用来进行各个时间粒度上的聚合分析,而不需要进行额外的上卷(Roll Up)操作。但是为了这个目的一下子引入这么多个维度,导致 Cube中总共的Cuboid数量呈现爆炸式的增长往往是得不偿失的。
当用户需要以更高的粒度(比如按周、 按月)来聚合时,如果在查询时获取按日聚合的Cuboid数据,并在查询引擎中实时地进行上卷操作,那么就达到了使用牺牲一部分运行时性能来节省Cube空间占用的目的。
Kylin将这样的理念包装成为了一个简单的优化工具——衍生维度。
衍生维度用于在有效维度内将维度表上的非主键维度排除掉,并使用维度表的主键(其实是事实表上相应的外键)来替代它们。Kylin会在底层记录维度表主键与维度表其他维度之间的映射关系,以便在查询时能够动 态地将维度表的主键翻译成这些非主键维度,并进行实时聚合。
例如,假设有一个日期查找表,其中的cal_dt是主键列,还有许多派生列,例如week_begin_dt,mont9h_begin_dt。即使分析人员需要week_begin_dt作为维度,我们也可以对其进行修剪,因为它始终可以从cal_dt维度进行计算,这是“派生”优化。
Rowkey编码优化
编码(Encoding)代表了该维度的值应使用何种方式进行编码,合适的编码能够减少维度对空间的占用,例如,我们可以把所有的日期都用三个字节进行编码,相比于字符串存储,或者是使用长整数形式存储的方法,我们的编码方式能够大大减少每行Cube数据的体积。而Cube中可能存在数以亿计的行数,使用编码节约的空间累加起来将是一个非常巨大的数字。
目前Kylin支持的编码方式有以下几种:
Date编码:将日期类型的数据使用三个字节进行编码,其支持从000-01-01到9999-01-01中的每一个日期。Time编码:仅支持表示从1970-01-01 00:00:00到2038-01-19 03:14:07的时间,且Time-stamp类型的维度经过编码和反编码之后,会失去毫秒信息,所以说Time编码仅仅支持到秒。但是Time编码的优势是每个维度仅仅使用4个字节,这相比普通的长整数编码节约了一半。如果能够接受秒级的时间精度,请选择Time编码来代表时间的维度。Integer编码:Integer编码需要提供一个额外的参数Length来代表需要多少个字节。Length的长度为1~8。如果用来编码int32类型的整数,可以将Length设为4;如果用来编码int64类型的整数,可以将Length设为8。在更多情况下,如果知道一个整数类型维度的可能值都很小,那么就能使用Length为2甚至是1的int编码来存储,这将能够有效避免存储空间的浪费。Dict编码:对于使用该种编码的维度,每个Segment在构建的时候都会为这个维度所有可能的值创建一个字典,然后使用字典中每个值的编 号来编码。Dict的优势是产生的编码非常紧凑,尤其在维度值的基数较小且长度较大的情况下,特别节约空间。由于产生的字典是在查询时加载入构建引擎和查询引擎的,所以在维度的基数大、长度也大的情况下,容易造成构建引擎或查询引擎的内存溢出。Fixed_length编码:编码需要提供一个额外的参数Length来代表需 要多少个字节。该编码可以看作Dict编码的一种补充。对于基数大、长度也大的维度来说,使用Dict可能不能正常工作,于是可以采用一段固定长度的字节来存储代表维度值的字节数组,该数组为字符串形式的维度值的UTF-8字节。如果维度值的长度大于预设的Length,那么超出的部分将会被截断。Fixed_Length_Hex编码:适用于字段值为十六进制字符,比如1A2BFF或者FF00FF,每两个字符需要一个字节。只适用于varchar或nvarchar类型。
类型的维度经过**编码**和**反编码**之后,会失去毫秒信息,所以说Time编码仅仅支持到**秒**。但是Time编码的优势是每个维度仅仅使用**4个字节**,这相比普通的长整数编码**节约了一半**。如果能够接受秒级的时间精度,请选择Time`编码来代表时间的维度。
Integer编码:Integer编码需要提供一个额外的参数Length来代表需要多少个字节。Length的长度为1~8。如果用来编码int32类型的整数,可以将Length设为4;如果用来编码int64类型的整数,可以将Length设为8。在更多情况下,如果知道一个整数类型维度的可能值都很小,那么就能使用Length为2甚至是1的int编码来存储,这将能够有效避免存储空间的浪费。Dict编码:对于使用该种编码的维度,每个Segment在构建的时候都会为这个维度所有可能的值创建一个字典,然后使用字典中每个值的编 号来编码。Dict的优势是产生的编码非常紧凑,尤其在维度值的基数较小且长度较大的情况下,特别节约空间。由于产生的字典是在查询时加载入构建引擎和查询引擎的,所以在维度的基数大、长度也大的情况下,容易造成构建引擎或查询引擎的内存溢出。Fixed_length编码:编码需要提供一个额外的参数Length来代表需 要多少个字节。该编码可以看作Dict编码的一种补充。对于基数大、长度也大的维度来说,使用Dict可能不能正常工作,于是可以采用一段固定长度的字节来存储代表维度值的字节数组,该数组为字符串形式的维度值的UTF-8字节。如果维度值的长度大于预设的Length,那么超出的部分将会被截断。Fixed_Length_Hex编码:适用于字段值为十六进制字符,比如1A2BFF或者FF00FF,每两个字符需要一个字节。只适用于varchar或nvarchar类型。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-o0xmzzCc-1648282042220)(Kylin.assets/image-20200425113449414.png)]](https://img-blog.csdnimg.cn/ccce4cc0c378461abf7a52a15c69a59c.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5bKB5pyI55qE55y4,size_20,color_FFFFFF,t_70,g_se,x_16)















 941
941











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









