






参考:pytorch练习:泰坦尼克号生存预测 - 知乎 (zhihu.com)
一、获取数据集
二、预处理
三、dataset
四、model
五、训练
六、预测
一、获取数据集
House Prices - Advanced Regression Techniques | Kaggle

二、预处理
#https://zhuanlan.zhihu.com/p/338974416
import re
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import os
train = pd.read_csv('data/data_ original/train.csv') #训练集
test = pd.read_csv('data/data_ original/test.csv') # 测试集
print('训练集:', train.shape, '测试集:', test.shape)
# 合并训练集和测试集
total_data = train._append(test, sort=False, ignore_index=True)
# 查看数据摘要信息
print("查看数据摘要信息")
print("{train.info()}")
print("-" * 40)
print("{test.info()}")
# 查看生存比例
total_data['Survived'].value_counts().plot.pie(autopct='%1.2f%%')
plt.show()
# 查看不同性别的人员存活率
print(total_data.groupby(['Sex'])['Survived'].agg(['count', 'mean']))
plt.figure(figsize=(10, 5))
sns.countplot(x='Sex', hue='Survived', data=total_data)
plt.title('Sex and Survived')
plt.show()
# 查看Embarked列值分布
print(f"查看Embarked列值分布:\n{total_data['Embarked'].value_counts()}")
# 用众数填充Embarked空值
total_data['Embarked'].fillna(
total_data.Embarked.mode().values[0], inplace=True)
#
print(f"查看不同上船地人员的存活率:\n{total_data.groupby(['Embarked'])['Survived'].agg(['count', 'mean'])}")
plt.figure(figsize=(10, 5))
sns.countplot(x='Embarked', hue='Survived', data=total_data)
plt.title('Embarked and Survived')
plt.show()
#C地登船的存活率最高、其次为Q地登船、S地登船人数最多但存活率仅有1/3
# Cabin缺失比较多,用Unknown替代缺失值
total_data['Cabin'].fillna('U', inplace=True)
total_data['Cabin'] = total_data['Cabin'].map(
lambda x: re.compile('([a-zA-Z]+)').search(x).group())
print(total_data.groupby(['Cabin'])['Survived'].agg(['count', 'mean']))
plt.figure(figsize=(10, 5))
sns.countplot(x='Cabin', hue='Survived', data=total_data)
plt.title('Cabin and Survived')
plt.show()
# 不同票等级生存的分布
print(total_data.groupby(['Pclass'])['Survived'].agg(['count', 'mean']))
# 不同票等级生存的几率
plt.figure(figsize=(10, 5))
sns.countplot(x='Pclass', hue='Survived', data=total_data)
plt.title('Pclass and Survived')
plt.show()
#票等级越高存活率就越高;3等级的人数占比超50%,但存活率不到1/3
# Cabin缺失比较多,用Unknown替代缺失值
total_data['Cabin'].fillna('U', inplace=True)
total_data['Cabin'] = total_data['Cabin'].map(
lambda x: re.compile('([a-zA-Z]+)').search(x).group())
print(total_data.groupby(['Cabin'])['Survived'].agg(['count', 'mean']))
#船舱票无信息的群体存活率仅0.3;船舱票B/D/E存活率较高均超70%
plt.figure(figsize=(10, 5))
sns.countplot(x='Cabin', hue='Survived', data=total_data)
plt.title('Cabin and Survived')
plt.show()
# 不同票等级生存的分布
print(total_data.groupby(['Pclass'])['Survived'].agg(['count', 'mean']))
# 不同票等级生存的几率
plt.figure(figsize=(10, 5))
sns.countplot(x='Pclass', hue='Survived', data=total_data)
plt.title('Pclass and Survived')
plt.show()
#票等级越高存活率就越高;3等级的人数占比超50%,但存活率不到1/3
#不同仓位男女生存的几率
print(total_data[['Sex', 'Pclass', 'Survived']].groupby(
['Pclass', 'Sex']).agg(['count', 'mean']))
total_data[['Sex', 'Pclass', 'Survived']].groupby(
['Pclass', 'Sex']).mean().plot.bar(figsize=(10, 5))
plt.xticks(rotation=0)
plt.title('Sex, Pclass and Survived')
plt.show()
# 查看票价分布
plt.figure(figsize=(10, 5))
total_data['Fare'].hist(bins=70)
plt.title('Fare distribution')
plt.show()
#票价集中在低档区
# 价格区间
bins_fare = [0, 8, 14, 31, 515]
