







 本文介绍了解决GCC编译器在处理GBK编码源文件时出现的乱码及错误的方法。通过设置-finput-charset和-fexec-charset参数确保源文件与编译输出编码一致,避免编译和运行时的乱码问题。
本文介绍了解决GCC编译器在处理GBK编码源文件时出现的乱码及错误的方法。通过设置-finput-charset和-fexec-charset参数确保源文件与编译输出编码一致,避免编译和运行时的乱码问题。
中文乱码/编译时报错:error: converting to execution character set: llegal byte sequence.
dev重新安装,搞了好久。
感谢铁汁!!我搞了好多方法都不行
so,发出来大家康康

------------------------------------------------分割线-----------------------------------------------------
2024/6/13 又再次被这个问题难到了 琢磨了很久才找到自己的问题
解决:
编辑器选项输入:-fexec-charset=GBK -finput-charset=GBK
必须是同一个,也就是都设置为gbk,如果一个utf-8 一个gbk肯定会错!别问我为什么知道,血泪的教训
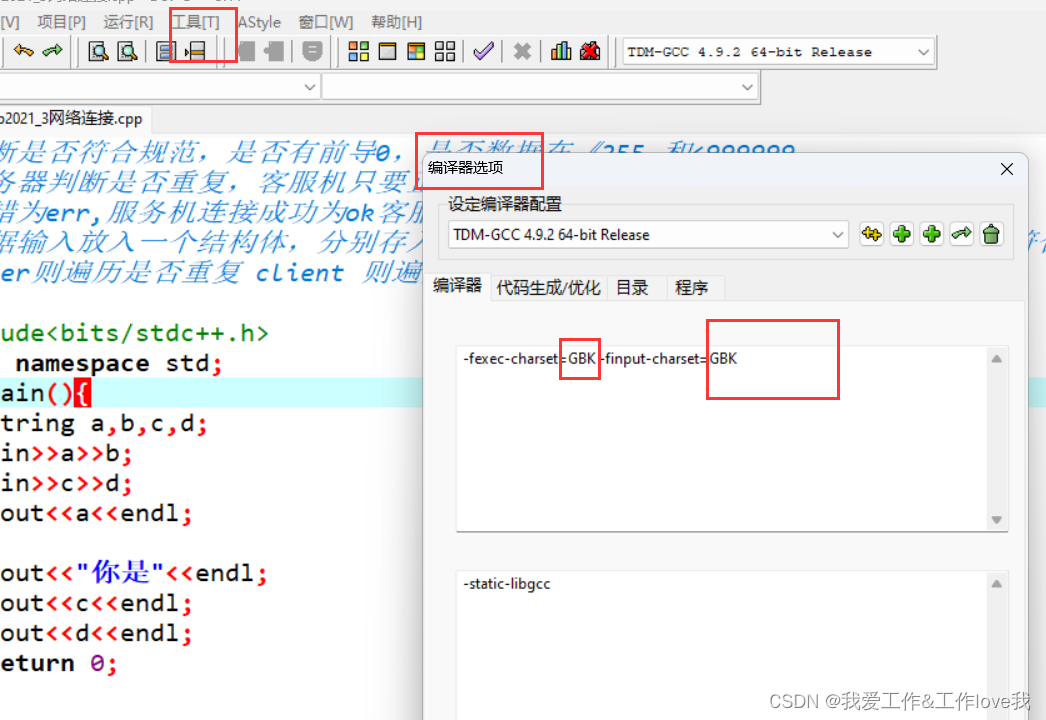
大概解释:
- 源代码文件和编译器输入时设置的编码可能不一致:源代码默认情况是保存为windows本地编码的,也就是WINDOWS-936字符集,也就是GBK编码。但是GCC编译器默认编译的时候是按照UTF-8解析的(linux默认字符集是UTF-8),如果没有声明编码格式,编译器会把GBK当成UTF-8解析,从而导致编译错误。
so :-finput-charset=GBK设置来指定编译器用什么编码解释输入源文件,格式为GBK。
-编译时就不会报错了,但是编译后运行时,在控制台显示的依然是乱码!: 编译之后默认情况的执行文件时编译成UTF-8的,控制台显示的时候缺省的是使用系统默认的字符集,比如windows下用的是GBK,所以乱码
so:fexec-charset=GBK设置来指定编译器编译后的代码格式,格式GBK。
同理:格式一致即可,都为UTF-8也行


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









