




 文章介绍了PostgreSQL中两种优化索引扫描的技术:HeapOnlyTuple(HOT)和index-onlyscans。HOT在更新行且新旧行位于同一表页时,避免插入新的索引元组,减少VACUUM处理的需求。index-onlyscans则在索引包含查询所需所有信息时,直接使用索引避免访问表页,以降低I/O成本。文章通过示例详细阐述了这两种技术的工作原理和效果。
文章介绍了PostgreSQL中两种优化索引扫描的技术:HeapOnlyTuple(HOT)和index-onlyscans。HOT在更新行且新旧行位于同一表页时,避免插入新的索引元组,减少VACUUM处理的需求。index-onlyscans则在索引包含查询所需所有信息时,直接使用索引避免访问表页,以降低I/O成本。文章通过示例详细阐述了这两种技术的工作原理和效果。
Chapter 7 Heap Only Tuple and Index-Only Scans
- This chapter describes two features related to the index scan, which are the heap only tuple and index-only scans.(这一章主要描述了两个有关于索引扫描的功能,分别是HOT和index-only scans)
7.1 Heap Only Tuple(HOT)
-
The HOT was implemented in version 8.3 to effectively use the pages of both index and table when the updated row is stored in the same table page that stores the old row. The HOT also reduces the necessity of VACUUM processing.(HOT是pg8.3版本中被实现,用于在更新的过后的行和旧的行存储在同一表页中时,更有效地使用索引和表的页面。HOT同样减少VACUUM过程的必要性)
Since the details of HOT are described in the README.HOT in the source code directory, this chapter briefly introduces HOT. Firstly, Section 7.1.1 describes how to update a row without HOT to clarify the issues that the resolves. Next, Section 7.1.2 describes how HOT performs.(因为HOT的细节描述在源码目录
src/backend/access/heap/README.HOT中,这一章简短地介绍了HOT。首先7.1.1小节描述了怎样不使用HOT对一行数据进行更新,用于引出接下来要解决的问题;7.1.2小节描述了HOT怎样解决问题和执行过程)
7.1.1 Update a Row Without HOT
- Assume that the table ‘tbl’ has two columns: ‘id’ and ‘data’; ‘id’ is the primary key of ‘tbl’.(假设表