total_data['Fare_bin'] = pd.cut(total_data['Fare'], bins_fare, right=False)
# 各价格区间存活率
print(total_data[['Fare_bin', 'Survived']].groupby(
'Fare_bin')['Survived'].agg(['count', 'mean']))
plt.figure(figsize=(10, 5))
sns.countplot(x='Fare_bin', hue='Survived', data=total_data)
plt.title('Fare and Survived')
plt.show()
# 查看不同票等级的价格分布
total_data.boxplot(column='Fare', by='Pclass',
showfliers=False, figsize=(10, 5))
plt.show()
# 对票的等级按不同价格细分
def pclass_fare_category(df, pclass1_mean_fare, pclass2_mean_fare, pclass3_mean_fare):
if df['Pclass'] == 1:
if df['Fare'] <= pclass1_mean_fare:
return 'Pclass1_Low'
else:
return 'Pclass1_High'
elif df['Pclass'] == 2:
if df['Fare'] <= pclass2_mean_fare:
return 'Pclass2_Low'
else:
return 'Pclass2_High'
elif df['Pclass'] == 3:
if df['Fare'] <= pclass3_mean_fare:
return 'Pclass3_Low'
else:
return 'Pclass3_High'
Pclass_mean = total_data['Fare'].groupby(by=total_data['Pclass']).mean()
Pclass1_mean_fare = Pclass_mean[1]
Pclass2_mean_fare = Pclass_mean[2]
Pclass3_mean_fare = Pclass_mean[3]
total_data['Pclass_Fare_Category'] = total_data.apply(pclass_fare_category, args=(
Pclass1_mean_fare, Pclass2_mean_fare, Pclass3_mean_fare), axis=1)
print(total_data[['Pclass_Fare_Category', 'Survived']].groupby(
'Pclass_Fare_Category')['Survived'].agg(['count', 'mean']))
plt.figure(figsize=(10, 5))
sns.countplot(x='Pclass_Fare_Category', hue='Survived', data=total_data)
plt.title('Pclass_Fare_Category and Survived')
plt.show()
#同一等级的高价格区间的存活率高于低价格区间
# 提取name中的title
def sub_title(x):
return re.search('([A-Za-z]+)\.', x).group()[:-1]
total_data['Title'] = total_data['Name'].apply(lambda x: sub_title(x))
# 对title进行归类
title_Dict = {}
title_Dict.update(dict.fromkeys(
['Capt', 'Col', 'Major', 'Dr', 'Rev'], 'Officer'))
title_Dict.update(dict.fromkeys(
['Don', 'Sir', 'Countess', 'Dona', 'Lady'], 'Royalty'))
title_Dict.update(dict.fromkeys(['Mme', 'Ms', 'Mrs'], 'Mrs'))
title_Dict.update(dict.fromkeys(['Mlle', 'Miss'], 'Miss'))
title_Dict.update(dict.fromkeys(['Mr'], 'Mr'))
title_Dict.update(dict.fromkeys(['Master', 'Jonkheer'], 'Master'))
total_data['Title'] = total_data['Title'].map(title_Dict)
# 查看训练集中不同title的存活率
total_data[['Title', 'Survived']].groupby(
['Title']).mean().plot.bar(figsize=(10, 5))
plt.title('Title and Survived')
plt.show()
# 查看名字不同长度的存活率
plt.figure(figsize=(18, 5))
total_data['Name_length'] = total_data['Name'].apply(len)
name_length = total_data[['Name_length', 'Survived']].groupby(
['Name_length'], as_index=False).mean()
sns.barplot(x='Name_length', y='Survived', data=name_length)
plt.title('Name length and Survived')
plt.show()
#名字长度越长,存活率越高
# 区分有无兄弟姐妹/配偶在船上的两个群体进行数据对比
sibsp_df = total_data[total_data['SibSp'] != 0]
no_sibsp_df = total_data[total_data['SibSp'] == 0]
plt.figure(figsize=(10, 5))
plt.subplot(121)
sibsp_df['Survived'].value_counts().plot.pie(
labels=['No Survived', 'Survived'], autopct='%1.1f%%')
plt.xlabel('sibsp')
plt.subplot(122)
no_sibsp_df['Survived'].value_counts().plot.pie(
labels=['No Survived', 'Survived'], autopct='%1.1f%%')
plt.xlabel('no_sibsp')
plt.show()
#有兄弟姐妹/配偶在船上的生存率高
