









Map集合
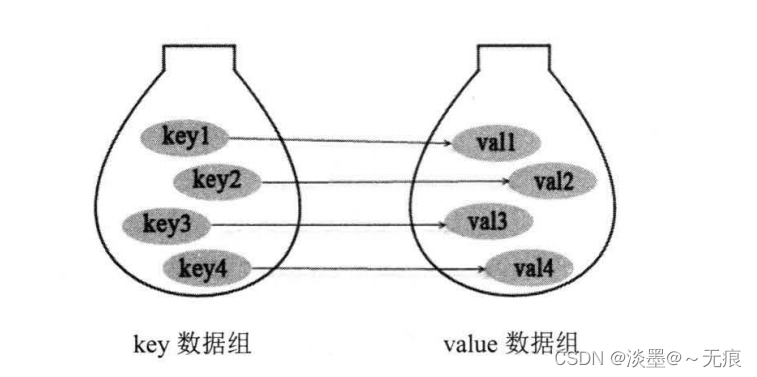
Map 用于保存具有映射关系的数据,因此Map集合里保存着两组值 ,一组值用于保存 Map 里的 key ,另外一组值用于保存 Map 里的 value , key 和 value 都可以是任何引用类型的数据 。 Map 的 key 不允许重复 ,即同一个 Map 对象的任何两个 key 通过 equals 方法比较总是返回 false 。
Map集合的示例图
Map集合子类或者实现类示例图
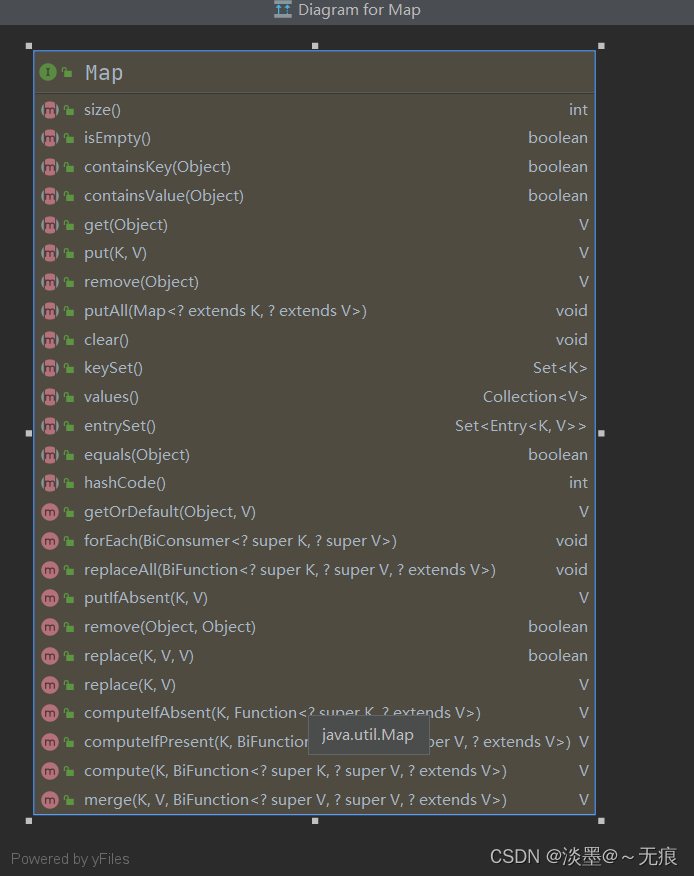
Map集合常用的API方法:
void clear(): 删除该 Map 对象中的所有 key - value 对 。
boolean containsKey(Object key): 查询 Map 中 是否包含指定的 key ,如果包含则返回 true 。
boolean containsValue(Object value):查询 Map 中 是否包含一个或多个 value ,如果包含则返回 true .