tbl有两列属性id和data,id是该表的主键)
\d tbl
Table "public.tbl"
Column | Type | Collation | Nullable | Default
--------+---------+-----------+----------+---------
id | integer | | not null |
data | text | | |
Indexes:
"tbl_pkey" PRIMARY KEY, btree (id)
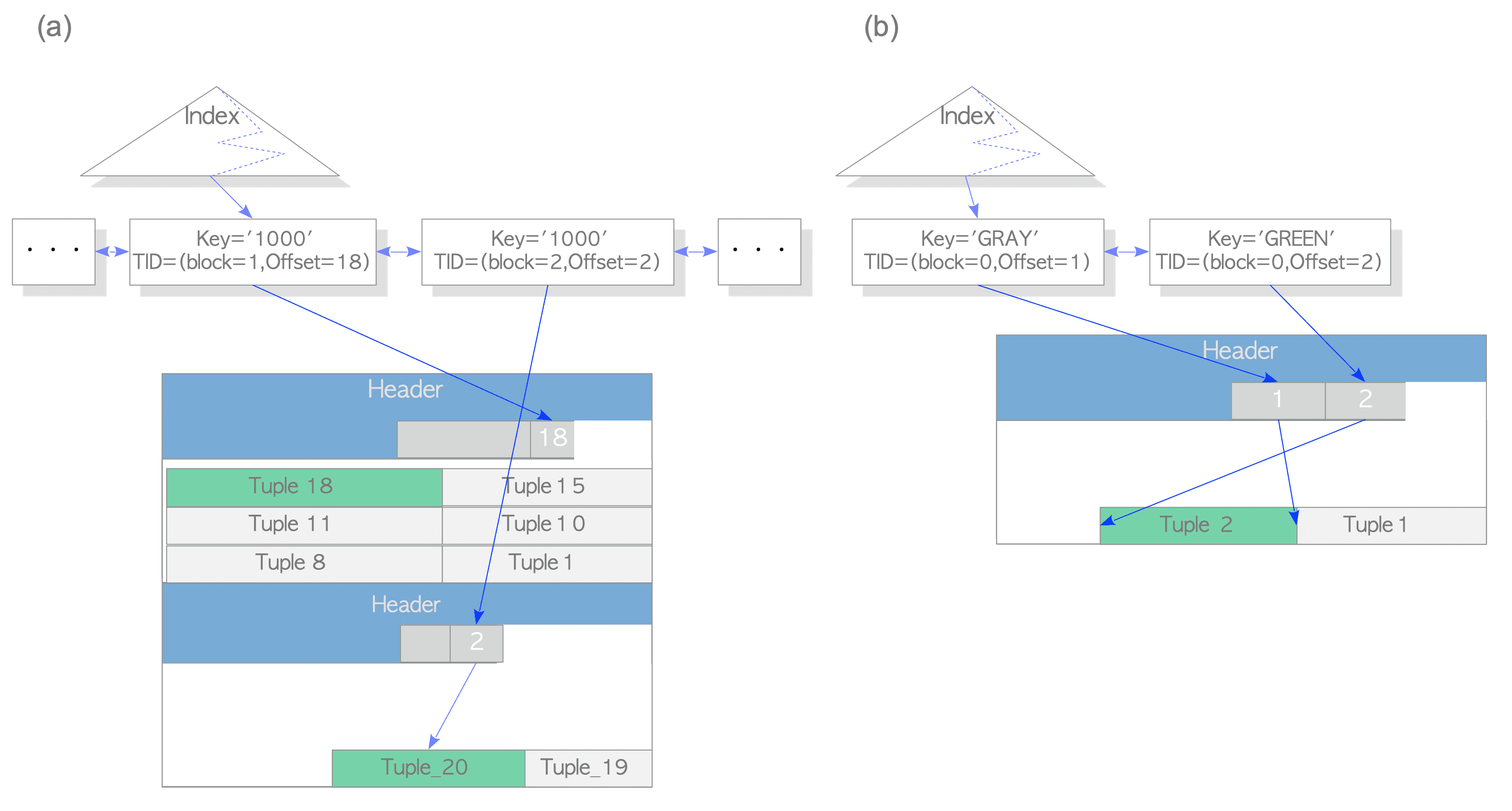
- The table ‘tbl’ has 1000 tuples; the last tuple of which the id is ‘1000’ is stored in the 5th page of the table. The last tuple is pointed from the corresponding index tuple, of which the key is ‘1000’ and whose tid is ‘(5,1)’. Refer to Fig. 7.1(a).(表
tbl有100个元组,最后一个属性id=100的元组被存储在该表文件的第5页中。最后一个元组被相应的索引元组所指,键为1000,tid=(5,1)。 - 复习一下tid:(元组标识符(TID)由两个值组成:①元组所属页面的块()页号,②指向该元组的指针在页面内的偏移量), For example, showing pseudo code below:
TID = (block=7,offset-2)
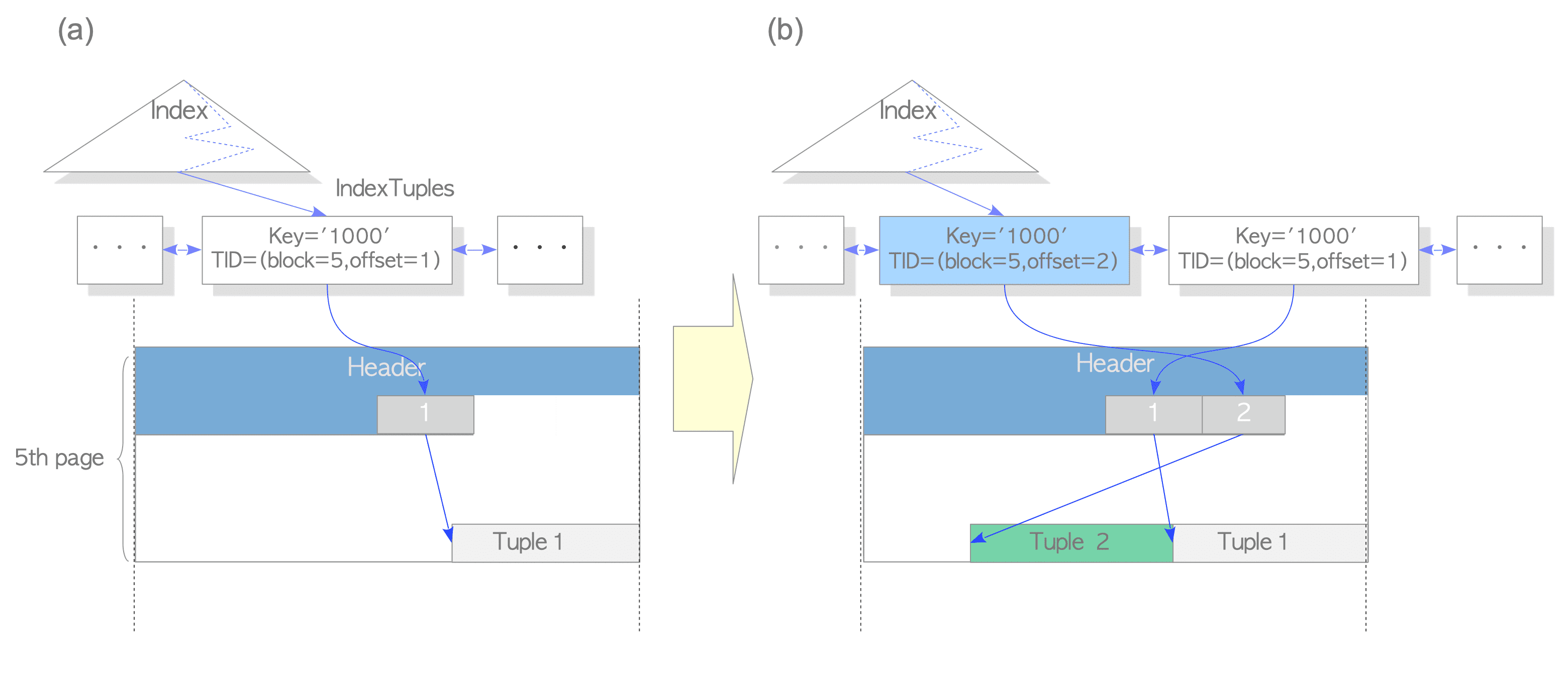
- We consider how the last tuple is updated without HOT.(思考不使用HOT的情况下,怎样更新最后一个元组)
- In this case, PostgreSQL inserts not only the new table tuple but also the new index tuple in the index page. Refer to Fig. 7.1(b).(在这种情况下,pg不仅要插入新的表元组,而且还要在索引页中插入新的索引元组。)
UPDATE tbl SET data='B' WHERE id = 1000;
- The inserting of the index tuples consumes the index page space, and both the inserting and vacuuming costs of the index tuples are high. The HOT reduces the impact of these issues.(索引元组的插入会消耗索引页的空间,而且对索引元组执行插入和vacuum的成本都巨tm高。HOT减少了这个成本方面的影响。)
7.1.2. How HOT Performs