# 区分有无父母/子女在船上在船上的两个群体进行数据对比
parch_df = total_data[total_data['Parch'] != 0]
no_parch_df = total_data[total_data['Parch'] == 0]
plt.figure(figsize=(10, 5))
plt.subplot(121)
parch_df['Survived'].value_counts().plot.pie(
labels=['No Survived', 'Survived'], autopct='%1.1f%%')
plt.xlabel('parch')
plt.subplot(122)
no_parch_df['Survived'].value_counts().plot.pie(
labels=['No Survived', 'Survived'], autopct='%1.1f%%')
plt.xlabel('no_parch')
plt.show()
#有父母的生存率高
# 查看不同家庭人数的存活率
fig, ax = plt.subplots(1, 2, figsize=(18, 8))
total_data[['Parch', 'Survived']].groupby(['Parch']).mean().plot.bar(ax=ax[0])
ax[0].set_title('Parch and Survived')
total_data[['SibSp', 'Survived']].groupby(['SibSp']).mean().plot.bar(ax=ax[1])
ax[1].set_title('SibSp and Survived')
plt.show()
# 合并家庭人员
total_data['Family_Size'] = total_data['Parch'] + total_data['SibSp'] + 1
total_data[['Family_Size', 'Survived']].groupby(
['Family_Size']).mean().plot.bar(figsize=(10, 5))
plt.title('Family size and Survived')
plt.show()
#有家庭成员的存活率比无家庭成员的存活率高,但家庭人员人数越高存活率降低
# 根据以上结果划分家庭大小
def family_size_category(family_size):
if family_size <= 1:
return 'Single'
elif family_size <= 4:
return 'Small_Family'
else:
return 'Large_Family'
total_data['Family_Size_Category'] = total_data['Family_Size'].map(
family_size_category)
# 填充前的年龄数据
print(total_data['Age'].describe())
# 将分类变量转化为数值
total_data['Embarked'], uniques_embarked = pd.factorize(total_data['Embarked'])
total_data['Sex'], uniques_sex = pd.factorize(total_data['Sex'])
total_data['Cabin'], uniques_cabin = pd.factorize(total_data['Cabin'])
total_data['Fare_bin'], uniques_fare_bin = pd.factorize(total_data['Fare_bin'])
total_data['Pclass_Fare_Category'], uniques_pclass_fare_category = pd.factorize(
total_data['Pclass_Fare_Category'])
total_data['Title'], uniques_title = pd.factorize(total_data['Title'])
total_data['Family_Size_Category'], uniques_family_size_category = pd.factorize(
total_data['Family_Size_Category'])
# 使用随机森林预测缺失的年龄
from sklearn.ensemble import RandomForestRegressor
ageDf = total_data[['Age', 'Pclass', 'Title', 'Name_length',
'Sex', 'Family_Size', 'Fare', 'Cabin', 'Embarked']]
ageDf_notnull = ageDf.loc[ageDf['Age'].notnull()]
ageDf_isnull = ageDf.loc[ageDf['Age'].isnull()]
X = ageDf_notnull.values[:, 1:]
y = ageDf_notnull.values[:, 0]
RFR = RandomForestRegressor(n_estimators=1000, n_jobs=-1)
# 训练
RFR.fit(X, y)
predictAges = RFR.predict(ageDf_isnull.values[:, 1:])
total_data.loc[total_data['Age'].isnull(), 'Age'] = predictAges
# 填充后的年龄数据
print(total_data['Age'].describe())
# 查看年龄分布
plt.figure(figsize=(18, 5))
plt.subplot(131)
total_data['Age'].hist(bins=70)
plt.xlabel('Age')
plt.ylabel('Num')
plt.subplot(132)
total_data.boxplot(column='Age', showfliers=False)
# 查看是否存活群体的年龄差异
plt.subplot(133)
sns.boxplot(x='Survived', y='Age', data=total_data)
plt.show()
fig, ax = plt.subplots(1, 2, figsize=((18, 8)))
# 查看不同等级不同年龄的存活分布
ax[0].set_title('Pclass and Age vs Survived')
ax[0].set_yticks(range(0, 110, 10))
sns.violinplot(x='Pclass', y='Age', hue='Survived',
data=total_data, split=True, ax=ax[0])
# 查看不同性别不同年龄的存活分布
ax[1].set_title('Sex and Age vs Survived')