Set entrySet(): 返回 Map 中包含 的 key-value 对所组成的 Set 集合,每个集合元素都是 Map.Entry(Entry 是 Map 的内部类)对象 。
Object get(Object key): 返 回 指定 key 所对应的 value; 如果此 Map 中不包含该 key ,则返回 null 。
boolean isEmpty():查询该 Map 是否为空(即不包含任何 key-value 对 ) ,如 果为空则返回 true 。
Set keySet(): 返回该 Map 中所有 key 组成的 Set 集合 。
Object put(Object key, Object value): 添加 一个 key-value 对,如果当前 Map 中己有一个与该 key相等的 key-value 对,则新的 key-value 对会覆盖原来的 key-value 对 。
void putAll(Map m): 将指定 Map 中的 key-value 对复制到本 Map 中 。
Object remove(Object key): 删除指定 key 所对应的 key-value 对,返回被删除 key 所关联的 value ,如果该 key 不存在,则返回 null 。
boolean remove(Object key, Object value): 这是 Java 8 新增的方法,删除指定 key 、 value 所对应的 key-value 对 。 如果从该 Map 中成功地删除该 key-value 对,该方法返回 true ,否则返回 false 。
int size(): 返回该 Map 里的 key-value 对的个数 。
Collection values(): 返回该 Map 里所有 value 组成的 Collection 。
示例代码:
import java.util.HashMap;
import java.util.Map;
/**
* @author: 随风飘的云
* @date 2022/03/20 23:06
*/
public class MapTest {
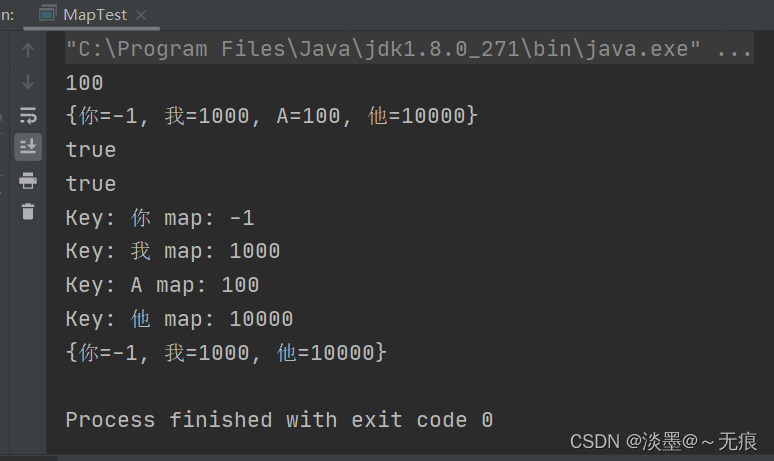
public static void main(String[] args) {
Map map = new HashMap();
//成对放入多个 key-value 对
map.put("你",100);
map.put("我", 1000);
map.put("他",10000);
//多次放入的 key - value 对中 value 可以重复
map.put("A", 100);
//放入重复的 key 时 ,新的value会覆盖原有的 value
//如果新的value覆盖了原有的 value ,该方法返回被覆盖的value
System.out.println(map.put("你", -1));//输出100
// 输出Map集合
System.out.println(map);
System.out.println(map.containsKey("我"));
System.out.println(map.containsValue(100));
for (Object key:map.keySet()) {
System.out.println("Key: "+ key + " map: "+ map.get(key));
}
map.remove("A");
System.out.println(map);
}
}
结果:
Entry内部类:
Map 中包括一个内部类 Entry,该类封装了 一个 key-value 对。 Entry 包含如下三个方法 。
Object getKey(): 返回该 En町里包含的 key 值 。
Object getValue(): 返回该 Entry 里包含的value 值 。
Object setValue(V value): 设置该 Entry 里包含的 value 值,并返回新设置的 value 值 。
Map集合新增的API的方法
1、Object compute(Object key, BiFunction remappingFunction): 该方法使用remappingFunction 根据 原 key-value 对计算一个新 value 。 只要新 value 不为 null,就使用新value 覆盖原 value; 如果原 value 不为 null,但新 value 为 null ,则删除原 key-value对;如果原 value 、新 value 同时为 null , 那么该方法不改变任何 key-value 对,直接返回 null 。