- When a row is updated with HOT, if the updated row will be stored in the same table page that stores the old row, PostgreSQL does not insert the corresponding index tuple and sets the HEAP_HOT_UPDATED bit and the HEAP_ONLY_TUPLE bit to the t_informask2 fields of the old tuple and the new tuple, respectively. Refer to Figs. 7.2 and 7.3.(当使用Heap Only Tuple更新行时,如果被更新的行将会被存储在旧的行相同的表页中的话,pg就不会插入对应的索引元组,并将
HEAP_HOT_UPDATE位和HEAP_ONLY_TUPLE位分别设置为旧元组和新元组的t_informask2字段,如下面两张图:)
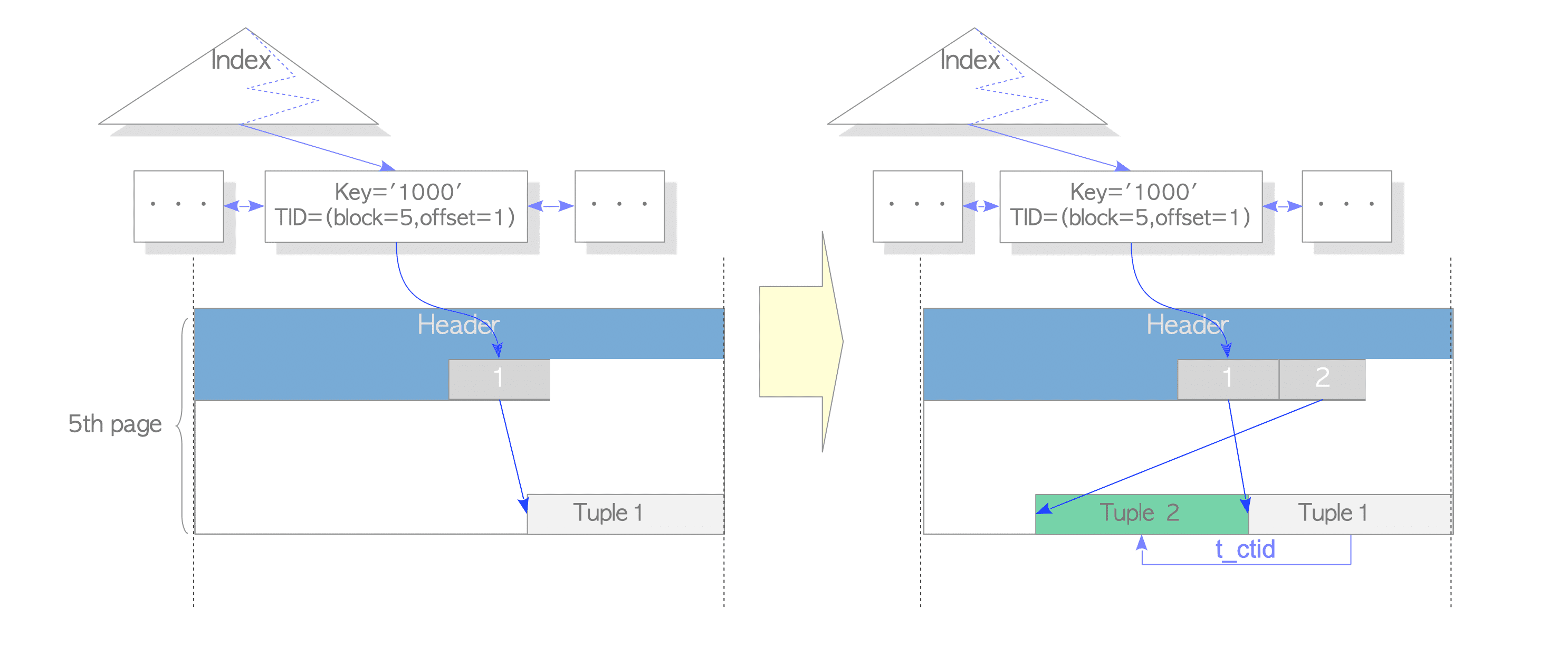

-
For example, in this case, ‘Tuple_1’ and ‘Tuple_2’ are set to the HEAP_HOT_UPDATED bit and the HEAP_ONLY_TUPLE bit, respectively.(例如,在这种情况下,
Tuple_1和Tuple_2别分别设置为HEAP_HOT_UPDATE和HEAP_ONLY_TUPLE位) -
In addition, the HEAP_HOT_UPDATED and the HEAP_ONLY_TUPLE bits are used regardless of the pruning and the defragmentation processes, which are described in the following, are executed.(另外,使用
HEAP_HOT_UPDATED和HEAP_ONLY_TUPLE位时不用管接下来介绍的“修剪”和“碎片整理”过程) -
In the following, a description of how PostgreSQL accesses the updated tuples using the index scan just after updating the tuples with HOT is given. Refer to Fig. 7.4(a).(接下来,会描述pg怎样用索引扫描访问使用HOT更新得到的元组)
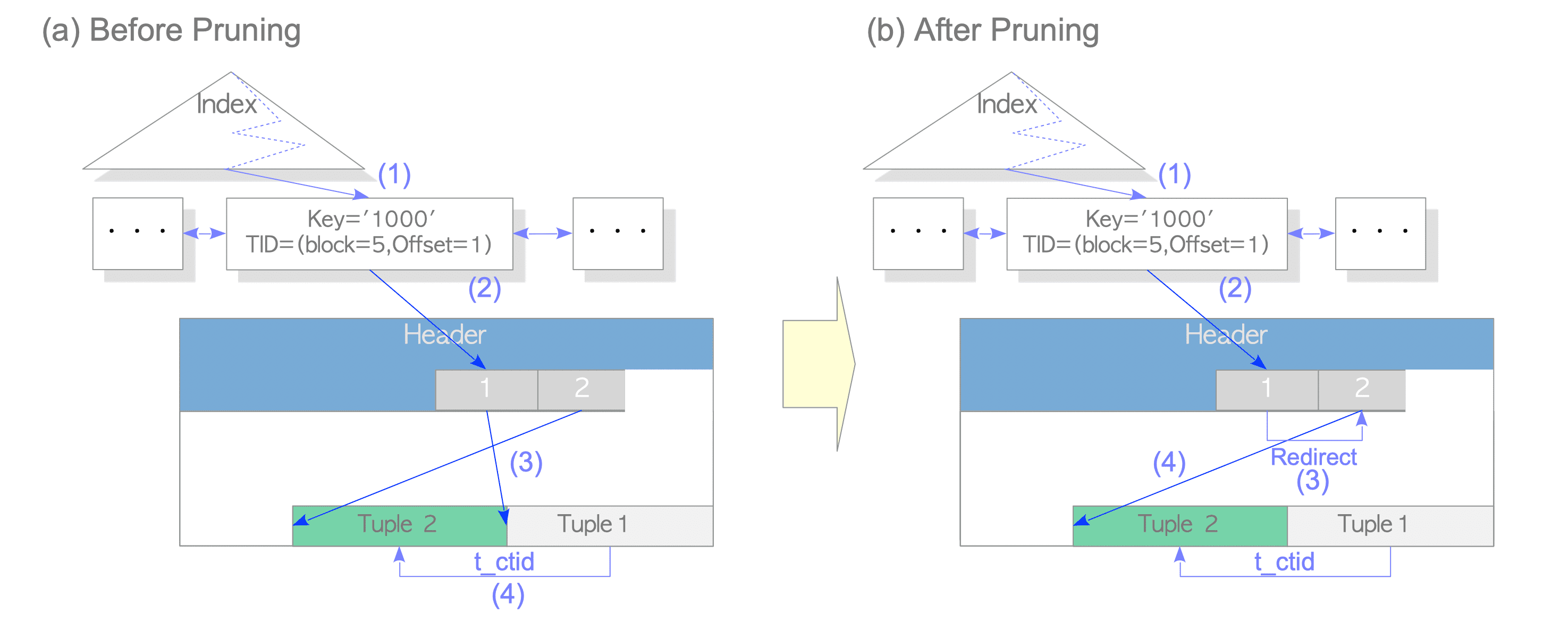
-
(1) Find the index tuple that points to the target tuple.(找到指向目标元组的索引元组)
-
(2) Access the line pointer ‘[1]’ that is pointed from the getting index tuple.(访问从获得的索引元组获得的行指针)
-
(3) Read ‘Tuple_1’.(读取
Tuple_1) -
(4) Read ‘Tuple_2’ via the t_ctid of ‘Tuple_1’.(由