ax[1].set_yticks(range(0, 110, 10))
sns.violinplot(x="Sex", y="Age", hue="Survived",
data=total_data, split=True, ax=ax[1])
plt.show()
facet = sns.FacetGrid(total_data, hue='Survived', aspect=4)
facet.map(sns.kdeplot, 'Age', shade=True)
facet.set(xlim=(0, total_data['Age'].max()))
facet.add_legend()
plt.show()
# 年龄分层
bins = [0, 12, 18, 65, 100]
total_data['Age_group'] = pd.cut(total_data['Age'], bins)
print(total_data.groupby('Age_group')['Survived'].agg(['count', 'mean']))
plt.figure(figsize=(10, 5))
sns.countplot(x='Age_group', hue='Survived', data=total_data)
plt.title('Age group and Survived')
plt.show()
#年幼存活率较高
total_data['Age_group'], uniques_age_group = pd.factorize(total_data['Age_group'])
Correlation = pd.DataFrame(total_data[[
'Survived', 'Embarked', 'Sex', 'Title', 'Name_length', 'Family_Size', 'Family_Size_Category',
'Fare', 'Fare_bin', 'Pclass', 'Pclass_Fare_Category', 'Age', 'Age_group', 'Cabin'
]])
# 查看数据相关性
colormap = plt.cm.viridis
plt.figure(figsize=(14, 12))
plt.title('Pearson Correlation of Features', y=1.05, size=15)
sns.heatmap(
Correlation.astype(float).corr(method='kendall'),
linewidths=0.1,
vmax=1.0,
square=True,
cmap=colormap,
linecolor='white',
annot=True)
plt.show()
# 对分类变量进行独热编码
pclass_dummies = pd.get_dummies(total_data['Pclass'], prefix='Pclass')
total_data = total_data.join(pclass_dummies)
title_dummies = pd.get_dummies(total_data['Title'], prefix='Title')
total_data = total_data.join(title_dummies)
sex_dummies = pd.get_dummies(total_data['Sex'], prefix='Sex')
total_data = total_data.join(sex_dummies)
cabin_dummies = pd.get_dummies(total_data['Cabin'], prefix='Cabin')
total_data = total_data.join(cabin_dummies)
embark_dummies = pd.get_dummies(total_data['Embarked'], prefix='Embarked')
total_data = total_data.join(embark_dummies)
bin_dummies_df = pd.get_dummies(total_data['Fare_bin'], prefix='Fare_bin')
total_data = total_data.join(bin_dummies_df)
family_size_dummies = pd.get_dummies(
total_data['Family_Size_Category'], prefix='Family_Size_Category')
total_data = total_data.join(family_size_dummies)
pclass_fare_dummies = pd.get_dummies(
total_data['Pclass_Fare_Category'], prefix='Pclass_Fare_Category')
total_data = total_data.join(pclass_fare_dummies)
age_dummies = pd.get_dummies(total_data['Age_group'], prefix='Age_group')
total_data = total_data.join(age_dummies)
# 数据标准化
from sklearn.preprocessing import StandardScaler
scale_age_fare = StandardScaler().fit(
total_data[['Age', 'Fare', 'Name_length']])
total_data[['Age', 'Fare', 'Name_length']] = scale_age_fare.transform(
total_data[['Age', 'Fare', 'Name_length']])
total_data_backup = total_data.drop(['PassengerId', 'Pclass', 'Name', 'Sex', 'SibSp', 'Parch',
'Ticket', 'Fare', 'Cabin', 'Embarked', 'Fare_bin', 'Pclass_Fare_Category', 'Title',
'Family_Size', 'Family_Size_Category', 'Age_int', 'Age_group'
], axis=1, errors='ignore')
#bool转浮点型
total_data_backup = total_data_backup.astype(float)
train_data = total_data_backup[:891]
test_data = total_data_backup[891:]
print(total_data_backup.columns)
os.makedirs("data/data_pre3",exist_ok=True)