2、Object computeIfAbsent(Object key, Function mappingFunction):如果传给该方法的 key 参数在 Map 中对应的 value 为 null ,则使用 mappingFunction 根据 key计算一个新的结果,如果计算结 果不为 null,则用计算结果覆盖原有的 value 。 如果原 Map 原来不包括该 key,那么该方法可能会添加一组 key-value 对 。
3、Object computeIfPresent(Object key, BiFunction remappingFunction):如果传给该方法的 key 参数 在 Map 中对应的 value 不为 null,该方法将使用 remappingFunction 根据原key、 value 计算一个 新的结果,如果计算结果不为 null,则使用该结果覆盖原来的 value; 如果计算结果为 null,则删除原 key-value 对 。
4、void forEach(BiConsumer action): 该方法是 Java 8 为 Map 新增的一个遍历 key-value 对的方法,通过该方法可以更简洁地遍历 Map 的 key-value 对 。
5、Object getOrDefault(Object key, V defaultValue): 获取指定 key 对应的 value 。 如果该 key 不存在,则返回 defaultValue。
6、Object merge(Object key, Object value, BiFunction remappingFunction): 该方法会先根据 key 参数获取该 Map 中对应的 value 。 如果获取的 value 为 null,则直接用传入的 value 覆盖原有的 value (在这种情况下,可能要添加一组 key-value 对 ) ;如果获取的value 不为 null ,则使用remappingFunction 函数根据原 value 、新 value 计算一个新的结果,并用得到的结果去覆盖原有 的 value 。
7、Object putlfAbsent(Object key, Object value): 该方法会自动检测指定 key 对应的value 是否为 null,如果该 key 对应的 value 为 null,该方法将会用新 value 代替原来的 null 值 。
8、Object replace(Object key, Object value): 将 Map 中指定 key 对应的 value替换成新 value 。与传统put()方法不同的是,该方法不可能添加新的 key-value 对 。 如果尝试替换的 key 在原 Map 中不存在,该方法不会添加 key-value 对,而是返回 null 。
9、boolean replace(K key, V oldValue, V newValue): 将 Map 中指定 key-value对的原 value 替换成新value 。如果在 Map 中找到指定的 key-value 对,则执行替换并返回 true ,否则返回false 。
10、replaceAll(BiFunction function): 该方法使用 BiFunction 对原 key-value 对执行计算,并将计算结果作为该 key-value 对的 value 值 。
Map总体方法
HashMap和HashTable的区别
1、线程安全不同: HashTable是一个线程安全的Map实现类,但是HashMap是线程不安全的实现类。因为线程安全问题,HashMap比HashTable性能高。
2、内部方法不同: HashTable内部的方法基本都经过synchronized 修饰。
例如:
3、存储值不同: HashTable实现类不可以使用null的key值或者是value值,如果在程序中添加null值,将会引发空指针异常(NUllPointerException)。但是HashMap可以使用null值作为key值或者是value值。
4、初始容量不同和每次扩容大小容量不同。 ① 如果创建时不指定容量的大小,那么HashTable默认初始容量大小为11,每次扩充变为原来的2n+1倍。HashMap实现类初始化容量大小为16,每一次扩容变为原来的两倍。② 如果创建时指定了容量大小,HashTable实现类直接使用指定的容量大小,而HashMap会扩充为原来的2的幂次方大小。
6、底层数据结构不同: HashMap实现类,当链表长度大于阈值(默认为 8)(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树)时,将链表转化为红黑树,以减少搜索时间。
LinkedHashMap 实现类
基本原理
LinkedHashMap 使用双向链表来维护 key-value 对的次序(其实只需要考虑 key 的次序) ,该链表负责维护 Map 的迭代顺序,迭代顺序与 key-value 对的插入顺序保持一致。