Tuple_1的t_ctid读取Tuple_2) -
In this case, PostgreSQL reads two tuples, ‘Tuple_1’ and ‘Tuple_2’, and decides which is visible using the concurrency control mechanism described in Chapter 5.(这种情况下,pg读取两个元组
Tuple_1和Tuple_2,并且决定用第五章介绍的并发控制决定谁可见) -
However, a problem arises if the dead tuples in the table pages are removed. For example, in Fig. 7.4(a), if ‘Tuple_1’ is removed since it is a dead tuple, ‘Tuple_2’ cannot be accessed from the index.(然而,也产生了一个问题,如果旧的元组被当做死元组被移除了,例如上面例子中,如果
Tuple_1被移除,Tuple_2就不能被索引访问了) -
To resolve this problem, at an appropriate time, PostgreSQL redirects the line pointer that points to the old tuple to the line pointer that points to the new tuple. In PostgreSQL, this processing is called pruning. Fig. 7.4(b) despicts how PostgreSQL accesses the updated tuples after pruning.(为了解决这一问题,pg会在一个合适的时间将指向旧元组的行指针重定向让其指向新元组。在pg中,这个过程就被称之为剪枝,上图中(b)描述了pg怎样访问更新和剪枝过后的元组)
- (1) Find the index tuple.(找到索引元组)
- (2) Access the line pointer ‘[1]’ that is pointed from the getting index tuple.(访问被索引元组指向的行指针[1])
- (3) Access the line pointer ‘[2]’ that points to ‘Tuple_2’ via the redirected line pointer.(访问经过重定向后,指向
Tuple_2的行指针[2] - (4) Read ‘Tuple_2’ that is pointed from the line pointer ‘[2]’.(读取被行指针[2]指向的