train_data.to_csv("data/data_pre3/data_pre3.csv",index=False)
test_data.to_csv("data/data_pre3/test_pre3.csv",index=False)
print("保存完成")
三、dataset
import pandas as pd
from torch.utils.data import Dataset,DataLoader
import torch
class MyDataset(Dataset):
def __init__(self, filepath):
data = pd.read_csv(filepath)
self.len = data.shape[0] # shape(多少行,多少列)
features = data.drop(['Survived'], axis=1)
label=data['Survived']
# 转化tensor格式
self.features_tensor = torch.from_numpy(features.values).float()
self.label_tensor = torch.from_numpy(label.values).float()
def __getitem__(self, index):
return self.features_tensor[index], self.label_tensor[index]
def __len__(self):
return self.len
if __name__ == '__main__':
filepath="./data/data_pre3/data_pre3.csv"
train_dataset=MyDataset(filepath)
trainLoader=DataLoader(train_dataset,batch_size=4,shuffle=True)
for features, labels in trainLoader:
print(f"feature:{features}")
print(f"label:{labels}")四、model
import torch.nn as nn
# 定义模型
class myNet3(nn.Module):
def __init__(self):
super(myNet3, self).__init__()
self.fc = nn.Sequential(
nn.Linear(43, 64),
nn.ReLU(),
nn.Linear(64, 16),
nn.ReLU(),
nn.Linear(16, 2),
nn.Softmax(dim=1)
)
def forward(self, x):
return self.fc(x)五、训练
import torch
import torch.optim as optim
from torch import nn
from mydateset3 import MyDataset
from mymodel3 import myNet3
from torch.utils.data import DataLoader
#加载数据
train_dataset=MyDataset("./data/data_pre3/data_pre3.csv")
#数据封装
train_loader=DataLoader(train_dataset,batch_size=1,shuffle=True)
#模型
net=myNet3()
#定义损失函数
criterion = nn.CrossEntropyLoss()
#定义优化器
optimizer = optim.Adam(net.parameters(), lr=0.001)
#训练
epoch_num=10
for epoch in range(epoch_num):
running_loss = 0.0
for i, data in enumerate(train_loader, 0):
inputs, labels = data # 获取数据
optimizer.zero_grad() # 清空梯度缓存
outputs = net(inputs)
loss = criterion(outputs, labels.long())
loss.backward() # 反向传播
optimizer.step() # 调整模型
running_loss += loss.item()
if i % 20 == 19:
# 每 20 次迭代打印一次信息
print('[%d, %5d] loss: %.3f' % (epoch+1, i+1, running_loss/2000))
running_loss = 0.0
if epoch==epoch_num-1:
# 保存模型
torch.save(net, "model/Mynet3.pth")
print("模型已保存")
六、预测
import torch
from mymodel3 import myNet3
from mydateset3 import MyDataset
import pandas as pd
import os
from torch.utils.data import DataLoader
import numpy as np
#数据
test_dataset=MyDataset("./data/data_pre3/test_pre3.csv")
tests_loader=DataLoader(test_dataset,batch_size=1,shuffle=False)
test_data=pd.read_csv("./data/data_pre3/test_pre3.csv")
test_data = test_data.drop('Survived', axis=1)
#加载模型
model=myNet3()
model = torch.load("model/Mynet3.pth", map_location=torch.device('cpu'))
#预测
test_data = torch.from_numpy(np.array(test_data)).float()
output = torch.max(model(test_data),1)[1]
print(output)
#保存
submission = pd.read_csv('./data/data_ original/gender_submission.csv')
submission['Survived'] = output
os.makedirs("data/submission",exist_ok=True)
submission.to_csv('data/submission/Submission3.csv', index=False)
print("保存完成")
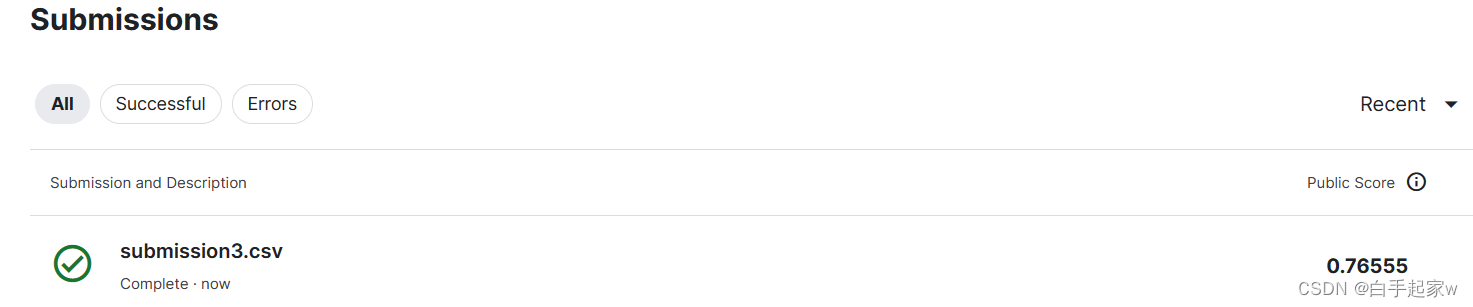
提交结果















 336
336











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