LinkedHashMap 可以避免对 HashMap 、 Hashtable 里 的 key-value 对进行排序(只要插入 key-value对时保持顺序即可),同时又可避免使用 TreeMap 所增加的成本 。LinkedHashMap 需要维护元素的插入顺序,因此性能略低于 HashMap 的性能;但因为它以链表来维护内部顺序,所以在迭代访问 Map 里的全部元素时将有较好的性能 。
实例代码:
import java.util.LinkedHashMap;
/**
* @author: 随风飘的云
* @describe:
* @date 2022/03/22 22:28
*/
public class LinkedHashMapTest {
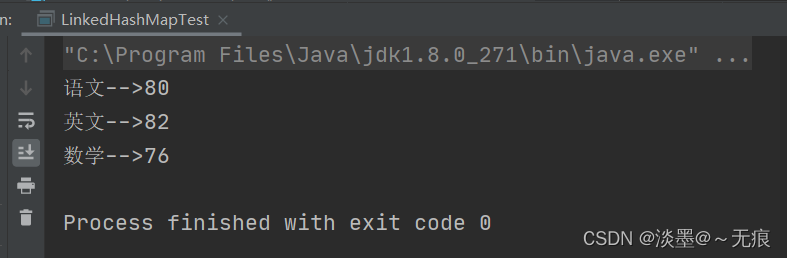
public static void main(String[] args) {
LinkedHashMap scores = new LinkedHashMap();
scores.put("语文" , 80);
scores.put("英文" , 82);
scores.put("数学" , 76);
// 调用forEach方法遍历scores里的所有key-value对
scores.forEach((key, value) -> System.out.println(key + "-->" + value));
}
}
结果:
SortedMap 接口和 TreeMap 实现类
基本原理
SortMap接口有一个TreeMap实现类,TreeMap 就是 一个红黑树数据结构 , 每个 key-value 对即作为红黑树的一个节点 。 TreeMap 存储key-value 对(节点)时, 需要根据 key 对节点进行排序。 TreeMap 可以保证所有的 key-value 对处于有序状态。 TreeMap 也有两种排序方式。
1、自然排序: TreeMap实现类的所有Key必须要实现Comparable接口,而且所有的key必须要是同一个类对象的,否则会抛出ClassCastException.
2、定制排序: 创建 TreeMap 时,传入一个 Comparator 对象, 该对象负责对 TreeMap 中的所有key 进行排序 。采用定制排序时不要求 Map的 key 实现 Comparable 接口。
TreeMap中判断两个key相等的方法是两个key通过compareTo()方法返回0, 如果使用自定义类作为TreeMap实现类的key时,应当重写equals()方法和compareTo()方法,使得两个方法的返回结果一致。
TreeMap实现类提供一系列的访问Key-Value方法如下:
Map.Entry fIrstEntry(): 返回该 Map 中 最小 key 所对应的 key-value 对,如果该 Map 为 空, 则返回 null 。
Object fIrstKey(): 返回该 Map 中的最小 key 值 , 如果该 Map 为 空, 则返回 null 。
Map.Entry lastEntry(): 返回该 Map 中 最大 key 所对应的 key-value 对,如果该 Map 为空或不存在这样的key-value对,则都返回 null 。
Object lastKey(): 返回该 Map中的最大 key 值,如果该 Map为空或不存在这样的 key. 则都返回 null 。
Map.Entry higherEntry(Object key): 返回 该 Map 中位于 key 后 一位 的 key-value 对 ( 即大于指定key 的最小 key 所对应的 key-value 对 )。如果该 Map 为空 ,则 返回 null 。
Map.Entry lowerEntry(Object key): 返回该 Map 中 位于 key 前一位的 key-value 对(即 小于指定key 的最大 key 所对应的 key-value 对) 。 如果该 Map 为 空或不存在这样 的 key-value 对,则都返回 null
Object lowerKey(Object key): 返回该 Map 中位于 key 前一位的 key 值(即小于指定 key 的最大key 值) 。 如果 该 Map 为 空或不存在这样的 key. 则都返回 null 。
NavigableMap subMap(Object fromKey, boolean fromInclusive, Object toKey, boolean toInclusive):
返回该 Map 的子 Map. 其 key 的范围是从 fromKey (是否包括取决于第二个参数) 到 toKey (是否包括取决于第四个参数) 。
SortedMap subMap(Object 仕omKey, Object toKey): 返回该 Map 的子 Map. 其 key 的 范围是从