Tuple_2) - The pruning processing will be executed, if possible, when a SQL command is executed such as SELECT, UPDATE, INSERT and DELETE. The exact execution timing is not described in this chapter because it is very complicated. The details are described in the README.HOT file.(剪枝过程将会被执行,如果可能的话,当执行一个增删改查的SQL命令时,确切的执行时间不会再这一章介绍,因为非常复杂,细节介绍可以看源码目录下的
src/backend/access/heap/README.HOT文件) - PostgreSQL removes dead tuples if possible, as in the pruning process, at an appropriate time. In the document of PostgreSQL, this processing is called defragmentation. Fig. 7.5 despicts the defragmentation by HOT.(如果可能的话,pg会在适当的时候移除死元组,就像剪枝一样,这个过程被称之为碎片整理,下图描述了HOT中的碎片整理)
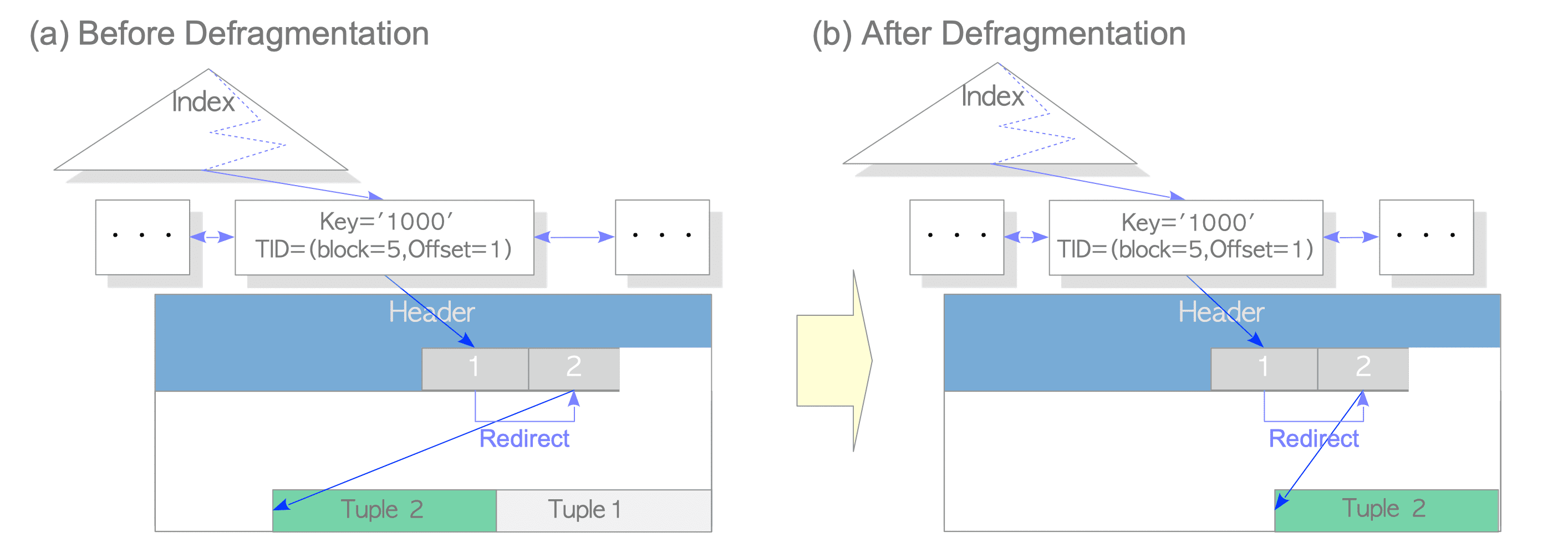
-
Note that the cost of defragmentation is less than the cost of normal VACUUM processing because defragmentation does not involve removing the index tuples.(注意碎片整理的成本要比正常的vacuum的成本小得多,因为碎片整理不会涉及到移除索引元组==(vacuum会涉及到移除所有元组,详细见vacuum源码的第一部分)==)
-
Thus, using HOT reduces the consumption of both indexes and tables of pages; this also reduces the number of tuples that the VACUUM processing has to process. Therefore, HOT has a good influence on performance because it eventually reduces the number of insertions of the index tuples by updating and reducing the necessity of VACUUM processing.(因此,使用HOT可以减少表文件的页和索引页的开销;同时也减少了VACUUM过程需要移除的元组的数量。因此,HOTHOT对性能有很正面的影响,因为它最终通过更新和减轻要用VACUUM处理死元组的必要性来减少索引元组的插入次数)
-
The Cases in which HOT is not available —— (不能使用HOT进行UPDATE的两种情况
- When the updated tuple is stored in the other page, which does not store the old tuple, the index tuple that points to the tuple is also inserted in the index page. Refer to Fig. 7.6(a).(当要被更新的元组要被存储在其他页面时,也就是和旧元组不是同一个页面时,指向这个元组的索引元组同样会被插入索引页,也就变回了不使用HOT的那种情况,如下图(a))
- When the key value of the index tuple is updated, the new index tuple is inserted in the index page. Refer to Fig. 7.6(b).(当索引元组的键值被更新时,新索引元组也会被插入到索引页中,如下图(b))
7.2 Index-Only Scans
- To reduce the I/O (input/output) cost, index-only scans (often called index-only access) directly use the index key without accessing the corresponding table pages when all of the target entries of the SELECT statement are included in the index key. This technique is provided by almost all commercial RDBMS, such as DB2 and Oracle. PostgreSQL has introduced this option since version 9.2.(为了减少IO操作的成本,index-only scans会在当SELECT语句的所有目标项都包含在索引键中时,直接用索引键而不访问对应的表文件中的页。这项技术几乎所有商业RDBMS都会提供。)
- In the following, using a specific example, a description of how index-only scans in PostgreSQL perform is given.(接下来,用一个特定的例子,描述index-only-scans怎样在pg中运行)
- The assumptions of the example areexplained below:(假设执行以下)
\d tbl
Table "public.tbl"
Column | Type | Modifiers
--------+---------+-----------
id | integer |
name | text |
data | text |
Indexes:
"tbl_idx" btree (id, name)
- Index(索引)
- The table ‘tbl’ has an index ‘tbl_idx’, which is composed of two columns: ‘id’ and ‘name’.(表
tbl中包含了索引tbl_idx,包含了两列,分别是id和namE)
- The table ‘tbl’ has an index ‘tbl_idx’, which is composed of two columns: ‘id’ and ‘name’.(表