fromKey (包括 〉 到 toKey (不包括) 。
SortedMap tailMap(Object 企omKey): 返回该 Map 的子 Map. 其 key 的 范围是大于 fromKey (包括)的所有 key 。
NavigableMap tailMap(Object fromKey, boolean inclusive): 返回该 Map 的子 Map. 其 key 的范围是大于 fromKey (是否包括取决于第二个参数〉的所有 key 。
SortedMap headMap(Object toKey): 返回该 Map 的子 Map. 其 key 的范围是小于 toKey (不包括)的所有 key 。
NavigableMap headMap(Object toKey, boolean inclusive): 返回 该 Map 的子 Map. 其 key 的范围
是小于 toKey (是否包括取决于第二个参数) 的所有 key 。
实例代码:
import java.util.TreeMap;
/**
* @author: 随风飘的云
* @describe:
* @date 2022/03/22 22:47
*/
class R implements Comparable
{
int count;
public R(int count)
{
this.count = count;
}
public String toString()
{
return "R[count:" + count + "]";
}
// 根据count来判断两个对象是否相等。
public boolean equals(Object obj)
{
if (this == obj)
return true;
if (obj != null && obj.getClass() == R.class)
{
R r = (R)obj;
return r.count == this.count;
}
return false;
}
// 根据count属性值来判断两个对象的大小。
public int compareTo(Object obj)
{
R r = (R)obj;
return count > r.count ? 1 :
count < r.count ? -1 : 0;
}
}
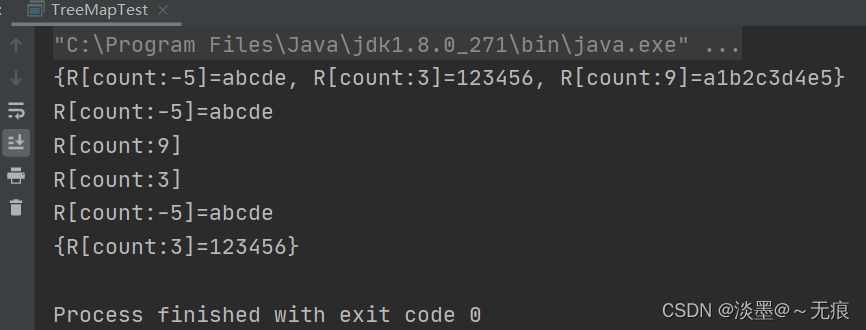
public class TreeMapTest {
public static void main(String[] args) {
TreeMap tm = new TreeMap();
tm.put(new R(3) , "123456");
tm.put(new R(-5) , "abcde");
tm.put(new R(9) , "a1b2c3d4e5");
System.out.println(tm);
// 返回该TreeMap的第一个Entry对象
System.out.println(tm.firstEntry());
// 返回该TreeMap的最后一个key值
System.out.println(tm.lastKey());
// 返回该TreeMap的比new R(2)大的最小key值。
System.out.println(tm.higherKey(new R(2)));
// 返回该TreeMap的比new R(2)小的最大的key-value对。
System.out.println(tm.lowerEntry(new R(2)));
// 返回该TreeMap的子TreeMap
System.out.println(tm.subMap(new R(-1) , new R(4)));
}
}
结果:
WeakHashMap 实现类
基本原理
WeakHashMap 与 HashMap 的用法基本相似 。 与 HashMap 的 区别在于,HashMap 的 key 保留了对实际对象的强引用,这意味着只要该 HashMap 对象不被销毁,该 HashMap 的所有 key 所引用的对象就不会被垃圾回收,HashMap 也不会自动删除这些 key 所对应的 key-value 对 ;但 WeakHashMap 的 key只保留了对实际对象的弱引用,这意味着如果 WeakHashMap 对象的 key 所引用的对象没有被其他强引用变量所引用,则这些 key 所引用的对象可能被垃圾回收, WeakHashMap 也可能自动删除这些 key 所对应的 key-value 对 。
实例源码:
import java.util.WeakHashMap;
/**
* @author: 随风飘的云
* @describe:
* @date 2022/03/22 23:05
*/
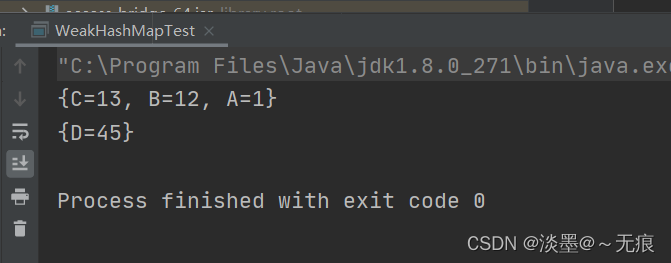