- Tuples
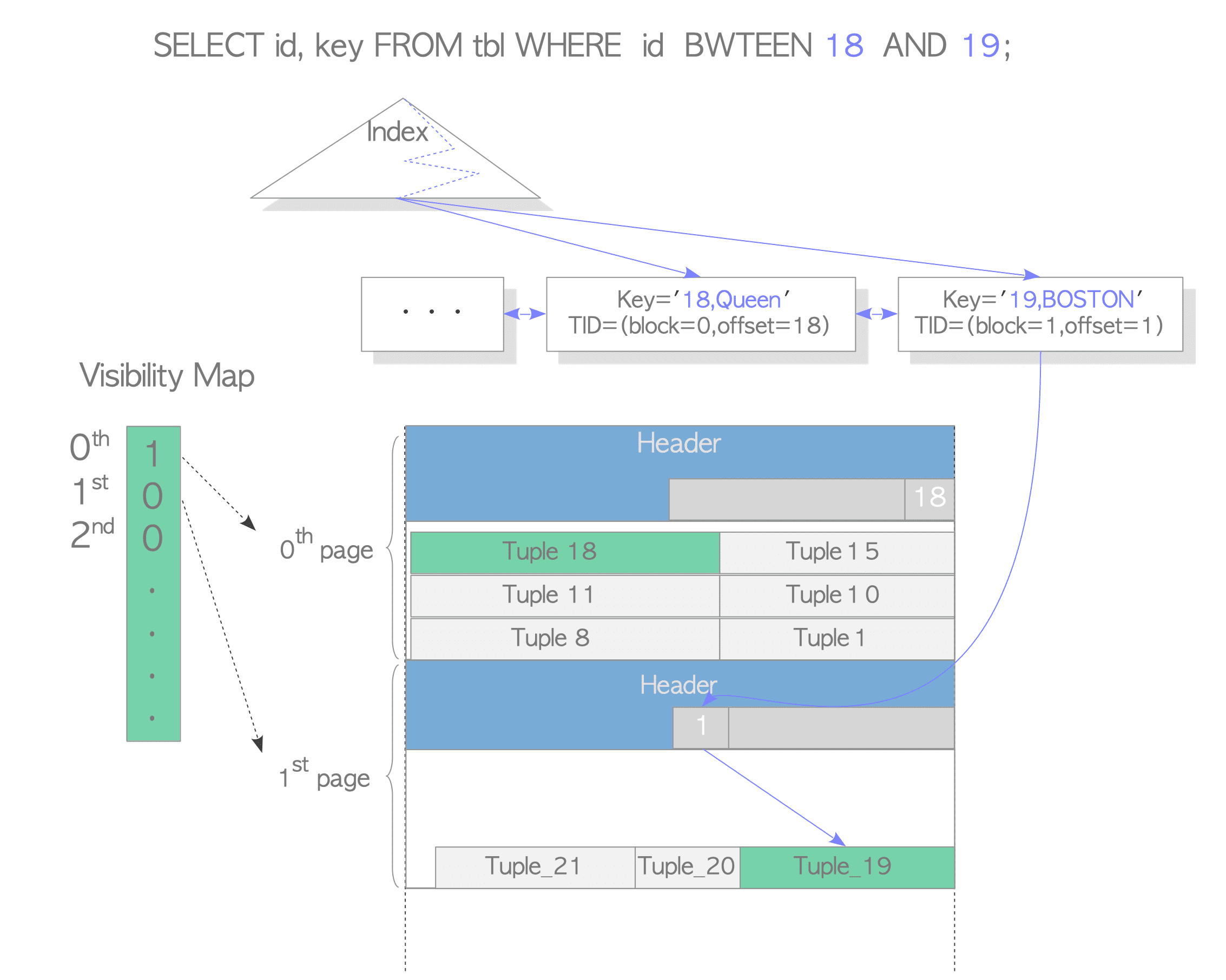
tblhas already inserted tuples.(tbl已经插入了一些元组)- ‘Tuple_18’, of which the id is ‘18’ and name is ‘Queen’, is stored in the 0th page.(
Tuple_18,id='18',name='Queen',被存储在第0页中) - ‘Tuple_19’, of which the id is ‘19’ and name is ‘BOSTON’, is stored in the 1st page.(
Tuple_19,id=19,name='BOSTON',被存储在第1页中)
- Visibility
- All tuples in the 0th page are always visible; the tuples in the 1st page are not always visible. Note that the visibility of each page is stored in the corresponding visibility map, and the visibility map is described in Section 6.2.(第0页所有元组总是可见的,第1页中的元组并不总是可见的。注意每一个页面的可见性都被存储在相应的VM文件中)
- Let us explore how PostgreSQL reads tuples when the following SELECT command is executed.(探索pg执行SELECT命令时如何读取元组)
SELECT id,name FROM tbl1 WHERE id BETWEEN 18 and 19;
id | name
----+--------
18 | Queen
19 | Boston
(2 rows)
- This query gets data from two columns of the table: ‘id’ and ‘name’, and the index ‘tbl_idx’ is composed of these columns. Thus, when using index scan, it seems at first glance that accessing the table pages is not required because the index tuples contain the necessary data.(这个查询数据来自表两列
id和name,索引tbl_idx由上述两列组成。因此,当使用索引扫描时,乍一看,不需要访问表页,因为索引元组包含必要的数据。) However, in fact, PostgreSQL has to check the visibility of the tuples in principle, and the index tuples do not have any information about transactions such as the t_xmin and t_xmax of the heap tuples, which are described in Section 5.2.