public class WeakHashMapTest {
public static void main(String[] args) {
WeakHashMap<String, Object> map = new WeakHashMap<>();
map.put(new String("A"), new String("1"));
map.put(new String("B"), new String("12"));
map.put(new String("C"), new String("13"));
System.out.println(map);
map.put("D", new String("45"));
System.gc();
System.out.println(map);
}
}
结果:
IdentityHashMap 实现类
基本原理
IdentityHashMap 实现类的实现机制与 HashMap 基本相似,但它在处理两个 key 相等时比较独特:在IdentityHashMap 中,当且仅当 两个 key 严格相等 (key1 == key2) 时, IdentityHashMap 才认为两个 key相等;对于普通的 HashMap 而言,只要 key1 和 key2 通过 equals()方法比较返回 true ,且它们的 hashCode值相等即可 。
实例源码:
import java.util.IdentityHashMap;
/**
* @author: 随风飘的云
* @describe:
* @date 2022/03/22 23:11
*/
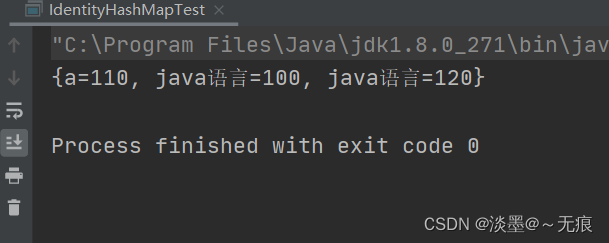
public class IdentityHashMapTest {
public static void main(String[] args) {
IdentityHashMap map = new IdentityHashMap();
// 通过比较 == 不等,
map.put(new String("java语言"),100);
map.put(new String("java语言"), 120);
// 常量,只能添加一个。
map.put("a", 100);
map.put("a", 110);
System.out.println(map);
}
}
结果:
EnumMap 实现类
基本原理
EnumMap 是一个与枚举类一起使用的 Map实现, EnumMap 中的所有 key 都必须是单个枚举类的枚举值 。 创建 EnumMap 时必须显式或隐式指定它对应的枚举类。 EnumMap 具有如下特征 。
1、EnumMap在内部以数组形式保存,所以这种实现形式非常紧凑、高效 。
2、EnumMap 根据 key 的自然顺序(即枚举值在枚举类中的 定义顺序〉来维护 key-value 对的顺序 ,当程序通过 keySet()、 entrySet() 、 values()等方法遍历EnumMap 时可以看到这种顺序 。
3、EnumMap 不允许使用 null 作为 key ,但允许使用 null 作为 value 。如果试图使用 null 作为 key时将抛出 NullPointerException 异常 。 如果只是查询是否包含值为 null 的key,或只是删除值为null 的key ,都不会抛出异常 。
与创建普通的 Map 有所区别的是,创建 EnumMap 时必须指定一个枚举类,从而将该 EnurnMap 和
指定枚举类关联起来 。
实例源码:
import java.util.EnumMap;
/**
* @author: 随风飘的云
* @describe:
* @date 2022/03/22 23:19
*/
enum Season {
SPRING,SUMMER,FALL,WINTER
}
public class EnumMapTest {
public static void main(String[] args) {
// 创建EnumMap对象,该EnumMap的所有key都是Season枚举类的枚举值
EnumMap enumMap = new EnumMap(Season.class);
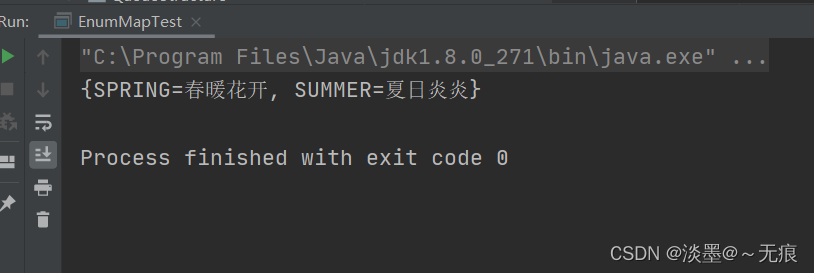
enumMap.put(Season.SUMMER , "夏日炎炎");
enumMap.put(Season.SPRING , "春暖花开");
System.out.println(enumMap);
}
}
结果:
各种Map集合类的性能分析
对于 Map 的常用实现类而言,虽然 HashMap 和 Hashtable 的实现机制几乎一样,但由于 Hashtable
是一个古老的、线程安全的集合,因此 HashMap 通常比 Hashtable 要快 。