(然而,实际上,pg原则上要检查元组的可见性,索引元组没有任何关于可见性的参数,例如堆元组中的t_xmin和t_xmax) Therefore, PostgreSQL has to access the table data to check the visibility of the data in the index tuples. This is like putting the cart before the horse.(因此,pg必须访问表数据以检查索引元组中数据的可见性,这就很本末倒置) - To avoid this dilemma, PostgreSQL uses the visibility map of the target table. If all tuples stored in a page are visible, PostgreSQL uses the key of the index tuple and does not access the table page that is pointed at from the index tuple to check its visibility; otherwise, PostgreSQL reads the table tuple that is pointed at from the index tuple and checks the visibility of the tuple, which is the ordinary process.(为了避免这种困境,pg会用目标表的VM文件,如果表的某一页中存储的所有元组都是可见的,那么pg就会直接使用这一页中对应的索引元组的键,不会再因为要检查索引元组的可见性而去访问这些索引元组指向的表的页;否则,pg就会读取这些索引元组指向的表页中的元组并检查这些元组的可见性)
- In this example, ‘Tuple_18’ need not be accessed because the 0th page that stores ‘Tuple_18’ is visible, that is, all tuples including Tuple_18 in the 0th page are visible. In contrast, ‘Tuple_19’ needs to be accessed to treat the concurrency control because the visibility of the 1st page is not visible. Refer to Fig. 7.7.(这上述的举例中,
Tuple_18所在的第0th页全部都是可见的,所有Tupel_18不需要被访问,相反的,Tuple_19所在的页并不是全部可见,所以在检查元组可见性时,需要再去访问Tuple_19所在的表页)

















 5793
5793

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