TreeMap 通常比 HashMap 、 Hashtable 要慢( 尤其在插入、删除 key-value 对时更慢),TreeMap
底层采用红黑树来管理 key-value 对(红黑树的每个节点就是一个 key-value 对) 。
使用 TreeMap 有一个好处::TreeMap 中的 key-value 对总是处于有序状态 ,无须专 门进行排序操作 。当 TreeMap 被填充之后,就可以调用 keySet(),取得由 key 组成的 Set,然后使用 toArray()方法生成 key的数组,接下来使用Arrays 的 binarySearch()方法在己排序的数组中快速地查询对象。
对于 一般的应用场景 , 程序应该多考虑使用 HashMap ,因为 HashMap 正是为快速查询设计的(HashMap 底层其实也是采用数组来存储 key-value 对 〉 。 但如果程序需要一个总是排好序的 Map 时,则可以考虑使用 TreeMap 。
LinkedHashMap 比 HashMap 慢一 点,因为它需要维护链表来保持 Map 中 key-value 时的添加顺序。IdentityHashMap 性能没有特别出色之处 ,因为它采用与 HashMap 基本相似的实现 , 只是它使用 == 而不是 equals()方法来判断元素相等 。 EnumMap 的性能最好 ,但它只能使用同一个枚举类的枚举值作为 key 。
Collections工具类
排序
Collections 提供了如下常用的类方法用于对 List 集合元素进行排序 。
void reverse(List list): 反转指定 List 集合中元素的顺序 。
void shuffie(List list): 对 List 集合元素进行随机排序 (shuffie 方法模拟了"洗牌"动作) 。
void sort(List list): 根据元素的自然顺序对指定 List 集合的元素按升序进行排序。
void sort(List list, Comparator c): 根据指定 Comparator 产生的顺序对 List 集合元素进行排序 。
void swap(List list, int i, int j): 将指定 List 集合中的 i 处元素和 j 处元素进行交换。
void rotate(List list , int distance): 当 distance 为正数时,将 list 集合的后 distance 个元素"整体"移到前面:当 distance 为负数时,将 !ist 集合的前 distance 个元素"整体"移到后面 。 该方法不会改变集合的长度 。
替换
Collection s 还提供了如下常用的用于查找 、 替换集合元素的类万法 。
int binarySearch(List list, Object key): 使用 二分搜索法搜索指定的 List 集合,以获得指定对象在 List
集合中的索引。如果要使该方法可 以正常工作,则必须保证 List 中的元素己经处于有序状态。
Object max(Collection coll): 根据元素的自然顺序,返 回给定集合中的最大元素。
Object max(Collection coll, Comparator comp): 根据 Comparator 指定的顺序 ,返回给定集合中的最大元素 。
Object min(Collection coll) : 根据元素的自然顺序,返回给定集合中的最小元素 。
Object min(Collection coll, Comparator comp): 根据 Comparator 指 定的顺序,返回给定集合中的
最小元素 。
void fill(List list, Object obj): 使用指定元素 obj 替换指定 List 集合中的所有元素 。
int frequency(Collection c, Object o): 返回指定集合中指定元素的出现次数 。
int indexOfSubList(List source, List target) : 返回子 List 对象在父 List 对象中第一次出现的位置索引:如果父 List 中没有出现这样的子 List,则返回-1。
int lastIndexOfSubList(List source, List target): 返回子 List 对象在父 Li st 对象中最后一 次出现 的
位置索引 ;如果父 List 中没有出现这样的子 List,则返回-1 。
boolean replaceAll(List list, Object o ldVal, Object newVal) : 使用 一个新值 newVal 替换 List 对象的所有旧值oldVal 。















 1027
1027











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









